文章目录
在对数据进行挖掘之前,我们得到的数据往往是不太理想的,数据缺失值太严重导致统计数据指标不太容易,这篇文章记录下如何在含有缺失值的情况下统计出我想要的一些数据
实验环境
- ubuntu 18.04
- python 3.6
- numpy scipy pandas
- 随意一个csv文件(当然是要有数据的,我的csv部分数据如下)

- 每个py文件都导入了以下三个依赖
import numpy as np
import pandas as pd
from scipy import stats
读取csv文件
读取csv文件,并在函数中打印出读取的结果,最后返回一个DataFrame对象
def readcsv(filepath):
"""
读取csv文件
:param filpath: 文件路径
"""
df = pd.read_csv(filepath)
print(df)
return df
filepath = 'santander-customer-satisfaction/test.csv'
readcsv(filepath)
我的运行结果结果如下:
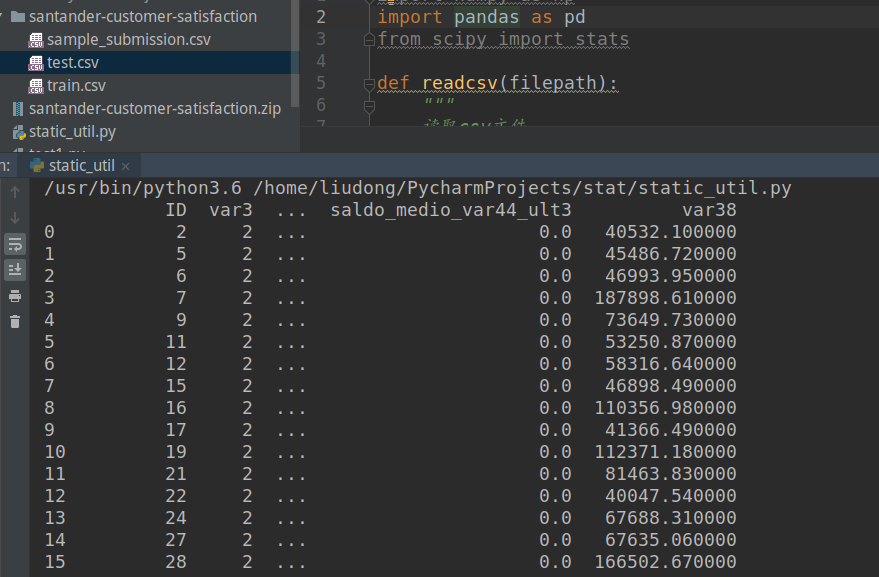
删除数据中我们不需要的列(假设我不需要ID的属性)
def dropProperty(df, drop_properties):
"""
传入一个数据表
:param df: dataFrame对象
:param drop_properties: 想要删除的属性集
:return 返回一个删掉了一个或多个属性的df对象,不影响传入的对象
"""
#axis=0代表删除相应的行,axis=1代表删除相应的列
df = df.drop(drop_properties, axis=1)
return df
简单测试
filepath = 'santander-customer-satisfaction/test.csv'
df = readcsv(filepath)
print('原始数据的前三行:')
print(df.head(3))
df = dropProperty(df, ['ID'])
print('--'*20)
print('删掉了ID属性列的结果:')
print(df.head(3))
测试的结果:
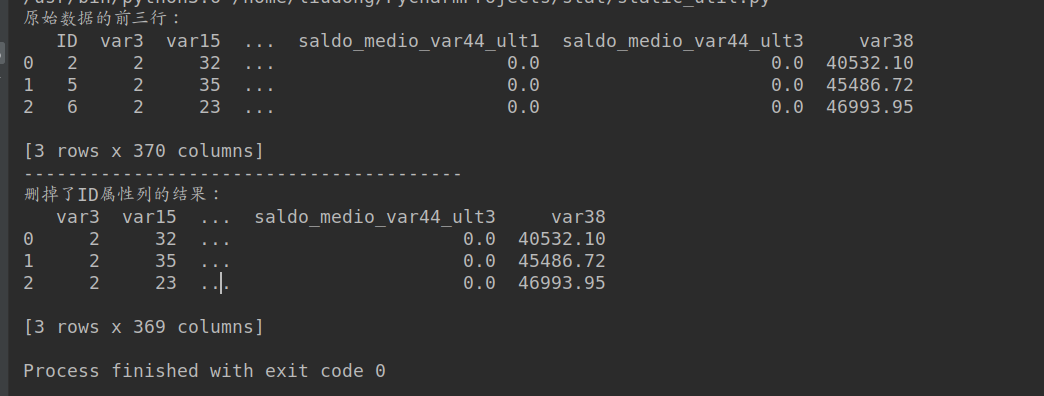
统计某一列或多列数据有多少种不同的值
def uniqueCount(df, start, end):
"""
统计一列或者多列有多少种不同的值
:param df: dataframe对象
:param start 开始统计的第(start+1)列
:param end 最后统计的一列(第end列)
:return:
"""
if end <= start:
return None
# 冒号是一个切片的意思
diffCount = df.iloc[:, start:end].apply(lambda x: len(x.unique()))
return diffCount
简单测试
filepath = 'santander-customer-satisfaction/test.csv'
df = readcsv(filepath)
result = uniqueCount(df, 0, 3)
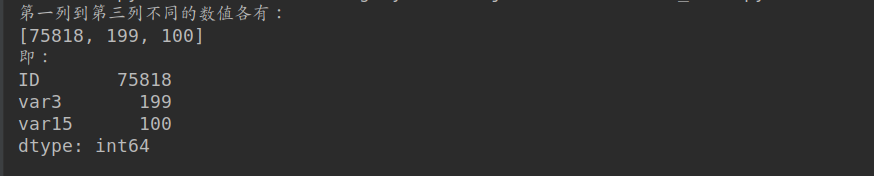
print('第一列到第三列不同的数值各有:')
print(list(result))
print('即:')
print(result)
测试结果:
扫描二维码关注公众号,回复:
10153447 查看本文章

统计某一列有多少个等于某个值(测试我这里统计第二列[var3]等于32的值的个数)
def countValue(df, col_start, col_end, value):
"""
统计第col+1列中等于value的数量
:param df: dataframe对象
:param col_start: 开始列数(从零开始)
:param col_end: 结束列数
:param value: 等于的某个值
:return: 个数(如果是多个列,那么返回一个序列)
"""
if col_start >= col_end:
return None
else:
count = df.iloc[:, col_start:col_end].apply(lambda x: np.sum(x == 0))
return count
简单测试
filepath = 'santander-customer-satisfaction/test.csv'
df = readcsv(filepath)
count = countValue(df, 1, 2, 32)
print(count)
测试结果

求取去除缺失值的均值
def meanValue(df, col_start, col_end, miss_set):
"""
求取各列去除了缺失值的均值
:param df:dataframe对象
:param col_start: 开始列
:param col_end: 结束列
:param miss_set: 缺失值的集合
:return: 返回各个列的均值
"""
if col_start >= col_end:
return None
else:
# ~ 代表取反操作,不属于miss_set里面的值的就属于正常的情况
# 对正常的值进行mean()操作就是去除了缺失值的均值
mean = df.iloc[:, col_start:col_end].apply(lambda x: np.mean(x[~np.isin(x, miss_set)]))
return mean
简单测试
filepath = 'santander-customer-satisfaction/test.csv'
df = readcsv(filepath)
# 假设32, np.nan和111是属于不正常的值
mean = meanValue(df, 0, 3, [32, np.nan, 111])
print('去除了不正常值的均值:')
print(mean)
测试结果

关于众数&最大值&最小值&出现频率在前几的数据
- 统计众数需要借助 scipy的stats中的mode函数即
stats.mode(list) - 统计最大值&最小值借助numpy中的max&min
- 统计出现频率最高的几位使用形如
df.iloc[:, :].value_counts().iloc[0:5]的函数
如有问题,请指教
