一、背景
应用的使用流畅度,是衡量用户体验的重要标准之一。Android 由于机型配置和系统的不同,项目复杂App场景丰富,代码多人参与迭代历史较久,代码可能会存在很多UI线程耗时的操作,实际测试时候也会偶尔发现某些业务场景发生卡顿的现象,用户也经常反馈和投诉App使用遇到卡顿。因此,我们越来越关注和提升用户体验的流畅度问题。
二、方案
基于这样的痛点,我们希望能使用一套有效的检测机制,能够覆盖各种可能出现的卡顿场景,一旦发生卡顿,能帮助我们更方便地定位耗时卡顿发生的地方,记录下具体的信息和堆栈,直接从代码程度给到开发定位卡顿问题。我们设想的Android卡顿监控系统需要达到几项基本功能:
-
如何有效地监控到App发生卡顿,同时在发生卡顿时正确记录app的状态,如堆栈信息,CPU占用,内存占用,IO使用情况等等;
-
统计到的卡顿信息上报到监控平台,需要处理分析分类上报内容,并通过平台Web直观简便地展示,供开发跟进处理。
三、如何从App层面监控卡顿?
我们的思路是,一般主线程过多的UI绘制、大量的IO操作或是大量的计算操作占用CPU,导致App界面卡顿。只要我们能在发生卡顿的时候,捕捉到主线程的堆栈信息和系统的资源使用信息,即可准确分析卡顿发生在什么函数,资源占用情况如何。那么问题就是如何有效检测Android主线程的卡顿发生,目前业界两种主流有效的app监控方式如下:
-
利用UI线程的Looper打印的日志匹配;
-
使用Choreographer.FrameCallback。
3.1、利用UI线程的Looper打印的日志匹配判断是否卡顿
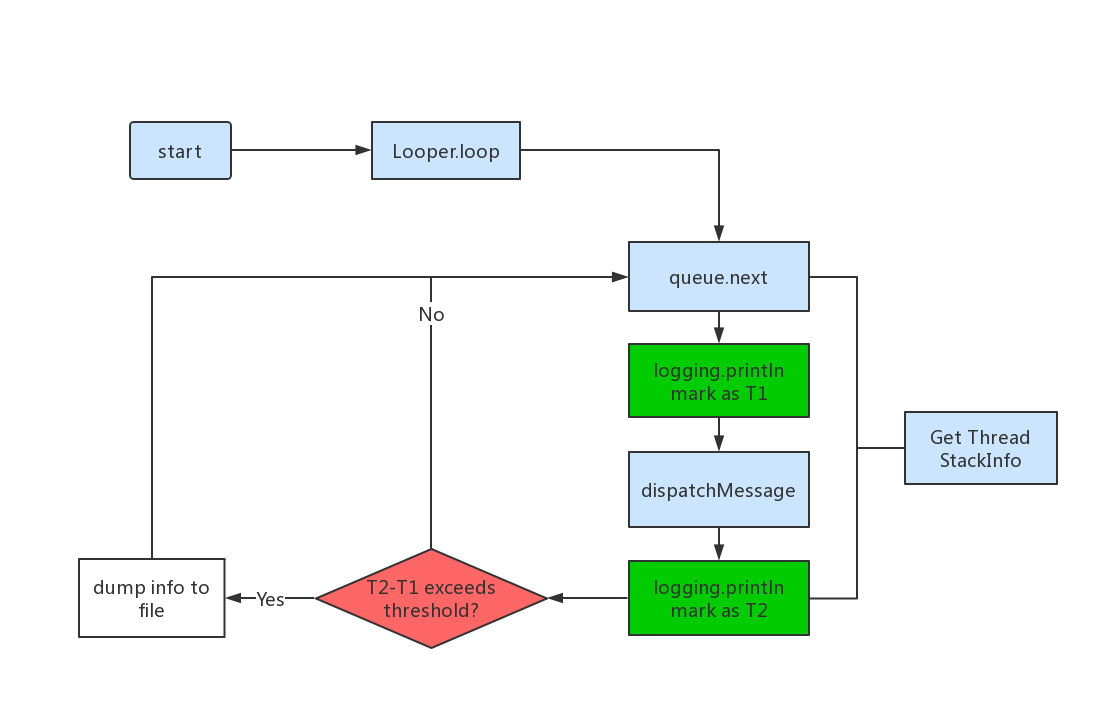
Android主线程更新UI。如果界面1秒钟刷新少于60次,即FPS小于60,用户就会产生卡顿感觉。简单来说,Android使用消息机制进行UI更新,UI线程有个Looper,在其loop方法中会不断取出message,调用其绑定的Handler在UI线程执行。如果在handler的dispatchMesaage方法里有耗时操作,就会发生卡顿。
3.1.1、Looper.loop( )的源码
public static void loop() {
final Looper me = myLooper();
if (me == null) {
throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread.");
}
final MessageQueue queue = me.mQueue;
// Make sure the identity of this thread is that of the local process,
// and keep track of what that identity token actually is.
Binder.clearCallingIdentity();
final long ident = Binder.clearCallingIdentity();
for (;;) {
Message msg = queue.next();
// might block
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
// This must be in a local variable, in case a UI event sets the logger
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
// Make sure that during the course of dispatching the
// identity of the thread wasn't corrupted.
final long newIdent = Binder.clearCallingIdentity();
if (ident != newIdent) {
Log.wtf(TAG, "Thread identity changed from 0x"
+ Long.toHexString(ident) + " to 0x"
+ Long.toHexString(newIdent) + " while dispatching to "
+ msg.target.getClass().getName() + " "
+ msg.callback + " what=" + msg.what);
}
msg.recycleUnchecked();
}
}
只要检测第25行代码msg.target.dispatchMessage(msg) 的执行时间,就能检测到部分UI线程是否有耗时的操作。注意到这行执行代码的前后,有两个logging.println函数,如果设置了logging,会分别打印出”>>>>> Dispatching to “和”<<<<< Finished to “这样的日志,这样我们就可以通过两次log的时间差值,来计算dispatchMessage的执行时间,从而设置阈值判断是否发生了卡顿。
3.1.2、如何设置logging呢?
我们看第19行代码me.mLogging源码
public final class Looper {
private Printer mLogging;
public void setMessageLogging(@Nullable Printer printer) {
mLogging = printer;
}
}
public interface Printer {
void println(String x);
}
Looper的mLogging是私有的,并且提供了setMessageLogging(@Nullable Printer printer)方法,所以我们可以自己实现一个Printer,在通过setMessageLogging()方法传入即可,代码如下:
public class BlockDetectByPrinter {
public static void start() {
Looper.getMainLooper().setMessageLogging(new Printer() {
private static final String START = ">>>>> Dispatching";
private static final String END = "<<<<< Finished";
@Override
public void println(String x) {
if (x.startsWith(START)) {
LogMonitor.getInstance().startMonitor();
}
if (x.startsWith(END)) {
LogMonitor.getInstance().removeMonitor();
}
}
});
}
}
设置了logging后,loop方法会回调logging.println打印出每次消息执行的时间日志:”>>>>> Dispatching to “和”<<<<< Finished to “。BlockDetectByPrinter的使用则在Application的onCreate方法中调用 BlockDetectByPrinter.start() 即可。
我们可以简单实现一个LogMonitor来记录卡顿时候主线程的堆栈信息。当匹配到>>>>> Dispatching时,执行startMonitor,会在1000ms(设定的卡顿阈值)后执行任务,这个任务负责在子线程(非UI线程)打印UI线程的堆栈信息。如果消息低于1000ms内执行完成,就可以匹配到<<<<< Finished日志,那么在打印堆栈任务启动前执行removeMonitor取消了这个任务,则认为没有卡顿的发生;如果消息超过1000ms才执行完毕,此时认为发生了卡顿,并打印UI线程的堆栈信息。
3.1.3、LogMonitor如何实现?
public class LogMonitor {
private static LogMonitor sInstance = new LogMonitor();
private HandlerThread mLogThread = new HandlerThread("log");
private Handler mIoHandler;
private static final long TIME_BLOCK = 1000L;
private LogMonitor() {
mLogThread.start();
mIoHandler = new Handler(mLogThread.getLooper());
}
private static Runnable mLogRunnable = new Runnable() {
@Override
public void run() {
StringBuilder sb = new StringBuilder();
StackTraceElement[] stackTrace = Looper.getMainLooper().getThread().getStackTrace();
for (StackTraceElement s : stackTrace) {
sb.append(s.toString() + "\n");
}
Log.e("TAG", sb.toString());
}
};
public static LogMonitor getInstance() {
return sInstance;
}
public boolean isMonitor() {
return mIoHandler.hasCallbacks(mLogRunnable);
}
public void startMonitor() {
mIoHandler.postDelayed(mLogRunnable, TIME_BLOCK);
}
public void removeMonitor() {
mIoHandler.removeCallbacks(mLogRunnable);
}
}
这里我们使用HandlerThread来构造一个Handler,HandlerThread继承自Thread,实际上就一个Thread,只不过比普通的Thread多了一个Looper,对外提供自己这个Looper对象的getLooper方法,然后创建Handler时将HandlerThread中的looper对象传入。这样我们的mIoHandler对象就是与HandlerThread这个非UI线程绑定的了,它处理耗时操作将不会阻塞UI。如果UI线程阻塞超过1000ms,就会在子线程中执行mLogRunnable,打印出UI线程当前的堆栈信息,如果处理消息没有超过1000ms,则会实时的remove掉这个mLogRunnable任务。
发生卡顿时打印出堆栈信息的大致内容如下,开发可以通过log定位耗时的地方。
优点:用户使用app或者测试过程中都能从app层面来监控卡顿情况,一旦出现卡顿能记录app状态和信息, 只要dispatchMesaage执行耗时过大都会记录下来,不再有前面两种adb方式面临的问题与不足。
缺点:需另开子线程获取堆栈信息,会消耗少量系统资源。
在实际实现中,不同手机不同Android系统甚至是不同的ROM版本,Loop函数不一定都能打印出”>>>>> Dispatching to “和”<<<<< Finished to “这样的日志,导致该方式无法进行。
优化的策略:我们知道Loop函数开始和结束必会执行println打印日志,所以优化版本将卡顿的判断改为,Loop输出第一句log时当作startMonitor,输出下一句log时当作end时刻来解决这个问题。
3.2、利用Choreographer.FrameCallback监控卡顿
Choreographer.FrameCallback官方文档链接(https://developer.android.com/reference/android/view/Choreographer.FrameCallback.html)
我们知道, Android系统每隔16ms发出VSYNC信号,来通知界面进行重绘、渲染,每一次同步的周期为16.6ms,代表一帧的刷新频率。SDK中包含了一个相关类,以及相关回调。理论上来说两次回调的时间周期应该在16ms,如果超过了16ms我们则认为发生了卡顿,利用两次回调间的时间周期来判断是否发生卡顿(这个方案是Android 4.1 API 16以上才支持)。
这个方案的原理主要是通过Choreographer类设置它的FrameCallback函数,当每一帧被渲染时会触发回调FrameCallback, FrameCallback回调void doFrame (long frameTimeNanos)函数。一次界面渲染会回调doFrame方法,如果两次doFrame之间的间隔大于16.6ms说明发生了卡顿。
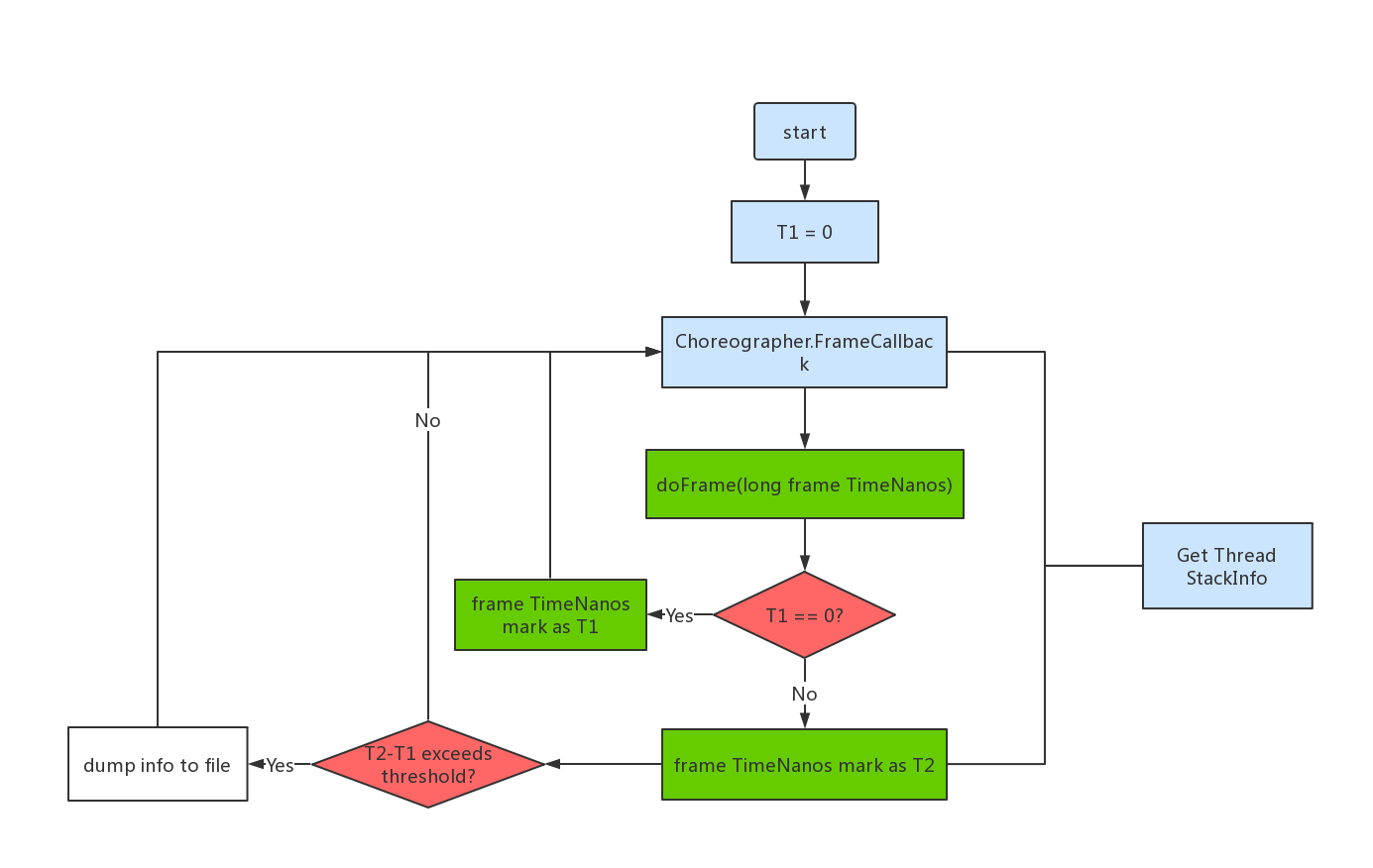
public class BlockDetectByChoreographer {
public static void start() {
Choreographer.getInstance().postFrameCallback(new Choreographer.FrameCallback() {
long lastFrameTimeNanos = 0;
long currentFrameTimeNanos = 0;
@Override
public void doFrame(long frameTimeNanos) {
if(lastFrameTimeNanos == 0){
lastFrameTimeNanos == frameTimeNanos;
}
currentFrameTimeNanos = frameTimeNanos;
long diffMs = TimeUnit.MILLISECONDS.convert(currentFrameTimeNanos-lastFrameTimeNanos, TimeUnit.NANOSECONDS);
if (diffMs > 16.6f) {
long droppedCount = (int)diffMs / 16.6;
}
if (LogMonitor.getInstance().isMonitor()) {
LogMonitor.getInstance().removeMonitor();
}
LogMonitor.getInstance().startMonitor();
Choreographer.getInstance().postFrameCallback(this);
}
});
}
}
在每一帧被渲染时,记下了渲染的时间用来计算掉帧数,数据可以绘制出流畅度曲线;同时,获取isMonitor()函数判断上一帧LogMonitor已经启动打印堆栈的任务,如果已启动,则移除LogMonitor,此时如果上一帧渲染的时间到现在已经超过了阈值,则已经执行了任务打印堆栈出来了;如果没有超过阈值则及时移除了任务。如果isMonitor返回false,没有LogMonitor回调任务,则开始新的一帧的监控任务。
优点:不仅可用来从app层面来监控卡顿,同时可以实时计算帧率和掉帧数,实时监测App页面的帧率数据,一旦发现帧率过低,可自动保存现场堆栈信息。
缺点:需另开子线程获取堆栈信息,会消耗少量系统资源。
3.3、总结下上述两种方案的对比情况:
| Looper.loop | Choreographer.FrameCallback | |
|---|---|---|
| 监控是否卡顿 | √ | √ |
| 支持静态页面卡顿检测 | √ | √ |
| 支持计算帧率 | X | √ |
| 支持获取App运行信息 | √ | √ |
实际项目使用中,我们一开始两种监控方式都用上,上报的两种方式收集到的卡顿信息我们分开处理,发现卡顿的监控效果基本相当。同一个卡顿发生时,两种监控方式都能记录下来。 由于Choreographer.FrameCallback的监控方式不仅用来监控卡顿,也方便用来计算实时帧率,因此我们现在只使用Choreographer.FrameCallback来监控app卡顿情况。
四、如何保证捕获卡顿堆栈的准确性?
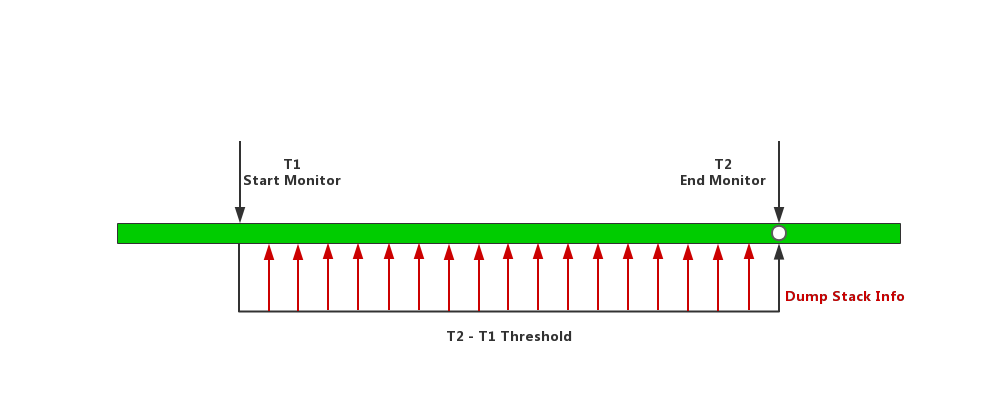
细心的同学可以发现,我们通过上述两种方案(Looper.loop和Choreographer.FrameCallback)可以判断是当前主线程是否发生了卡顿,进而在计算发现卡顿后的时刻dump下了主线程的堆栈信息。实际上,通过一个子线程,监控主线程的活动情况,计算发现超过阈值后dump下主线程的堆栈,那么生成的堆栈文件只是捕捉了一个时刻的现场快照。打个不太恰当的比方,相当于闭路电视监控只拍下了凶案发生后的惨状,而并没有录下这个案件发生的过程,那么作为警察的你只看到了结局,依然很难判断案情和凶手。在实际的运用中,我们也发现这种方式下获取到的堆栈情况,查看相关的代码和函数,经常已经不是发生卡顿的代码了。
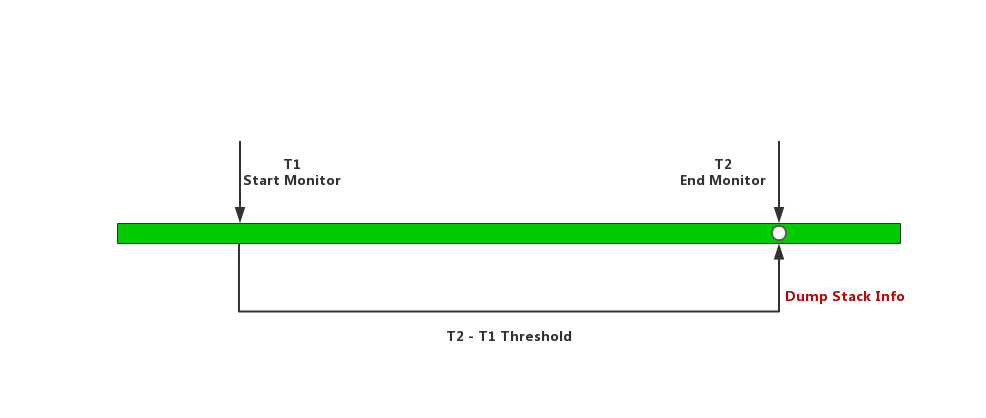
如图所示,主线程在T1~T2时间段内发生卡顿,上述方案中获取卡顿堆栈的时机已经是T2时刻。实际卡顿可能是这段时间内某个函数的耗时过大导致卡顿,而不一定是T2时刻的问题,如此捕获的卡顿信息就无法如实反应卡顿的现场。
我们看看在这之前微信iOS主线程卡顿监控系统是如何实现的捕获堆栈。微信iOS的方案是起检测线程每1秒检查一次,如果检测到主线程卡顿,就将所有线程的函数调用堆栈dump到内存中。本质上,微信iOS方案的计时起点是固定的,检查次数也是固定的。如果任务1执行花费了较长的时间导致卡顿,但由于监控线程是隔1秒扫一次的,可能到了任务N才发现并dump下来堆栈,并不能抓到关键任务1的堆栈。这样的情况的确是存在的,只不过现上监控量大走人海战术,通过概率分布抓到卡顿点,但依然不是最佳的捕获方案。
因此,摆在我们面前的是如何更加精准地获取卡顿堆栈。为了卡顿堆栈的准确度,我们想要能获取一段时间内的堆栈,而不是一个点的堆栈,如下图:
我们采用高频采集的方案来获取一段卡顿时间内的多个堆栈,而不再是只有一个点的堆栈。这样的方案的优点是保证了监控的完备性,整个卡顿过程的堆栈都得以采样、收集和落地。
具体做法是在子线程监控的过程中,每一轮log输出或是每一帧开始启动monitor时,我们便已经开启了高频采样收集主线程堆栈的工作了。当下一轮log或者下一帧结束monitor时,我们判断是否发生卡顿(计算耗时是否超过阈值),来决定是否将内存中的这段堆栈集合落地到文件存储。也就是说,每一次卡顿的发生,我们记录了整个卡顿过程的多个高频采样堆栈。由此精确地记录下整个凶案发生的详细过程,供上报后分析处理(后文会阐述如何从一次卡顿中多个堆栈信息中提取出关键堆栈)。
五、海量卡顿堆栈后该如何处理?
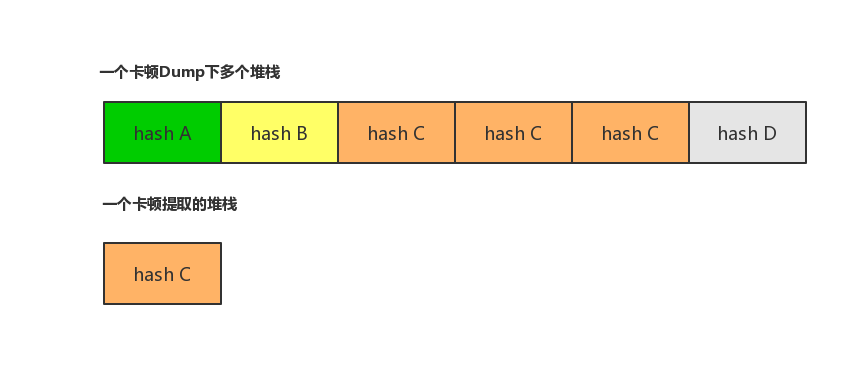
卡顿堆栈上报到平台后,需要对上报的文件进行分析,提取和聚类过程,最终展示到卡顿平台。前面我们提到,每一次卡顿发生时,会高频采样到多个堆栈信息描述着这一个卡顿。做个最小的估算,每天上报收集2000个用户卡顿文件,每个卡顿文件dump下了用户遇到的10个卡顿,每个卡顿高频收集到30个堆栈,这就已经产生20001030=60W个堆栈。按照这个量级发展,一个月可产生上千万的堆栈信息,每个堆栈还是几十行的函数调用关系。这么大量的信息对存储,分析,页面展示等均带来相当大的压力。很快就能撑爆存储层,平台无法展示这么大量的数据,开发更是没办法处理这些多的堆栈问题。因而,海量卡顿堆栈成为我们另外一个面对的难题。
在一个卡顿过程中,一般卡顿发生在某个函数的调用上,在这多个堆栈列表中,我们把每个堆栈都做一次hash处理后进行排重分析,有很大的几率会是dump到同一个堆栈hash,如下图: