神经元中不添加偏置项可以吗?答案是,不可以
每个人都知道神经网络中的偏置(bias)是什么,而且从人类实现第一个感知器开始,每个人都知道神经元需要添加偏置项。但你是否考虑过我们为什么要使用偏置项呢?就我而言,直到不久前我才弄清楚这个问题。当时我和一个本科生讨论了一些神经网络模型,但不知何故她把“偏置输入”(bias input)和“统计基差”( statistical bias)搞混了。对我来说,向她解释这些概念当然很容易,但我却很难进一步地告诉她我们为什么要使用偏置项。过了一段时间,我决定尝试写代码来研究这一问题。
让我们先从一些简单的概念开始。
感知器是多层感知器(MLP)和人工神经网络的前身。众所周知,感知器是一种用于监督学习的仿生算法。它本质上是一个线性分类器,如图所示:
一个简单的感知器示意图
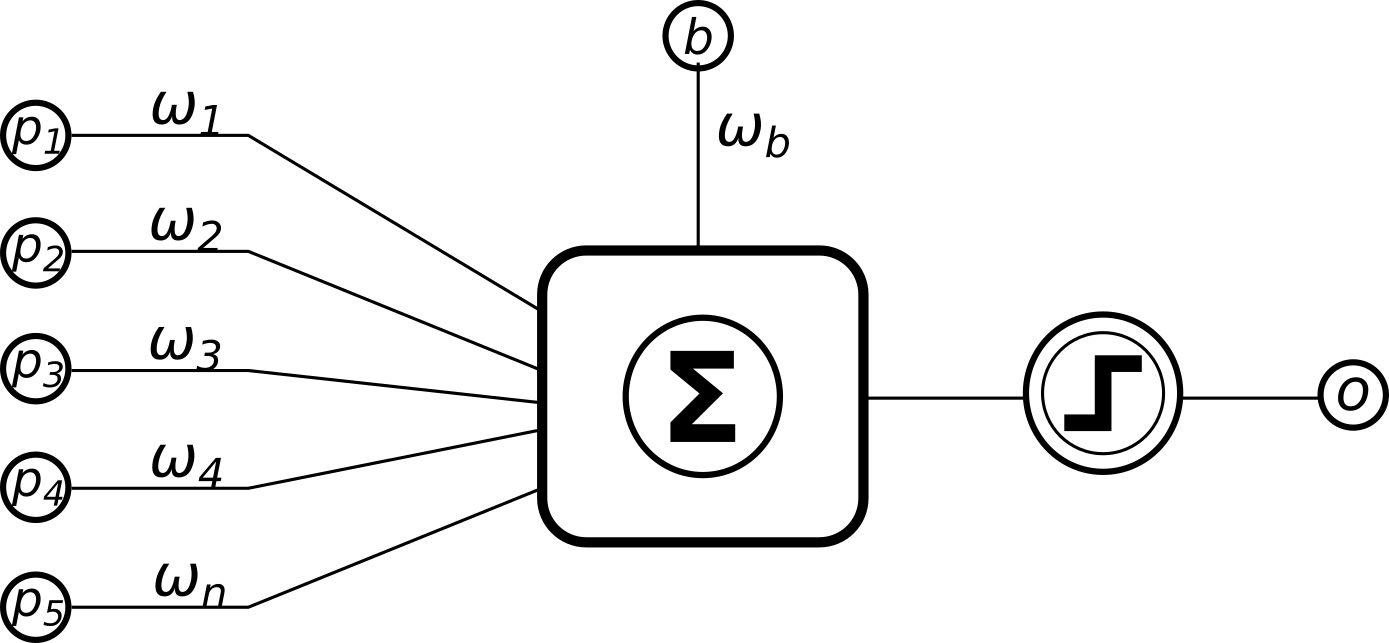
下面让我们考察一下这个模型的数学方程:
在这里,f(x)代表激活函数(通常是一个阶跃函数)。b是偏置项, p和w分别是输入和权重。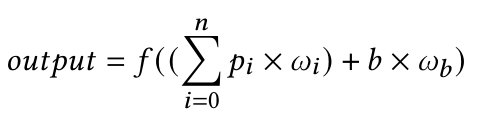
你可能会注意到它与线性函数的标准形式是相似的。如果我们不适用激活函数,或将激活函数替换为恒等映射,这些公式将是相同的(在这里为了方便描述,我们只考虑单一输入):
在这里偏置项的权重是1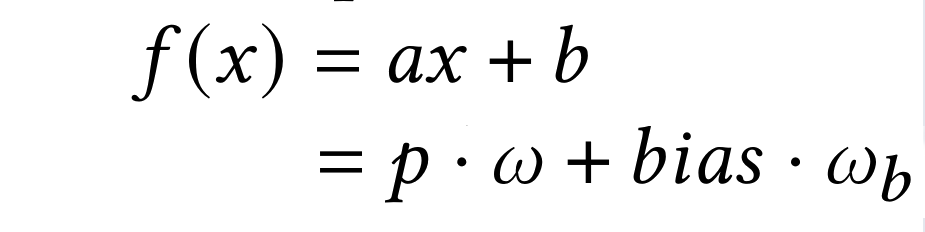
比较这两个公式,很明显我们的偏置项就对应了线性函数中的b。现在的问题就转化为,线性函数中的b为什么那么重要?如果你过去几年没有上过任何线性代数课程(就像我一样),可能对一些概念不够了解。但是下面的内容是很容易理解的: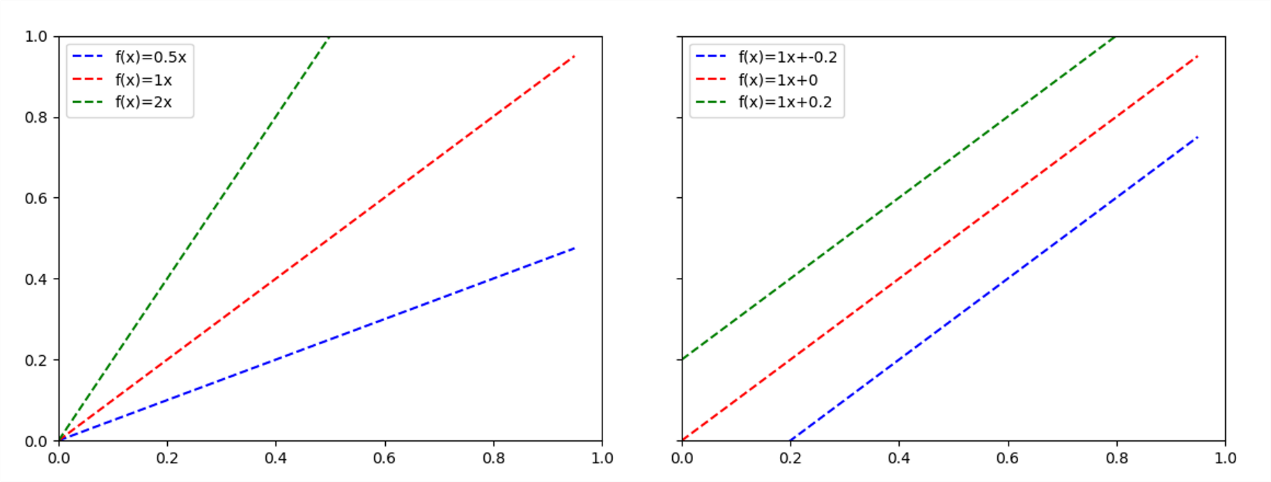
我们很容易就注意到,当b=0时,函数总是通过原点[0,0]。当我们保持a不变的情况下引入b时,新的函数总是相互平行的。那么,我们能从中得到什么信息呢?
我们可以说,系数a决定了函数的角度,而分量b决定了函数与x轴的交点。
此时我想你已经注意到了一些问题,对吧?如果没有b,函数将会失去很多灵活性。只不过对一些分布进行分类时偏置项可能有用,但不是对所有情况都有用。怎样测试它的实际效果呢?让我们使用一个简单的例子:OR函数。让我们先来看看它的分布:
绘制在笛卡尔坐标系中的OR函数: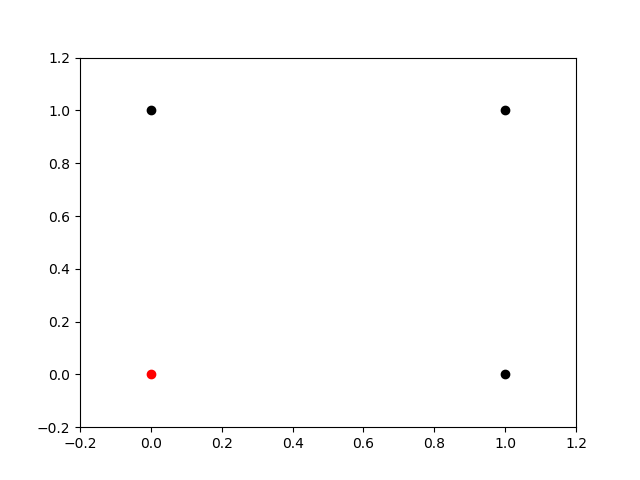
我想你已经想明白了这个问题。图中两个点([0,0]和[1,0])是两个不同的类,但任何一条过[0,0]的直线都没有办法将这两个点分开。那么感知机如何对它分类呢?有偏置项和无偏置项的结果分别是怎样的呢?让我们通过编程,看看将会发生什么!下面是用Python实现的感知器神经元:
class Perceptron():def __init__ (self, n_input, alpha=0.01, has_bias=True):
self.has_bias = has_bias
self.bias_weight = random.uniform(-1,1)
self.alpha = alpha
self.weights = []
for i in range(n_input):
self.weights.append(random.uniform(-1,1))def classify(self, input):
summation = 0
if(self.has_bias):
summation += self.bias_weight * 1
for i in range(len(self.weights)):
summation += self.weights[i] * input[i]
return self.activation(summation)def activation(self, value):
if(value < 0):
return 0
else:
return 1
def train(self, input, target):
guess = self.classify(input)
error = target - guess
if(self.has_bias):
self.bias_weight += 1 * error * self.alpha
for i in range(len(self.weights)):
self.weights[i] += input[i] * error * self.alpha没有偏置项的感知器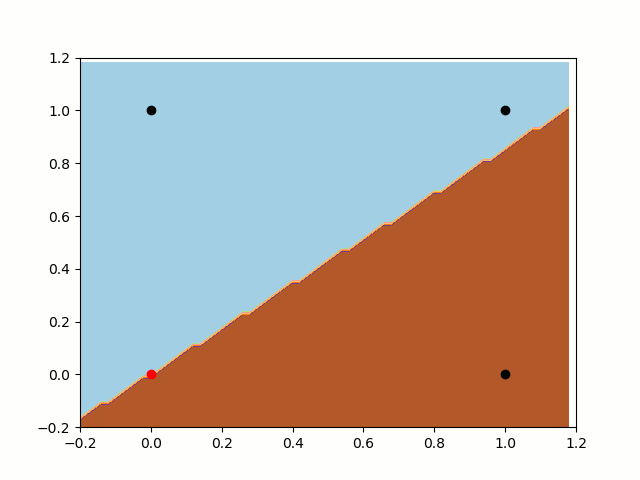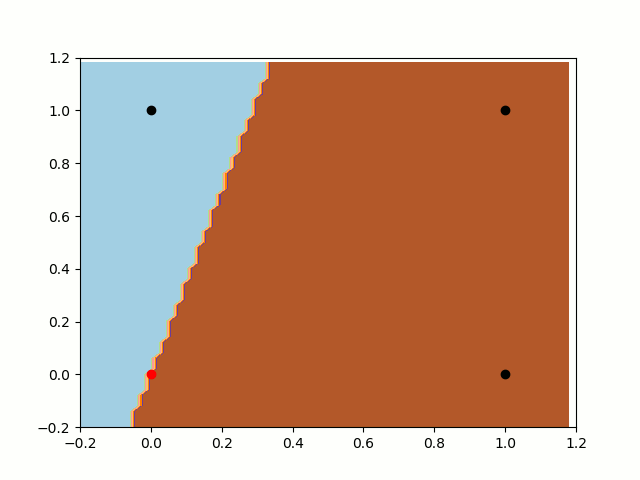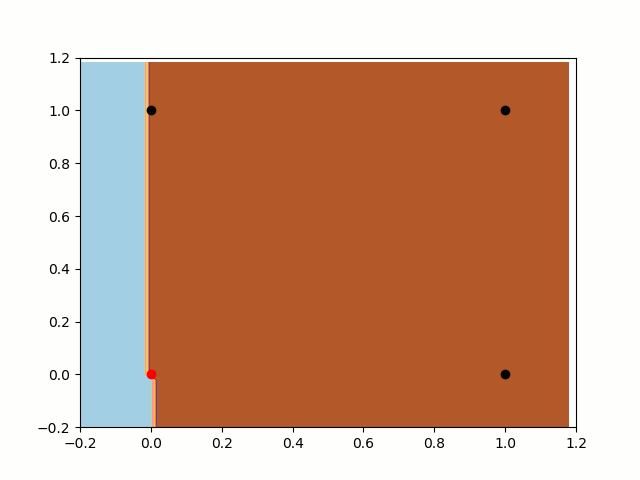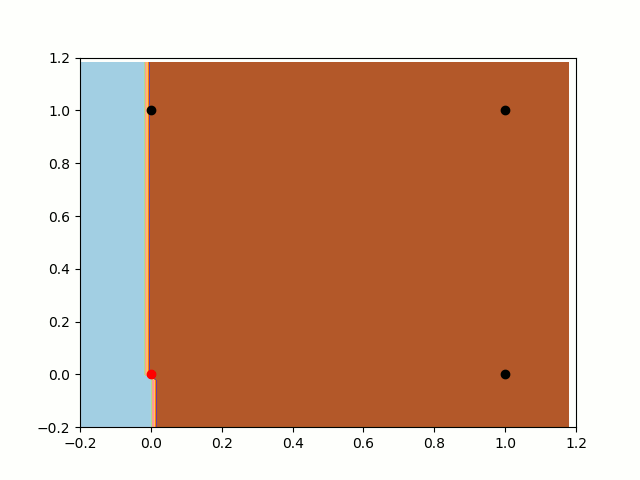
首先,让我们训练无偏置项的感知器。我们知道,分类器(在本例中是我们的函数)总是通过[0,0]的。正如我们之前所说的那样,分类器无法分开这两类。在这种情况下尽管一直在向分离平面逼近,但它还是不能将[0,0]和[1,0]分开,
有偏置项的感知器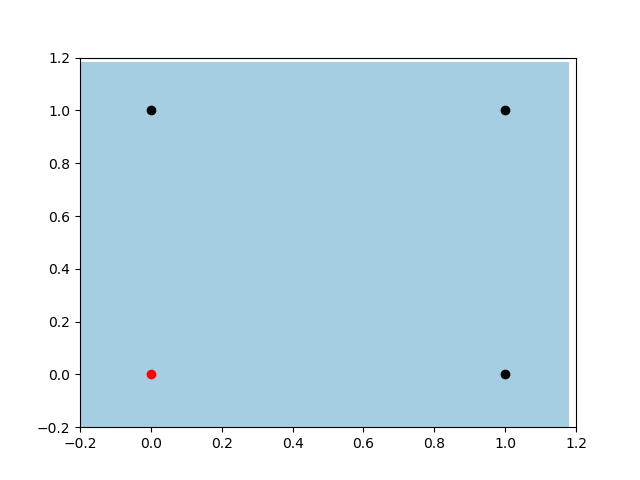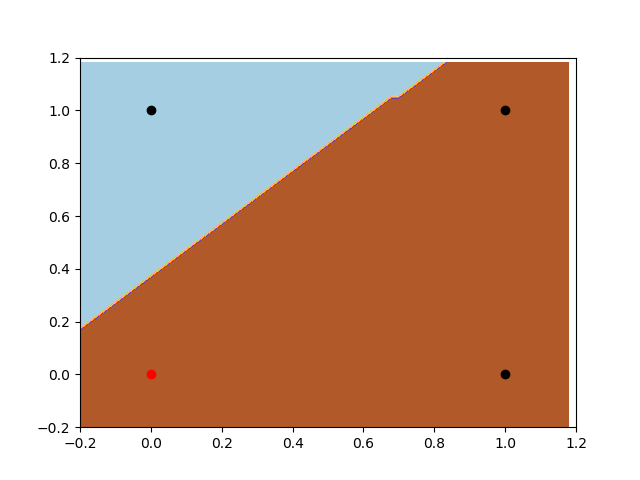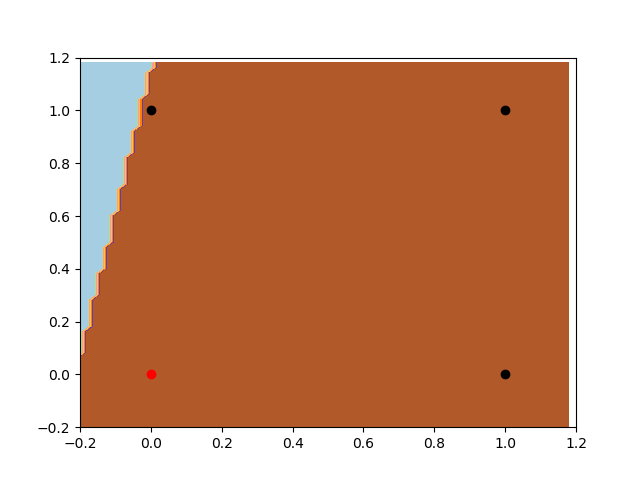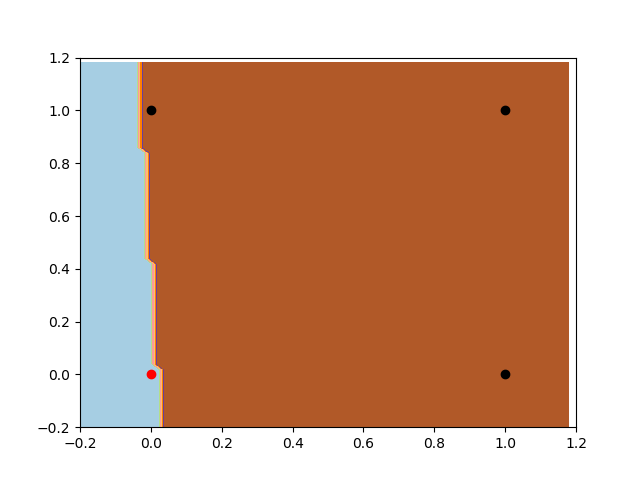
现在我们来看一下有偏置项的感知器。首先,注意分类器的灵活性。如前所述,在这种情况下感知器具有更大的灵活性。此外我们可以注意到,它正在寻找与上一个示例相同的判别平面,但是现在它能够找到分离数据的最佳位置。
所以,偏置项的重要性现在已经很清楚了。我知道你现在可能在思考激活函数,我们在python例子中使用了一个阶跃函数作为激活函数,如果我们使用sigmoid作为激活函数,它的效果可能会更好?相信我:不会的。让我们看看当我们将sigmoid函数作为线性函数的激活函数(σ(f (x)))会发生什么:
你是否注意到这里的例子和线性函数的例子很相似?sigmoid函数虽然改变了输出的形状,但是我们仍然遇到同样的问题:如果没有偏置项,所有的函数都会经过原点。当我们试图用曲线分离OR函数中时,它仍然得不到满意的结果。如果您想尝试一下,看看它是如何工作的,您只需要对python代码做一些小小的修改。
我真诚地感谢你对这个主题感兴趣。如果你有任何建议、意见,或者只是想和我打个招呼,请给我留言!我将很乐意和你讨论这个问题。
作者:Caio Davi
deephub翻译组:zhangzc
原文地址:https://imba.deephub.ai/p/971936e06c3511ea90cd05de3860c663
