本文内容:
-
ResNets
-
几个ResNet的Identity mapping 方式
-
WRNs
-
ResNeXt
-
Res2Net
ResNet:
论文链接:https://arxiv.org/abs/1512.03385
CNN网络存在的两个问题:一,vanishing/exploding gradients;深度会带来恶名昭著的梯度弥散/爆炸,导致系统不能收敛。然而梯度弥散/爆炸在很大程度上被normalized initialization and intermediate normalization layers处理了。二、degradation;当深度开始增加的时候,accuracy经常会达到饱和,然后开始下降,但这并不是由于过拟合引起的。如56-layer的error大于20-layer的error。
ResNet的核心方法:提出了一种基于残差块的identity mapping,通过学习残差的方式,而非直接去学习直接的映射关系

Deeper Bottleneck Architectures:

当换成上图右边这种Bottleneck 结构的时候,可以发现152层的ResNet竟然比VGG16/19 都要少的复杂度。先用1x1降维,3x3进行卷积,再用1x1进行升维。事实上,deeper左边这种结构也能获得很好的效果。用右边这种结构,主要是源自于practical,因为左边这种结构在训练时间上要比右边结构长的多。
ResNets的结构:

ResNet34与VGG19 架构对比:

几种 Identity mappings的结构:
作者通过探究Identity Mapping来使得网络变得更容易训练,并且能够提高其网络泛化能力
原始Residual unit和改进后的效果及比较:

原始Residual unit 公式是:

改进的unit,将h(x)与f(x)都为identity mapping后,公式为:

two identity mappings: (i) the identity skip connection h(xl) = xl, and (ii) the condition that f is an identity mapping
作者发现如果h(x)和f(y)都是identity mapping的话,那么在forward或者backward的时候,信号都能直接propagate from 一个unit to other unit。residualNet在backward的时候,可以将梯度完全的往回传
这样表示有两个好处:
1) feature XL可以表示为浅层的xl + 残差累计,真正的实现了残差网络
2)目前的输出可以看做所有preceding residual functions (plus x0),跟VGG这类plain Network不同的是,instead matrix-vector products,目前的算法相当于summation
skip connection结构探索:

效果:

Activation上的结构探索:

效果:

事实上这些附加实验显示这些算法并不是很work
WRNs:
文章链接:https://arxiv.org/abs/1605.07146
解决的问题:非常深的网络往往会出现diminishing feature reuse,这往往会导致网络的训练速度会变得相当的慢。为了解决这个问题,提出了wide ResNet。
像ResNet这类网络也会存在着一些问题:由于梯度在反向传播的时候,可以直接经过shortcut,而不用被强制经过residual block,这会导致可能只有很有限的layer学到了有用的知识,而更多的layers对最终结果只做出了很少的贡献。这个问题也被称之为diminishing feature reuse。当然在后续的工作中,很多人都朝着解决这个问题的方向做,比如residual block进行随机失活,类似于特殊的dropout。基于上述问题,作者认为widening of ResNet blocks可能会提供更有效的方法。WRN-40-4(40层,宽度为4倍)精度赶上了1000layer 的resNet, 并且在训练速度上提升了8倍。
改进的方式:

dropout作为一种正则化的技术也体现了它的有效性,d结构可以继续提升网络效果
结构:

效果:

ResNeXt:
文章链接:https://arxiv.org/abs/1611.05431
在ResNet提出deeper可以带来网络性质提高的同时,WideResNet则认为Wider也可以带来深度网络性能的改善。为了打破或deeper,或wider的常规思路,ResNeXt则认为可以引入一个新维度,称之为cardinality。并且作者在实验上也证明了: increasing cardinality is more effective than going deeper or wider when we increase the capacity
模块结构对比:

左边是ResNet结构,而右边则是cardinality=32的ResNeXt结构(也就是含32个group)。
等效结构:

上面三个设计是等价设计,主要看最后一个C的结构,是不是极其类似ResNet的bottleneck,但是通道数却比ResNet多的多。这就意味着,ResNeXt引入Inception结构,通过稀疏连接来approach之前的dense连接
网络结构对比:

本文则提出了一个simple architecture将Inception和ResNet进行很好的结合。跟同期的Inception-ResNet不同的是,ResNeXt在每个path中都采取相同的设计(采用相同的卷积参数),从Figure1中也能看出来,这可以带来更好的泛化
可以看到在每个conv中,感觉总的通道数要比Resnet多的多,但是两者的参数量是一样的。
计算一下便可得:假设输入特征图为256维,如图1则得知,
resnet的参数量为:
256x64+3x3x64x64+64x256=70k
ResNeXt的参数量为:
Cx(256xd+3x3xdxd+dx256) 当C取32,d=4时,上式也等于70k
Res2Net:
论文地址:https://arxiv.org/pdf/1904.01169.pdf
目前现有的特征提取方法大多都是用分层方式表示多尺度特征。分层方式即要么对每一层使用多个尺度的卷积核进行提特征(如SPPNet),要么就是对每一层提取特征进行融合(如FPN)。
本文提出的Res2Net在原有的残差单元结构中又增加了小的残差块,在更细粒度上,增加了每一层的感受野大小。Res2Net也可以嵌入到不同的特征提取网络中,如ResNet, ResNeXt, DLA等等。
提出了一个新维度,scale:

上图左边是最基本的卷积模块。右图是针对中间的3x3卷积进行的改进。
首先对经过1x1输出后的特征图按通道数均分为s(图中s=4)块,每一部分是xi,i ∈ {1,2,...,s}。
每一个xi都会具有相应的3x3卷积,由Ki()表示。我们用yi表示Ki()的输出。
特征子集xi与Ki-1()的输出相加,然后送入Ki()。为了在增加s的同时减少参数,我们省略了x1的3×3卷积,这样也可以看做是对特征的重复利用。

与其他模块结合(ResNeXt、SE模块):

深度、基数、scale维度变化效果的对比:

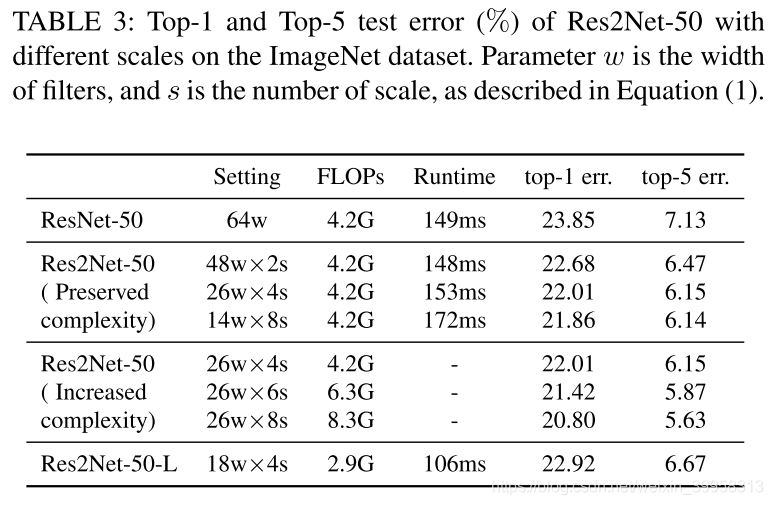
在分类任务上的表现:
参考文章:
https://blog.csdn.net/shwan_ma/article/details/78203020
https://blog.csdn.net/ruoruojiaojiao/article/details/89074763
