Flink HA配置文档
详细HA原因及原理介绍说明请查看此博客链接,
https://blog.csdn.net/xu470438000/article/details/79633824
本文档只涉及HA具体安装步骤
Flink Standalone集群HA配置
1. HA集群环境规划
使用三台节点实现两主两从集群(由于笔记本性能限制,不能开启太多虚拟机,其实使用三台和四台机器在安装配置上没有本质区别)
Jobmanager:hadoop100 hadoop101【一个active,一个standby】
Taskmanager:hadoop101 hadoop102
zookeeper: hadoop100【建议使用外置zk集群,在这里我使用单节点zk来代替】

2. 开始配置+启动
集群内所有节点的配置都一样,所以先从第一台机器hadoop100开始配置
ssh hadoop100
| #首先按照之前配置standalone的参数进行修改 vi conf/flink-conf.yaml jobmanager.rpc.address: hadoop100 vi conf/slaves hadoop101 hadoop102 # 然后修改配置HA需要的参数 vi conf/masters hadoop100:8081 hadoop101:8081 vi conf/flink-conf.yaml high-availability: zookeeper high-availability.zookeeper.quorum: hadoop100:2181 high-availability.zookeeper.path.root: /flink high-availability.cluster-id: /cluster_one # 建议指定hdfs的全路径。如果某个flink节点没有配置hdfs的话,不指定全路径无法识别 high-availability.zookeeper.storageDir: hdfs://hadoop100:9000/flink/ha # 把hadoop100节点上修改好配置的flink安装目录拷贝到其他节点 cd /usr/local/ scp -rq flink-1.4.2 hadoop101:/usr/local scp -rq flink-1.4.2 hadoop102:/usr/local # 【先启动zk服务】 bin/start-cluster.sh |
3. 验证HA集群进程
查看机器进程会发现如下情况【此处只列出flink自身的进程信息,不包含zk,hadoop进程信息】
| 登录hadoop100节点 执行jps: 20159 JobManager 登录hadoop101节点 执行jps: 7795 JobManager 8156 TaskManager 登录hadoop100节点 执行jps: 5046 TaskManager |
因为jobmanager节点都会启动web服务,也可以通过web界面进行验证
访问http://hadoop100:8081/#/jobmanager/config
发现以下信息:
注意:此时就算是访问hadoop101:8081也会跳转回hadoop100:8081 因为现在hadoop100是active的jobmanager。从下图中也可以看出,点击jobmanager查看,显示哪个节点,就表示哪个节点现在是active的。

4. 模拟jobmanager进程挂掉
现在hadoop100节点上的jobmanager是active的。我们手工把这个进程kill掉,模拟进程挂掉的情况,来验证hadoop101上的standby状态的jobmanager是否可以正常切换到active。
| ssh hadoop100 执行jps: 20159 JobManager kill 20159 |
5. 验证HA切换
hadoop100节点上的jobmanager进程被手工kill掉了,然后hadoop101上的jobmanager会自动切换为active,中间需要有一个时间差,稍微等一下
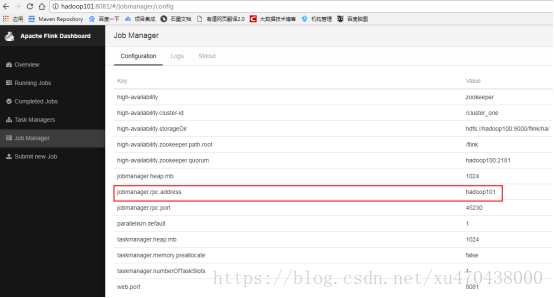
访问http://hadoop101:8081/#/jobmanager/config
如果可以正常访问并且能看到jobmanager的信息变为hadoop101,则表示jobmanager节点切换成功
6. 重启之前kill掉的jobmanager
进入到hadoop100机器
ssh hadoop100
执行下面命令启动jobmanager
| bin/jobmanager.sh start cluster |
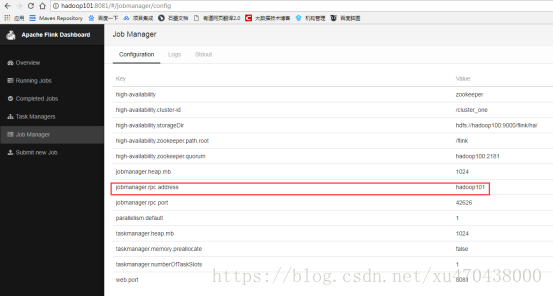
启动成功之后,可以访问http://hadoop100:8081/#/jobmanager/config
这个节点重启启动之后,就变为standby了。hadoop101还是active。
Flink on yarn集群HA配置
1. HA集群环境规划
flink on yarn的HA 其实是利用yarn自己的集群恢复机制。
在这需要用到zk,主要是因为虽然flink-on-yarn cluster HA依赖于Yarn自己的集群机制,但是Flink Job在恢复时,需要依赖检查点产生的快照,而这些快照虽然配置在hdfs,但是其元数据信息保存在zookeeper中,所以我们还要配置zookeeper的HA信息
hadoop集群搭建的伪分布,在hadoop100节点上面【flink on yarn 使用伪分布hadoop集群和真正分布式hadoop集群,在操作上没有区别】
zookeeper服务也在hadoop100节点上

2. 开始配置+启动
主要在hadoop100这个节点上配置即可
首先需要修改hadoop中yarn-site.xml中的配置,设置提交应用程序的最大尝试次数
| <property> <name>yarn.resourcemanager.am.max-attempts</name> <value>4</value> <description> The maximum number of application master execution attempts. </description> </property> |
然后修改flink部分相关配置
| 可以解压一份新的flink-1.4.2安装包 tar -zxvf flink-1.4.2-bin-hadoop27-scala_2.11.tgz 修改配置文件【标红的目录名称建议和standalone HA中的配置区分开】 vi conf/flink-conf.yaml high-availability: zookeeper high-availability.zookeeper.quorum: hadoop100:2181 high-availability.zookeeper.storageDir: hdfs://hadoop100:9000/flink/ha-yarn high-availability.zookeeper.path.root: /flink-yarn yarn.application-attempts: 10 |
3. 启动flink on yarn,测试HA
先启动hadoop100 上的zookeeper
在hadoop100上启动HA集群
| cd /usr/local/flink-1.4.2 bin/yarn-session.sh -n 2 |
在hadoop100上执行jps命令,可以看到下面进程信息:
28680 YarnApplicationMasterRunner
jobmanager进程就在这个(YarnApplicationMasterRunner)进程里面
所以想要测试jobmanager的HA情况,只需要拿YarnApplicationMasterRunner这个进程进行测试即可。
执行下面命令手工模拟kill掉jobmanager(YarnApplicationMasterRunner)
kill 28680
然后你再执行jps 会发现,YarnApplicationMasterRunner这个进程又出现了。
并且还可以去yarn的web界面进行确认:
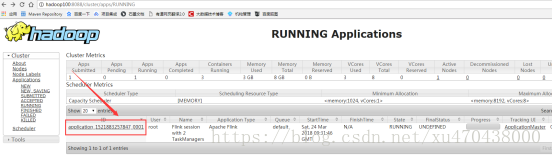
发现这个程序的AttemptId变为00002了

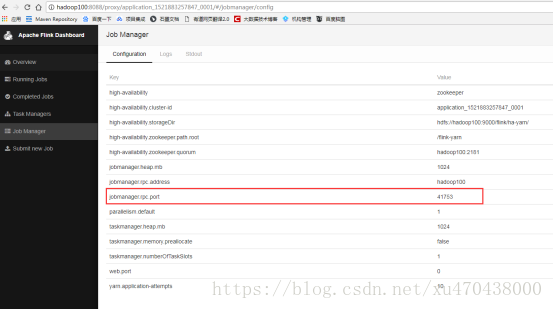
如果想查看jobmanager的webui界面可以点击下面链接:

对比重启前后的jobmanager.rpc.port参数,会发现两次是不一样的,所以可以验证jobmanager是重启之后的。
获取更多大数据资料,视频以及技术交流请加群:
QQ群号1:295505811(已满)
QQ群号2:54902210
QQ群号3:555684318