一、是什么?
二、能做什么?
最小化误差平方和找数据最佳匹配函数,来求得未知数据。用来拟合曲线,解决回归问题。
三、原理?
对于一元线性回归模型, 假设从总体中获取了n组观察值(X1,Y1),(X2,Y2), …,(Xn,Yn)。对于平面中的这n个点,可以使用无数条曲线来拟合。要求样本回归函数尽可能好地拟合这组值。综合起来看,这条直线处于样本数据的中心位置最合理。 选择最佳拟合曲线的标准可以确定为:使总的拟合误差(即总残差)达到最小。有以下三个标准可以选择:
(1)用“残差和最小”确定直线位置是一个途径。但很快发现计算“残差和”存在相互抵消的问题。
(2)用“残差绝对值和最小”确定直线位置也是一个途径。但绝对值的计算比较麻烦。
(3)最小二乘法的原则是以“残差平方和最小”确定直线位置。用最小二乘法除了计算比较方便外,得到的估计量还具有优良特性。这种方法对异常值非常敏感。
最常用的是普通最小二乘法( Ordinary Least Square,OLS):所选择的回归模型应该使所有观察值的残差平方和达到最小。(Q为残差平方和)- 即采用平方损失函数。
样本回归模型:
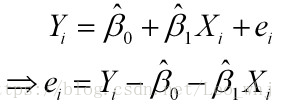
平方损失函数:
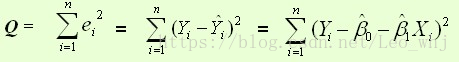
则通过Q最小确定这条直线,即确定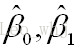
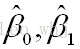
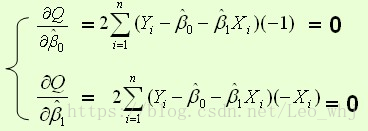
根据数学知识我们知道,函数的极值点为偏导为0的点。
解得:
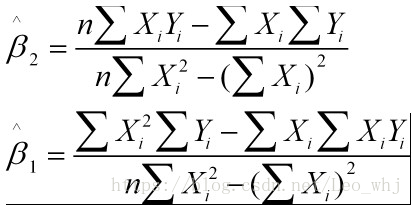
这就是最小二乘法的解法,就是求得平方损失函数的极值点。
四、最小二乘法与梯度下降法
相同点:
1.本质相同:两种方法都是在给定已知数据(independent & dependent variables)的前提下对dependent variables算出出一个一般性的估值函数。然后对给定新数据的dependent variables进行估算。
2.目标相同:都是在已知数据的框架内,使得估算值与实际值的总平方差尽量更小(事实上未必一定要使用平方),估算值与实际值的总平方差
的公式为:
其中
 为第i组数据的independent variable,
为第i组数据的independent variable,
 为第i组数据的dependent variable,
为第i组数据的dependent variable,
 为系数向量。
为系数向量。
不同点:
实现方法不同,最小二乘法
是直接对
 求导找出
全局最小
,是非迭代法。梯度下降法是一种迭代法,先给定一个,然后向下降最快的方向调整,在若干次迭代之后找到局部最小。梯度下降法的缺点是到最小点的时候收敛速度变慢,并且对初始点的选择极为敏感,其改进大多是在这两方面下功夫。
求导找出
全局最小
,是非迭代法。梯度下降法是一种迭代法,先给定一个,然后向下降最快的方向调整,在若干次迭代之后找到局部最小。梯度下降法的缺点是到最小点的时候收敛速度变慢,并且对初始点的选择极为敏感,其改进大多是在这两方面下功夫。