主要参考:
k近邻法介绍:
https://blog.csdn.net/Smile_mingm/article/details/108385312
-
k近邻法:判别模型
-
模型:
y = a r g m a x c j ∑ x i ∈ N k ( x ) I ( y i = c j ) , i = 1 , 2 , . . . , N ; j = 1 , 2 , . . . , K y = arg \underset{cj}{max}\sum_{x_{i}\in N_{k}(x)}^{}I(y_{i}=c_{j}),i=1,2,...,N;j=1,2,...,K y=argcjmax∑xi∈Nk(x)I(yi=cj),i=1,2,...,N;j=1,2,...,K
I I I为指示函数,即当 y i = c j y_{i}=c_{j} yi=cj时 I I I为1,否则 I I I就为 0 0 0 -
基本思想:在要预测的点画一个圈(也就是离该点距离最近的K个点作为一个邻域),然后看这个邻域中K个点属于哪个类别的多就判断该预测点为哪个类。
-
三要素:k值的选择、距离度量、分类决策规则
- 当k=1时,称为最近邻法
- 较小的k值:
- 优:只有与实例相近的训练实例才会对预测结果起作用。近似误差会减小。
- 缺:预测结果会对邻近的实力点敏感。估计误差会变大。
- 较大的k值:
- 优:减少了估计误差。
- 缺:与输入实例较远的(不相关的)点也会起作用。近似误差会变大。 -
距离度量:对两点之间的距离,度量方式有多种,如平时常用的欧式距离,还有曼哈顿距离(直接坐标减,不平方)等。
-
分类决策规则:多数表决规则,也就是圈子里哪个类别多,就预测为该类。
kd树:
https://zhuanlan.zhihu.com/p/53826008
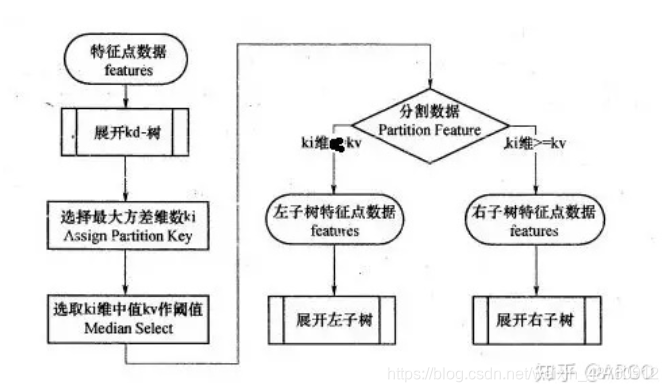
构建kd树-> 选择切分域、切分点
查找->
1 寻找近似点-寻找最近邻的叶子节点作为目标数据的近似最近点。
2 回溯-以目标数据和最近邻的近似点的距离沿树根部进行回溯和迭代。
作业中的代码解释参考:
作业:https://blog.csdn.net/sdu_hao/article/details/103055338
zip: https://www.runoob.com/python/python-func-zip.html
plt.subplots(): https://www.cnblogs.com/komean/p/10670619.html
flatten()函数用法:
https://www.cnblogs.com/yvonnes/p/10020926.html
numpy.meshgrid():
https://zhuanlan.zhihu.com/p/41968396
代码大致解释:
https://blog.csdn.net/smallcases/article/details/78236412