Regressão linear
Prefácio
Precisamos entender que o valor alvo resolvido pelo algoritmo de classificação é um problema discreto; enquanto o algoritmo de regressão resolve o problema do valor alvo contínuo
O que é regressão linear?
Definição: Regressão linear é uma análise de regressão modelada entre uma ou mais variáveis independentes e dependentes. É caracterizada por uma combinação linear de um ou mais parâmetros do modelo chamados coeficientes de regressão.
Regressão linear univariada: apenas uma variável está envolvida
Regressão linear múltipla: duas ou mais variáveis estão envolvidas
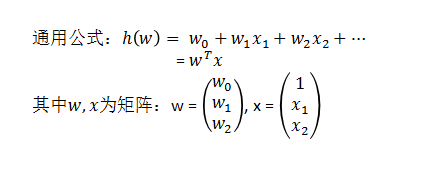
Nota: A regressão linear precisa ser padronizada para evitar um único peso que é muito grande e afeta o resultado final
Exemplos
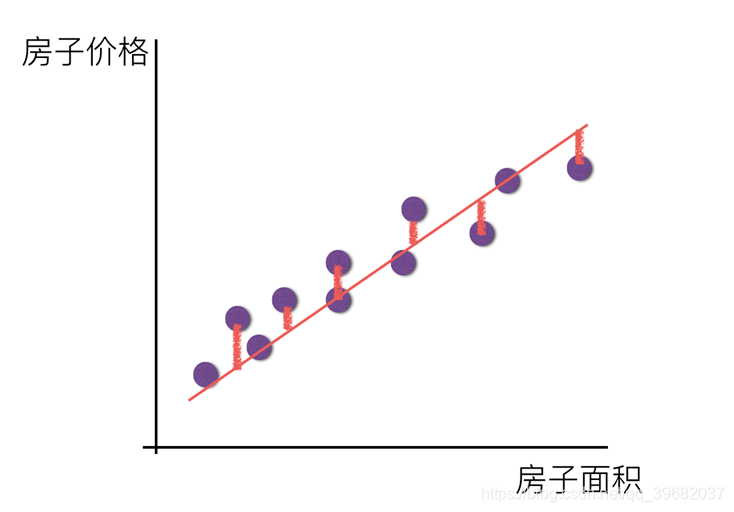
Recurso único:
- Tente encontrar um valor k, b satisfazendo:
- Preço da casa = área da casa * k + b (b é compensado, a fim de ser mais comum para um único recurso)
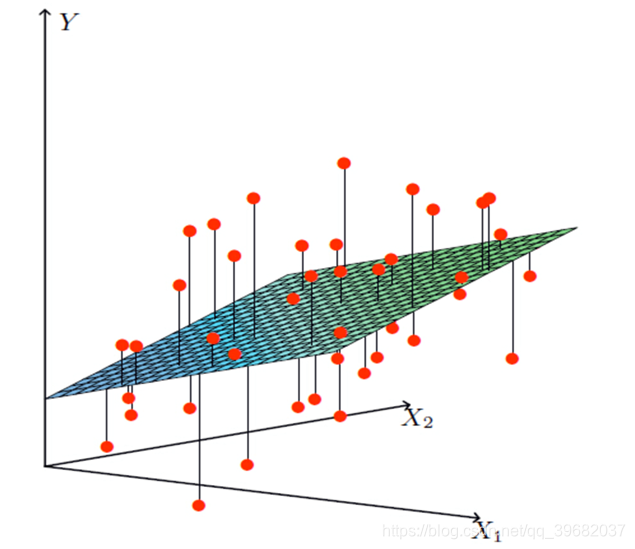
Múltiplas características: (tamanho da casa, localização da casa, ...)
- Tente encontrar um valor de k1, k2, ..., b e atenda:
- Preço da casa = área da casa * k1 + localização da casa * k2 +… + b
Modelo de relacionamento linear
Tente encontrar uma combinação de atributos e pesos para prever o resultado:

No entanto, sempre há um erro no valor previsto, portanto, você precisa usar a função de perda para calcular o erro
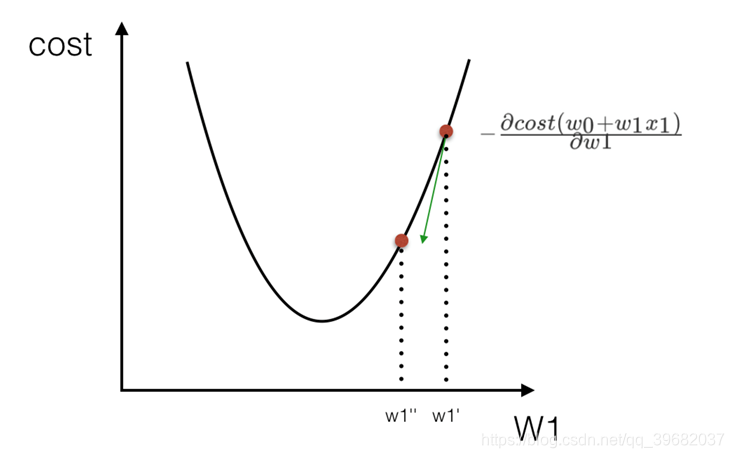
Função de perda (método do quadrado mínimo)

Como encontrar W (peso) no modelo para minimizar a perda? (O objetivo é encontrar o valor W correspondente à menor perda)
Otimização
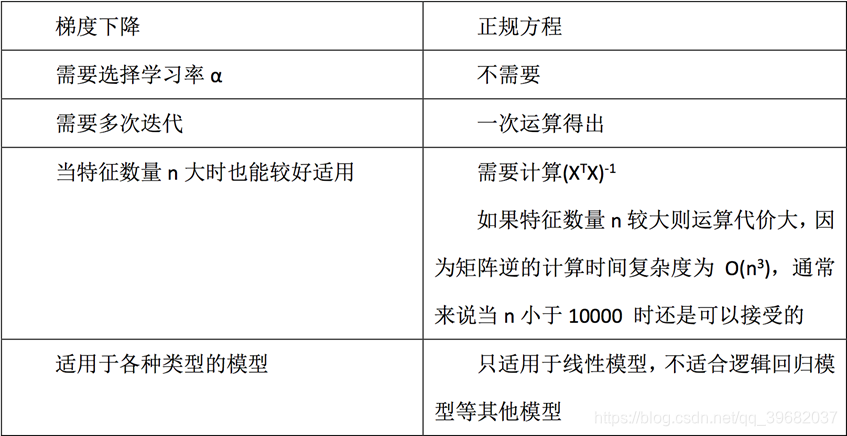
A equação normal dos mínimos quadrados (não recomendado)
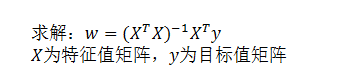
Desvantagens:
- Quando o recurso é muito complexo, a velocidade da solução é muito lenta
- Para algoritmos complexos, equações normais não podem ser usadas (regressão logística, etc.)
O gráfico visual da função de perda (exemplo de variável única) é o seguinte:
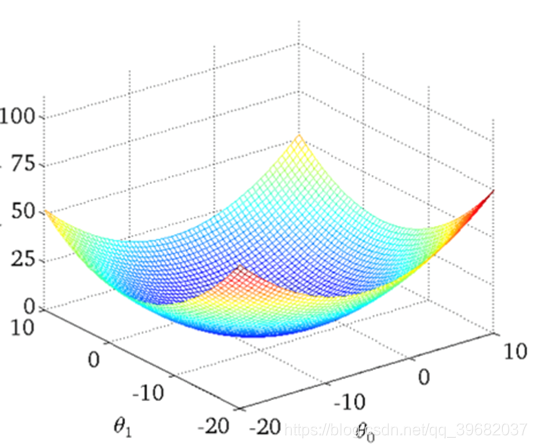
Descida em gradiente do método dos mínimos quadrados (❤️ ❤️ ❤️)

Entenda: Encontre ao longo da direção descendente dessa função e, finalmente, encontre o ponto mais baixo da função e atualize o valor W. (O processo de iteração constante)
Reserva de conhecimento
API de equação normal de regressão linear sklearn
- sklearn.linear_model.LinearRegression ()
coef_: coeficiente de regressão
API de descida do gradiente de regressão linear Sklearn
- sklearn.linear_model.SGDRegressor ()
coef_: coeficiente de regressão
Demonstração de código
Caso de equação normal
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression,SGDRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
def mylinear():
'''
线性回归预测房价
:return: None
'''
# 加载数据
lb = load_boston()
# 分割数据集到训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25)
print(y_train,y_test)
# 进行标准化处理
# 特征值和目标值都需要进行标准化处理
# 扫描器要求的是二维数据类型,需要利用reshape
std_x = StandardScaler()
# 特征值
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
#目标值
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train.reshape(-1,1))
y_test = std_y.transform(y_test.reshape(-1,1))
# estimator预测
# 正规方程求解方程预测结果
lr = LinearRegression()
lr.fit(x_train,y_train)
print(lr.coef_)
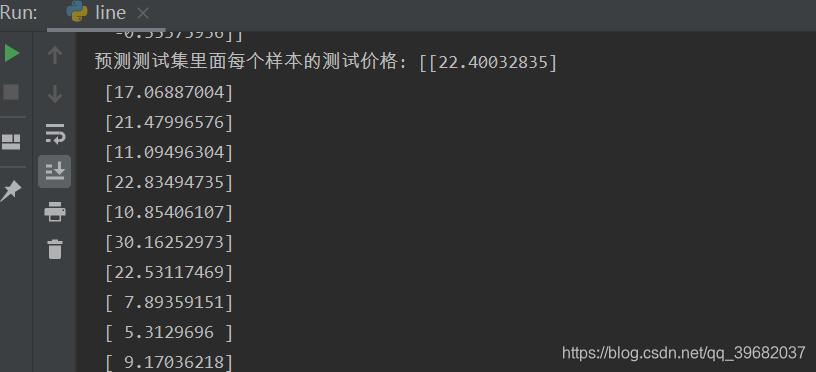
# 预测测试集的房价
y_predict = std_y.inverse_transform(lr.predict(x_test))
print("预测测试集里面每个样本的测试价格:",y_predict)
return None
if __name__ == "__main__":
mylinear()
Descida de gradiente
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression,SGDRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
def mylinear():
'''
线性回归预测房价
:return: None
'''
# 加载数据
lb = load_boston()
# 分割数据集到训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25)
print(y_train,y_test)
# 进行标准化处理
# 特征值和目标值都需要进行标准化处理
# 扫描器要求的是二维数据类型,需要利用reshape
std_x = StandardScaler()
# 特征值
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
#目标值
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train.reshape(-1,1))
y_test = std_y.transform(y_test.reshape(-1,1))
# estimator预测
# 正规方程求解方程预测结果
lr = LinearRegression()
lr.fit(x_train,y_train)
print(lr.coef_)
# 预测测试集的房价
y_lr_predict = std_y.inverse_transform(lr.predict(x_test))
print("正规方程预测测试集里面每个样本的测试价格:",y_lr_predict)
# 梯度下降进行房价预测
# 学习率参数 learning_rate 默认 learning_rate = invscaling
'''
learning_rate : string, default='invscaling'
The learning rate schedule:
'constant':
eta = eta0
'optimal':
eta = 1.0 / (alpha * (t + t0))
where t0 is chosen by a heuristic proposed by Leon Bottou.
'invscaling': [default]
eta = eta0 / pow(t, power_t)
'adaptive':
eta = eta0, as long as the training keeps decreasing.
Each time n_iter_no_change consecutive epochs fail to decrease the
training loss by tol or fail to increase validation score by tol if
early_stopping is True, the current learning rate is divided by 5.
'''
sgd = SGDRegressor()
sgd.fit(x_train, y_train)
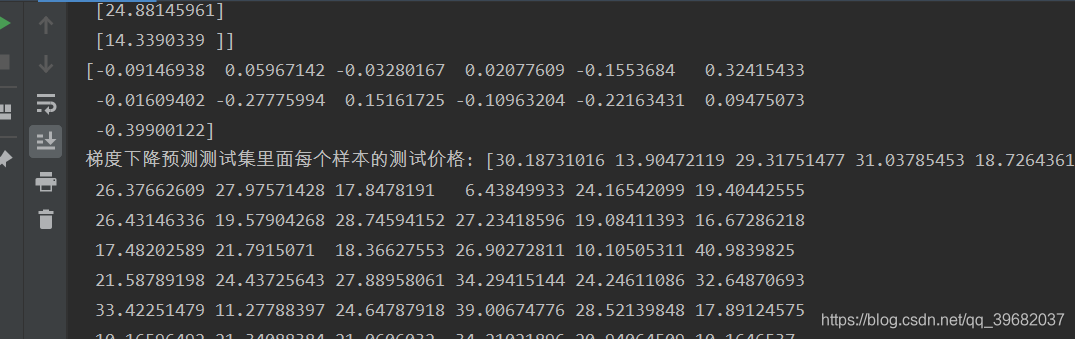
print(sgd.coef_)
# 预测测试集的房价
y_sgd_predict = std_y.inverse_transform(sgd.predict(x_test))
print("梯度下降预测测试集里面每个样本的测试价格:",y_sgd_predict)
return None
if __name__ == "__main__":
mylinear()
Avaliação de desempenho de regressão

Perda de regressão do erro quadrado médio
mean_squared_error (y_true, y_pred)
- y_true: valor verdadeiro
- y_pred: valor previsto
- return: resultado de ponto flutuante
Nota: O valor verdadeiro, o valor previsto é o valor antes da normalização
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression,SGDRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
def mylinear():
'''
线性回归预测房价
:return: None
'''
# 加载数据
lb = load_boston()
# 分割数据集到训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25)
print(y_train,y_test)
# 进行标准化处理
# 特征值和目标值都需要进行标准化处理
# 扫描器要求的是二维数据类型,需要利用reshape
std_x = StandardScaler()
# 特征值
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
#目标值
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train.reshape(-1,1))
y_test = std_y.transform(y_test.reshape(-1,1))
# estimator预测
# 正规方程求解方程预测结果
lr = LinearRegression()
lr.fit(x_train,y_train)
print(lr.coef_)
# 预测测试集的房价
y_lr_predict = std_y.inverse_transform(lr.predict(x_test))
#print("正规方程预测测试集里面每个样本的测试价格:",y_lr_predict)
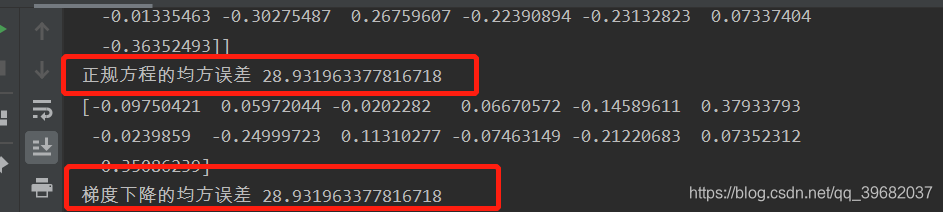
print("正规方程的均方误差",mean_squared_error(std_y.inverse_transform(y_test),y_lr_predict))
# 梯度下降进行房价预测
# 学习率参数 learning_rate 默认 learning_rate = invscaling
'''
learning_rate : string, default='invscaling'
The learning rate schedule:
'constant':
eta = eta0
'optimal':
eta = 1.0 / (alpha * (t + t0))
where t0 is chosen by a heuristic proposed by Leon Bottou.
'invscaling': [default]
eta = eta0 / pow(t, power_t)
'adaptive':
eta = eta0, as long as the training keeps decreasing.
Each time n_iter_no_change consecutive epochs fail to decrease the
training loss by tol or fail to increase validation score by tol if
early_stopping is True, the current learning rate is divided by 5.
'''
sgd = SGDRegressor()
sgd.fit(x_train, y_train)
print(sgd.coef_)
# 预测测试集的房价
y_sgd_predict = std_y.inverse_transform(sgd.predict(x_test))
#print("梯度下降预测测试集里面每个样本的测试价格:",y_sgd_predict)
print("梯度下降的均方误差",mean_squared_error(std_y.inverse_transform(y_test),y_lr_predict))
return None
if __name__ == "__main__":
mylinear()
Sumário
Características: A regressão linear é o modelo de regressão mais simples e fácil de usar.
Até certo ponto, o uso é restrito, mas, sem conhecer a relação entre os recursos, ainda usamos a regressão linear como a principal escolha para a maioria dos sistemas.
Dados em pequena escala: Regressão linear (não pode resolver o problema de ajuste) e outros
dados em grande escala: SGDRegressor
