在了解kafka之前需要先了解消息系统
消息系统
消息系统分类
Peer-to-Peer
- 一般都基于Pull或Polling接收消息
- 发送到队列中的消息被一个而且仅仅一个接收者所接收,即使有多个接收者在同一个队列中侦听同一消息
- 既支持异步"即发即弃"的消息传送方式,也支持同步请求/应答传送方式
发布/订阅
- 发布到一个主题的消息,可被多个订阅者所接收
- 发布/订阅即可基于Push消费数据,也可基于Pull或Polling消费数据
- 解耦能力比P2P模型强.
消息系统适用场景
解耦
各系统之间通过消息系统这个统一的接口交换数据,无须了解彼此的存在
冗余
部分消息系统具有消息持久化能力,可规避消息处理前丢失的风险
扩展
消息系统是统一的数据接口,各系统可独立扩展
峰值处理能力
消息系统可顶住峰值流量,业务系统可根据处理能力从消息系统中获取并处理对应量的请求
可恢复性
系统中部分组件失效并不会影响整个系统,它恢复后仍然可从消息系统中获取并处理数据
异步通信
在不需要立即处理请求的场景下,可以将请求放入消息系统,合适的时候再处理.
kafka
概念详解
简介
Apache Kafka® 是 一个分布式流处理平台
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
流处理平台的特性
- 可以让你发布和订阅流式的记录。
- 可以储存流式的记录,并且有较好的容错性。
- 可以在流式记录产生时就进行处理。
适用场景
- 构造实时流数据管道,它可以在系统或应用之间可靠地获取数据。 (相当于message queue)
- 构建实时流式应用程序,对这些流数据进行转换或者影响。 (就是流处理,通过kafka stream topic和topic之间内部进行变化)
概念
- Kafka作为一个集群,运行在一台或者多台服务器上.
- Kafka 通过 topic 对存储的流数据进行分类。
- 每条记录中包含一个key,一个value和一个timestamp(时间戳)
核心
- The Producer API 允许一个应用程序发布一串流式的数据到一个或者多个Kafka topic。
- The Consumer API 允许一个应用程序订阅一个或多个 topic ,并且对发布给他们的流式数据进行处理。
- The Streams API 允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或多个topic中去,在输入输出流中进行有效的转换。
- The Connector API 允许构建并运行可重用的生产者或者消费者,将Kafka topics连接到已存在的应用程序或者数据系统。比如,连接到一个关系型数据库,捕捉表(table)的所有变更内容。
- 架构图
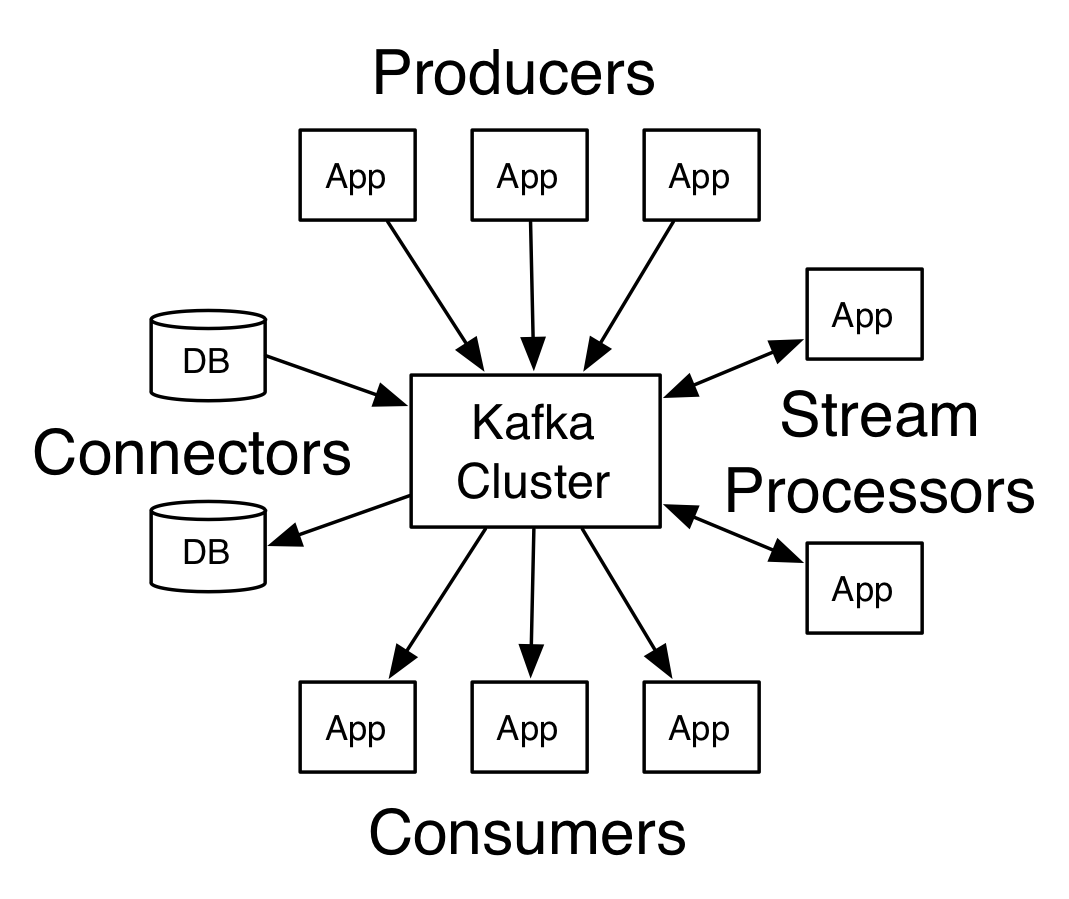
Topics和日志
- 提供一串流式的记录— topic
- Topic 就是数据主题,是数据记录发布的地方,可以用来区分业务系统。Kafka中的Topics总是多订阅者模式,一个topic可以拥有一个或者多个消费者来订阅它的数据。
- 对于每一个topic, Kafka集群都会维持一个分区日志
- 每个分区都是有序且顺序不可变的记录集,并且不断地追加到结构化的commit log文件。分区中的每一个记录都会分配一个id号来表示顺序,我们称之为offset,offset用来唯一的标识分区中每一条记录
- Kafka 集群保留所有发布的记录—无论他们是否已被消费—并通过一个可配置的参数——保留期限来控制. 举个例子, 如果保留策略设置为2天,一条记录发布后两天内,可以随时被消费,两天过后这条记录会被抛弃并释放磁盘空间。Kafka的性能和数据大小无关,所以长时间存储数据没有什么问题
- 事实上,在每一个消费者中唯一保存的元数据是offset(偏移量)即消费在log中的位置.偏移量由消费者所控制:通常在读取记录后,消费者会以线性的方式增加偏移量,但是实际上,由于这个位置由消费者控制,所以消费者可以采用任何顺序来消费记录。例如,一个消费者可以重置到一个旧的偏移量,从而重新处理过去的数据;也可以跳过最近的记录,从"现在"开始消费
分布式
- 日志的分区partition (分布)在Kafka集群的服务器上。每个服务器在处理数据和请求时,共享这些分区。每一个分区都会在已配置的服务器上进行备份,确保容错性.
- 每个分区都有一台 server 作为 “leader”,零台或者多台server作为 follwers 。leader server 处理一切对 partition (分区)的读写请求,而follwers只需被动的同步leader上的数据。当leader宕机了,followers 中的一台服务器会自动成为新的 leader。每台 server 都会成为某些分区的 leader 和某些分区的 follower,因此集群的负载是平衡的。
生产者
- 生产者可以将数据发布到所选择的topic(主题)中。生产者负责将记录分配到topic的哪一个 partition(分区)中。可以使用循环的方式来简单地实现负载均衡,也可以根据某些语义分区函数(例如:记录中的key)来完成
- 分区
- 指定broker
- 主题
消费者
- 消费者使用一个 消费组 名称来进行标识,发布到topic中的每条记录被分配给订阅消费组中的一个消费者实例.消费者实例可以分布在多个进程中或者多个机器上。
- 如果所有的消费者实例在同一消费组中,消息记录会负载平衡到每一个消费者实例.
- 如果所有的消费者实例在不同的消费组中,每条消息记录会广播到所有的消费者进程.
- 分区
- 指定broker
- 主题
- 消费者组
安装
检查是否zookeeper能正常使用
检查是否jdk能正常使用
单节点
- 上传解压
- 配置环境变量
export KAFKA_HOME=/usr/local/LinuxApp/kafka2.10;
export PATH=$KAFKA_HOME/bin
export PATH KAFKA_HOME
保存退出
source /etc/profile
- 修改kafka/config/server.properties
- zookeeper.connect=node1:2181,node2:2181,node3:2181/kafka //zookeeper服务器位置
- log.dirs=/opt/kafka-logs //日志存储位置
- broker.id=0
单节点测试
如要了解命令请先看下方命令详解
-
启动kafka(首先要启动zookeeper)
-
创建topic
kafka-topics.sh
--create
--zookeeper node1:2181:node2:2181,node3:2181
--replication-factor 1
--partitions 1
--topic test
- 查看topic列表
./kafka-topics.sh --list --zookeeper localhost:2181
集群安装
以本机 node1 node2 node3节点为例
每一个节点都要进行以下操作
- 解压下载好的kafka压缩包
- 配置环境变量
export KAFKA_HOME=/usr/local/LinuxApp/kafka2.10;
export PATH=$KAFKA_HOME/bin
export PATH KAFKA_HOME
保存退出
source /etc/profile
- 修改配置文件
vim ./kafka/config/server.properties
node1修改的内容
broker.id=0
listeners=PLAINTEXT://192.168.131.130:9092 //对外提交的接口
zookeeper.connect=node1:2181,node2:2181,node3:2181
node2修改的内容
broker.id=1
listeners=PLAINTEXT://192.168.131.130:9092 //对外提交的接口
zookeeper.connect=node1:2181,node2:2181,node3:2181
node3修改的内容
broker.id=2
listeners=PLAINTEXT://192.168.131.130:9092 //对外提交的接口
zookeeper.connect=node1:2181,node2:2181,node3:2181
Kafka集群环境测试
如要了解命令请先看下方命令详解
- 开启3台虚拟机的zookeeper程序
zkServer.sh start
- 在后台开启3台虚拟机的kafka程序
kafka-server-start.sh -daemon config/server.properties
- 在其中一台虚拟机(192.168.131.130)创建topic
kafka-topics.sh
--create
--zookeeper node1:2181,node2:2181,node3:2181
--replication-factor 3 –partitions 1
--topic my-replicated-topic
- 查看创建的topic信息
kafka-topics.sh
--describe
--zookeeper 192.168.131.130:2181
--topic my-replicated-topic
命令详解
kafka-topics.sh
Option Description
------ -----------
--alter Alter the configuration for the topic.
--config <name=value> A topic configuration override for the
topic being created or altered.
--create Create a new topic.
--deleteConfig <name> A topic configuration override to be
removed for an existing topic
--describe List details for the given topics.
--help Print usage information.
--list List all available topics.
--partitions <Integer: # of partitions> The number of partitions for the topic
being created or altered (WARNING:
If partitions are increased for a
topic that has a key, the partition
logic or ordering of the messages
will be affected
--replica-assignment A list of manual partition-to-broker
<broker_id_for_part1_replica1 : assignments for the topic being
broker_id_for_part1_replica2 , created or altered.
broker_id_for_part2_replica1 :
broker_id_for_part2_replica2 , ...>
--replication-factor <Integer: The replication factor for each
replication factor> partition in the topic being created.
--topic <topic> The topic to be create, alter or
describe. Can also accept a regular
expression except for --create option
--topics-with-overrides if set when describing topics, only
show topics that have overridden
configs
--unavailable-partitions if set when describing topics, only
show partitions whose leader is not
available
--under-replicated-partitions if set when describing topics, only
show under replicated partitions
--zookeeper <urls> REQUIRED: The connection string for
the zookeeper connection in the form
host:port. Multiple URLS can be
given to allow fail-over.
- 创建
kafka-topics.sh
--zookeeper node1:2181
--create
--topic demo #创建名
--partitions 1 #分区
--replication-factor 3 #副本数
- 查询所有topic列表
kafka-topics.sh
--zookeeper node1:2181
--list
- 查看topic的详细信息
查看所有则不加- -topic
kafka-topics.sh --zookeeper node1:2181,node2:2181,node3:2181 --describe --topic test
信息如下:名称 分区数 副本数 副本存放编号 同步编号
Topic:test PartitionCount:1 ReplicationFactor:2 Configs:
Topic:test Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
- 修改
kafka-topics.sh
--zookeeper node1:2181,node2:2181,node3:2181
--alter --topic test
--partitions 3 #修改了分区数
- 删除
删除时需修改server.properties中delete.topic.enable=true,否则执行删除命令不会生效。
kafka-topics.sh
--zookeeper node1:2181
--delete
--topic test
- 查询正在同步的主题
查询所有则不加- -topic
kafka-topics.sh
--zookeeper node1:2181,node2:2181,node3:21181
--describe
--topic test1
--under-replicated-partitions
- 查看不可用分区
kafka-topics.sh
--zookeeper node1:2181,node2:2181,node3:21181
--describe
--unavailable-partitions
- 查看主题重写的信息
kafka-topics.sh
--zookeeper node1:2181,node2:2181,node3:21181
--describe
--topics-with-overrides
--topic test1
Producer(生产)
kafka-console-producer.sh
--broker-list node1:9092,node2:9092,node3:9092
--topic test1
Consumer(消费)
kafka-console-consumer.sh
--bootstrap-server node1:9092,node2:9092,node3:9092
--topic test1
--from-beginning #从第一条消息开始
老版本使用- -zookeeper
新版本使用- -bootstrap-server
查看topic某分区偏移量值
kafka-run-class.sh kafka.tools.GetOffsetShell
--topic test1
--time -1
--broker-list node1:9092
time为-1时表示最大值,time为-2时表示最小值
