EECS 489实验3:带Bloom过滤器的ImageDB
我的
服务器(imgdb)最终将成为我们的分布式哈希表(DHT)节点,但是在本实验中,我们假设只有一个这样的节点。
bloom filter

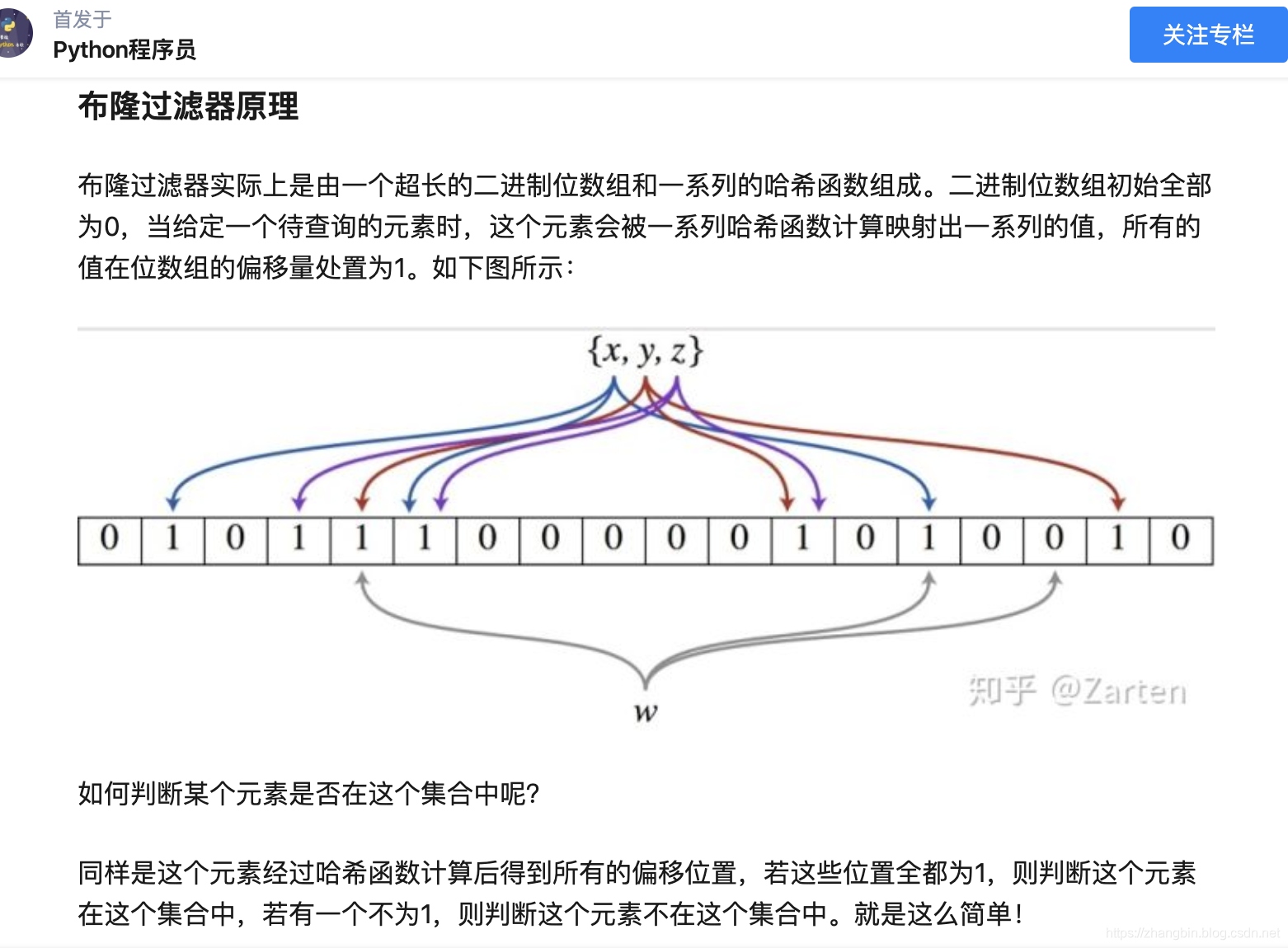
布隆过滤器原理
布隆过滤器(Bloom Filter)的核心实现是一个超大的位数组和几个哈希函数。假设位数组的长度为m,哈希函数的个数为k
以上图为例,具体的操作流程:假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置位0。对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到位数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。
布隆过滤器添加元素
将要添加的元素给k个哈希函数
得到对应于位数组上的k个位置
将这k个位置设为1
布隆过滤器查询元素
将要查询的元素给k个哈希函数
得到对应于位数组上的k个位置
如果k个位置有一个为0,则肯定不在集合中
如果k个位置全部为1,则可能在集合中
中文
介绍
就完成本练习所需编写的行数而言,它很短。您只需要编写约10行代码。任务1有两行,任务2有8行。所需的时间长短取决于您对模块化算术和按位运算的满意程度。
我们假定在本实验中设置客户端-服务器。服务器(imgdb)最终将成为我们的分布式哈希表(DHT)节点,但是在本实验中,我们假设只有一个这样的节点。
% imgdb [ -b -e ]
启动时,服务器使用当前工作目录(从中运行服务器)下“ images ”文件夹中的图像加载数据库。对于每个图像,服务器计算一个SHA1值,从中得出一个ID。只有那些ID落在服务器ID范围内的映像才会被加载到其数据库中。将图像加载到数据库时,还可以通过从上述SHA1值计算三个索引,将其输入到Bloom过滤器中。在函数imgdb :: loaddb()下的支持代码中提供了用于加载数据库和填充Bloom筛选器的功能。 。您应该仔细研究此功能,以了解如何从图像名称生成SHA1值,以及如何生成ID并从SHA1值填充Bloom过滤器。您也可以查看有关布隆过滤器的讲座(第7页,幻灯片#28)。默认情况下,服务器的范围是(0,0],即完整的标识符环。(在数学上,括号用于指示范围不包括指定的值(打开),并使用方括号表示它确实是(闭合的)。在这种情况下,范围是一个大于零的实数,一直到标识符环回到零为止。范围的开始不包括零,但范围结束。您可以使用 -b和-e 命令行选项来设置服务器ID范围的开始和结束值。
客户端(netimg)正是Lab1中的客户端。完整的客户代码是支持代码的一部分。您不必编写任何客户端代码。如果您已经为PA1编写了自己的客户端代码,则可以使用它代替,尽管imgdb实现必须与提供的netimg互操作。
假设条件
我们为此实验和后续实验以及PA2做一些假设。
我们假设对象ID的大小为8位。为了计算对象ID,我们将160位SHA1值“折叠”为8位。因此,ID冲突的可能性变得更高。对于图像,一旦在布隆过滤器上命中,我们就可以对数据库进行线性搜索。匹配需要匹配图像的ID和名称,这也可以为我们解决任何哈希冲突(误报)。
我们假定图像数据库的最大固定大小为IMGDB_MAXDBSIZE。一旦达到此容量,我们只需打印一条消息,通知用户我们不会添加更多图像,但是服务器将继续运行。
我们假设一旦加载,就不会删除图像。因此,我们不必担心数据库中的漏洞或重置Bloom筛选器。
我们假设在任何时候只有一个图像被读入内存。每次有搜索命中时,将从文件中读取图像。
任务1:循环ID和Bloom筛选器
您的第一项任务是写函数ID_inrange(ID,开始,结束)在hash.cpp。给定一个ID,如果ID在hash.h中定义的HASH_IDMAX + 1模(范围为(begin,end ]) 范围内,则返回true(1)。例如,147 处于(138,150)范围内,但不在(150,200 ],而210在(200,10 ]范围内。imgdb :: loaddb()使用此函数 ,因此您可以通过修改服务器的ID范围(使用-b和-e命令行)来观察其工作情况。选项),并查看数据库中加载了哪些图像。
接下来,填充Bloom Filter imgdb :: bf。在 imgdb :: loadimg()中,每次将图像名称添加到数据库中时,使用函数hash.cpp:bfIDX()计算三个Bloom Filter索引(位置)。我们使用三个常量/宏 BFIDX1,BFIDX2和BFIDX3来计算三个索引。这些在hash.h中定义。一旦计算出索引,就可以使用它来设置布隆过滤器上的相应位。有关更多说明,请参见imgdb :: loadimg()中的在线注释。
上面的每一项都需要一行代码。
任务2:图像数据库搜索
您的第二个任务是完成imgdb :: searchdb() 函数,以检查Bloom筛选器中数据库中是否存在图像。从imgdb :: handleqry()调用 函数imgdb :: searchdb()。要调用imgdb :: searchdb() ,您首先计算给定的SHA1消息摘要imgname。根据计算的SHA1值,您可以计算图像的ID。在尝试完成此任务之前,您需要透彻了解imgdb :: loaddb()的工作方式,该过程大约需要6行代码:imgdb :: handleqry()中需要 2行,imgdb :: searchdb()中的其余 行都可以在文件imgdb.cpp中。
支持代码
由于Lab3支持代码包含对PA1部分的解决方案,因此仅提供给上交PA1的人员可以使用。对于上交PA1的人员,支持代码将 在PA1到期后的1/29星期五之前在课程文件夹中作为lab3.tgz提供。届时,我们将从EECS 489 CTools投递箱下载您提交的PA1进行评分。如果您想延迟提交PA1,请不要在到期日之前将任何PA1提交文件放入“投递箱”。如果您的投递箱中有截止日期之前的PA1文件,我们将假定您不会进行任何较晚的提交,并且我们将不会对以后的提交进行评分,无一例外。 在您上交PA1之前,您将无法访问Lab3支持代码。如果您决定不上交PA1,请给课程讲师发电子邮件,您将获得访问权限。
您还可以找到参考implementeation refimgdb和图片文件夹中 /afs/umich.edu/class/eecs489/w16/lab3。如果要将图像下载到自己的计算机上,则可以获取images.tgz (约25 MB)。由于refimgdb通常是在CAEN的Red Hat 7上编译的,因此不要尝试在Mac OS X或Windows计算机上运行它们。回想一下,netimg的完整源代码 包含在支持代码中,因此您应该能够在本地平台上构建客户端。支持代码已在Linux,Mac OS X和Windows上构建并经过测试。如果您没有使用提供的Makefile,请注意imgdb.cpp必须使用编译器选项-DLAB3进行 编译,才能包含main()函数。

在Ubuntu和Windows上,您需要安装OpenSSL库以构建 imgdb。在Ubuntu上,假设您具有sudo特权,请执行以下操作:
sudo apt-get install libssh-dev
在Windows上,请参阅Building Socket Program课程注释的部分, 以获取安装和使用OpenSSL库的链接和说明。您还需要将编译器标志/ DLAB3添加到项目的属性中。如果您不知道如何执行此操作,请按照课程说明中的说明进行操作。
测试您的代码
在没有任何命令行选项的情况下运行imgdb。运行 netimg以连接到正在运行的imgdb并请求ShipatSea.tga。图片应被投放并显示。现在运行:
% imgdb -b 220 -e 20
您应该看到每个ID都在imgdb的ID范围内的图像的名称旁边印有“ * in range * ” 。
接下来运行netimg以连接到正在运行的imgdb 并请求ShipatSea.tga。假设您为ShipatSea.tga计算的ID 不在(220,20 ]范围内,则应该获得一个
imgdb: ShipatSea.tga: Bloom filter miss.
服务器端的消息和 netimg: ShipatSea.tga image not found.
在客户端。测试其他边界条件。
投稿须知
与实验1一样,在本课程中,将公开可用的代码合并到您的解决方案中,或者将一种算法的实现与另一种算法的实现一样,都视为作弊。如果无法实现所需的算法,则在上交作业时必须通知教学人员。
您提交的内容必须编译和运行,而不使用所提供的CAEN eecs489主机错误的Makefile,未经修改的,没有任何额外的库或编译器选项。
您的“ Lab3文件 ”包括hash.cpp 和imgdb.cpp文件。
要上交Lab3,请将Lab3文件的压缩 或压缩的tarball上传到CTools投递箱。保留自己的备份副本!您上传的文件上的时间戳就是您的提交时间。如果超过了截止日期,则您的提交将被视为延迟。只要您遵守截止日期,就可以进行多次“提交”,而没有后期政策的影响。我们强烈建议您使用 第三方私有存储库(例如github或M + Box或Dropbox或Google云端硬盘)来保存提交的备份副本。本地时间戳很容易更改,不能用来确定文件的最后修改时间(-10点)。注意仅使用允许私有存储的第三方存储库 访问。将您的代码放置在可公开访问的第三方存储库中是违反荣誉代码的行为。
仅上交已修改的文件。请勿上交我们提供的尚未修改的支持代码(-4分)。 请勿随您的作业(-4点)一起上交任何二进制文件(对象,可执行文件,dll,库或图像文件)。除了Makefile中列出的库或头文件(-10分)以外,您的代码不得要求其他任何其他库或头文件。
不要删除所有printf()或 cout和cerr,以及为调试目的添加的其他任何日志记录语句。您应该使用调试器进行调试,而不是使用printf()进行调试。如果我们无法理解您的代码输出,您将得到零分。
