Diretório do artigo
1. Finalidade experimental
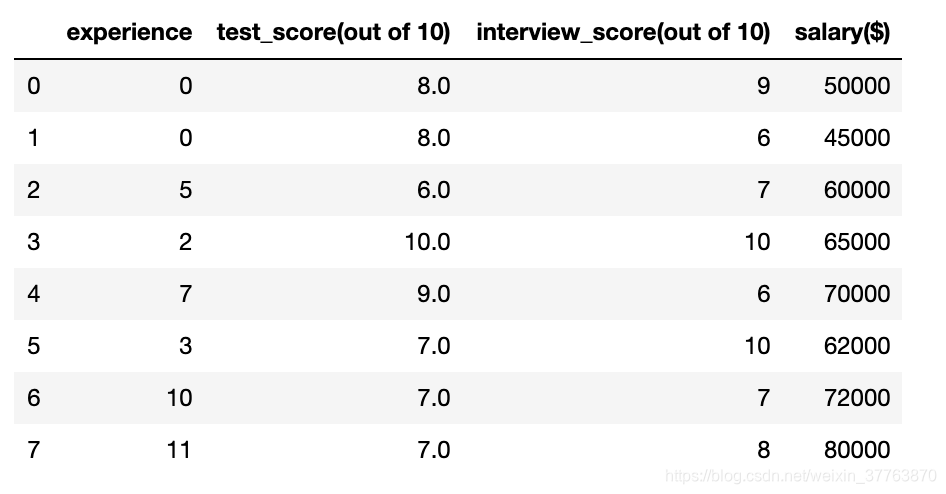
Hiring.csv contém informações de recrutamento da empresa, como a experiência de trabalho do candidato, resultados de testes escritos e resultados de entrevistas pessoais. Com base nesses três fatores, os recursos humanos determinarão os salários. Com esses dados, você precisa criar um modelo de aprendizado de máquina para o departamento de recursos humanos para ajudá-los a determinar o salário dos futuros candidatos. Use esse salário previsto para prever o salário dos seguintes candidatos,
(1) 2 anos de experiência profissional, pontuação no teste 9, pontuação na entrevista 6
(2) 12 anos de experiência profissional, pontuação no teste 10, pontuação na entrevista 10
2. Importe os módulos necessários e leia os dados
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from word2number import w2n
df = pd.read_csv('hiring.csv')
df
3. Processe os dados
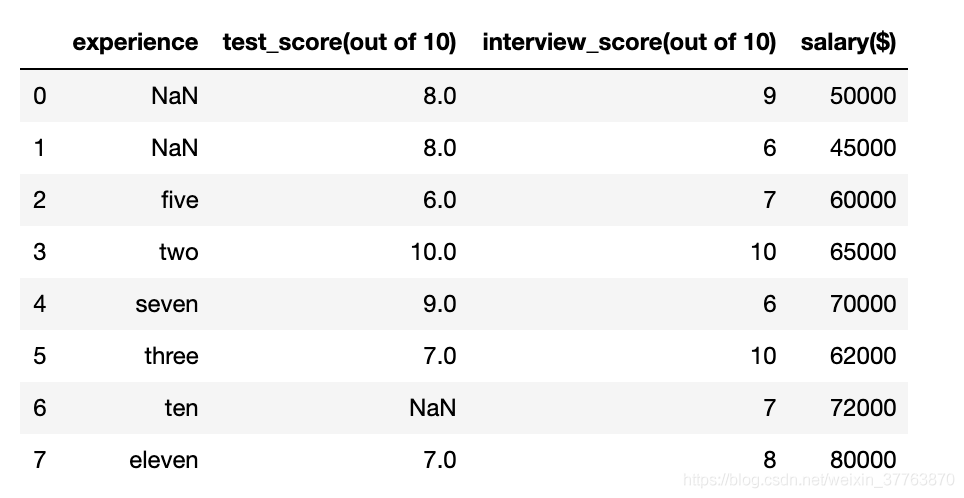
3.1 Digitalização do campo de experiência
df.experience = df.experience.fillna('zero') #NaN统一替换为zero
df
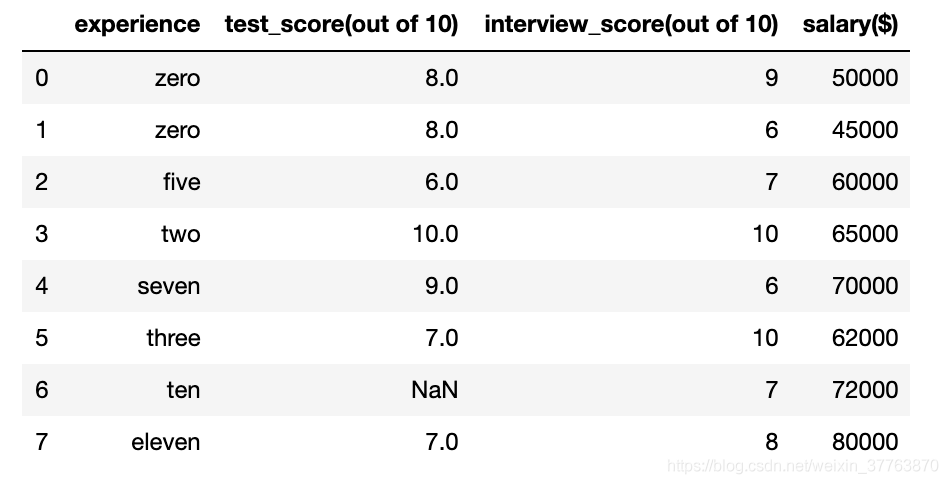
df.experience = df.experience.apply(w2n.word_to_num) #运用w2n.word_to_num将字母转化为数字
df
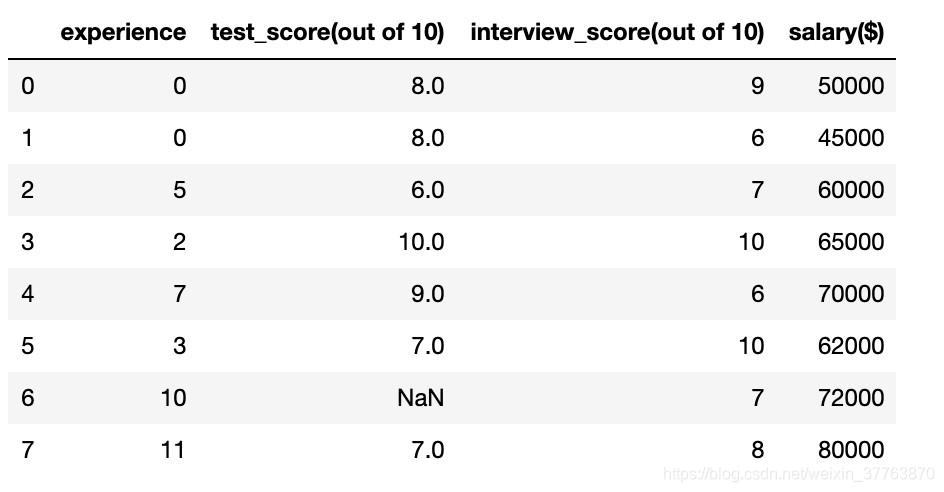
3.2 O campo Test_score (fora de 10) do campo NaN é substituído pela média
import math
median_test_score = math.floor(df['test_score(out of 10)'].mean()) #取平均数并向下取整
median_test_score
#输出
7
df['test_score(out of 10)'] = df['test_score(out of 10)'].fillna(median_test_score) #用平均数填充NaN
df
4. Treinamento + previsão
reg = LinearRegression() #实例化模型
reg.fit(df[['experience','test_score(out of 10)','interview_score(out of 10)']],df['salary($)']) #训练
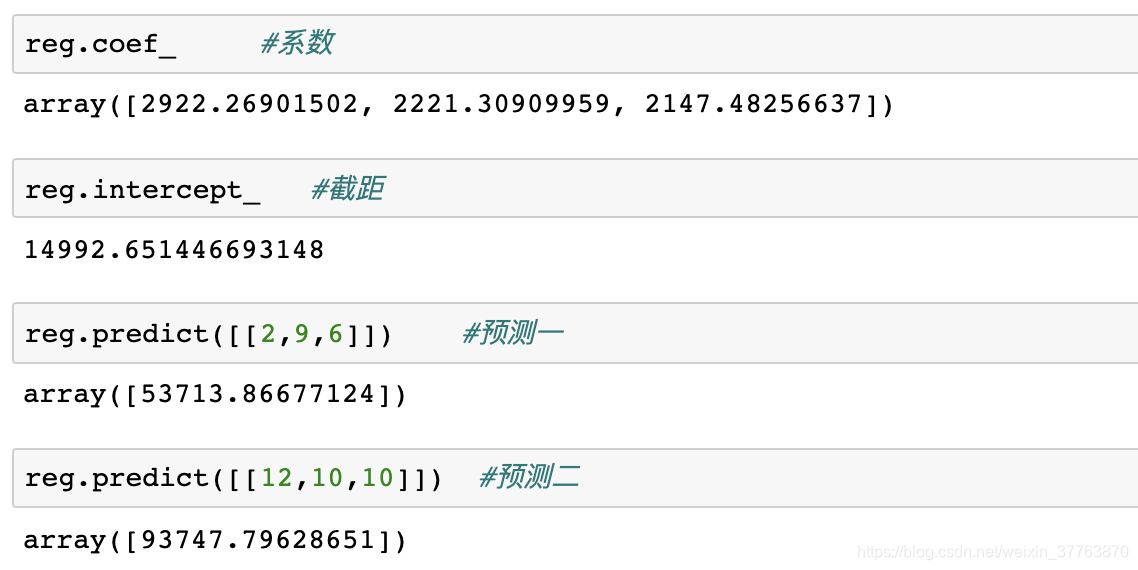
reg.coef_ #系数
reg.intercept_ #截距
reg.predict([[2,9,6]]) #预测一
reg.predict([[12,10,10]]) #预测二