点我查看上一篇
基于上篇的分析
我们来具体分析压缩每一步
1 Huffman树的节点保存什么?
双向指针(孩子双亲),权值。
字符保存什么信息:
次数,字符,Huffman编码
2 怎么建造森林?
我们每次从森林中取2颗权值最小的二叉树,那么我们采用小堆来做森林。我们采用优先级队列。
优先级队列默认大堆:那么我们需要修改比较器;
3 怎么获取待压缩文件的每个字符的权值?
遍历一边,利用哈希的思想256个哈希桶足够。
有了权值信息我们便可以建造Huffman 树。
有了Huffman树,我们便可以获取Huffman编码(左走0,右走1)
4 但是Huffman编码到时候怎么获取?
要是从根开始,那只能获取一条路径的编码,便走到叶子了。
我们反着走,从叶子开始,反向求路径。
求得的路径必然唯一,因为二叉树的每一条叶子的路径必然唯一。
现在Huffman编码都有了 ,那么我们就可以进行文本替换了。
5 怎么 替换?
获取一段文件数据,逐个字符挨着替换为Huffman编码。
注意,我们的Huffman编码是个01这样的串,那么我们便可以充分利用每个字节每一位来保存Huffman编码。这是压缩的核心原理。
不仅要能压缩,当然还需要解压缩
6 那么我们怎么解压缩?
想解压缩,直接解压缩肯定不行,为什么,,仔细想,我们怎么知道每个字符的权值呢?
也就是说,我们得保存一组权值信息,解压缩时,利用权值信息构造哈夫曼Huffman树。
7 你可能会问,那为什么不保存Huffman树呢?
Huffman树的节点是new出来的,我问你,怎么存???
8
好了 ,言归正传,我们的解压缩可以根据构造的Huffman树来进行。
到时我们将拿到的是一串二进制数字,然后从Huffman树顶开始向下走,走到叶子就是一个Huffman编码,然后翻译为对应字符, 直到解压缩完成。
遇到的问题: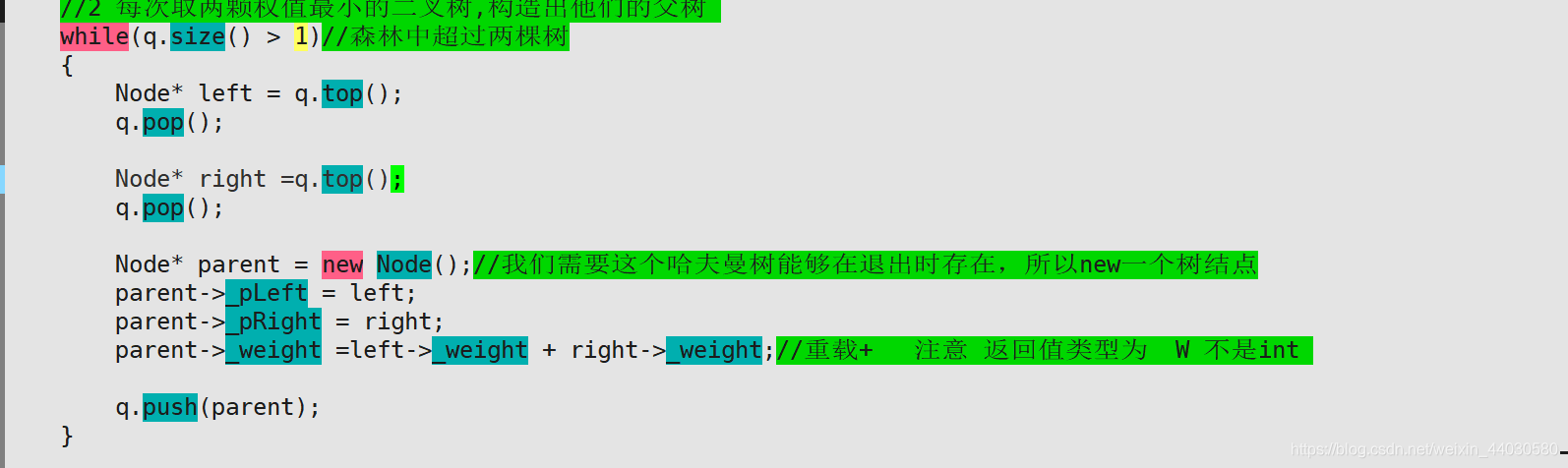

都是运算符重载一下就OK
出现问题 1 : 将出现0次的节点也加入到了Huffman树中:没有意义
**解决方案:**将创建Huffman树期间要将出现0次的结点过滤掉
出现问题 2 :写入文件时,要是一个字节写哈夫曼编码时,将编码分为两半,会影响吗?
出现问题3 解压缩呢? 只拿着压缩数据没法解压缩呀-------么有Huffman 树呀
解决方案:存储Huffman树的节点信息
压缩文件:
需要:
1原文件后缀,以后好还原
2 编码的行数。
3 (编码)字符及出现次数的信息
4 压缩数据
遇到问题: Linux下不支持itoa函数
解决方法 : 用sprintf函数替换
下一篇:
基于LZ77算法的文件压缩
