Métodos de aprendizado de máquina na previsão de séries temporais (2): Regressão Linear
Este é o segundo artigo da série " Métodos de aprendizado de máquina em previsão de séries temporais ". Se você estiver interessado, pode ler o artigo anterior primeiro:
[Análise de dados] Análise preditiva usando algoritmos de aprendizado de máquina (1): Média móvel ( Média móvel) média)
O modelo de regressão linear retorna uma equação que determina a relação entre a variável independente e a variável dependente.
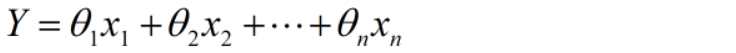
Dentre eles, x representa a variável independente e θ representa o peso. Para o problema de previsão do preço das ações neste artigo, não temos um conjunto de variáveis independentes. Temos apenas datas, então extraímos recursos como dia, mês, ano, segunda / sexta-feira, etc. da coluna de data e, em seguida, ajustamos um modelo de regressão linear.
Os dados de origem e o código deste artigo estão no meu GitHub, amigos que precisarem podem fazer o download sozinhos: https://github.com/Beracle/02-Stock-Price-Prediction.git
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
Importar dados.
df = pd.read_csv('NSE-TATAGLOBAL11.csv')
df.head()
Primeiro, definimos a data como o índice. Para não destruir os dados originais, definimos um novo conjunto de dados.
# setting the index as date
df['Date'] = pd.to_datetime(df.Date,format='%Y-%m-%d')
df.index = df['Date']
#creating dataframe with date and the target variable
data = df.sort_index(ascending=True, axis=0)
new_data = pd.DataFrame(index=range(0,len(df)),columns=['Date', 'Close'])
for i in range(0,len(data)):
new_data['Date'][i] = data['Date'][i]
new_data['Close'][i] = data['Close'][i]
Usamos a função add_datepart () para analisar a data. Se o pacote fastai não estiver instalado, você pode usar pip install fastai para instalá-lo; se você estiver em um ambiente Jupyter, use! Pip install fastai.
#create features
from fastai.tabular import add_datepart
add_datepart(new_data, 'Date')
new_data.drop('Elapsed', axis=1, inplace=True) #elapsed will be the time stamp
new_data
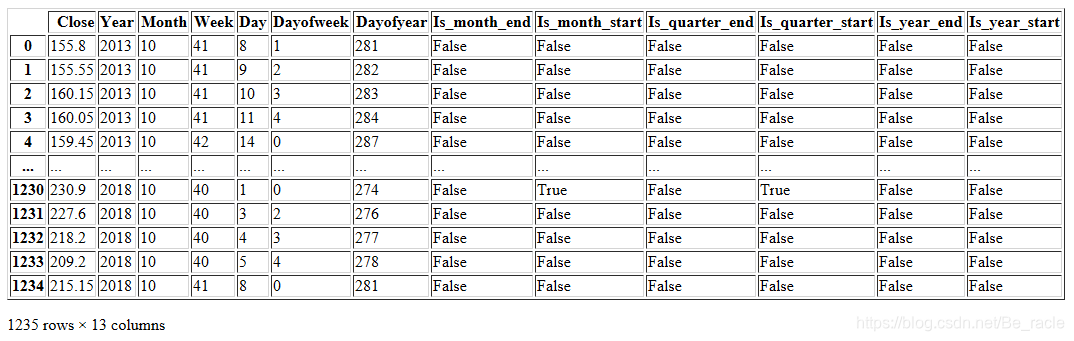
Além disso, podemos adicionar funções que consideramos relevantes para a previsão. Neste artigo, suponho que o primeiro e o último dias da semana podem ter um impacto muito maior no preço de fechamento das ações do que os outros dias. Portanto, criei uma função para determinar se um determinado dia é segunda / sexta ou terça / quarta / quinta.
Se o dia da semana for igual a 0 ou 4, o valor da coluna será 1, caso contrário, será 0. Da mesma forma, podemos criar vários elementos livremente.
new_data['mon_fri'] = 0
for i in range(0,len(new_data)):
if (new_data['Dayofweek'][i] == 0 or new_data['Dayofweek'][i] == 4): #如果是星期一或星期五,列值为1
new_data['mon_fri'][i] = 1
else:
new_data['mon_fri'][i] = 0
Divida os dados em um conjunto de treinamento e um conjunto de predição para verificar o desempenho do modelo.
#split into train and validation
train = new_data[:987]
valid = new_data[987:]
x_train = train.drop('Close', axis=1)
y_train = train['Close']
x_valid = valid.drop('Close', axis=1)
y_valid = valid['Close']
Importe o modelo de regressão linear. Instale o pacote sklearn por meio de pip ou conda primeiro.
#implement linear regression
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(x_train,y_train)
O efeito de previsão é testado por "erro quadrático médio de raiz".
#make predictions and find the rmse
preds = model.predict(x_valid)
rmse = np.sqrt(np.mean(np.power((np.array(y_valid)-np.array(preds)),2)))
rmse

O valor do RMSE é superior ao valor obtido pelo método da "média móvel" que usamos antes, o que indica que o efeito da "regressão linear" é fraco. Pode ser visto de forma mais intuitiva através do desenho.
#plot
valid['Predictions'] = 0
valid['Predictions'] = preds
valid.index = new_data[987:].index
train.index = new_data[:987].index
plt.figure(figsize=(16,8))
plt.plot(train['Close'])
plt.plot(valid[['Close', 'Predictions']])
plt.show()
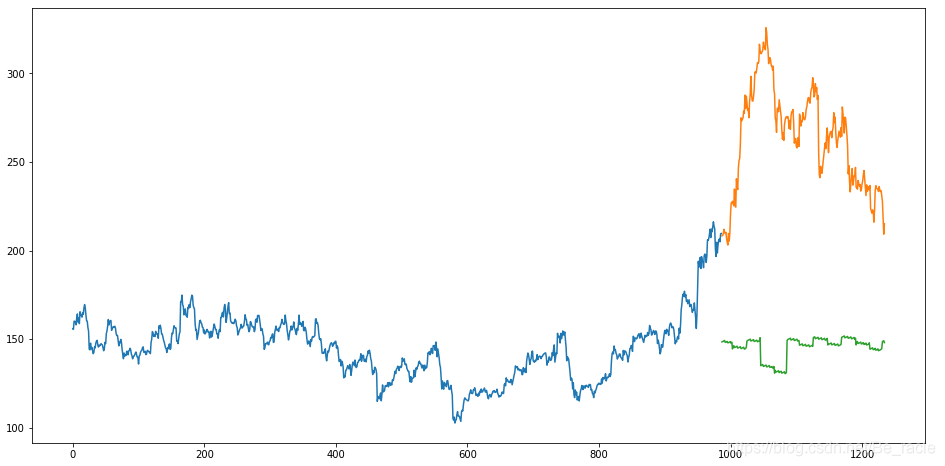
Obviamente, não é apropriado usar a regressão linear para prever os dados neste artigo.