paper地址:
Distributed Representations of Words and Phrases and their Compositionality-Tomas Mikolov
翻译:
发布的连续型Skip-gram,对于学习高质量分布式向量表述,是一个非常搞笑的模型,它描述了大量精确的语法语义方面的词语关系。在这篇论文中,我们将陈述数个延展,将会推进向量的质量和训练速度。通过对于高频词的二次抽样,我们获得了巨大的速度提升,同时也能够学会更为规范的词语表达。一个分层softmax函数的替代品——负例采样也将会被介绍。
一个词语表达的内在局限表现在它们忽视了词语在句子中的顺序,它们也不能够表达俚语。就比如,“Canada"和"Air"两个词不能轻易得到"Air Canada”(加拿大航空公司)这样的意思。基于这个例子,我们将介绍一个在文中查找词组的简单方法,并会证明,获得大量句子良好的向量表示这件事是可能的。
最近,马尔可夫介绍了Skip-gram模型,它是一个从大量杂乱无章的文本数据中学习到高质量词向量表示的行之有效的方法。不像大多数先前被运用于词向量学习的神经网络架构,Skip-gram模型的训练(图1)并不包含稠密的向量乘法。这使得训练过程是极其高效的:一个优化的单机实现能够在一天内在超过1000亿的单词上进行训练。
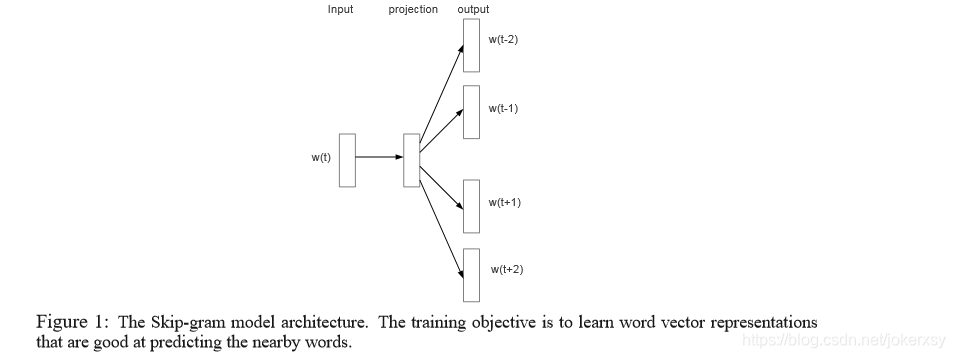
使用神经网络计算得出的词语表达非常有意思,因为学习过的向量能够精确地对许多语言学上的规律和模式进行编译。令人惊讶的是,这些模式中的许多都能够被看作是线性的。举个例子,向量计算"Madrid" - “Spain” + “France"的结果比任何其他词向量都接近于向量"Paris”。
在这篇论文中,我们会陈述数个初代Skip-gram模型的延伸。我们将证实训练中,高频词的二次采样会导致巨大的速度飞跃(大约2倍到10倍),也会改善低频单词表达的精确性。另外,我们发现,与使用在先前工作的更为复杂的分层softmax方法相比,一个噪声对比评估(NCE)的简化变体对于训练Skip-gram模型来说,能够产生更快的训练和更好的高频词的向量表示。
词语表示限制于它们并不能表示俗语,那些俗语并不是由个体单词组成。比如,"Boston Globe"是一个报纸,所以它不是一个"Boston"和"Globe"意思的天然组合。因此,使用向量去表示整个短语使得Skip-gram(以下简称sg)模型更富有表现力。其他用于表达词向量组成的句意的工具(如递归自动编译器),也将会受益于使用词组向量,而不是单词向量。
从基于单词到基于词组模型的延伸是相对简单的。首先,我们使用一个依照数据处理的方法来识别大量的短语,我们在训练中将这些短语看作是独立的符号。为了评估短语向量的质量,我们开发了一个包含词语和短语的类比推理任务测试集。测试集中一个典型的类比队是“Montreal”:“MontrealCanadiens”::“Toronto”:“TorontoMaple
Leafs”。很显然, 与vec(“Montreal Canadiens”) - vec(“Montreal”) + vec(“Toronto”)最接近的表示是vec(“Toronto Maple Leafs”)。
最后,我们描述另外一个sg模型的有趣的性能。我们发现,简单的向量加法经常会产生有意义的结果。比如,vec(“Russia”) + vec(“river”) 接近于vec(“Volga River”), 以及 vec(“Germany”) + vec(“capital”) 接近于vec(“Berlin”)。这样的语意合成性表明:在词向量表示上采取基础的数学计算,我们就可以达到一个并不明显的语言理解程度。
