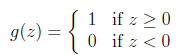review:回顾上节课的一些参数定义。
本次课程大纲:
1.局部加权回归:线性回归的变化版本
2.最小二乘法的概率解释:另一种可能的对于线性回归的解释
3.Logistic回归:基于2的分类算法
4.感知器算法
新的概念定义
过拟合和欠拟合
给定一个假设空间 H,一个假设 h 属于 H,如果存在其他的假设 h 1 ,使得在训练样例上 h 的错误率比 h 1 好,但在整个实例分布上 h 1 的错误率比 h 小,那么就说假设 h 是过拟合。
同理,欠拟合的定义可以类比过合。

参数学习算法
parametric learning algorithm: θ:fixed set of parametric 一类有固定参数集合的参数。
Non-parametric learning algorithm :parametric grows with dataset 参数数目随着数据集增长
局部加权回归(Lwr)
对线性回归的拓展:
LR:fit θ to minimize

当处理的目标假设不是线性模型,比如一个忽上忽下的的函数,这时用线性模型就拟合的很差。为了解决这个问题,当我们在预测一个点的值时,我们选择和这个点相近的点而不是全部的点做线性回归。基于这个思想,就有了局部加权回归算法。
LWR的思想:fit θ to minimize

where:

if |x[i]-x | small then w[i] 趋近于1
if |x[i]-x| large then w[i]趋近于0
w[i]的作用是根据要预测的点与数据集中点的距离来为数据集中的点赋全职,当某点距离待预测带你远时,
权重叫较小,反之较大。
定义新的w[i] :指数衰减函数

新参数控制了权值随距离下降的速率。
缺点:对于每个要查询的点,都要计算整个数据集做线性回归模型,代价很大。准确率提高,消耗巨大。
最小二乘法的概率解释
线性回归的最小二乘法的合理性作出概率解释,既是为什么选择平方函数作为目标函数会使得效果更好。‘
对于每个样例(x[i],y[i])特征值x和目标值y的关系是:


故给定参数θ,x时,目标值y:

其中θ表示已知变量。
由于各样例的误差服从IID(独立同分布)
得到似然函数:

根据概率论中求极大似然函数的求法:


逻辑回归
应用线性模型解决目标值是离散变量的分类问题,用到simoid函数(logistic函数)
这个函数特性x<0时 y 属于(0,0.5) x>0时y属于(0.5,1)x=0 时 y=0.5

则对于一个样例我们可以得到它的分类的概率值。

因而:

故而可以构造h在整个数据集的似然函数:



计算似然值是个复杂的过程,由于公式过多,简化给出结果。
感知器算法
在logistic方法中,g(z)会生成[0,1]之间的小数,但如何是g(z)只生成0或1?
所以,感知器算法将g(z)定义如下: