kafka avro序列化读写消息
avro是Hadoop的一个子项目,由Hadoop的创始人Doug Cutting领导开发的一种数据序列化系统。avro具有支持二进制的序列化方式具有丰富的数据结构,可以持久化数据,快速的处理大量数据等优点。kafka与avro的结合能更高效的处理大数据。
在使用avro之前,我们需要提前定义好Schema信息(Json格式),在本案例中,我们定义了一个用户行为对象,使用的数据来自阿里云天池公开数据集 :经过脱敏处理的淘宝用户数据,包括用户id、商品id、商品类别id、用户行为、时间戳。
创建Schema信息
{
"namespace": "kafka.bean.UserBehavior",
"type": "record",
"name": "Stock",
"fields": [
{"name": "userId", "type": "long"},
{"name": "itemId", "type": "long"},
{"name": "categoryId", "type": "long"},
{"name": "behavior", "type": "string"},
{"name": "timestamp", "type": "long"}
]
}
使用到的pom
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.8.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.twitter/bijection-core -->
<dependency>
<groupId>com.twitter</groupId>
<artifactId>bijection-core_2.11</artifactId>
<version>0.9.6</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.twitter/bijection-avro -->
<dependency>
<groupId>com.twitter</groupId>
<artifactId>bijection-avro_2.11</artifactId>
<version>0.9.6</version>
</dependency>
定义一个用户行为类
case class UserBehavior(userId: Long,
itemId: Long,
categoryId: Long,
behavior: String,
timestamp: Long)
extends Serializable {
}
object UserBehavior {
def apply(usrArray: Array[String]): UserBehavior = new UserBehavior(
usrArray(0).toLong, usrArray(1).toLong, usrArray(2).toLong, usrArray(3), usrArray(4).toLong
)
kafka生产者
import java.io.File
import java.util.Properties
import com.twitter.bijection.Injection
import com.twitter.bijection.avro.GenericAvroCodecs
import kafka.bean.UserBehavior
import org.apache.avro.Schema
import org.apache.kafka.clients.producer.KafkaProducer
import org.apache.avro.generic.GenericRecord
import org.apache.avro.generic.GenericData
import org.apache.kafka.clients.producer.ProducerRecord
import scala.collection.immutable
/**
* Created by WZZC on 2019/1/13
**/
object AvroSerializerProducerTest {
def main(args: Array[String]): Unit = {
// Avro Schema解析
val schema: Schema = new Schema.Parser().parse(new File("src/Customer.avsc"))
val recordInjection: Injection[GenericRecord, Array[Byte]] = GenericAvroCodecs.toBinary(schema)
// 用户数据
val source = scala.io.Source.fromURL(this.getClass.getResource("/UserBehavior.csv"))
// 数据解析为User对象
val data: immutable.Seq[UserBehavior] = source.getLines().toList.map(_.split(","))
.filter(_.length >= 5)
.map(arr => UserBehavior(arr))
// kafka配置参数
val props = new Properties()
props.put("bootstrap.servers", "localhost:9092")
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
props.put("value.serializer", "org.apache.kafka.common.serialization.ByteArraySerializer")
//创建一个kafka生产者
val producer: KafkaProducer[String, Array[Byte]] = new KafkaProducer(props)
//将用户数据写入kafka
data.foreach(user => {
val avroRecord: GenericData.Record = new GenericData.Record(schema)
avroRecord.put("userId", user.userId)
avroRecord.put("itemId", user.itemId)
avroRecord.put("categoryId", user.categoryId)
avroRecord.put("behavior", user.behavior)
avroRecord.put("timestamp", user.timestamp)
val bytes = recordInjection.apply(avroRecord)
try {
val record = new ProducerRecord[String, Array[Byte]]("user", bytes)
producer.send(record).get()
println(user.toString)
} catch {
case e: Exception => e.printStackTrace()
}
})
producer.close()
}
}
##################################################################
Kafka消费者
import java.io.File
import java.util.{Collections, Properties}
import com.twitter.bijection.Injection
import com.twitter.bijection.avro.GenericAvroCodecs
import org.apache.avro.Schema
import org.apache.avro.generic.GenericRecord
import org.apache.kafka.clients.consumer.KafkaConsumer
import scala.collection.JavaConversions._
import org.apache.kafka.clients.consumer.ConsumerRecords
import scala.util.Random
/**
* Created by WZZC on 2018/01/14
**/
object kafkaConsume {
def main(args: Array[String]): Unit = {
val props = new Properties()
props.put("bootstrap.servers", "localhost:9092")
props.put("group.id", "G3") // 消费组ID
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
props.put("value.deserializer", "org.apache.kafka.common.serialization.ByteArrayDeserializer")
// 创建kafka消费者
val consumer = new KafkaConsumer[String, Array[Byte]](props)
// 订阅主题 subscribe() 方法接受一个主题列表作为参数
// consumer.subscribe("user.*") 也可以使用正则表达式 订阅相关主题
consumer.subscribe(Collections.singletonList("user"))
// Avro Schema
val schema: Schema = new Schema.Parser().parse(new File("src/Customer.avsc"))
val recordInjection: Injection[GenericRecord, Array[Byte]] = GenericAvroCodecs.toBinary(schema)
try {
while (true) {
val consumerRecords: ConsumerRecords[String, Array[Byte]] = consumer.poll(100) //如果没有数据到consumer buffer 阻塞多久
for (record <- consumerRecords) {
// 每条记录都包含了记录所属主题的信息、记录所在分区的信息、记录在分区里的偏移量,以及记录的键值对
val genericRecord: GenericRecord = recordInjection.invert(record.value()).get
println(genericRecord.get("userId") + "\t" +
genericRecord.get("itemId") + "\t" +
genericRecord.get("categoryId") + "\t" +
genericRecord.get("behavior") + "\t" +
genericRecord.get("timestamp") + "\t")
}
}
// 同步提交 :在broker对提交请求做出回应之前,应用会一直阻塞
// 处理完当前批次的消息,在轮询更多的消息之前,
// 调用 commitSync() 方法提交当前批次最新的偏移量
consumer.commitAsync()
} catch {
case e: Exception => println("Unexpected error", e)
}
finally {
// 异步提交:在成功提交或碰到无法恢复的错误之前,commitSync() 会一直重试,但是commitAsync() 不会
try {
consumer.commitSync()
} finally {
consumer.close()
}
}
}
}
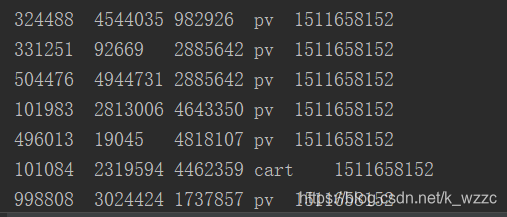
启动kafka生产者和消费者
查看打印的消费信息
参考资料
Kafka权威指南
https://www.iteblog.com/archives/2236.html
https://www.iteblog.com/archives/1008.html