hello大家好,上次学习了逻辑数据库设计(点击查看),今天我们来学习物理数据库设计。教妹学数据库,没见过这么酷炫的标题吧?“语不惊人死不休”,没错,标题就是这么酷炫。
我的妹妹小埋18岁,校园中女神一般的存在,成绩优异体育万能,个性温柔正直善良。然而,只有我知道,众人眼中光芒万丈的小埋,在过去是一个披着仓鼠斗篷,满地打滚,除了吃就是睡和玩的超级宅女。而这一切的转变,是从那一天晚上开始的。
从此之后,小埋经常让我帮她辅导功课。今天她想了解物理数据库设计。本篇教程通过我与小埋的对话的方式来谈一谈物理数据库设计。
物理数据库设计
设计步骤
-
设计步骤1:分析数据库负载
-
设计步骤2:选择关系数据库的存取方法
-
设计步骤3:设计关系数据库的物理存储结构
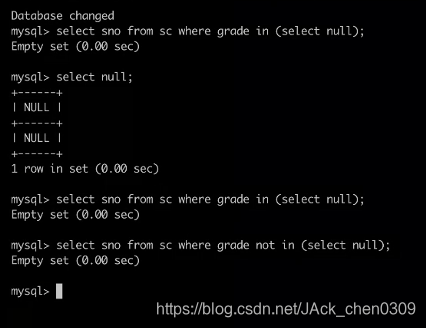
索引
- 构成
-
索引键(indexkey):索引根据一组属性(索引键)来定位元组
-
索引记录了元组的索引键值与元组地址的对应关系
-
索引项(indexentry):索引中的(键值,地址)对
-
索引中的索引项按索引键值排序
- 分类
-
主索引与二级索引,根据索引键是否是关系的主键
-
唯一索引与非唯一索引,根据索引键值是否重复
-
聚簇索引与非聚簇索引
聚簇索引:索引中存储的是元组本身。一个关系上只能有一个聚簇索引。
非聚簇索引:索引中存储的是元组地址
- 创建索引
-
创建主索引
-
创建二级索引
-
创建唯一索引
- 删除索引
索引的数据结构
B+树
- B+树是大多数RDBMS所使用的索引结构
- B+树是一棵平衡多叉树,所有叶节点的深度都相同
- 索引项全部存储在B+树的叶节点中,并按索引键值排序存储
B+树索引的限制
- 必须从索引的最左属性开始查找
SELECT*FROMStudentWHERESage=19;
不能在该索引上执行这个查询
- 条件中不能包含表达式
SELECT*FROMStudent
WHERESname='Elsa'AND2020-Sage=2000;在索引上只能根据条件Sname=’Elsa’进行查找,在返回的元组上验证条件2020-Sage=2000
- 不能跳过索引中的属性
SELECT*FROMStudent
WHERESname='Elsa'ANDSsex='F';在索引上只能根据条件Sname=’Elsa’进行查找,在返回的元组上验证条件Ssex=’F’
- 如果查询中有关于某个属性的范围查询,则其右边所有属性都无法使用索引查找
SELECT*FROMStudentWHERESname='Elsa'ANDSageBETWEEN18AND20ANDSsex='F';在索引上只能根据条件Sname=’Elsa’ANDSageBETWEEN18
AND20进行查找,在返回的元组上验证条件Ssex=’F’
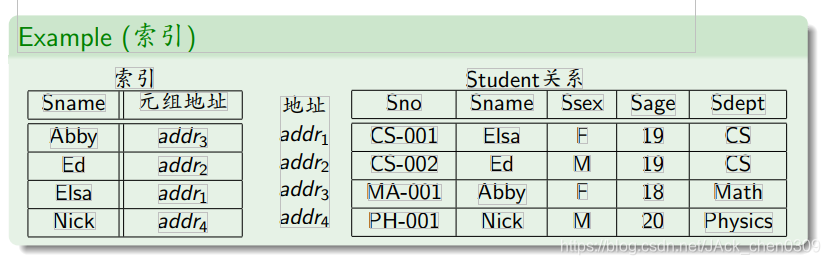
哈希索引
- 哈希索引是基于哈希表(hashtable)实现的
- 哈希表中的索引项是(索引键值的哈希值,元组地址)
- 哈希索引只支持对所有索引属性的精确匹配
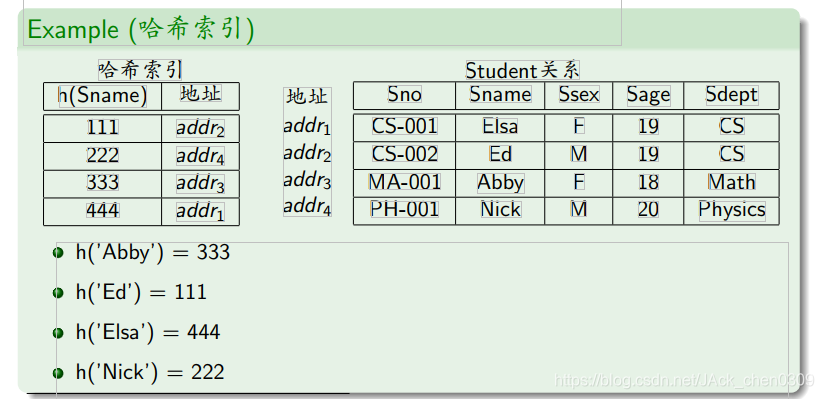
哈希索引的限制
- 哈希索引不支持部分索引属性匹配
SELECT*FROMStudentWHERESage=19;(不能使用索引)
- 哈希索引只支持等值比较查询(=,IN),不支持范围查询
SELECT*FROMStudentWHERESname='Elsa'AND
Sage<19ANDSsex='F';(不能使用索引)
- 哈希索引并不是按照索引值排序存储的,所以无法用于排序
- 哈希索引存在冲突问题
索引的设计过程
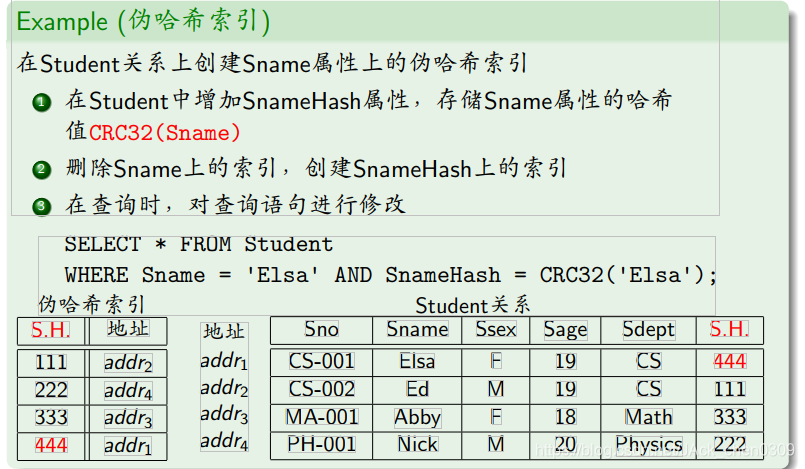
设计技巧1:伪哈希索引
尽管有些存储引擎不支持哈希索引,但我们可以模拟哈希索引。
- 优点: 查询速度快
- 缺点: 仅支持等值查询,不支持范围查询I需要改写查询
- 需要在数据更新时维护哈希值属性
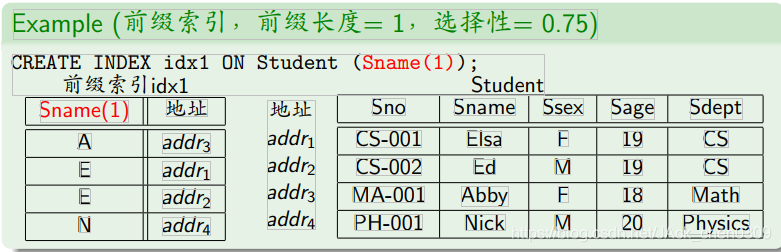
设计技巧2:前缀索引
- 当索引很长的字符串时,索引会变得很大,而且很慢。当字符串的前缀(prefix)具有较好的选择性时,可以只索引字符串的前缀

- 缺点
- 前缀索引不支持排序(ORDERBY)
- 前缀索引不支持分组查询(GROUPBY)
- 例子
设计技巧3:单个多属性索引vs.多个单属性索引


- 多个单属性索引的缺点
- 效率没有在单个多属性索引上做查询高
- 索引合并涉及排序,要消耗大量计算和存储资源
- 在查询优化时,索引合并的代价并不被计入,故“低估”了查询代价
设计技巧4: 索引属性的顺序
当不考虑排序(ORDERBY)和分组(GROUPBY)时,将选择性最高的属性放在最前面通常是好的,可以更快地过滤掉不满足条件的记录。
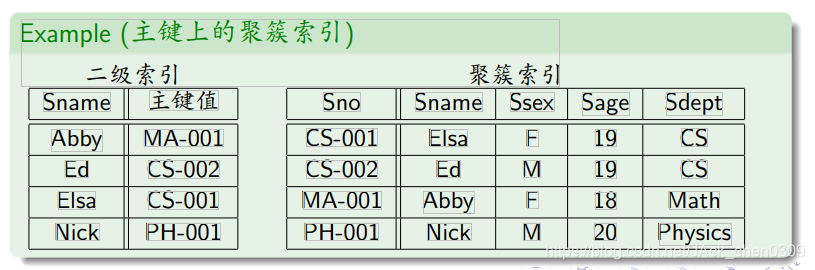
设计技巧5: 聚簇索引
- 优点
-
相关数据保存在一起,可以减少磁盘I/O
-
无需“回表”,数据访问更快
- 缺点
-
设计聚簇索引是为了提高I/O密集型应用的性能,如果数据全部在内存中,那么聚簇索引就没什么优势了
-
聚簇索引上元组插入的速度严重依赖于元组的插入顺序
-
更新聚簇索引键值的代价很高,需要将每个被更新的元组移动到新的位置
-
如果每条元组都很大,需要占用更多的存储空间,全表扫描变慢
设计技巧6: 覆盖索引
如果一个索引包含(覆盖)一个查询需要用到的所有属性,则称该索引为覆盖索引(coverageindex)
避免不合理地使用索引
一方面要设计好的索引,另一方面要避免不合理地使用索引
若不合理地使用索引,则不但不会让查询变快,反而会使查询变慢
查询改写
查询优化器不能保证总是找到好的查询计划
用户不能给DBMS指定查询计划
用户只能通过添加索引或改写查询来影响查询优化器的决策
如果基于现有索引对查询进行改写就能获得好的查询计划,就没必要添加新的索引
如何改写查询取决于查询优化器的实现

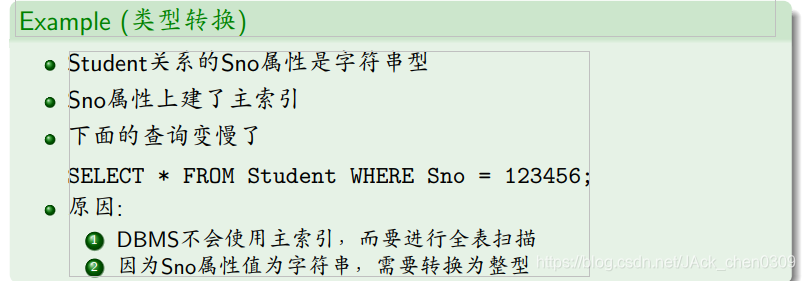
物理存储结构的设计
- 尽量使用可以正确存储数据的最小数据类型
-
原因:最小数据类型占用空间更少,处理速度更快
-
例:INTEGER或INT占4字节;SMALLINT占2字节;TINYINT占1字
节;MEDIUMINT占3字节;BIGINT占8字节 -
例:使用VARCHAR(5)和VARCHAR(100)来存储’hello’的空间开销是一
样的;但在排序时,MySQL会按照类型分配固定大小的内存块
- 尽量选择简单的数据类型
-
原因:简单数据类型的处理速度更快
-
例:用DATE、DATETIME等类型来存储日期和时间,不要用字符串I例:用整型来存储IP地址,而不是用字符串
- 若无需存储空值,则最好将属性声明为NOTNULL
- 原因:含空值的属性使得索引、统计、比较都更复杂
标识符类型的选择
为标识符属性选择合适的数据类型非常重要
- 标识符属性通常会被当作索引属性,频繁地进行比较- 标识符属性通常会被当作主键或外键,频繁地进行连接
- 在设计时,既要考虑标识符属性类型占用的空间,还要考虑比较的
效率
整型:最好的选择 - 占用空间少- 比较速度快
- 可声明为AUTO- NCREMENT,为应用提供便利
ENUM和SET类型:糟糕的选择 - MySQL内部用整型来存储ENUM和SET类型的值,占用空间少
- 在比较时会被转换为字符串,比较速度慢
字符串型:糟糕的选择 - 占用空间大- 比较速度慢
总结
咱们玩归玩,闹归闹,别拿学习开玩笑。
物理数据库的重点在于索引的设计,通过对比B+树索引和哈希索引进行深入思考,同时结合实例记住索引的六大设计技巧。
备注
在数据库中, true,反过来不一定是false,可能是unkown。null表示不知道,它不是c语言的null。
null的比较会得到null的结果 null是无法比较的。所以对数据库要有约束,若不能为空则要声明
NULL就好像你和朋友出去吃饭,点菜时她说随便。