这次要整理的笔记是视频背景、前景提取及运动检测,是通过对视频前面的一系列帧图像来提取背景模型,从而分离出前景目标和背景,进而对运动的前景目标进行检测。OpenCV中实现的背景模型提取算法有两种,一种是基于自适应高斯混合背景建模(MOG2)的帧差法实现的背景提取,另外一种是基于最近邻KNN算法实现的。这两种算法相比之下,基于自适应高斯混合背景建模(MOG2)的帧差法所能达到的效果更好,所以使用频率也比基于最近邻KNN算法实现的要高,本篇笔记也是基于MOG2来实现的。
自适应高斯混合背景建模(MOG2)的帧差法,这个方法主要有高斯混合模型和帧差法这两个重要组成部分。下面进行简要介绍:
混合高斯模型:图像灰度直方图反映的是图像中某个灰度级出现的频次,也可以认为是图像灰度概率密度的估计。如果图像所包含的前景目标区域和背景区域相差比较大,且背景区域和前景目标区域在灰度上有一定的差异,那么该图像的灰度直方图呈现双峰形状,其中一个峰对应于前景目标,另一个峰对应于背景的中心灰度。那么图像灰度直方图的每个峰提取出来都可以作为高斯分布的中心,将图像分为3 - 5个高斯模型,当一个新的像素点出现后,如果该像素点离任何一个高斯模型的距离都大于其2倍的标准差,则将该像素点归为前景即运动物体,否则归为背景。
帧差法:将连续两帧的图像数据进行差分,即进行相减操作, 如果其相减后的绝对值大于阈值,则像素点变为255, 否则变为0,通过这种方法来找出视频中运动的物体。帧差法也分为三帧差法和两帧差法。
OpenCV中使用createBackgroundSubtractorMOG2(history, 10, false)来创建一个MOG2背景提取器,其参数如下:
第一个参数history:视频前面一部分用于训练背景的帧数,默认为500帧,选择history = 1就变成两帧差。history越大,背景更新越慢,默认值为500帧。
如果参数learningRate(MOG2背景提取器的apply()中)为默认值,则history被用于计算当前的learningRate,此时history越大,learningRate越小。
第二个参数varThreshold:方差阈值,用于判断当前像素属于前景还是背景。
阈值越大,则只有那些差异化越明显的像素会被归为前景,运动检测的灵敏度降低;阈值越小,前景提取越灵敏,但对光照也越敏感,稳定性会降低。
第三个参数 detectShadows :是否保留阴影检测,默认值为true表示保留阴影检测;选择false可提高运行速度,如无特殊要求,建议设为false。
创建MOG2背景提取器后,需要使用apply()方法来应用该背景提取器,其参数为:
第一个参数image:输入的图像;
第二个参数fgmask:提取出的前景区域的掩膜,是一个二值图像,其中白色区域为前景目标,黑色区域为背景;
第三个参数learningRate:学习率,取值范围为 [0 , 1], 学习率为0时表示背景不更新,为1时表示逐帧更新,学习率越高,背景更新速度越快,默认值为-1,表示算法自动更新学习率(由参数history计算获得)。
然后使用MOG2背景提取器的getBackgroundImage()方法来获取图像的背景图像,就实现了一幅图像的背景、前景分离。
如果我们将目标前景区域的二值图像进行轮廓分析,就能将前景目标的轮廓给寻找出来,然后再获取该轮廓的外接最小正矩形并绘制出来,这样就能在一幅图像中标记出前景目标区域。
如果在视频中逐帧进行这样的操作,那么每帧都标记出前景目标,就达到了前景目标跟踪的效果,那么当前景目标运动时,就能实现对视频的运动检测。
下面是代码演示:
VideoCapture capture;
//capture.open("D:\\opencv_c++\\opencv_tutorial\\data\\images\\video.avi");
capture.open("D:\\OpenCV\\opencv\\sources\\samples\\data\\vtest.avi");
//capture.open(0);
if (!capture.isOpened())
{
return 0;
}
int fps = capture.get(CAP_PROP_FPS);
Mat frame;
Ptr<BackgroundSubtractorMOG2> p_MOG2 = createBackgroundSubtractorMOG2(500, 10, false);
while (capture.read(frame))
{
Mat mask, back_image;
p_MOG2->apply(frame, mask);
p_MOG2->getBackgroundImage(back_image); //获取背景图像
//消除掩膜毛刺和细微干扰
Mat kernel = getStructuringElement(MORPH_RECT, Size(1, 5));
morphologyEx(mask, mask, MORPH_OPEN, kernel, Point(-1, -1), 1, 0);
vector<vector<Point>> contours;
findContours(mask, contours, RETR_EXTERNAL, CHAIN_APPROX_SIMPLE);
//寻找最大轮廓,并在图像中标记出来
//vector<float> area;
//for (int i = 0; i < contours.size(); i++)
//{
// area.push_back(contourArea(contours[i]));
//}
//if (area.size() != 0)
//{
// double minVal, maxVal;
// int minIdx[2], maxIdx[2];
// minMaxIdx(area, &minVal, &maxVal, minIdx, maxIdx);
// Rect rect = boundingRect(contours[maxIdx[1]]);
// rectangle(frame, rect, Scalar(0, 0, 255), 2, 8, 0); //绘制最大轮廓的最小外接正矩形
//}
//检测视频中的运动物体
for (int t = 0; t < contours.size(); t++)
{
float area = contourArea(contours[t]);
if (area < 300)
{
continue;
}
Rect box = boundingRect(contours[t]);
rectangle(frame, box, Scalar(0, 255, 0), 1, 8, 0);
}
char ch = waitKey(fps);
if (ch == 27)
{
break;
}
imshow("back_image", frame);
}
capture.release();
我们来看一下提取出的背景效果图:

由于演示视频开始就有人在走动,所以人的初始位置也被当作了背景的一部分,但是随着视频不断地播放,背景也在不断地更新,所以这些初始人背景部分也会逐步地变淡,直至消失,就是真正的背景部分了。
下面看一下提取出的前景区域的掩膜图像:
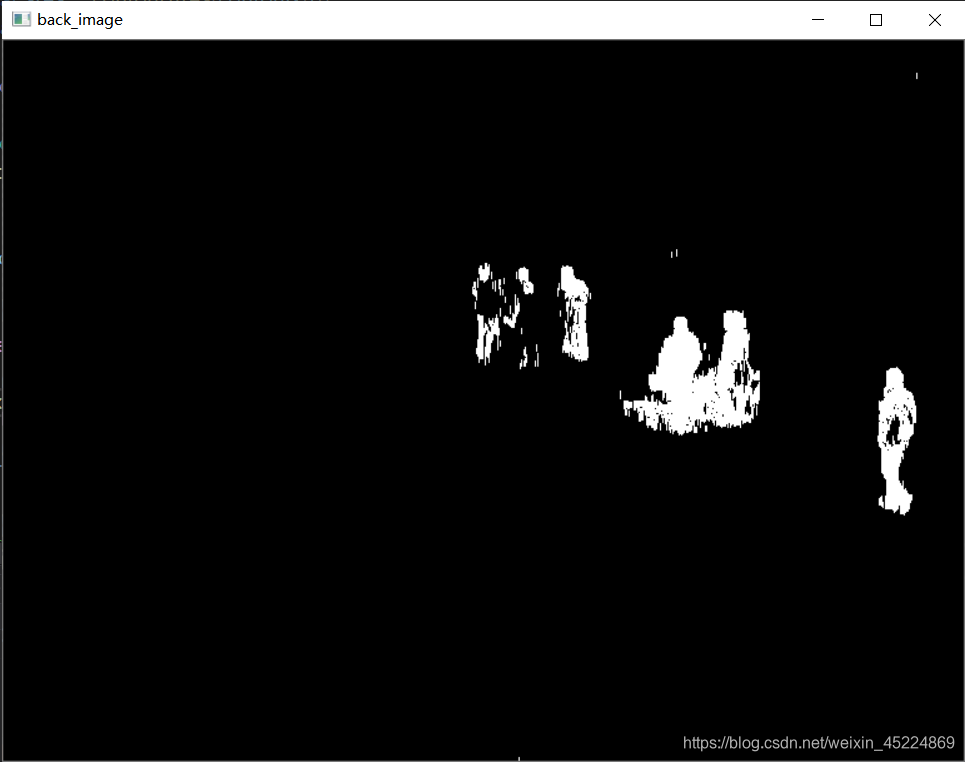
图中白色区域就是被提取出的前景目标,也就是在走动的人。
再看一下运动检测效果:

由于我不知道怎么发小视频,所以只能用截图。。。可见图中,对于运动中的人,都能比较好的用方框标记出来。
MOG2背景提取算法在视频分析中,是比较常用而且效果还不错的算法,在对于实时检测时,虽然也可以对运动物体进行检测,但是速度就略微有些跟不上,画面会出现卡顿现象。对于视频分析,我们通常使用FPS(每秒多少帧的处理能力)来衡量一个算法是否能够满足实时处理要求,一般情况下每秒大于5帧基本上可以认为是在进行视频处理。
好了本次笔记到此结束,谢谢阅读~
PS:本人的注释比较杂,既有自己的心得体会也有网上查阅资料时摘抄下的知识内容,所以如有雷同,纯属我向前辈学习的致敬,如果有前辈觉得我的笔记内容侵犯了您的知识产权,请和我联系,我会将涉及到的博文内容删除,谢谢!
