Este artigo é apenas meu entendimento, corrija-me se houver desvios e erros
Regressão: a regressão é a primeira a propor um modelo experimental, mas os parâmetros-chave do modelo são desconhecidos. Uma grande quantidade de dados é usada para encontrar o modelo experimental que melhor corresponda aos dados de teste, ou seja, para encontrar os parâmetros-chave de o modelo. Em seguida, use um exemplo da palestra de Li Hongyi. Veja especificamente o que é regressão
Este é um exemplo muito interessante para avaliar a habilidade de combate (CP) do Pokémon após a evolução
Ele contém alguns outros atributos, Xcp, Xs, Xhp, Xw, Xh, etc.

A primeira etapa é determinar um modelo (modelo). Aqui, um modelo linear é determinado ![]() . Também pode ser expresso que
. Também pode ser expresso que ![]() b, w são parâmetros e podem ser quaisquer dados, Xi são vários atributos de Pokémon, w pode ser entendido como peso, eb pode ser entendido é o desvio.
b, w são parâmetros e podem ser quaisquer dados, Xi são vários atributos de Pokémon, w pode ser entendido como peso, eb pode ser entendido é o desvio.

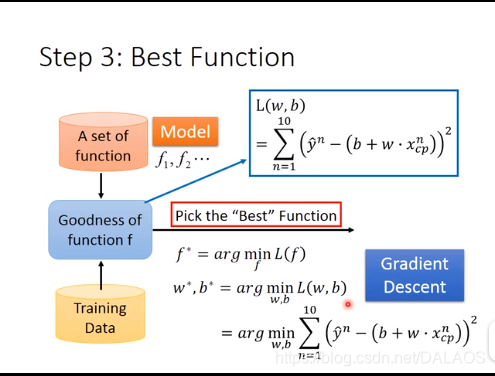
O segundo passo é determinar quais dessas funções são boas, na verdade, é determinar b, w, primeiro coletar os dados de evolução do Pokémon,

Abaixo estão os 10 dados coletados (parecendo tão poucos) e seus gráficos bidimensionais de dados antes e depois da evolução. Parece algo a se aprender na teoria da probabilidade? Na verdade, é encontrar uma linha reta para fazer isso. aponta o máximo possível. Está próximo, o método dos mínimos quadrados é usado;

Use o método dos mínimos quadrados para resolver b, w; use a função de perda L, na verdade, é o erro quadrático médio, quanto menor melhor; a solução b, w é L
O processo de minimização é chamado de estimativa dos parâmetros do método dos mínimos quadrados do modelo de regressão linear;

Cada ponto na figura representa uma função do modelo, a cor representa o erro quadrático médio, o azul representa o bom e o vermelho representa o ruim

O terceiro passo é selecionar a melhor função, que é o valor mínimo de L, que usa derivação diferencial.O método usado aqui é o método de gradiente descendente.
Gradiente descendente: aqui primeiro calculamos em uma dimensão, há apenas um w desconhecido
1. Selecione aleatoriamente um ponto inicial
2. Calcule a derivada.![]() Se for um número negativo, aumente o valor de w, se for um número positivo, diminua w. Na verdade, isso determina a direção do declínio.
Se for um número negativo, aumente o valor de w, se for um número positivo, diminua w. Na verdade, isso determina a direção do declínio. ![]() Isso é chamado de taxa de aprendizado. Quanto wi aumenta ou diminuições depende da derivada e da taxa de aprendizagem.
Isso é chamado de taxa de aprendizado. Quanto wi aumenta ou diminuições depende da derivada e da taxa de aprendizagem.
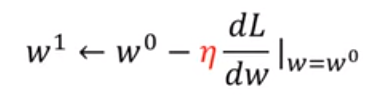 Então pegue o segundo ponto
Então pegue o segundo ponto
3. Repita a segunda etapa para encontrar ótica local,
Na verdade, todos estão muito intrigados com o fato de que apenas o ótimo local pode ser encontrado dessa forma.Na verdade, não existe um ótimo local neste modelo.

Sob dois parâmetros: derivadas parciais são usadas, e os outros são basicamente iguais a um parâmetro. Veja por si mesmo (haha). Também não há ótimo local sob dois parâmetros;

Esta é uma ilustração das etapas para resolver o problema


Então eu encontrei este modelo: Calcular a taxa de erro média  , essa é a soma da distância vertical entre a amostra e a linha reta; estamos mais preocupados com a taxa de erro média do teste, a taxa de erro média do teste é um pouco maior do que a taxa de erro média, devemos Como fazer melhor:
, essa é a soma da distância vertical entre a amostra e a linha reta; estamos mais preocupados com a taxa de erro média do teste, a taxa de erro média do teste é um pouco maior do que a taxa de erro média, devemos Como fazer melhor:


A primeira: usando a forma quadrática, o efeito é obviamente melhor do que o da primeira vez, e precisamos fazer melhor, usamos a terceira potência, a quarta potência e a quinta potência:




Não é difícil descobrir que os resultados do treinamento estão ficando cada vez melhores, mas os resultados do quarto e do quinto testes pioraram, e há resultados irracionais na quinta potência e aparecem números negativos. Na verdade, isso é um ajuste excessivo .


Mencionamos acima que coletamos poucos dados. Agora coletamos muitos dados: não é difícil descobrir que nosso trabalho acima parece ser em vão. Não é uma relação linear simples. Também podemos descobrir que sua distribuição é também relacionado aos seus tipos. Está relacionado, o que significa que olharmos apenas para um de seus atributos (cp) não é suficiente:

Temos outra forma de processamento, utilizando a seguinte estrutura linear:


De acordo com 0 e 1, as seguintes equações são úteis para a compreensão

Encontrar o modelo a seguir não é difícil de descobrir que o efeito é melhor do que o anterior, mas ainda existem pontos acima e abaixo da linha reta que temos que considerar outros atributos:


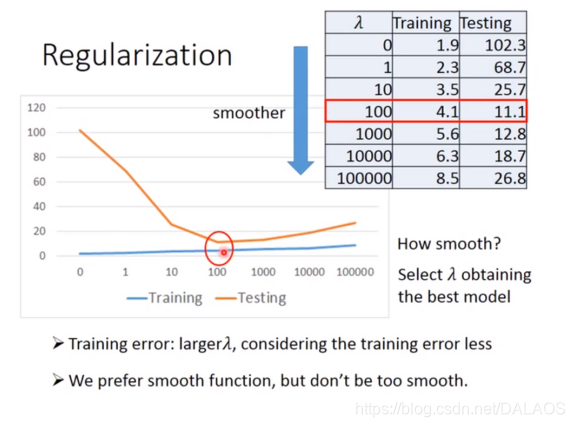
Podemos preencher todos os atributos em que pensamos, mas descobrimos que o efeito do treinamento é bom e o efeito do teste é muito ruim. Usamos outro método para ajustar:

Quanto menor for o wi, melhor, o que torna o resultado mais suave, que ![]() é um determinado número.
é um determinado número.

Este é o resultado do experimento: veja se você consegue entender, estou com preguiça de escrever

################# Deixe-me mostrar o código #############################################################################################################
Este é o código adicionado mais tarde
##李弘毅线性回归模型demo
#y_data = b + w*x_data
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
import numpy as np
x_data = [338.,333.,328.,207.,226.,25.,179.,60.,208.,606.]
y_data = [640.,633.,619.,393.,428.,27.,193.,66.,226.,1591.]
b = -120
w = -4
lr = 1##学习率//这个是添加lr_b,lr_w之后随意设置的
iteration = 100000###迭代次数
##求值过程之中b,w的保存用于画图
b_history = [b]
w_history = [w]
############添加lr_b,lr_w效果更好一些,这涉及到一个方法以后会写
lr_b = 0.0
lr_w = 0.0
############
for i in range(iteration):
##偏导
b_grad = 0.0;
w_grad = 0.0;
for n in range(len(x_data)):
b_grad = b_grad-2.0*(y_data[n]-b-w*x_data[n])*1.0
w_grad = w_grad-2.0*(y_data[n]-b-w*x_data[n])*x_data[n]
#################################
lr_b = lr_b + b_grad ** 2
lr_w = lr_w + w_grad ** 2
################################
##更新b,w的值 b0->b1 w0->w1
b = b - lr/(np.sqrt(lr_b))*b_grad
w = w - lr/(np.sqrt(lr_w))*w_grad
##将数据保存,用于画图
b_history.append(b)
w_history.append(w)
#################作图准备工作########################
x = np.arange(-200,-100,1)##bias
y = np.arange(-5,5,0.1)##weight
Z =np.zeros((len(x),len(y)))
X,Y = np.meshgrid(x,y)
for i in range(len(x)):
for j in range(len(y)):
b= x[i]
w = y[j]
Z[j][i] = 0
for n in range(len(x_data)):
Z[j][i] = Z[j][i] + (y_data[n] -b -w*x_data[n])**2
Z[j][i] = Z[j][i]/len(x_data)
###########################作图###########################
plt.contourf(x,y,Z,50,alpha=0.5,cmap=plt.get_cmap('jet'))
plt.plot([-188.4],[2.67],'x',ms=12,markeredgewidth=3,color='orange')
plt.plot(b_history,w_history,'o-',ms=3,lw=1.5,color='black')
plt.xlim(-200,-100)
plt.ylim(-5,5)
plt.xlabel(r'$b$',fontsize=16)
plt.ylabel(r'$w$',fontsize=16)
plt.show()
Imagem do efeito: