目录
摘要
使用C#Jupyter Notebook和Daany – C#数据分析库在.NET平台上完全实现了Notebook。此notebook与Azure官方gallery门户上的notebook之间存在细微差别,但是在大多数情况下,代码遵循此处定义的步骤。
Notebook显示了如何将Daty.DataFrame和ML.NET与.NET Jupyter Notebook一起使用,以准备数据并在.NET平台上构建预测性维护模型。
描述
在前面的文章中,我们分析了100台机器的5个数据集,包括telemetry,data,errors和maintenance以及failure。数据经过转换和分析,以创建最终数据集,以建立用于预测性维护的机器学习模型。
一旦我们创建从数据集所有功能,作为最后一步,我们创建的标签栏,以便它描述了如果某台机器将在未来24小时因故障失效component1,component2,component3,component4或者它会继续工作。在这一部分中,我们将执行一部分机器学习任务,并开始训练机器学习模型,以预测特定机器在接下来的24小时内是否会由于故障而出现故障,或者在该时间段内将正常运行。
我们将要构建的模型是一个多类分类模型,因为它具有5个可预测的值:
- component1
- component2
- component3
- component4 或
- none –表示它将继续工作
ML.NET Framework作为训练库
为了训练模型,我们将使用ML.NET – Microsoft .NET平台上机器学习的开源框架。首先,我们需要得到一些准备代码,例如:
- 必需的Nuget软件包
- 一组using语句和用于格式化输出的代码
在此notebook的开头,我们安装了多个NugetPackages以完成此notebook。以下代码显示了using语句和用于格式化DataFrame数据的方法。
//using Microsoft.ML.Data;
using XPlot.Plotly;
using System;
using System.Collections.Generic;
using System.Drawing;
using System.Linq;
//
using Microsoft.ML;
using Microsoft.ML;
using Microsoft.ML.Data;
using Microsoft.ML.Transforms;
using Microsoft.ML.Trainers.LightGbm;
//
using Daany;
using Daany.Ext;
//DataFrame formatter
using Microsoft.AspNetCore.Html;
Formatter.Register((df, writer) =>
{
var headers = new List();
headers.Add(th(i("index")));
headers.AddRange(df.Columns.Select(c => (IHtmlContent) th(c)));
//renders the rows
var rows = new List<List>();
var take = 20;
//
for (var i = 0; i < Math.Min(take, df.RowCount()); i++)
{
var cells = new List();
cells.Add(td(df.Index[i]));
foreach (var obj in df[i]){
cells.Add(td(obj));
}
rows.Add(cells);
}
var t = table(
thead(
headers),
tbody(
rows.Select(
r => tr(r))));
writer.Write(t);
}, "text/html");安装Nuget程序包并定义using语句后,我们将定义创建ML.NET管道所需的类。
类PrMaintenanceClass——包含我们在上一篇文章中构建的功能(属性)。我们需要它们来定义ML.NET管道中的功能。我们定义的第二个PrMaintenancePrediction类用于预测和模型评估。
class PrMaintenancePrediction
{
[ColumnName("PredictedLabel")]
public string failure { get; set; }
}
class PrMaintenanceClass
{
public DateTime datetime { get; set; }
public int machineID { get; set; }
public float voltmean_3hrs { get; set; }
public float rotatemean_3hrs { get; set; }
public float pressuremean_3hrs { get; set; }
public float vibrationmean_3hrs { get; set; }
public float voltstd_3hrs { get; set; }
public float rotatestd_3hrs { get; set; }
public float pressurestd_3hrs { get; set; }
public float vibrationstd_3hrs { get; set; }
public float voltmean_24hrs { get; set; }
public float rotatemean_24hrs { get; set; }
public float pressuremean_24hrs { get; set; }
public float vibrationmean_24hrs { get; set; }
public float voltstd_24hrs { get; set; }
public float rotatestd_24hrs { get; set; }
public float pressurestd_24hrs { get; set; }
public float vibrationstd_24hrs { get; set; }
public float error1count { get; set; }
public float error2count { get; set; }
public float error3count { get; set; }
public float error4count { get; set; }
public float error5count { get; set; }
public float sincelastcomp1 { get; set; }
public float sincelastcomp2 { get; set; }
public float sincelastcomp3 { get; set; }
public float sincelastcomp4 { get; set; }
public string model { get; set; }
public float age { get; set; }
public string failure { get; set; }
}现在,我们已经定义了一个类类型,我们将为此ml模型实现管道。首先,我们使用恒定的种子进行创建MLContext,以便运行此notebook的任何用户都可以复制该模型。然后,我们加载数据并将数据拆分为训练集和测试集。
MLContext mlContext= new MLContext(seed:88888);
var strPath="data/final_dataFrame.csv";
var mlDF= DataFrame.FromCsv(strPath);
//
//split data frame on training and testing part
//split at 2015-08-01 00:00:00,
//to train on the first 8 months and test on last 4 months
var trainDF = mlDF.Filter("datetime", new DateTime(2015, 08, 1, 1, 0, 0),
FilterOperator.LessOrEqual);
var testDF = mlDF.Filter("datetime", new DateTime(2015, 08, 1, 1, 0, 0),
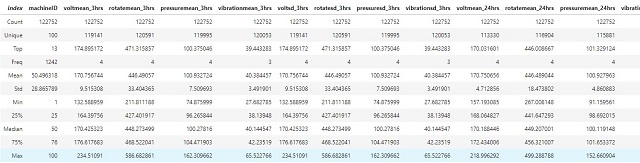
FilterOperator.Greather);下面表中显示了训练集的摘要:

同样,测试集具有以下摘要:
一旦将数据存入应用程序内存,就可以准备ML.NET管道。管道包括从Daany.DataFrame类型到IDataView集合的数据转换。对于此任务,使用LoadFromEnumerable方法。
//Load daany:DataFrame into ML.NET pipeline
public static IDataView loadFromDataFrame(MLContext mlContext,Daany.DataFrame df)
{
IDataView dataView = mlContext.Data.LoadFromEnumerable(df.GetEnumerator(oRow =>
{
//convert row object array into PrManitenance row
var ooRow = oRow;
var prRow = new PrMaintenanceClass();
prRow.datetime = (DateTime)ooRow["datetime"];
prRow.machineID = (int)ooRow["machineID"];
prRow.voltmean_3hrs = Convert.ToSingle(ooRow["voltmean_3hrs"]);
prRow.rotatemean_3hrs = Convert.ToSingle(ooRow["rotatemean_3hrs"]);
prRow.pressuremean_3hrs = Convert.ToSingle(ooRow["pressuremean_3hrs"]);
prRow.vibrationmean_3hrs = Convert.ToSingle(ooRow["vibrationmean_3hrs"]);
prRow.voltstd_3hrs = Convert.ToSingle(ooRow["voltsd_3hrs"]);
prRow.rotatestd_3hrs = Convert.ToSingle(ooRow["rotatesd_3hrs"]);
prRow.pressurestd_3hrs = Convert.ToSingle(ooRow["pressuresd_3hrs"]);
prRow.vibrationstd_3hrs = Convert.ToSingle(ooRow["vibrationsd_3hrs"]);
prRow.voltmean_24hrs = Convert.ToSingle(ooRow["voltmean_24hrs"]);
prRow.rotatemean_24hrs = Convert.ToSingle(ooRow["rotatemean_24hrs"]);
prRow.pressuremean_24hrs = Convert.ToSingle(ooRow["pressuremean_24hrs"]);
prRow.vibrationmean_24hrs = Convert.ToSingle(ooRow["vibrationmean_24hrs"]);
prRow.voltstd_24hrs = Convert.ToSingle(ooRow["voltsd_24hrs"]);
prRow.rotatestd_24hrs = Convert.ToSingle(ooRow["rotatesd_24hrs"]);
prRow.pressurestd_24hrs = Convert.ToSingle(ooRow["pressuresd_24hrs"]);
prRow.vibrationstd_24hrs = Convert.ToSingle(ooRow["vibrationsd_24hrs"]);
prRow.error1count = Convert.ToSingle(ooRow["error1count"]);
prRow.error2count = Convert.ToSingle(ooRow["error2count"]);
prRow.error3count = Convert.ToSingle(ooRow["error3count"]);
prRow.error4count = Convert.ToSingle(ooRow["error4count"]);
prRow.error5count = Convert.ToSingle(ooRow["error5count"]);
prRow.sincelastcomp1 = Convert.ToSingle(ooRow["sincelastcomp1"]);
prRow.sincelastcomp2 = Convert.ToSingle(ooRow["sincelastcomp2"]);
prRow.sincelastcomp3 = Convert.ToSingle(ooRow["sincelastcomp3"]);
prRow.sincelastcomp4 = Convert.ToSingle(ooRow["sincelastcomp4"]);
prRow.model = (string)ooRow["model"];
prRow.age = Convert.ToSingle(ooRow["age"]);
prRow.failure = (string)ooRow["failure"];
//
return prRow;
}));
return dataView;
}将数据集加载到应用程序内存中:
//Split dataset in two parts: TrainingDataset and TestDataset
var trainData = loadFromDataFrame(mlContext, trainDF);
var testData = loadFromDataFrame(mlContext, testDF);在开始训练之前,我们需要处理该数据,以便将所有非数字列编码为数字列。另外,我们需要定义哪些列将成为Features的一部分,哪些列将被标记。因此,我们定义PrepareData方法。
//Split dataset in two parts: TrainingDataset and TestDataset
var trainData = loadFromDataFrame(mlContext, trainDF);
var testData = loadFromDataFrame(mlContext, testDF);可以看出,该方法将作为简单文本列的标签列failure转换为包含每个不同类别Keys的数字表示的分类列。
既然我们已经完成了数据转换,我们将定义实现ML算法的Train方法,该算法的超参数以及训练过程。一旦调用此方法,该方法将返回经过训练的模型。
//train method
static public TransformerChain Train(MLContext mlContext, IDataView preparedData)
{
var transformationPipeline=PrepareData(mlContext);
//settings hyper parameters
var options = new LightGbmMulticlassTrainer.Options();
options.FeatureColumnName = "Features";
options.LearningRate = 0.005;
options.NumberOfLeaves = 70;
options.NumberOfIterations = 2000;
options.NumberOfLeaves = 50;
options.UnbalancedSets = true;
//
var boost = new DartBooster.Options();
boost.XgboostDartMode = true;
boost.MaximumTreeDepth = 25;
options.Booster = boost;
// Define LightGbm algorithm estimator
IEstimator lightGbm = mlContext.MulticlassClassification.Trainers.LightGbm(options);
//train the ML model
TransformerChain model = transformationPipeline.Append(lightGbm).Fit(preparedData);
//return trained model for evaluation
return model;
}训练过程和模型评估
由于我们具有所有必需的方法,因此主程序结构如下所示:
//prepare data transformation pipeline
var dataPipeline = PrepareData(mlContext);
//print prepared data
var pp = dataPipeline.Fit(trainData);
var transformedData = pp.Transform(trainData);
//train the model
var model = Train(mlContext, trainData);一旦Train方法返回模型,评估阶段开始。为了评估模型,我们使用培训和测试数据进行全面评估。
训练数据集的模型评估
将对模型进行评估,以训练和测试数据集:
//evaluate train set
var predictions = model.Transform(trainData);
var metricsTrain = mlContext.MulticlassClassification.Evaluate(predictions);
ConsoleHelper.PrintMultiClassClassificationMetrics("TRAIN DataSet", metricsTrain);
ConsoleHelper.ConsoleWriteHeader("Train DataSet Confusion Matrix ");
ConsoleHelper.ConsolePrintConfusionMatrix(metricsTrain.ConfusionMatrix);模型评估输出:
************************************************************
* Metrics for TRAIN DataSet multi-class classification model
*-----------------------------------------------------------
AccuracyMacro = 0.9603, a value between 0 and 1, the closer to 1, the better
AccuracyMicro = 0.999, a value between 0 and 1, the closer to 1, the better
LogLoss = 0.0015, the closer to 0, the better
LogLoss for class 1 = 0, the closer to 0, the better
LogLoss for class 2 = 0.088, the closer to 0, the better
LogLoss for class 3 = 0.0606, the closer to 0, the better
************************************************************
Train DataSet Confusion Matrix
###############################
Confusion table
||========================================
PREDICTED || none | comp4 | comp1 | comp2 | comp3 | Recall
TRUTH ||========================================
none || 165 371 | 0 | 0 | 0 | 0 | 1.0000
comp4 || 0 | 772 | 16 | 25 | 11 | 0.9369
comp1 || 0 | 8 | 884 | 26 | 4 | 0.9588
comp2 || 0 | 31 | 22 | 1 097 | 8 | 0.9473
comp3 || 0 | 13 | 4 | 8 | 576 | 0.9584
||========================================
Precision ||1.0000 |0.9369 |0.9546 |0.9490 |0.9616 |可以看出,在大多数情况下,该模型可以在训练数据集中正确预测值。现在,让我们看看模型如何预测训练过程中未包含的数据。
使用测试数据集进行模型评估
//evaluate test set
var testPrediction = model.Transform(testData);
var metricsTest = mlContext.MulticlassClassification.Evaluate(testPrediction);
ConsoleHelper.PrintMultiClassClassificationMetrics("Test Dataset", metricsTest);
ConsoleHelper.ConsoleWriteHeader("Test DataSet Confusion Matrix ");
ConsoleHelper.ConsolePrintConfusionMatrix(metricsTest.ConfusionMatrix);
************************************************************
* Metrics for Test Dataset multi-class classification model
*-----------------------------------------------------------
AccuracyMacro = 0.9505, a value between 0 and 1, the closer to 1, the better
AccuracyMicro = 0.9986, a value between 0 and 1, the closer to 1, the better
LogLoss = 0.0033, the closer to 0, the better
LogLoss for class 1 = 0.0012, the closer to 0, the better
LogLoss for class 2 = 0.1075, the closer to 0, the better
LogLoss for class 3 = 0.1886, the closer to 0, the better
************************************************************
Test DataSet Confusion Matrix
##############################
Confusion table
||========================================
PREDICTED || none | comp4 | comp1 | comp2 | comp3 | Recall
TRUTH ||========================================
none || 120 313 | 6 | 15 | 0 | 0 | 0.9998
comp4 || 1 | 552 | 10 | 17 | 4 | 0.9452
comp1 || 2 | 14 | 464 | 24 | 24 | 0.8788
comp2 || 0 | 39 | 0 | 835 | 16 | 0.9382
comp3 || 0 | 4 | 0 | 0 | 412 | 0.9904
||========================================
Precision ||1.0000 |0.8976 |0.9489 |0.9532 |0.9035 |我们可以看到该模型的整体准确度为99%,每类平均准确度为95%。可以在这里找到此博客文章的完整notebook。
