5.1信息标记的三种形式

- 标记后的信息可形成信息组织结构,增加信息的维度
- 标记后的信息可用于通信、存储或展示
- 标记的结构与信息一样具有重要价值
- 标记后的信息更有利于程序的理解和运用
HTML的信息标记
HTML是WWW(World Wide Web)的信息组织方式,能将声音、图像、视频等超文本嵌入到文本中去
 信息标记的三种形式:XML、JSON、YAML
信息标记的三种形式:XML、JSON、YAML
5.1.1XML
XML以标签为主构建信息、表达信息

如果标签没有内容可以用空元素的缩写形式,用一对尖括号表达一个标签

XML通过标签形式来构建所有信息,当标签有内容用一对标签来表达这个信息,如果标签没有信息用一对尖括号来表达,同时可以增加注释
5.1.2JSON
 类型的定义叫键key,对信息值的描述叫value,都需要添加“”表示它是字符串的形式,而如果是数字,直接写就行。
类型的定义叫键key,对信息值的描述叫value,都需要添加“”表示它是字符串的形式,而如果是数字,直接写就行。
当值有多个部分时候时候

键值对的嵌套使用
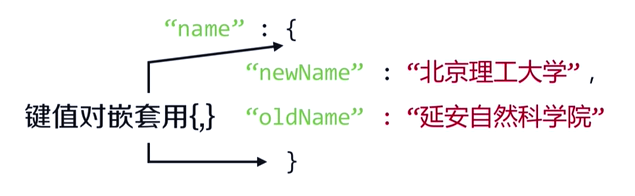
总结:
5.1.3YAML

通过缩进表达所属关系:

用 - 表达并列关系:


总结:

5.2三种信息标记形式的比较







XML Internet上的信息交互与传递
JSON 移动应用云端和节点的信息通信,缺点无注释。一般应用到程序对接口处理的地方
YAML 各类文件的配置文件,有注释易读
5.3信息提取的一般方法
方法一:完整的解析信息的标记形式,再提取关键信息
用标记解析器解析XML、JSON、YAML然后将需要的消息提取出来 例如:bs4库的标签树遍历
优点:信息解析准确
缺点:提取信息过程繁琐、速度慢
方法二:无视标签形式,直接搜索 关键信息
对信息的文本查找函数即可。
优点:提取过程简洁,速度较快
缺点:提取结果的准确性与信息内容相关
融合方法
融合方法:结合形式解析与搜索方法,提取关键信息,需要标记解析器及文本查找函数

import requests
r=requests.get('https://python123.io/ws/demo.html')
demo=r.text
from bs4 import BeautifulSoup
soup=BeautifulSoup(demo,"html.parser")#给出的解释器是html.parser
for link in soup.find_all('a'):
print(link.get('href'))结果
http://www.icourse163.org/course/BIT-268001
http://www.icourse163.org/course/BIT-10018700015.4基于bs4库的HTML内容查找方法
<>.find_all(name,attrs,recursive,string,**kwargs)
返回一个列表类型,存储查找的结果。
name:对标签名称的检索字符串
attrs:对标签属性值得检索字符串,可标注属性检索
recursive:是对子孙全部检索,默认True
调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜索tag的直接子节点,可以使用参数 recursive=False .
string:<>…</>中字符串区域的检索字符串
import requests
r=requests.get('https://python123.io/ws/demo.html')
demo=r.text
from bs4 import BeautifulSoup
soup=BeautifulSoup(demo,"html.parser")#给出的解释器是html.parser
print(soup.prettify())
# <html>
# <head>
# <title>
# This is a python demo page
# </title>
# </head>
# <body>
# <p class="title">
# <b>
# The demo python introduces several python courses.
# </b>
# </p>
# <p class="course">
# Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
# <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">
# Basic Python
# </a>
# and
# <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">
# Advanced Python
# </a>
# .
# </p>
# </body>
# </html>
#查询a标签
print(soup.find_all('a'))
#[<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
#同时查找'a','b'标签返回一个列表
print(soup.find_all(['a','b']))
#[<b>The demo python introduces several python courses.</b>, <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
#如果给出的标签名称为True,将显示soup的所有标签信息,用以下for循环测试
for tag in soup.find_all(True):
print(tag.name)
# html
# head
# title
# body
# p
# b
# p
# a
# a
#如果只显示其中以'b'开头的标签,b body标签
import re
for tag in soup.find_all(re.compile('b')):
print(tag.name)
# body
# b
#查找p标签中包含course字符串的信息
print(soup.find_all('p','course'))
# [<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
# <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>]
#查找属性中id=link1的信息
print(soup.find_all(id='link1'))
# [<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>]
print(soup.find_all(id='link'))
# []
#属性查找必须精确完整
#输出以link开头的信息
import re
print(soup.find_all(id=re.compile('link')))
# [<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
print(soup.find_all('a'))
# [<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
print(soup.find_all('a',recursive=False))
# []
print(soup.find_all(string="Basic Python"))
# ['Basic Python']
import re
print(soup.find_all(string=re.compile("python")))
# ['This is a python demo page', 'The demo python introduces several python courses.']
简短表达:
扩展方法
| 方法 | 说明 |
|---|---|
| <>.find() | 搜索且只返回一个结果,字符串类型,同.find_all()参数 |
| <>.find_parents() | 先辈节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_parent() | 先辈节点中返回一个结果,字符串类型,桐.find()参数 |
| <>.find_next_siblings() | 后续平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_next_sibling() | 在后续平行节点中返回一个结果,字符串类型,同.find()参数 |
| <>.find_previous_siblings() | 在前序平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_previous_sibling() | 在前序平行节点中返回一个结果,字符串类型,同.find参数 |
