一、前言
支持向量机(Support Vectore Machine,SVM)学习问题可以表示为凸优化问题,能够在小样本训练量的情况下,使用有效地算法求解线性及非线性问题的全局最优解。支持向量机在求解非线性分类问题时,利用核技巧将非线性问题从低维空间向高维空间映射,然后采取线性分类问题的方式去解决。在非线性问题上的优异表现及较高的鲁棒性,使得支持向量机成功应用于语音识别、人脸识别、图像处理等领域。
二、基础
1.概念
支持向量机以间隔最大化为目标,采取硬间隔最大化(Hard margin)与软间隔最大化(Soft margin)的模型,寻找一个超平面对样本进行分割。支持向量机三个核心要点为间隔、对偶、核技巧。
1)训练样本线性可分时,采用硬间隔最大化训练线性可分支持向量机;
2)训练样本近似线性可分时,采用软间隔最大化训练线性支持向量机;
3)训练样本非线性时,基于核技巧,采用硬间隔最大化或软间隔最大化训练非线性支持向量机。

在样本空间中,划分超平面可通过如下线性方程来描述:
ωτxi+b=0
其中
w为法向量,决定了超平面的方向,
b为位移量,决定了超平面与原点的距离。
假设超平面能将训练样本正确地分类,即对于训练样本
(xi,yi),满足以下公式:
{ωτxi+b>0,yi=+1ωτxi+b<0,yi=−1
其中,
yi=+1 表示样本为正样本,
yi=−1表示样本为负样本。
2.函数间隔与几何间隔
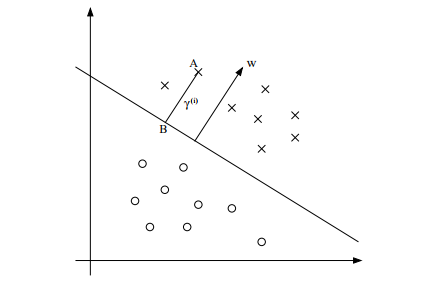
由超平面的公式可得知超平面
(ω,b)关于样本
(xi,yi)的函数间隔为:
γ
i=yi(ωτxi+b)
如果成比例地改变
ω和
b,超平面没有改变,函数间隔却有所变化。函数间隔可以表示分类预测的正确性及确信度,但是不足以选择分离超平面,因此引出超平面
(ω,b)关于样本
(xi,yi)的几何间隔,即样本点至超平面的距离:
γi=yi(∥ω∥ωτxi+∥ω∥b)
即使超平面参数
ω和
b成比例地改变,几何间隔也不会变化。
三、硬间隔最大化
1.间隔最大化
下面考虑如何求得一个几何间隔最大的分离超平面,即最大间隔分离超平面。该问题可以表示为下面的约束最优化问题:
⎩⎨⎧ω,bmaxγs.t.yi(∥ω∥ωτxi+∥ω∥b)≥γ,i=1,2,...,N
该优化问题可改写为:
{ω,bmax∥ω∥γ
s.t.yi(ωτxi+b)≥γ,i=1,2,...,N
由于函数间隔
γ
可随着
ω和
b等比例缩放,它的取值不影响最优化问题的求解,因此取
γ
=1,注意到求最大化
∥ω∥1和最小化
21∥ω∥2是等价的,于是得到下面的线性可分支持向量机学习的最优化问题:
{ω,bmin21∥ω∥2s.t.yi(ωτxi+b)≥1,i=1,2,...,N
这是一个凸二次规划问题(QP问题)及原问题,即可对问题进行求解。
由最优化问题的约束条件得到下面对于训练样本
(xi,yi)满足的公式,也是我们常见的约束条件:
{ωτxi+b≥1,yi=+1ωτxi+b≤1,yi=−1
2.对偶算法
我们要求解的是最小化问题,可以构造一个可行解区域内与原目标函数完全一致的函数,而在可行解区域外的数值非常大,甚至是无穷大,那么这个没有约束条件的新目标函数的优化问题就与原来有约束条件的原始目标函数的优化问题是等价的问题。因此基于拉格朗日乘子法将约束条件放到目标函数中,将有约束的优化问题转换为无约束问题。然后利用凸优化问题的强对偶性,对问题再进行一次转换,最终实现问题的求解。也正是基于对偶算法,SVM才能应用核函数去解决非线性的问题。
1)构造拉格朗日目标函数
拉格朗日目标函数
L(ω,b,α)=21∥ω∥2+i=1∑Nαi[1−yi(ωτxi+b)]
其中
αi是拉格朗日乘子,
αi≥0。原问题即可转化为新的目标函数:
ω,bminαi≥0maxL(ω,b,α)
2)强对偶性
基于凸优化问题具有强对偶性的特点,使用拉格朗日函数对偶性,将最小和最大的位置交换一下,形成新的优化目标函数:
αi≥0maxω,bminL(ω,b,α)
3)求解
求
L(ω,b,α)关于
ω和
b的极小值,我们分别对
ω和
b偏导数,令其等于0,即:
∂ω∂L=0⇒ω∗=i=1∑Naiyixi∂b∂L=0⇒i=1∑Naiyi=0
将结果带入
L(ω,b,α),可得:
w,bminL(ω,b,a)=−21i=1∑Nj=1∑NaiajyiyjxiTxj+i=1∑Nai
因此原问题经过强对偶转化后得到的目标函数为:
amax−21i=1∑Nj=1∑NaiajyiyjxiTxj+i=1∑Nais.t.ai≥0,i=1,2,...,ni=1∑Naiyi=0
该问题可直接求解
α,也可以使用高效的序列最小优化(SMO)算法求解
α,然后求解
ω和
b。其中
ω的公式已经求出,而
b可基于以下的KKT条件进行推导求解。
3.KKT条件
一个最优化模型能够表示成下列的标准形式:
⎩⎨⎧minf(x)s.t.gj(x)≤0,j=1,2,...,mhk(x)=0,k=1,2,...,l
该优化模型需满足以下KKT(Karush-Kuhn-Tucker)条件:
1)条件一:经拉格朗日函数转化得到的目标函数
L(ω,b,α)对x求导为零:
2)条件二:
α⋅gj(x)=0;
3)条件三:
hk(x)=0 。
对于经过强对偶转换后的优化问题满足:
$$\left{\begin{array}{l}\frac{\partial L}{\partial x}=0\\alpha_i\left[1-y_i\left(\omega^\tau x_i+b\right)\right]=0\1-y_i\left(\omega^\tau x_i+b\right)\leq0\\alpha_i\geq0\end{array}\right.\$$
根据支持向量机的特点,存在使得
αi≥0的位于间隔边界上的样本
(xi,yi),因此有:
1−yk(ωτxk+b)=0⇒yk(ωτxk+b)=1⇒ωτxk+b=yk⇒b∗=yk−ωτxk
带入
ω∗=∑i=1Naiyixi有:
{ω∗=∑i=1Naiyixib∗=yk−∑i=1NaiyixiTxk
然后就能求解出对偶问题的求解
ω和
b。
四、软间隔最大化
1.间隔最大化
对于近似线性可分的问题,软间隔最大化允许存在一点点错误,因此在目标函数在硬间隔最大化的基础上增加损失函数。
求解
ω,bmin21∥ω∥2的问题变为
ω,bmin21∥ω∥2+loss的问题。
2.合页损失函数
期望
yi(ωτxi+b)≥1时,
loss为0;
yi(ωτxi+b)<1时允许
loss存在,定义
loss=1−yi(ωτxi+b)。则合页损失函数(Hinge loss)表达式为:
L=max{0,1−y(ωτx+b)}

因此,期望求解的目标函数为:
ω,bmin21∥ω∥2+Ci=1∑Nmax{0,1−yi(ωτxi+b)}
引入
ζi=1−yi(ωτxi+b),ζi≥0,软间隔最大化的最优化问题可表示为:
{ω,bmin21∥ω∥2+C∑i=1Nςis.t.yi(ωτxi+b)≥1−ςi,ςi≥0
五、总结
本文介绍了支持向量机的基本概念,然后以函数间隔及几何间隔为基础推导出硬间隔和软间隔最大化的原问题。以采取硬间隔最大化的线性可分支持向量机为主线,从原问题推导出对偶问题,并基于KKT条件对超平面参数进行求解。
参考资料
[1]:机器学习-白板推导系列(六)-支持向量机SVM
[2]:支持向量机——线性可分支持向量机
[3]:支持向量机原理篇之手撕线性SVM
[4]:合页损失函数的理解


