基本了解
缺点:
- 不适用与数据量大的情况:K近邻需要计算目标实例与所有样本实例的距离,计算量大,耗时长,需要保存所有的训练数据,所需大量的内存空间。
- 无法给出给出任何数据的数据结构,不能知晓典型实例样本和平均实例样本具有什么样的特征。
优点:
- 最简单的分类算法。
- 对异常值不敏感。
- 精度高
- 无数据输入假定
注意点:
在求解距离的过程中,数值较大的特征,如取值为1000和10的两个特征,取值为1000的特征会对分类结果产生比较大的影响,但这并不意味着该特征在模型中具有较强的影响力,所以需要对数据进行归一化处理。
工作原理
k近邻模型的主要原理:计算目标实例与所有样本实例的距离,对距离进行排序,选择出前K个距离最小的样本实例,通常采用投票表决机制,即选择出类别最多的那一种类别。
本章概要
-
k近邻是基本且简单的分类与回归方法,既可用于二分类,又可用于多分类。支持线性不可分的数据。K近邻法的基本做法是:对给定的训练实例点和输入实例点,首先确定输入实例点的K个最近邻训练实例点,然后利用这K个训练实例点的类的多数来预测输入实例点的类。
-
k近邻模型对应于基于训练数据集对特征空间的一个划分。K近邻法中,当训练集、距离度量、K值及分类决策规则确定后,其结果唯一确定。
-
K邻近法三要素:距离度量、K值的选择和分类决策规则。常用的距离度量是欧氏距离及更一般的 距离。K值小时,k近邻模型更复杂,即会发生过拟合;k值大时,k近邻模型更简单,即会发生欠拟合。k值的选择反应了对近似误差(训练集的误差)和估计误差(预测集的误差)之间的权衡,通常首先选择较小的k值,再由交叉验证选择最优的k。常用的分类决策是多数表决,对应于经验风险最小化。
-
K近邻的误分类率:
-
K近邻法的实现需要考虑如何快速搜索K个最近邻点。因为当进行一个未知样本点的预测时,需要遍历整个训练集样本找到k个近邻点,时间复杂度高,所以需要优化其存储结构,加速搜索速度。
-
kd树是一种便于对k维空间中的数据进行快速检索的数据结构。kd树是二叉树,表示对k维空间的一个划分,其每个节点对应于k维空间划分中的一个超矩形区域。利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
基本算法

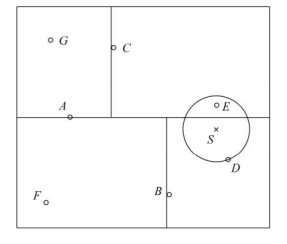
以下图为例,进行简单说明:
(1) 找到包含目标点S的最小超矩形中的叶节点D,D是近似最近邻;
(2) 以S为圆心,D在圆上形成一个圆形区域;
(3) 找到D的父节点B,搜索B的另一边区域是否与圆相交,且在交集中有节点;
(4) 若没有则继续查找B的父节点A,搜索A的另一区域内搜索最近邻;
(5) 节点C的区域与圆相交;且查找交集内存在节点E,所以E是真正最近邻
作业
1.思考k近邻算法的模型复杂度体现在哪里?什么情况下会造成过拟合?
模型复杂度体现在k值的选择,k值越小,模型复杂度越高,容易造成过拟合,k值越小,模型复杂度越低。
2.给定一个二维空间的数据集T={正实例:(5,4),(9,6),(4,7);负实例:(2,3), (8,1),(7,2)},试基于欧氏距离,找到数据点S(5,3)的最近邻(k=1),并对S点进行分类预测。
(1)用“线性扫描”算法自编程实现。
(2)试调用sklearn.neighbors的KNeighborsClassifier模块,对S点进行分类预测,并对比近邻数k取值不同,对分类预测结果的影响。
k取值不同,最终的分类预测结果也不同
(3)思考题:思考“线性扫描”算法和“kd树”算法的时间复杂度。
只考虑样本N的情况下:
线性扫描:O(N)
kd树算法:O(logN)
当维度d接近样本量N时,线性扫描与kd树算法的线性复杂度相当。
(1)用“线性扫描”算法自编程实现。
import numpy as np
import matplotlib.pyplot as plt
import collections
def main():
x_train = np.array([[5,4],[9,6],[4,7],[2,3],[8,1],[7,2]])
y_train = np.array([1,1,1,-1,-1,-1])
s = np.array([5,3])
k = 1
myKNN = KNN()
prediction = myKNN.predict(x_train, y_train, s, k)
print("目标点S的类别为:{}".format(prediction))
class KNN:
# 核心算法实现: 距离度量采用欧式距离,并利用线性检索,找到离s点最近的样本点
def predict(self, x_train, y_train, s, k):
distance = []
labels = []
for i in range(x_train.shape[0]):
x = x_train[i]
# 计算x_test与s的距离度量/欧式距离
distance.append(np.sqrt(pow(x[0]-s[0],2) + pow(x[1]-s[1],2)))
# print("s到各点的距离度量:{}".format(distance))
# 对欧式距离进行排序,找出欧氏距离最小的k个节点对应的标签
sorted_distance = sorted(distance)
for i in range(k):
labels.append(y_train[distance.index(sorted_distance[i])])
# 对K个y值进行统计,输出出现频率最高的y值
map_label = collections.Counter(labels)
return max(map_label.keys(), key=map_label.get)
main()
优化方法一:
主要是列表生成式的使用和通过np.linalg.norm计算欧式距离。
class KNN:
def __init__(self, x_train, y_train, k):
self.x_train = x_train
self.y_train = y_train
self.k = k
# 核心算法实现: 距离度量采用欧式距离,并利用线性检索,找到离s点最近的样本点
def predict(self, s):
dist_list = [(np.linalg.norm(s-self.x_train[i],ord=2), self.y_train[i])
for i in range(self.x_train.shape[0])]
# 输出为: [(d0, 1), (d1, -1)...]
#print("s到各点的距离度量:{}".format(dist_list))
# 对欧式距离进行排序
dist_list.sort(key=lambda x: x[0])
# 取前k个最小的距离的标签
y_list = [dist_list[i][-1] for i in range(self.k)]
# 对K个y值进行统计,输出出现频率最高的y值
"""
另一种方法:
y_count = Counter(y_list).most_common()
return y_count[0][0]
"""
y_count = Counter(y_list)
return max(y_count.keys(), key=y_count.get)
if __name__=="__main__":
main()
(2) 调用sklearn.neighbors的KNeighborsClassifier模块,对S点进行分类预测,并对比近邻数k取值不同,对分类预测结果的影响。

- kd_tree和ball_tree在数据量较大时使用;
- 当维度上升时,kd树效率下降,一般当特征维度大于20时,使用ball_tree算法;
| 方法 | 描述 |
|---|---|
| fit(self, X, y) | Fit the model using X as training data and y as target values;训练模型,确定使用算法,即确定选择哪一种算法。 |
| get_params(self[, deep]) | Get parameters for this estimator. 获取评估器的参数 |
| kneighbors(self[, X, n_neighbors, …]) | Finds the K-neighbors of a point. 找到目标点的K个近邻 |
| kneighbors_graph(self[, X, n_neighbors, mode]) | Computes the (weighted) graph of k-Neighbors for points in X. 计算X中节点的(加权)图 |
| predict(self, X) | Predict the class labels for the provided data. 预测给定数据的类别 |
| predict_proba(self, X) | Return probability estimates for the test data X. 对测试点属于不同分类的概率 |
| score(self, X, y[, sample_weight]) | Return the mean accuracy on the given test data and labels. 返回给定测试数据和标签的平均准确率 |
| set_params(self, **params) | Set the parameters of this estimator. 设置评估器的参数 |
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
def main():
x_train = np.array([[5,4],[9,6],[4,7],[2,3],[8,1],[7,2]])
y_train = np.array([1,1,1,-1,-1,-1])
s = np.array([[5,3]])
for k in range(1,6,2):
kneighbor = KNeighborsClassifier(n_neighbors=k).fit(x_train,y_train)
prediction = kneighbor.predict(X = s)
# 输出结果为一个数组,分别表示属于该分类的概率;如[0,1]表示属于‘-1’的概率为0,属于‘1’的概率为1。
print("目标点S属于不同分类的概率:{}".format(kneighbor.predict_proba(s)))
print("目标点S[5,3]的类别为:{}".format(prediction))
accuracy = kneighbor.score(x_train,y_train)
print("模型预测的准确率:{:.0%}".format(accuracy))
if __name__=="__main__":
main()
输出值:
目标点S属于不同分类的概率:[[0. 1.]]
目标点S[5,3]的类别为:[1]
模型预测的准确率:100%
目标点S属于不同分类的概率:[[0.66666667 0.33333333]]
目标点S[5,3]的类别为:[-1]
模型预测的准确率:83%
目标点S属于不同分类的概率:[[0.6 0.4]]
目标点S[5,3]的类别为:[-1]
模型预测的准确率:83%
