对于正态分布,一直以来只闻其名不见其实,只听得鼎鼎大名,而不知由来。在初高中时学习概率,只死记硬背正态分布的形式为:
但对于此公式是如何推导出来的并不了解,正巧又听闻其与最小二乘法有着密切联系,那么本着正本清源的态度,此次就对他们一探究竟。
-
最小二乘法的过往
最小二乘法的诞生与很多科学理论类似,是为了解决天文学以及测地学的问题。例如,计算行星的运行轨道,测定地球子午线长度,定位经纬度。
在解决这些问题时,无不需要大量的观测,再通过观测数据解决目标问题。然而观测数据总是有误差的,为了在有误差的数据上尽可能精确地计算结果,过去的人们一般使用多次测量取均值作为估计值。虽然从结果上来讲是好的,但是这种方法缺乏理论依据。
对于一个数学模型,我们目标估计量为 β = (β0,β1,…,βp,),另有若干个个可以测量的 X = (x1,x2,…,xp) 和 y = (y1,y2,…,yn),那么如何通过观测数据求解出参数 (β0,β1,…,βp,)呢?欧拉和拉普拉斯采用的都是求解线性方程组的方法。
但是面临的一个问题是,当 n>p+1 时,方程组无法直接求解。 所以欧拉和拉普拉斯采用的方法都是通过 一定的对数据的观察,把 n 个线性方程分为 p+1组,然后把每个组内的方程线性求和,归并为一个方程,从而就把 n 个方程的方程组转化为包含 p+1 个方程的方程组,进而求解。这些方法初看有一些道理,但是过于特殊化, 无法形成统一处理这一类问题的一个通用解决框架。
对于此,勒让德提出了有效的解决办法:最小二乘法。其基本思想为,既然存在误差,那么所有误差的累计误差可形式化为:
基于此,定义 ,我们只需要导出能使累计误差最小的参数即可:
勒让德在论文中对最小二乘法的优良性做了几点说明:
- 最小二乘使得误差平方和最小,并在各个方程的误差之间建立了一种平衡,从而防止某一个极端误差取得支配地位;
- 计算中只需求偏导后求解线性方程组,计算过程明确便捷;
- 最小二乘可以导出算术平均值作为估计值。
对于最后一点,从统计学的角度来看是非常重要的一个性质。推理如下:假设真值为 yi,xi,i = 1,2,…,n 为 n 次测量值,每次测量的误差为 ,按最小二乘法,累计误差为:
求解 使得 L(yi) 达到最小,正好是算术平均 。
由于算术平均是一个历经考验的方法,而以上的推理说明,算术平均是最小二乘的一个特例,所以从另一个角度说明了最小二乘方法的优良性,使我们对最小二乘法更加有信心。
-
正态分布的前生
我们在数据处理中经常使用平均的常识性法则,千百来来的数据使用经验说明算术平均能够消除误差,提高精度。 平均有如此的魅力,道理何在,之前没有人做过理论上的证明。 算术平均的合理性问题在天文学的数据分析工作中被提出来讨论:测量中的随机误差服应该服从怎样的概率分布? 算术平均的优良性和误差的分布有怎样的密切联系?
伽利略在他著名的《关于两个主要世界系统的对话》中,对误差的分布做过一些定性的描述,主要包括:
- 误差是对称分布的;
- 大的误差出现频率低,小的误差出现频率高。
用数学的语言描述,也就是说误差分布函数 f(x) 关于 0 对称分布,概率密度随 |x| 增加而减小, 这两个定性的描述都很符合常识。
许多天文学家和数学家开始了寻找误差分布曲线的尝试,大数学家拉普拉斯也加入到了寻找误差分布函数的队伍中,不过最终只得到了著名的“拉普拉斯分布”,距离正态分布曲线仅一步之遥。
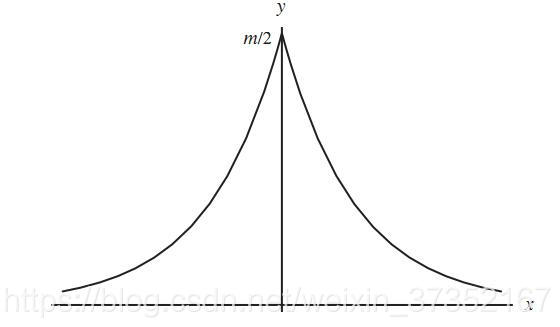
(拉普拉斯分布)而后伟大的高斯在一次计算谷神星轨道过程中解出了正态分布曲线:
高斯设真值为 θ, (x1,⋯,xn) 为 n 次独立测量值, 每次测量的误差为 , 假设误差 ei 的概率密度函数为 f(e), 则测量值的联合概率为 n 个误差的联合概率,记为:
但在求解过程中,高斯没有采用贝叶斯的推理方式,而是直接取 L(θ) 达到最大值的 作为 θ 的估计值,即:
现在我们把 L(θ) 称为样本的似然函数,而得到的估计值 称为极大似然估计。高斯首次给出了极大似然的思想,这个思想后来被统计学家 R.A.Fisher 系统的发展成为参数估计中的极大似然估计理论。
在这之后,高斯做了非常大胆的假设:误差分布导出的极大似然估计 = 算术平均值。而后高斯去寻找误差密度函数 f 以迎合这一点。即寻找这样的概率分布函数 f, 使得极大似然估计正好是算术平均 。
并最终求解出,唯一一个满足以上条件的函数:
至此,正态分布的密度函数 被解出来了。
-
二者的联姻
高斯基于这个误差分布函数:正态分布,对最小二乘法给出了一个很漂亮的解释。 对于每个误差 ei,有 , 则 (e1,⋯,en) 的联合概率分布为:
这个联合概率分布即之前的
对于这个联合概率分布,要使概率最大,那么 应达到最小值,正好就是最小二乘法的要求。
高斯设定的准则“最大似然估计应该导出优良的算术平均”,并导出了误差服从正态分布,推导的形式上非常简洁优美,但是高斯给的准则在逻辑上并不足以让人完全信服,因为算术平均的优良性当时更多的是一个直觉经验,缺乏严格的理论支持。高斯的推导存在循环论证的味道:因为算术平均是优良的,推出误差必须服从正态分布; 反过来,又基于正态分布推导出最小二乘和算术平均,来说明最小二乘法和算术平均的优良性。 这陷入了一个鸡生蛋蛋生鸡的怪圈,逻辑上算术平均的优良性到底有没有自行成立的理由呢?
实际上,在之前的“棣莫弗-拉普拉斯中心极限定理”中,已经出现了正态分布的函数形式:
设随机变量 服从参数为 p 的二项分布,则对任意的 x,恒有:
高斯的文章发表之后,拉普拉斯很快得知了高斯的工作。拉普拉斯不愧为概率论的大牛,他将误差的正态分布理论和中心极限定理联系起来,提出了元误差解释。他指出如果误差可以看成许多量的叠加,则根据他的中心极限定理,则随机误差理所应当是高斯分布。 而20世纪中心极限定理的进一步发展,也给这个解释提供了更多的理论支持。因此有了这个解释为出发点,高斯的循环论证的圈子就可以打破。估计拉普拉斯悟出这个结论之后一定想撞墙,自己辛辛苦苦寻寻觅觅 了这么久的误差分布曲线就在自己的眼皮底下,自己却长年来视而不见,被高斯给占了先机。