特征分析与偏移分析
什么是开窗函数?
开窗函数用于为行定义一个窗口(这里的窗口是指运算将要操作的行的集合),它对一组值进行操作,不需要使用GROUP BY子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列。
- Window Function又称为窗口函数、分析函数。
- 窗口函数与聚合函数类似,但是每一行数据都生成一个结果。
- 聚合函数(比如sum、avg、max等)可以将多行数据按照规定聚合为一行,一般来讲聚集后的行数要少于聚集前的行数。但是有时我们想要既显示聚集前的数据,又要显示聚集后的数据,这时便引入了窗口函数。
- 窗口函数是在select时执行的,位于order by之前。
OVER(PARTITION BY)
over不能单独使用,要和分析函数:rank(),dense_rank(),row_number()等一起使用。
其参数:over(partition by columnname1 order by columnname2)
含义:按columname1指定的字段进行分组排序,或者说按字段columnname1的值进行分组排序。开窗函数over( ),包含三个分析子句:partition by , order by , rows rows代表开窗,窗口就是分析函数要处理的范围。
学习目标:
1、掌握sum()、avg()用于累计计算的函数
2、掌握row_number()、rank()用于排序的函数
3、掌握ntile()用于分组查询的函数
4、掌握lag()、lead()``偏移分析函数
1、累计计算窗口函数
(1)sum(…) over(……)
大家在做报表的时候,经常会遇到计算截止某月的累计数值,通常在
EXCEL里可以通过函数来实现。
那么在Hive中,我们该如何实现这种累计数值的计算呢?——利用窗口函数
我们通过几个需求案例来讲解开窗函数的具体应用。
需求1-1:
对2018年公司的支付总额按月度累计进行分析。
按月度进行累计分析:
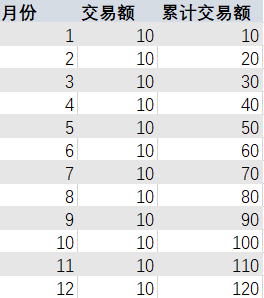
SELECT a.month,
a.pay_amount,
sum(a.pay_amount) over(order by a.month)
FROM
(SELECT month(dt) month,
sum(pay_amount) pay_amount
FROM user_trade
WHERE year(dt)=2018
GROUP BY month(dt))a;
SQL解析:
子查询中:dt 是分区字段,这里month(dt)是取月份,需求要按月度进行分析,所以我们要按month分组GROUP BY month(dt),还要计算每个月的支付总额sum(pay_amount),最后将子查询结果命名为a,子查询要查的是两个指标month和pay_amount
外层查询我们要使用窗口函数了
查询月份,以及每个月的支付总额,还有一个字段就是需求要求的支付总额按月度累计的字段。
sum(a.pay_amount) over(order by a.month)
这里因为要求累计,所以窗口函数这里用到了sum函数,sum(a.pay_amount)是对子查询结果a中的支付总额进行求和,这里over(order by a.month)就是要根据月份month逐渐递增累计求和。
例如:累计求和中第三月的累计月度支付总额5640670.2=第一月317697.2的支付总额 + 第二月2532234.3000000003的支付总额。
4月累计总额=前三个月累计总额+四月支付总额。
需求1-2:
对2017和2018年公司的支付总额按月度累计进行分析,按年度进行汇总。
分析:按照月度累计后,还要按照年度进行汇总,也就是2017年的支付总额和2018年的支付总额按年度累计分开显示。
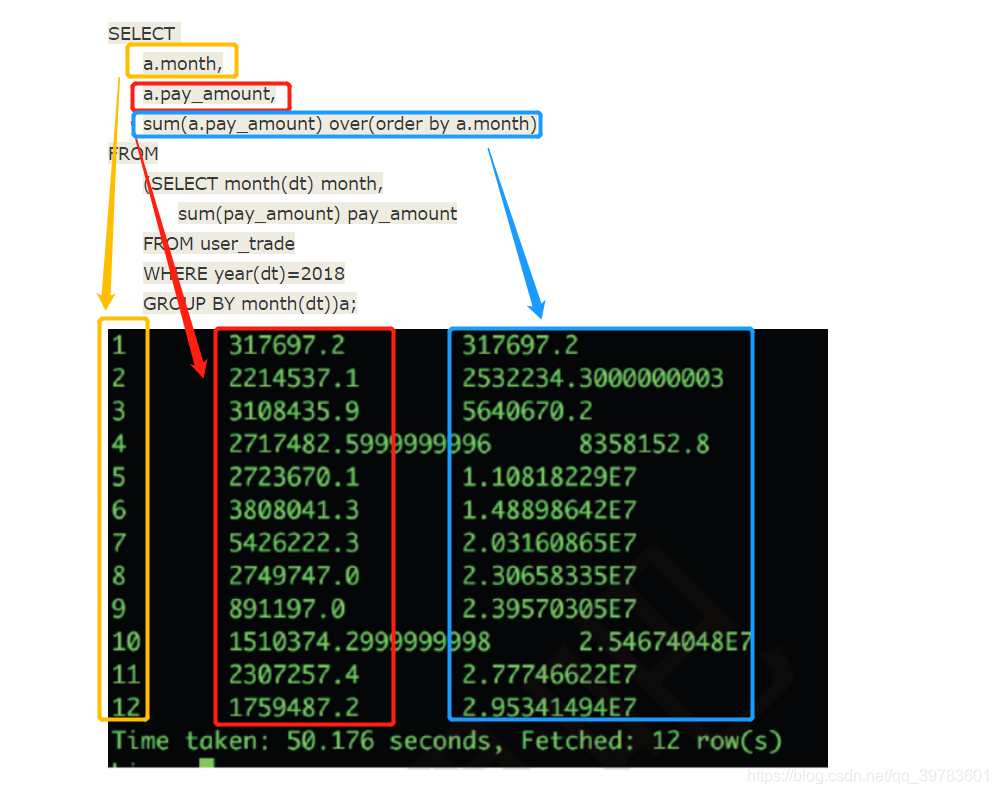
SELECT a.year year,
a.month month,
a.pay_amount pay_amount,
sum(a.pay_amount) over(partition by a.year order by sum_pay_amount
a.month )
FROM
(SELECT year(dt) year,
month(dt) month,
sum(pay_amount) pay_amount
FROM user_trade
WHERE year(dt) in (2017,2018)
GROUP BY year(dt),
month(dt))a;
SQL解析:
子查询中:按照年和月进行分组GROUP BY year(dt),month(dt),年份选择year(dt) in (2017,2018),要查询的是年,月和支付在总额。
外层查询:
前三列查询年,月,支付总额,第四列就是开窗函数,与需求1-1相比多了个partition by a.year,也就是要根据year进行分组/分区,目的就是将2017年的数据和2018年的数据分两个去汇总展示。
下图中可以看到,2017年和2018年分两个区展示累计月度支付总额。
说明:
1、partition by起到了分组的作用
2、order by 按照什么顺序进行累加,升序ASC、降序DESC,默认升序
(2)avg(…) over(……)
移动平均值
大家看股票的时候,经常会看到这种K线图吧,里面经常用到的就是7日、
30日移动平均的趋势图,那如何使用窗口函数来计算移动平均值呢?
对移动平均值的理解:

需求2:
对2018年每个月的近三个月进行移动地求平均支付金额。
SELECT
a.MONTH MONTH,
a.pay_amount pay_amount,
avg( a.pay_amount ) over ( ORDER BY a.MONTH rows BETWEEN 2 preceding AND current ROW ) avg_pay_amount
FROM
(
SELECT MONTH( dt ) MONTH,
sum( pay_amount ) pay_amount
FROM
user_trade
WHERE
YEAR ( dt )= 2018
GROUP BY
MONTH ( dt )) a;
SQL解析:
子查询中:查询2018年的月份和支付金额,按照月份分组,给子查询命名为a
外层查询中:查询a表中的month,pay_mount,以及用到的窗口函数,计算近三个月进行移动地求平均支付金额。
因为计算的平均值,所以用到了avg函数。
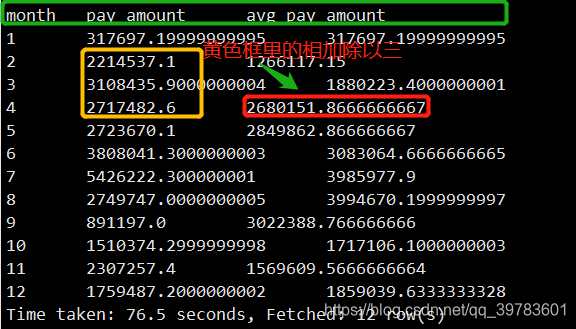
我们列举4月份的数据看下:
4月的移动平均数是2680151.8666666667,它是怎么来的呢?2680151.8666666667=(2214537.1+3108435.9000000004+2717482.6)/3
SQL中的开窗函数:avg( a.pay_amount ) over ( ORDER BY a.MONTH rows BETWEEN 2 preceding AND current ROW )是什么意思呢?
答:根据month逐渐递增计算移动平均数,这里每个月的移动平均数等于前两个月的支付总额加本月的支付总额除以三。
说明:
我们用rows between 2 preceding and current row来限制计算移动平均
的范围,本语句含义是包含本行及前两行,这个就是我们题目中要求的近
三月的写法。
(3)语法总结:
sum(…A…) over(partition by …B… order by …C… rows between … D1… and …D2…)
avg(…A…) over(partition by …B… order by …C… rows between …D1…and …D2…)
A:需要被加工的字段名称
B:分组的字段名称
C:排序的字段名称
D:计算的行数范围
rows between unbounded preceding and current row ——包括本行和之前所有的行
rows between current row and unbounded following ——包括本行和之后所有的行
rows between 3 preceding and current row ——包括本行以内和前三行
rows between 3 preceding and 1 following ——从前三行到下一行(5行)
unbounded preceding——之前所有的行
current row——本行
3 preceding——前三行
unbounded following——之后所有的行
1 following——下一行
拓展:
max(……) over(partition by …… order by …… rows between …… and ……)
min(……) over(partition by …… order by …… rows between …… and ……)
2、分区排序窗口函数
row_number() over(……)
rank() over(……)
dense_rank() over(……)
这三个函数的作用都是返回相应规则的排序序号
row_number() over(partition by …A… order by …B… )
rank() over(partition by …A… order by …B… )
dense_rank() over(partition by …A… order by …B… )
A:分组的字段名称
B:排序的字段名称
注意:
row_number()的这个括号内是不加任何字段名称的,rank() 和dense_rank() 同理。
row_number:它会为查询出来的每一行记录生成一个序号,依次排序且不会重复。
rank&dense_rank:dense_rank函数出现相同排名时,将不跳过相同排名号,rank值紧接上一次的rank值。在各个分组内,rank()是跳跃排序,有两个第一名时接下来就是第三名,dense_rank()是连续排序,有两个第一名时仍然跟着第二名。
我们通过一个需求来理解一下分区排序窗口函数:
需求3:
对2019年1月份用户的购买爱好进行分析。
我们要查不同用户购买商品的爱好,我们可以查询用户购买商品品类数量的排名,以此来进行的分析用户的爱好。
SELECT
user_name,
count( DISTINCT goods_category ) goods_num,
row_number () over (ORDER BY count( DISTINCT goods_category)) row_number,
rank () over (ORDER BY count( DISTINCT goods_category )) rank,
dense_rank () over (ORDER BY count( DISTINCT goods_category)) dense_rank
FROM
user_trade
WHERE
substr( dt, 1, 7 )= '2019-01'
GROUP BY
user_name;
SQL解析:
substr 是字符串截取。我们要查不同用户,所以要根据用户进行分组。
查询用户名user_name,商品种类数goods_num,以及对应商品种类的窗口排序。
这里用到分区排序窗口函数row_number (),rank ()和dense_rank (),还有我们要根据商品种类递增进行分组后再排序。
我们通过查询结果看下具体分区排序窗口函数的作用:
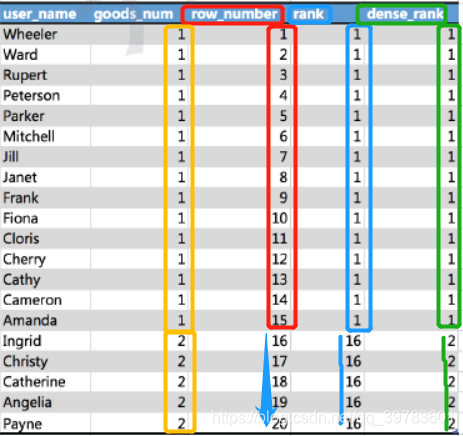
在查询结果中我们可以看到:
- 当商品种类是两类时,row_number是依次排序并且不会重复;
- 当商品种类是1类的时候,rank 的排序序号都是1,但如果是两类商品时,rank就变为了序号16,因为rank()是跳跃排序,当遇到不同类时,它的排序会根据实际多少排名的下一名开始排序,也就是有两个第一名时接下来就是第三名;
- dense_rank 和rank一样相同种类时他的排名不会发生改变,但是当商品种类为两类时,dense_rank会跟着前面的排名向下继续排序,也就是有两个第一名时仍然跟着第二名。
需求4:
选出2019年支付金额排名在第10、20、30名的用户。
SELECT
a.user_name,
a.pay_amount,
a.dr
FROM
(
SELECT
user_name,
sum( pay_amount ) pay_amount,
dense_rank () over ( ORDER BY sum( pay_amount ) DESC ) dr
FROM
user_trade
WHERE
YEAR ( dt )= 2019
GROUP BY
user_name
) a
WHERE
a.dr IN ( 10, 20, 30 );
3、分组排序窗口函数
ntile(n) over(……)
ntile(n) over(partition by …A… order by …B… )
n:切分的片数
A:分组的字段名称
B:排序的字段名称
NTILE(n):用于将分组数据按照顺序切分成n片,返回当前切片值
NTILE不支持ROWS BETWEEN,比如 NTILE(2) OVER(PARTITION BY …… ORDER BY …ROWS BETWEEN 3 PRECEDING AND CURRENT ROW)
如果切片不均匀,默认增加到第一个切片的分布
需求5:
将2019年1月的支付用户,按照支付金额分成5组。
SELECT user_name,
sum(pay_amount) pay_amount,
ntile(5) over(order by sum(pay_amount) desc) level
FROM user_trade
WHERE substr(dt,1,7)='2019-01'
GROUP BY user_name;
SQL解析:
ntile(5) 分成5组,按照总的支付金额进行降序排序。
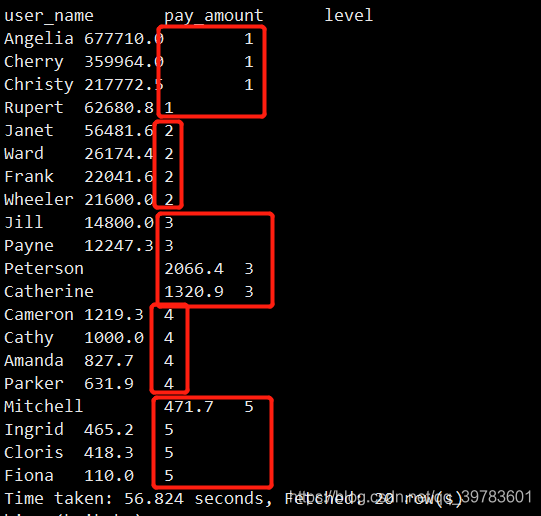
结果分成5组,就是5个等级,第一级有4个人,第二级也有4个人…结果返回的是他们的等级。这里因为分成5组刚好很均匀,我们将切片改为6看看结果:
SELECT user_name,
sum(pay_amount) pay_amount,
ntile(6) over(order by sum(pay_amount) desc) level
FROM user_trade
WHERE substr(dt,1,7)='2019-01'
GROUP BY user_name;
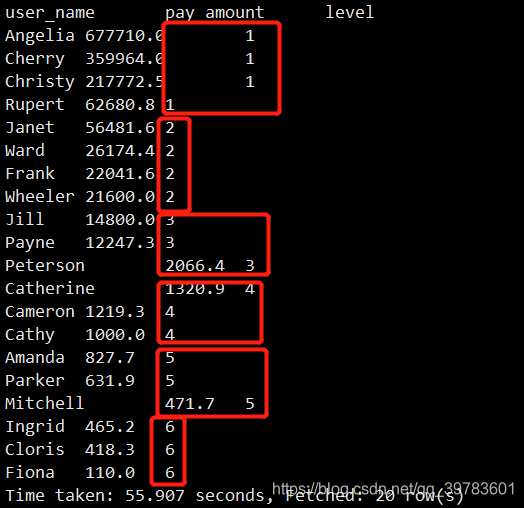
如果是ntile(6)的话,结果每个等级个数就被分成了443333
需求6:
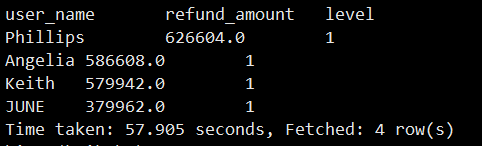
选出2019年退款金额排名前10%的用户。
SELECT
a.user_name user_name,
a.refund_amount refund_amount,
a.level level
FROM
(SELECT user_name,
sum(refund_amount) refund_amount,
ntile(10) over(order by sum(refund_amount)desc) level
FROM user_refund
WHERE year(dt)=2019
GROUP BY user_name)a
WHERE a.level=1;
SQL解析:
子查询中:我们查询退款总额,以及退款金额前10%并且根据退款总金额的降序排序的用户。
refund_piece——退款件数
refund_amount ——退款金额
ntile(10) over(order by sum(refund_amount)desc) level 这里ntile(10)就是代表10%,分成10组每组就是10%
4、偏移分析窗口函数
Lag和Lead分析函数可以在同一次查询中取出同一字段的前N行的数据(Lag)和后N行的数据(Lead)作为独立的列。
在实际应用当中,若要用到取今天和昨天的某字段差值时,Lag和Lead函数的应用就显得尤为重要。当然,这种操作可以用表的自连接实现,但是LAG和LEAD与left join、right join等自连接相比,效率更高,SQL更简洁。
lag(exp_str,offset,defval) over(partion by ……order by ……)
lead(exp_str,offset,defval) over(partion by ……order by ……)
exp_str是字段名称
offset是偏移量,即是上1个或上N个的值,假设当前行在表中排在第5行,则offset 为3,则表示我们所要找的数据行就是表中的第2行(即5-3=2)。offset默认值为1。
defval默认值,当这两个函数取上N/下N个值,当在表中从当前行位置向前数N行已经超出了表的范围时,lag()函数将defval这个参数值作为函数的返回值,若没有指定默认值,则返回NULL,那么在数学运算中,总要给一个默认值才不会出错。
lag()实例:
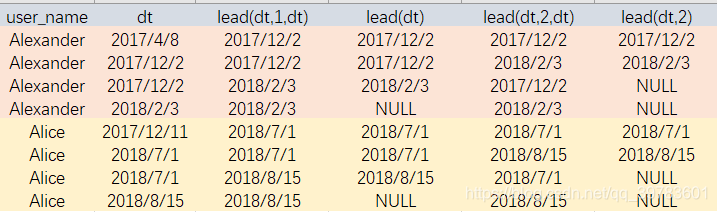
查看Alice和Alexander的各种时间偏移
SELECT
user_name,dt,
lag(dt,1,dt) over(partition by user_name order by dt),
lag(dt) over(partition by user_name order by dt),
lag(dt,2,dt) over(partition by user_name order by dt),
lag(dt,2) over(partition by user_name order by dt)
FROM user_trade
WHERE dt>'0' and user_name in ('Alice','Alexander');
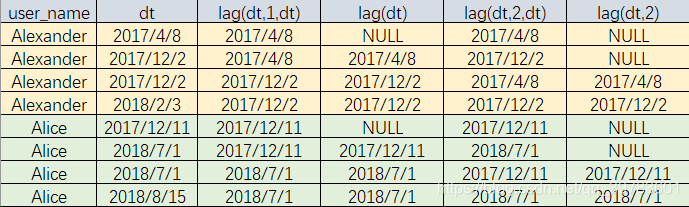
我们以Alexander为例来看下:


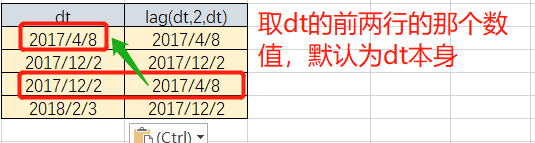
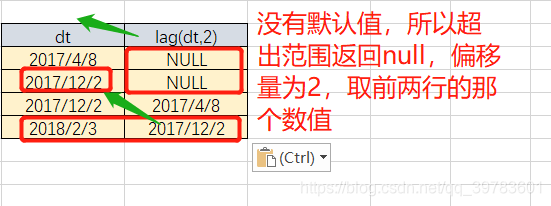
关键是看有没有偏移量,有没有默认值。
lead()就是取后几行的数值。
lead()实例:
查看Alice和Alexander的各种时间偏移
SELECT user_name,dt,
lead(dt,1,dt) over(partition by user_name order by
dt),
lead(dt) over(partition by user_name order by dt),
lead(dt,2,dt) over(partition by user_name order by dt),
lead(dt,2) over(partition by user_name order by dt)
FROM user_trade
WHERE dt>'0'
and user_name in ('Alice','Alexander');
练习
做点练习吧!!!
需求7:
支付时间间隔超过100天的用户数【跨时间潜在VIP用户流失分析】
SELECT count(distinct user_name)
FROM
(SELECT user_name,dt,
lead(dt) over(partition by user_name order by dt) as lead_dt
FROM user_trade
WHERE dt>'0' )a
WHERE a.lead_dt is not null
and datediff(a.lead_dt,a.dt)>100;
SQL解析:
计算支付时间间隔我们用lead_dt和dt相差时间来算, datediff是用来计算时间间隔。
需求8:
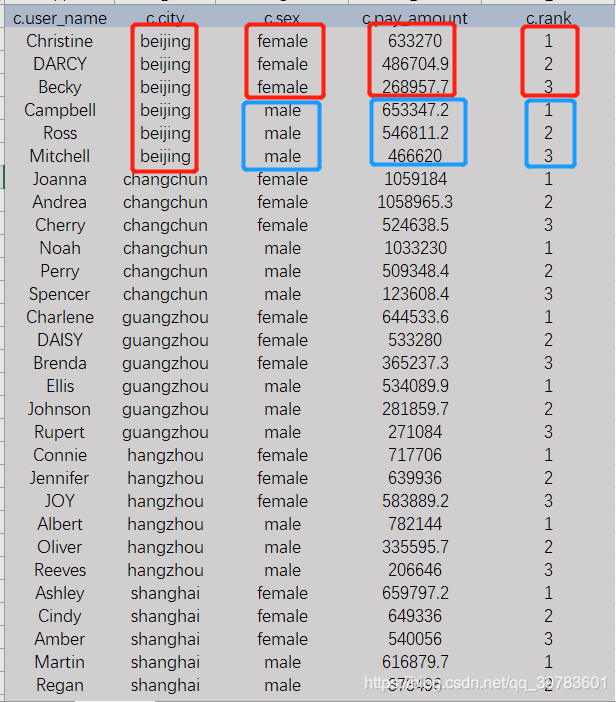
每个城市,不同性别,2018年支付金额最高的TOP3用户。
SELECT c.user_name,
c.city,
c.sex,
c.pay_amount,
c.rank
FROM
(SELECT a.user_name,
b.city,
b.sex,
a.pay_amount,
row_number() over(partition by b.city,b.sex order by a.pay_amount desc) rank
FROM
(SELECT user_name,
sum(pay_amount) pay_amount
FROM user_trade
WHERE year(dt)=2018
GROUP BY user_name)a
LEFT JOIN user_info b
on a.user_name=b.user_name)c
WHERE c.rank<=3;
SQL解析:
我们看sql需要从里向外看,分析需求也是需要我们一个一个往出扣指标。
子查询c表中,我们查出了用户名user_name,支付金额pay_amount,并且我们通过连接用户信息表user_info 可以查出城市,性别这些信息。
row_number() over(partition by b.city,b.sex order by a.pay_amount desc) rank
这句的意思是我们依据row_number()进行排序,对城市和性别分组后的值进行排序,支付金额降序排列。
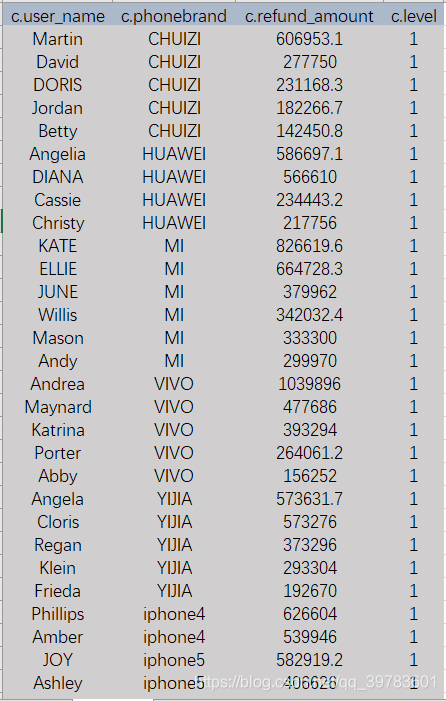
需求9:
每个手机品牌退款金额前25%的用户【跨手机品牌用户退款分析】
SELECT *
FROM
(SELECT a.user_name,
extra2['phonebrand'] as phonebrand,
a.refund_amount,
ntile(4) over(partition by extra2['phonebrand'] order by a.refund_amount desc) level
FROM
(SELECT user_name,
sum(refund_amount) refund_amount
FROM user_refund
WHERE dt>'0'
GROUP BY user_name)a
LEFT JOIN user_info b
on a.user_name=b.user_name)c
WHERE c.level=1;
SQL解析:
ntile(4) over(partition by extra2[‘phonebrand’] order by a.refund_amount desc) level
这句话的意思是:将结果分为4组,计算25%即ntile(4)
根据 extra2[‘phonebrand’] 进行分组,退款金额refund_amount 降序排列
dt>‘0’ 是查看所有分区
dt 是一个分区字段,extra2存放的是map类型的数据,根据phonebrand找出对应手机品牌
总结:
1、注意如何对sum()、avg()这类累计计算的窗口函数的行数限制。
2、不要混淆row_number()、rank()、dense_rank()三种函数。
3、会使用ntile()进行分组查询。
4、lag():前N行、lead():后N行。
5、总结Hive中窗口函数的用法。
