
読み書きプロセス、コピー整合性メカニズム、ストレージメカニズム、高可用性メカニズムなどに関する Apache Doris のよくある質問を基に、Q&A 形式で整理して回答します。始める前に、この記事に関連する用語について説明しましょう。
-
FE : フロントエンド、Doris のフロントエンド ノード。主にクライアントリクエストの受信と返却、メタデータ、クラスター管理、クエリプラン生成などを担当します。
-
BE : バックエンド、Doris のバックエンド ノード。主にデータの保存と管理、クエリプランの実行などを担当します。
-
BDBJE : Oracle Berkeley DB Java Edition. Doris では、BDBJE はメタデータ操作ログの永続化、FE 高可用性、その他の機能を実現するために使用されます。
-
タブレット: タブレットはテーブルの実際の物理ストレージ ユニットです。テーブルはパーティションとバケットに従って BE によって形成される分散ストレージ層にタブレット単位で格納されます。各タブレットにはメタ情報と複数の連続する RowSet が含まれます。
-
RowSet : RowSet は、Tablet でのデータ変更のデータ コレクションです。データ変更には、データのインポート、削除、更新などが含まれます。RowSet はバージョン情報によってレコードを記録します。変更が行われるたびにバージョンが生成されます。
-
Version : Start と End の 2 つの属性で構成され、データ変更の記録情報を保持します。通常、RowSet のバージョン範囲を表すために使用されます。新しいインポートの後、開始と終了が等しい RowSet が生成されます。圧縮後、範囲指定された RowSet バージョンが生成されます。
-
Segment : RowSet 内のデータ セグメントを表し、複数のセグメントで RowSet を構成します。
-
圧縮: RowSet の連続したバージョンをマージするプロセスは圧縮と呼ばれ、データはマージ プロセス中に圧縮されます。
-
キー列、値列:Dorisではデータをテーブル形式で論理的に記述します。テーブルには行 (Row) と列 (Column) が含まれます。行はユーザー データの行であり、列はデータ行のさまざまなフィールドを記述するために使用されます。列は、キーと値の 2 つのカテゴリに分類できます。ビジネスの観点から見ると、キーと値はそれぞれディメンション列とインジケーター列に対応できます。Doris の Key 列は、テーブル作成ステートメントで指定された列です。テーブル作成ステートメント内のキーワードの一意キー、集計キー、または重複キーに続く列がキー列です。キー列に加えて、残りの列は値です。カラム。
-
データ モデル: Doris のデータ モデルは主に、集約、一意、重複の 3 つのカテゴリに分類されます。
-
ベース テーブル: Doris では、ユーザーがテーブル作成ステートメントによって作成したテーブルをベース テーブルと呼びます。ベース テーブルには、ユーザーのテーブル作成ステートメントで指定された方法で格納される基本データが格納されます。
-
ROLLUP テーブル: ベース テーブルの上に、ユーザーは任意の数の ROLLUP テーブルを作成できます。これらの ROLLUP データはベース テーブルに基づいて生成され、物理的に独立して保存されます。ROLLUP テーブルの基本的な機能は、マテリアライズド ビューと同様に、ベース テーブルに基づいてより粒度の粗い集計データを取得することです。
Q1: Doris パーティショニングとバケット化の違いは何ですか?
Doris は 2 つのレベルのデータ パーティショニングをサポートしています。
-
最初の層は Partition で、Range および List 分割メソッドをサポートします (MySQL のパーティション テーブルの概念に似ています)。複数のパーティションがテーブルを形成しており、パーティションは最小の論理管理単位とみなすことができます。データのインポートと削除は 1 つのパーティションに対してのみ可能です。
-
2 番目の層はバケット (タブレットはバケットとも呼ばれます) で、ハッシュとランダムの分割方法をサポートします。各タブレットには複数行のデータが含まれており、タブレット間のデータは交差せず、物理的に独立して保存されます。タブレットは、データの移動やコピーなどの操作を行うための最小の物理ストレージ ユニットです。
1 レベルのパーティショニングのみを使用することもできます。テーブルの作成時にパーティショニング ステートメントを作成しない場合、Doris はユーザーに対して透過的なデフォルトのパーティションを生成します。
表示は次のとおりです。
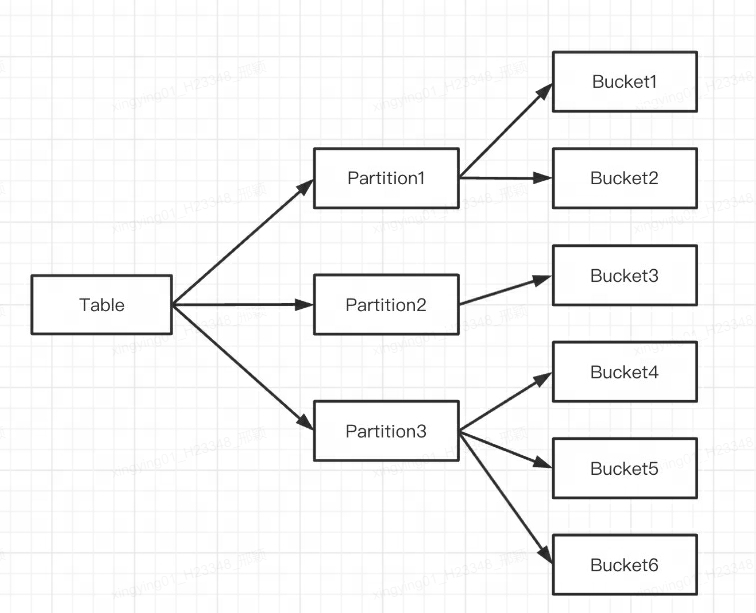
複数のタブレットは論理的に異なるパーティション(Partition)に属しており、1つのタブレットは1つのパーティションにのみ属し、1つのパーティションには複数のタブレットが含まれます。Tablet は物理的に独立して格納されているため、Partition も物理的に独立していると考えることができます。
論理的に言えば、パーティショニングとバケット化の最大の違いは、バケット化ではデータベースがランダムに分割されるのに対し、パーティショニングではデータベースが非ランダムに分割されることです。
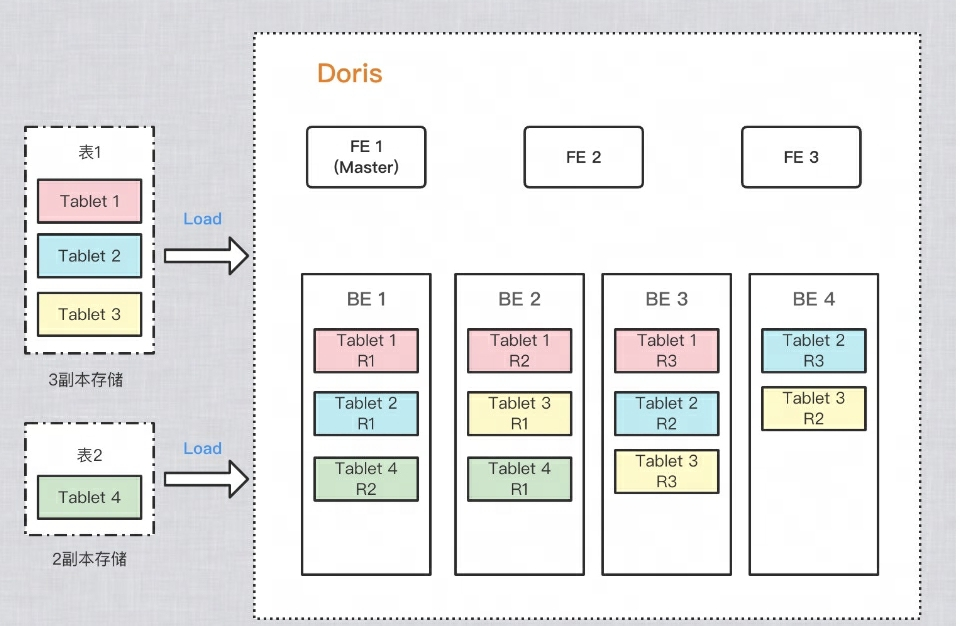
データの複数のコピーを確保するにはどうすればよいですか?
データ ストレージの信頼性と計算パフォーマンスを向上させるために、Doris は各テーブルのコピーを複数作成して保存します。データの各コピーはコピーと呼ばれます。Doris は、データのコピーを保存するための基本ユニットとしてタブレットを使用しています。デフォルトでは、シャードには 3 つのコピーがあります。テーブルを作成するときに、次のPROPERTIES項目でコピー数を設定できます。
PROPERTIES
(
"replication_num" = "3"
);
下図の例では、2 つのテーブルがそれぞれ Doris にインポートされており、テーブル 1 はインポート後に 3 つのコピーに保存され、テーブル 2 はインポート後に 2 つのコピーに保存されます。データの分布は以下の通りです。
Q2: バケット化が必要なのはなぜですか?
バケットに分割してデータ スキューを回避し、読み取り IO を分散してクエリ パフォーマンスを向上させるために、タブレットの異なるコピーを異なるマシンに分散して、クエリ中に異なるマシンの IO パフォーマンスを最大限に活用できます。
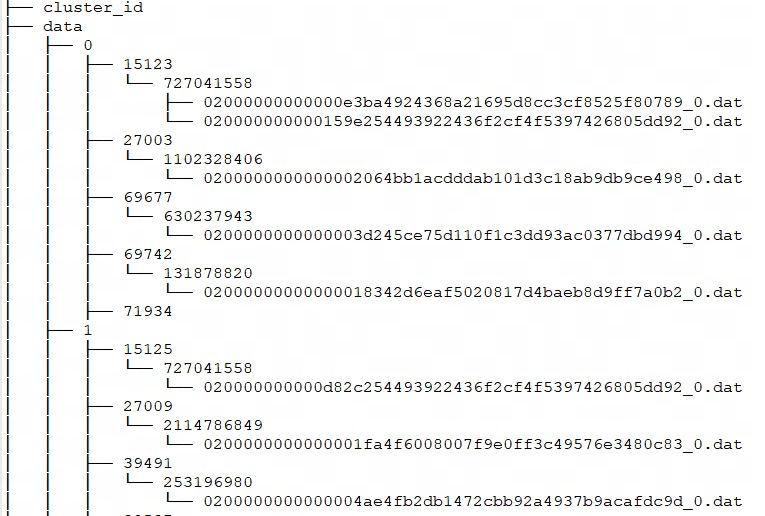
Q3: 物理ファイルのストレージ構造とフォーマットは何ですか?
Doris の各インポートはトランザクションとみなされ、RowSet が生成されます。また、RowSet には複数のセグメント、つまり が含まれますTablet-->Rowset-->Segment。それでは、BE はこれらのファイルをどのように保存するのでしょうか?
ドリスの収納構造
Doris はstorage_root_pathを通じてストレージ パスを設定し、セグメント ファイルはtablet_idディレクトリに保存され、SchemaHash によって管理されます。複数のセグメント ファイルが存在する可能性があり、通常はサイズに応じて分割されます。デフォルトは 256MB です。保存ディレクトリとセグメントファイルの命名規則は次のとおりです。
${storage_root_path}/data/${shard}/${tablet_id}/${schema_hash}/${rowset_id}_${segment_id}.dat
storage_root_pathディレクトリに入ると、次のストレージ構造が表示されます。
-
${shard}:上図の0、1です。これは BE によってストレージ ディレクトリに自動的に作成され、ランダムです。データの増加とともに増加します。 -
${tablet_id}:つまり、上図の15123、27003などで、前述のBucketのIDになります。 -
${schema_hash}: つまり、上の図の 727041558、1102328406 などです。テーブルの構造は変更される可能性があるため、スキーマ バージョンごとにテーブルが生成され、SchemaHashそのバージョンのデータを識別します。 -
${segment_id}.dat: 最初のものrowset_id、つまり、上図の 02000000000000e3ba4924368a21695d8cc3cf8525f80789 は、${segment_id}現在の RowSet でsegment_id、0 から始まり増加します。
セグメントファイルの保存形式
セグメントの全体的なファイル形式は、次の図に示すように、データ領域、インデックス領域、フッターの 3 つの部分に分かれています。

-
データ領域: 各列のデータ情報を格納するために使用されます。ここのデータはオンデマンドでページにロードされます。ページには列データが含まれており、各ページは 64k です。
-
インデックス領域: Doris は各列のインデックス データをインデックス領域に保存します。ここでのデータは列の粒度に従ってロードされるため、列データ情報とは別に保存されます。
-
フッター情報: ファイルのメタデータ情報、コンテンツのチェックサムなどが含まれます。
Q4: Doris のさまざまなテーブル モデルの DML 制限は何ですか?
-
Update: Update ステートメントは現在、UNIQUE KEY モデルのみをサポートし、Value 列の更新のみをサポートします。
-
削除: 1) テーブル モデルが集約クラス (AGGREGATE、UNIQUE) を使用する場合、削除操作ではキー列の条件のみを指定できます; 2) この操作では、このベース インデックスに関連するロールアップ インデックスのデータも削除されます。
-
挿入: すべてのデータ モデルを挿入できます。
インサートを実装するにはどうすればよいですか? データを挿入した後にデータをクエリするにはどうすればよいですか?
-
AGGREGATE モデル: 挿入フェーズでは、Append メソッドで増分データが RowSet に書き込まれ、クエリ フェーズでは、マージにMerge on Readメソッドが使用されます。つまり、データはインポート時に最初に新しい RowSet に書き込まれ、書き込み後に重複排除は実行されません。複数方向の同時ソートは、クエリが開始されたときにのみ実行されます。複数方向のマージ ソートを実行する場合、重複は行われません。データはソートされ、キーがまとめて配置され、集約されます。より高いバージョンのキーは、より低いバージョンのキーを上書きし、最終的には最も高いバージョンのレコードのみがユーザーに返されます。
-
DUPLICATE モデル: このモデルは上記と同様に記述されており、読み取りフェーズでは集計操作は行われません。
-
UNIQUE モデル: バージョン 1.2 より前は、このモデルは本質的に集約モデルの特殊なケースであり、動作は AGGREGATE モデルと一致していました。集計モデルはMerge on Read によって実装されるため、一部の集計クエリのパフォーマンスが低下します。Doris は、バージョン 1.2 以降の Unique モデルの新しい実装であるMerge on Writeを導入しました。これは、書き込み時に上書きおよび更新されたデータをマークして削除します。クエリ中に、マークおよび削除されたデータはすべて削除されます。データはファイル レベルでフィルタリングされます。読み取られたデータは最新のデータとなり、読み取り時のマージにおけるデータ集約プロセスが不要になり、多くの場合、複数の述語のプッシュダウンをサポートできます。
簡単に言えば、Merge on Write の処理フローは次のとおりです。
-
各キーについて、ベース データ (RowSetid + セグメント ID + 行番号) 内のその位置を見つけます [クエリを高速化するために、セグメント レベルの主キー間隔ツリーがメモリ内に維持されます]
-
キーが存在する場合は、データの行を削除対象としてマークします。削除対象としてマークされた情報は削除ビットマップに記録され、各セグメントには対応する削除ビットマップがあります。
-
更新されたデータを新しい RowSet に書き込み、トランザクションを完了して、新しいデータを表示します。つまり、ユーザーがクエリできるようになります。
-
クエリを実行するときは、削除ビットマップを読み取り、削除対象としてマークされた行をフィルターで除外し、有効なデータのみを返します [すべてのヒット セグメントについて、上位から下位のバージョンに従ってクエリを実行します]
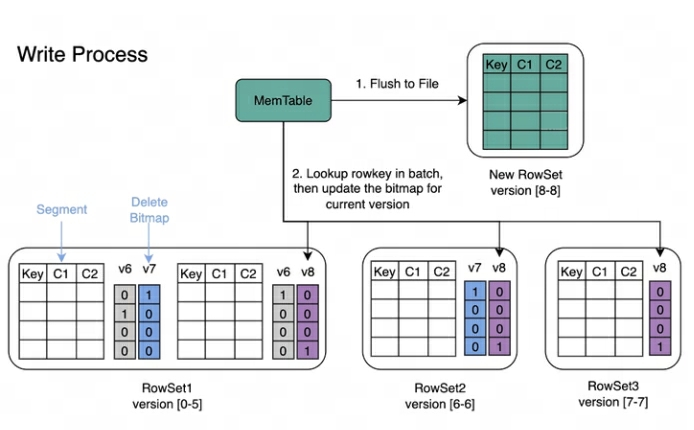
以下に書き込み処理と読み出し処理の実装を紹介します。
書き込み処理:データ書き込み時は、まず各セグメントの主キーインデックスが作成され、その後削除ビットマップが更新されます。
読み取りプロセス: Bitmap の読み取りプロセスを次の図に示します。
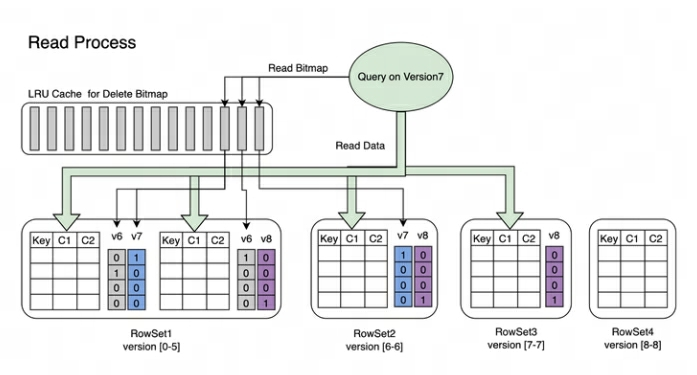
-
バージョン 7 をリクエストするクエリでは、バージョン 7 に対応するデータのみが表示されます。
-
RowSet5 のデータを読み取るとき、V6 および V7 の変更によって生成されたビットマップがマージされ、データのフィルター処理に使用される、Version7 に対応する完全な DeleteBitmap が取得されます。
-
上の例では、バージョン 8 のインポートは RowSet1 の Segment2 のデータをカバーしていますが、バージョン 7 を要求するクエリは引き続きデータを読み取ることができます。
アップデートはどのように実装されますか?
UNIQUE モデルの更新プロセスは、基本的に選択 + 挿入です。
-
Update では、クエリ エンジン独自の Where フィルター ロジックを使用して、更新対象のテーブルから更新が必要な行をフィルターで除外し、これに基づいて削除ビットマップを維持し、新しく挿入されたデータを生成します。
-
次に、Insert ロジックを実行します。具体的なプロセスは、前述の UNIQUE モデル作成ロジックと同様です。
Q5: ドリスの削除はどのように実装されますか? RowSet も生成されますか? 該当するデータを削除するにはどうすればよいですか?
-
Doris の Delete では RowSet も生成されます。DELETE モードでは、実際にデータは削除されませんが、データの削除条件が記録されます。メタ情報に格納されます。Base Compaction を実行すると、削除条件が Base バージョンにマージされます。
-
Doris は、UNIQUE KEY モデルでの LOAD_DELETE もサポートしています。これにより、削除するキーをバッチ インポートすることでデータを削除でき、大規模なデータ削除機能をサポートできます。全体的な考え方は、削除ステータス識別子をデータ レコードに追加することであり、削除されたキーは圧縮プロセス中に圧縮されます。圧縮は主に、複数の RowSet バージョンをマージする役割を果たします。
Q6: ドリスはどのようなインデックスを持っていますか?
現在、Doris は主に 2 種類のインデックスをサポートしています。
-
プレフィックス インデックスやゾーンマップ インデックスなどの組み込みスマート インデックス。
-
ユーザーが手動で作成するセカンダリ インデックスには、転置インデックス、ブルームフィルター インデックス、Ngram ブルームフィルター インデックス、およびビットマップ インデックスが含まれます。
ZoneMap インデックスは、列格納形式の列ごとに自動的に保持される最小値/最大値、Null 値の数などのインデックス情報です。このインデックス作成はユーザーに対して透過的です。
インデックスはどのレベルですか?
-
Doris のすべてのインデックスは、転置インデックス、ブルームフィルター インデックス、Ngram ブルームフィルター インデックスとビットマップ インデックス、プレフィックス インデックスとゾーンマップ インデックスなど、BE レベルのローカルになります。
-
ドリスにはグローバルインデックスがありません。広い意味では、パーティション + バケット キーもグローバルとみなされますが、比較的粒度が粗いです。
インデックスの保存形式は何ですか?
Dorisでは、各カラムのインデックスデータはセグメントファイルのインデックス領域に一律に格納されますが、ここのデータはカラム粒度に応じてロードされるため、カラムデータ情報とは別に格納されます。ここでは、例として Short Key Index プレフィックス インデックスを取り上げます。
ショート キー インデックス プレフィックス インデックスは、キー (AGGREGATE KEY、UNIQ KEY、および DUPLICATE KEY) ソートに基づいたインデックス方法で、特定のプレフィックス列に基づいてデータを迅速にクエリします。こちらのShort Key Indexインデックスもスパースインデックス構造を採用しており、データ書き込み処理中に一定行数ごとにインデックス項目が生成されます。この行数はインデックスの粒度であり、デフォルトは 1024 行であり、構成可能です。プロセスを以下に示します。
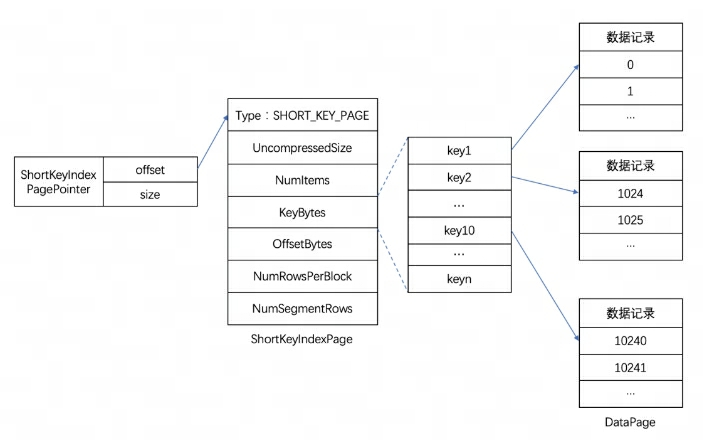
このうち、KeyBytes にはインデックス項目のデータが格納され、OffsetBytes には KeyBytes 内のインデックス項目のオフセットが格納されます。
ショート キー インデックスは、最初の 36 バイトをこのデータ行のプレフィックス インデックスとして使用します。VARCHAR 型が見つかった場合、接頭辞インデックスは直接切り捨てられます。ショート キー インデックスは、最初の 36 バイトをこのデータ行のプレフィックス インデックスとして使用します。VARCHAR 型が見つかった場合、接頭辞インデックスは直接切り捨てられます。
読み取りプロセスはどのようにしてインデックスにヒットしますか?
セグメント内のデータをクエリする場合、実行されたクエリ条件に従って、データはまずフィールド インデックスに基づいてフィルタリングされます。次にデータを読み取ります。全体的なクエリ プロセスは次のとおりです。
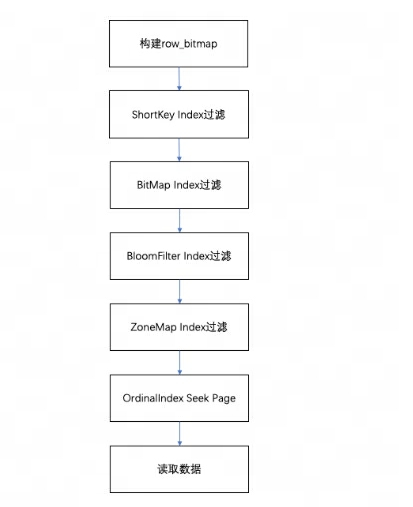
-
まず、セグメント内の行数に応じて、
row_bitmapどのデータを読み取る必要があるかを示すものが作成されます。すべてのデータはインデックスを使用せずに読み取る必要があります。 -
プレフィックス インデックス ルールに従ってクエリ条件でキーが使用されている場合、最初に ShortKey インデックスがフィルタリングされ、ShortKey インデックス内で一致する可能性のある Ordinal 行番号の範囲が に結合されます
row_bitmap。 -
クエリ条件の列フィールドに BitMap Index インデックスがある場合、条件を満たす Ordinal 行番号を BitMap Index に従って直接見つけ出し、row_bitmap と交差させてフィルタリングします。ここでのフィルタリングは正確です。後でクエリ条件が削除された場合、このフィールドは後続のインデックスに対してフィルタリングされません。
-
クエリ条件の列フィールドに BloomFilter インデックスがあり、条件が等しい場合 (eq、in、is)、BloomFilter インデックスに従ってフィルタリングされます。ここでは、すべてのインデックスがウォークスルーされ、各ページの BloomFilter が実行されます。すべてのページ。インデックス情報の Ordinal 行番号範囲と の
row_bitmap交差部分をフィルター処理します。 -
クエリ条件の列フィールドに ZoneMap インデックスがある場合、ZoneMap インデックスに従ってフィルタリングされます。ここでは、クエリ条件が ZoneMap と交差する可能性のあるすべてのページを検索するために、すべてのインデックスも実行されます。インデックス情報の Ordinal 行番号範囲と の
row_bitmap交差部分をフィルター処理します。 -
を生成した後
row_bitmap、各列の OrdinalIndex を使用して特定のデータ ページをバッチで検索します。 -
各列の列データページのデータをバッチで読み取ります。Null 値を含むページの場合、読み取り時に、Null 値のビットマップに基づいて現在の行が Null であるかどうかを判断し、Null の場合は直接入力します。
Q7: Doris はどのように圧縮を実行しますか?
Doris は、圧縮を使用して RowSet ファイルを段階的に集約し、パフォーマンスを向上させます。RowSet のバージョン情報は、マージされた RowSet のバージョン範囲を表すために、Start と End の 2 つのフィールドで設計されています。マージされていない累積 RowSet のバージョン Start と End は同じです。圧縮中に、隣接する RowSet がマージされて新しい RowSet が生成され、バージョン情報の開始と終了もマージされてより大きなバージョンが形成されます。一方、圧縮プロセスでは RowSet ファイルの数が大幅に削減され、クエリの効率が向上します。
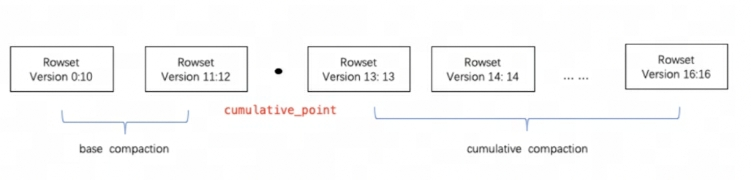
上図に示すように、圧縮タスクは基本圧縮と累積圧縮の 2 種類に分類されます。cumulative_point2 つの戦略を区別することが鍵となります。
これは次のように理解できます。
-
cumulative_point右側には、一度もマージされていない増分 RowSet があり、各 RowSet の開始バージョンと終了バージョンは同じです。 -
cumulative_point左側はマージされた RowSet です。開始バージョンと終了バージョンは異なります。 -
基本コンパクションと累積コンパクションのタスクプロセスは基本的に同じですが、唯一の違いはマージするInputRowSetを選択するロジックです。
圧縮はどのキーに基づいていますか?
-
セグメントでは、データは常に Key のソート順 (AGGREGATE KEY、UNIQ KEY、DUPLICATE KEY) で格納され、Key のソートによってデータ格納の物理構造が決まり、列データの物理構造の順序も決まります。
-
したがって、Doris Compaction プロセスは、AGGREGATE KEY、UNIQ KEY、および DUPLICATE KEY に基づいています。
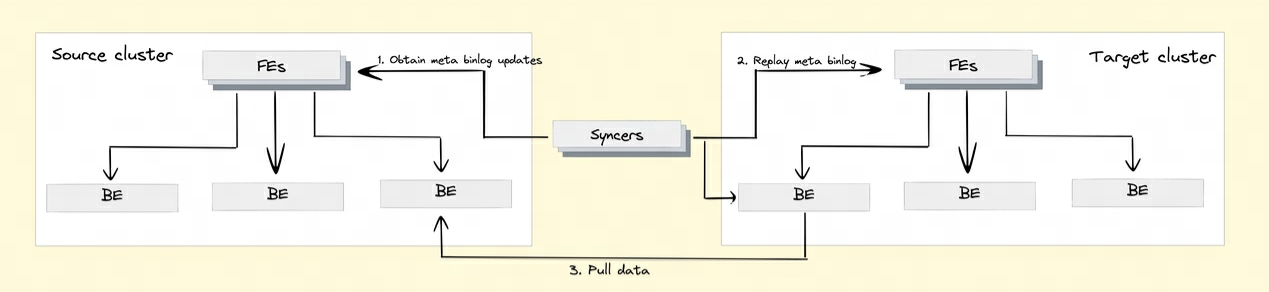
Q8: Doris はクラスタ間データ レプリケーションをどのように実装していますか?
クラスタ間データ レプリケーション機能を実現するために、Doris は Binlog メカニズムを導入しました。データの変更記録と操作は、Binlog メカニズムを通じて自動的に記録され、データのトレーサビリティを実現します。また、Binlog 再生メカニズムに基づいてデータの再生と復元も実現できます。
Binlog はどのように記録されますか?
Binlog 属性をオンにすると、FE と BE は DDL/DML 操作の変更レコードを Meta Binlog と Data Binlog に永続化します。
-
Meta Binlog: Doris は、ログの順序性を確保するために EditLog の実装を強化しました。LogID の増加シーケンスを構築することにより、各操作が正確に記録され、順番に保持されます。この順序付けされた永続化メカニズムは、データの一貫性を確保するのに役立ちます。
-
データ バイナリ: FE がパブリッシュ トランザクションを開始すると、BE は対応するパブリッシュ操作を実行します。BE は、RowSet を含むこのトランザクションのメタデータ情報を接頭辞付き
rowset_metaの、メタ ストレージに永続化します。送信後、インポートされたセグメント ファイルは次のようになります。 Binlog フォルダーにリンクされています。
ビンログの生成:
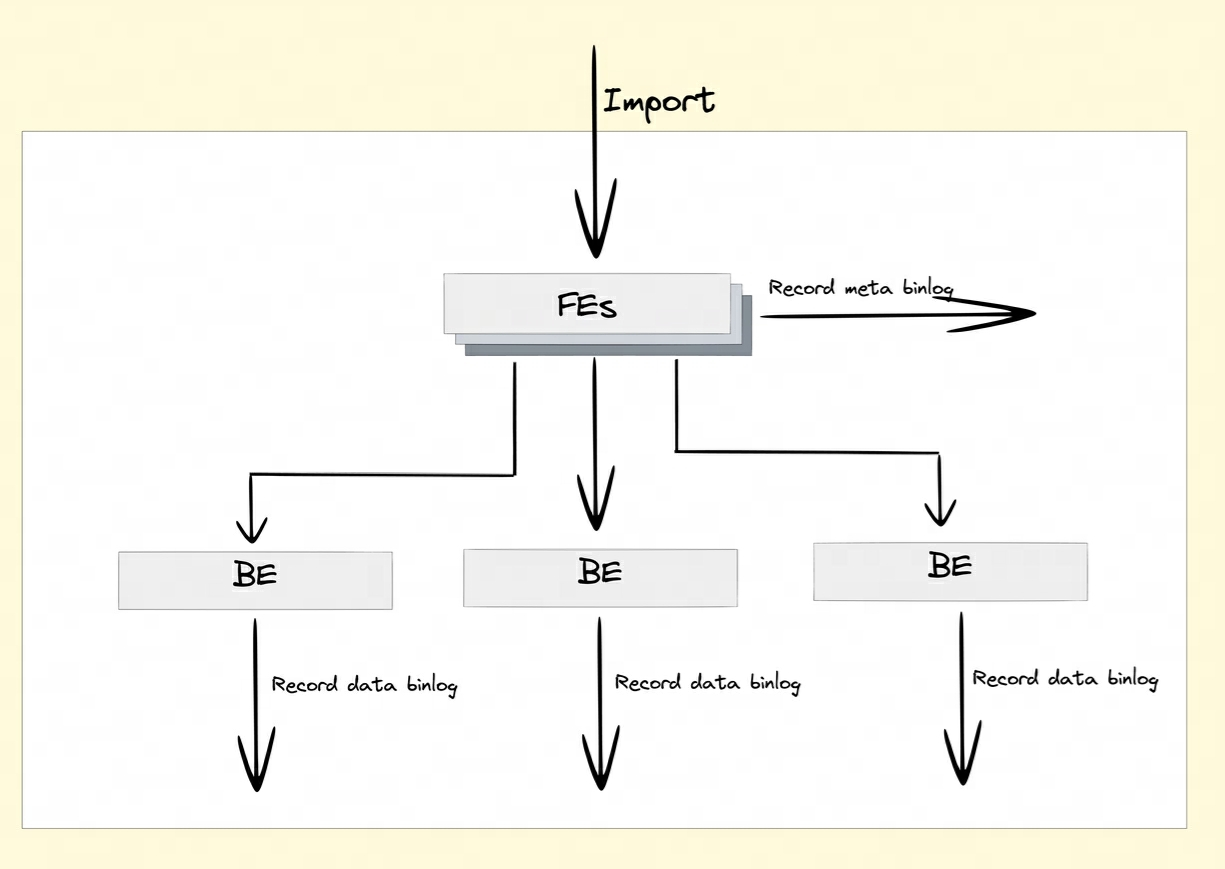
BInlog データの再生:
Q9: Doris のテーブルには複数のコピーがあります。書き込みフェーズ中に複数のコピーを確保するにはどうすればよいですか? マスター/スレーブの概念はありますか? Majority後に書き込み成功を返す必要はありますか?
-
Doris BE の 3 つのコピーにはマスター/スレーブの概念がなく、クォーラム アルゴリズムを使用してマルチコピー書き込みを保証します。
-
書き込みプロセス中に、FE は、データの書き込みに成功した各タブレットのコピー数がタブレットの総コピー数の半分を超えるかどうかを判断します。データの書き込みに成功した各タブレットのコピー数がタブレットの総数の半分を超える場合は、コピー (最も成功) の場合、コミット トランザクションは成功し、トランザクション ステータスは COMMITTED に設定されます。COMMITTED ステータスは、データは正常に書き込まれたが、データはまだ表示されていないことを示し、バージョンの公開タスクを続行する必要があります。その後、トランザクションをロールバックすることはできません。
-
FE には、成功したコミット トランザクションの公開バージョンを実行する別のスレッドがあります。FE が公開バージョンを実行すると、Thrift RPC を介して、トランザクションに関連するすべての Executor BE ノードに公開バージョン リクエストが送信されます。公開バージョン タスクは、各ノードで非同期に実行されます。 Executor BE ノード: 生成された RowSet にデータをインポートし、それを可視データ バージョンにします。
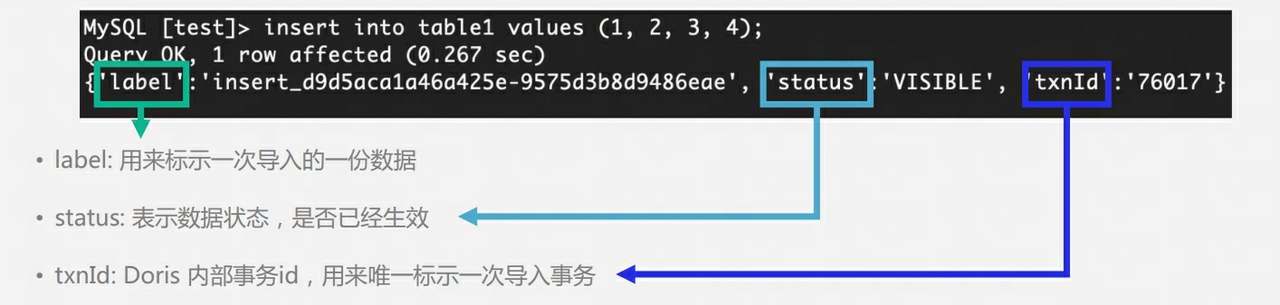
パブリッシュ メカニズムがある理由: MVCC と同様に、パブリッシュ メカニズムがない場合、ユーザーはまだ送信されていないデータを読み取る可能性があります。
テーブルに 3 つのコピーがあり、1 つのコピーだけが正常に書き込まれた場合はどうなりますか: この時点で、トランザクションは中止されます。
テーブルに 3 つのコピーがあり、2 つのコピーだけが正常に書き込まれた場合はどうなりますか: この時点で、トランザクションは COMMITTED になり、Doris FE は定期的にタブレットの監視と検査を実行します。タブレットのコピーに異常が見つかった場合、クローンが作成されます。新しいコピーを複製するタスクが生成されます。
ユーザーが Insert Into を実行した直後にクエリを実行し、結果が空になるのはなぜですか? その理由は、トランザクションがまだ公開されていないためです。
Q10: Doris の FE はどのようにして高可用性を確保しますか?
メタデータ レベルでは、Doris は Paxos プロトコルとメモリ + チェックポイント + ジャーナル メカニズムを使用して、メタデータの高いパフォーマンスと高い信頼性を保証します。
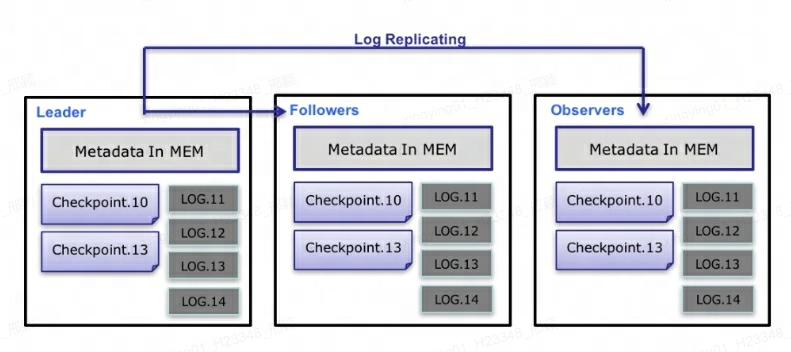
メタデータ データ フローの具体的なプロセスは次のとおりです。
-
リーダー FE のみがメタデータを書き込むことができます。書き込み操作によってリーダーのメモリが変更されると、そのメモリはログにシリアル化され、
key-valueの形式で BDBJE に書き込まれます。Key は連続整数、log idValue はシリアル化された操作ログです。 -
ログが BDBJE に書き込まれた後、BDBJE はポリシー (過半数書き込み/すべて書き込み) に従ってログを他の非リーダー FE ノードにコピーします。非リーダー FE ノードは、ログを再生することで自身のメタデータ メモリ イメージを変更し、リーダー ノードとのメタデータ同期を完了します。
-
リーダー ノード上のログの数がしきい値 (デフォルトでは 100,000) に達し、チェックポイント スレッドの実行サイクル (デフォルトでは 60 秒) を満たしています。チェックポイントは、既存のイメージ ファイルと後続のログを読み取り、メモリ内の新しいメタデータ イメージ コピーを再生します。次に、コピーがディスクに書き込まれ、新しいイメージが形成されます。既存のイメージをイメージとして書き込む代わりにイメージのコピーを再生成する理由は、主に、イメージへの書き込みと読み取りロックの追加によって書き込み操作がブロックされるためです。したがって、各チェックポイントは 2 倍のメモリ領域を占有します。
-
イメージ ファイルが生成されると、リーダー ノードは他の非リーダー ノードに新しいイメージが生成されたことを通知します。非リーダーは、HTTP 経由で最新のイメージ ファイルを積極的に取得し、古いローカル ファイルを置き換えます。
-
BDBJEのログはイメージ化完了後、定期的に古いログが削除されます。
説明する:
-
メタデータの各更新は、まずディスク上のログ ファイルに書き込まれ、次にメモリに書き込まれ、最後に定期的にローカル ディスクにチェックポイントが設定されます。
-
これは純粋なメモリ構造と同等であり、すべてのメタデータがメモリにキャッシュされるため、クラッシュ後に FE がメタデータを失うことなく迅速にメタデータを復元できることが保証されます。
-
Leader、Follower、Observer の 3 つで信頼性の高いサービスを構成します 1 つのノードに障害が発生した場合、結局 FE ノードにはメタデータのコピーが 1 つしか保存されず、その負荷は大きくないため、基本的には 3 つで十分です。 FE が多すぎるとマシン リソースが消費されるため、ほとんどの場合、可用性の高いメタデータ サービスを実現するには 3 つで十分です。
-
ユーザーは MySQL を使用して任意の FE ノードに接続し、メタデータへの読み取りおよび書き込みアクセスを行うことができます。接続が非リーダー ノードへの場合、ノードは書き込み操作をリーダー ノードに転送します。
著者について
Invisible (Xing Ying) は NetEase のシニア データベース カーネル エンジニアで、卒業以来データベース カーネルの開発に従事し、現在は主に MySQL と Apache Doris の開発、保守、ビジネス サポートに携わっています。MySQL カーネルの貢献者として、彼は MySQL の 50 を超えるバグと最適化項目を報告し、複数の提出が MySQL 8.0 バージョンに組み込まれました。2023 年から Apache Doris コミュニティに参加している Apache Doris アクティブ コントリビューターは、コミュニティに数十のコミットを送信してマージしてきました。
中学校が「インテリジェントな対話型カタルシス デバイス」を購入 - これは実際に任天堂 Wii のケースです TIOBE 2023 年間最優秀プログラミング言語: C# Kingsoft WPS がクラッシュ Linux の Rust 実験は成功、Firefox はチャンスを掴めるか…に関する 10 の予測オープンソース 女性幹部による従業員解雇事件の続報:同社会長は従業員を「常習犯」と呼び、「虚偽の学歴履歴書」に疑問を呈した オープンソースのアーティファクトLSPosedは、更新を停止すると発表した。悪意のある攻撃の数。2024 年のフロントエンドサークルの「今年の戦い」: React は穴を掘ることができません。書類で記入する必要がありますか? Linux カーネル 6.7 が正式にリリースされる 「ポスト・オープンソース」の時代が到来: ライセンスは無効であり、一般大衆にサービスを提供することはできない 女性幹部は不法解雇された 従業員は海賊版 EDA ツールの使用に反対し、声を上げ、標的にされたデザインチップ。