
著者: SelectDB技術チーム
現在、企業のデータ クエリのニーズは増え続けており、同じクラスターを共有する場合、複数のビジネス ラインからの同時クエリや複数の分析負荷に同時に直面する必要があります。リソースが限られている状況では、クエリ タスク間のリソースのプリエンプションはパフォーマンスの低下を引き起こし、さらにはクラスターの不安定性を引き起こす可能性があるため、負荷管理の重要性は自明のことです。
ビジネス シナリオから始めて、ユーザー負荷管理の要件は主に次の側面から生じます。
- 複数の事業部門やテナントが同じクラスタを共有する場合、異なるテナント間の負荷の相互作用を避けるために、各テナントのリソース使用の独立性とパフォーマンスの安定性を確保する必要があります。
- リアルタイム データ分析やオンライン トランザクションなどの主要なビジネスや優先度の高いタスクについては、ビジネスごとに異なる要件があり、これらのタスクが十分なリソースを確保できるようにする必要があります。リソースの競合を避けるために優先的に実行されます。クエリのパフォーマンスに影響を与えます。
- ユーザーはリソースの割り当てと管理だけでなく、コスト管理やリソースの使用状況にも注意を払っています。負荷管理ソリューションは、分離要件を満たすと同時に、低い使用コストと高いリソース使用率に対するユーザーの要求も実現する必要があります。
初期のバージョンでは、Apache Doris は、クラスター内のノードレベルのリソース グループ分割や個々のクエリのリソース制限を含む、リソース タグに基づく分離ソリューションを開始し、異なるユーザー間でのリソースの物理的な分離を実現しました。より完全な負荷管理ソリューションをユーザーに提供するために、Apache Doris はバージョン 2.0 以降、ワークロード グループに基づく管理ソリューションを開始しました。これにより、CPU リソースのソフト制限が実現され、ユーザーのリソース使用率が向上します。新しくリリースされたバージョン 2.1 は、Linux カーネルによって提供される CGroup テクノロジーに基づいており、 CPU リソースに対するハード制限をさらに実装し、ユーザーにクエリの安定性を向上させます。
リソースタグに基づく物理的隔離ソリューション
Apache Doris には FE と BE の 2 種類のノードがあり、FE ノードはメタデータ ストレージ、クラスター管理、ユーザー リクエスト アクセス、クエリ プラン分析などを担当し、BE ノードはデータ ストレージと計算を担当します。クエリ実行プロセスに関係する主なリソース消費は BE ノードであるため、Apache Doris 負荷分離ソリューションは BE ノード向けに設計されています。
リソースタグリソース物理分離ソリューションでは、同じクラスタ内のBEノードにタグを設定でき、同じタグを持つBEノードがリソースグループ(リソースグループ)を形成し、リソースグループをデータストレージの単位とみなすことができます。そしてコンピューティング。データがデータベースに入力されると、データのコピーがリソース グループの構成に従って異なるリソース グループに書き込まれ、クエリ時に、リソース グループの分割に従って、対応するリソース グループ上のコンピューティング リソースが計算に使用されます。
参考ドキュメント: https://dris.apache.org/zh-CN/docs/2.0/admin-manual/resource-admin/multi-tenant
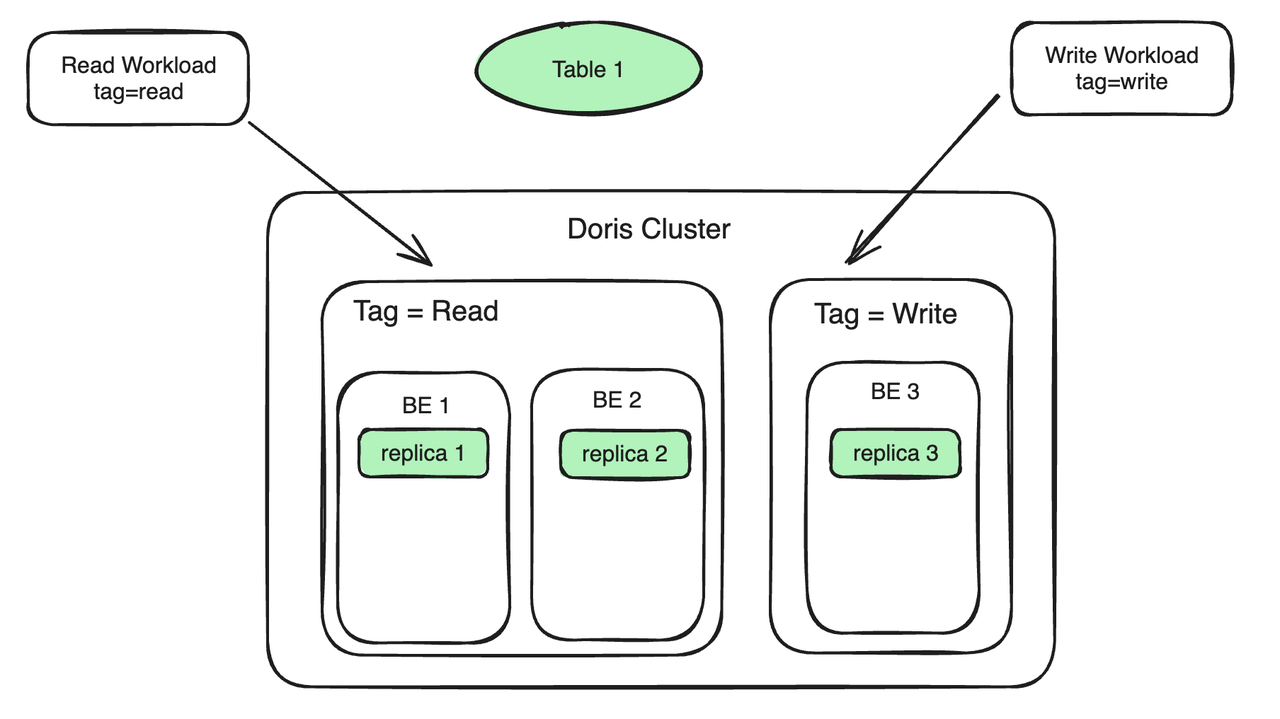
例として、一般的な読み取り/書き込み分析シナリオを考えてみましょう。具体的な使用手順は次のとおりです。
- BE ノード バインディング リソース タグ: 2 つの BE を Tag Read にバインドして読み取り負荷を処理し、1 つの BE を Tag Write にバインドして書き込み負荷を処理します。読み取りワークロードと書き込みワークロードは、読み取りと書き込みの分離を実現するために別のマシンに配置されます。
- データ コピーはリソース タグにバインドされます。表 1 には 3 つのコピーがあり、2 つのコピーはタグ読み取りにバインドされ、1 つのコピーはタグ書き込みにバインドされます。レプリカ 3 に書き込まれたデータは、レプリカ 1 とレプリカ 2 に自動的に同期されます。同期プロセスは、BE 1 と BE 2 のコンピューティング リソースをあまり占有しません。
- ワークロードはリソース タグにバインドされます。クエリ SQL によって保持されるタグが読み取りの場合、ストリーム ロードがインポートされると、クエリはタグが読み取りとしてマシン (BE 1、BE 2) に自動的にルーティングされます。ロードにロードされ、指定されたタグが Write である場合、ストリーム ロードはタグが Write であるマシンにルーティングされます (BE 3)。このプロセスでは、レプリカの同期中に生成されるオーバーヘッドに加えて、クエリとインポートの間でリソースの競合がなくなりました。
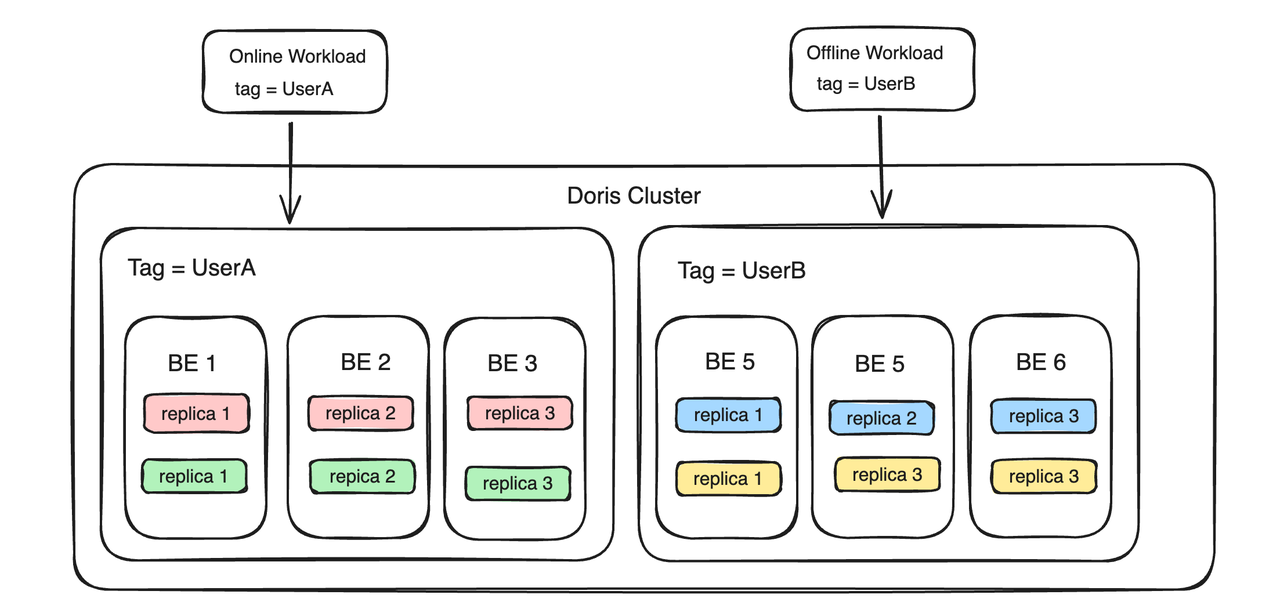
リソースタグはマルチテナント機能も実装できます。たとえば、UserA と UserB という 2 人のユーザーがおり、相互の影響を避けるために独立したテナントを作成したいと考えています。その後、UserA のコンピューティング リソースとストレージ リソースを UserA という名前のタグにバインドし、UserB のコンピューティング リソースとストレージ リソースを UserA という名前のタグにバインドできます。 . が UserB のタグである場合、2 人のユーザーは BE 側のテナント間でリソースの分離を実現します。
リソース タグの本質は、BE ノードをグループ化することでリソースの分離を実現することです。このソリューションの利点は次のとおりです。
- 優れた分離。複数のテナントが物理マシンを通じて分離され、CPU、メモリ、および IO の完全な分離が実現されます。
- 障害分離。一方のテナントで問題が発生した場合 (プロセス クラッシュなど)、もう一方のテナントはまったく影響を受けません。
このテクノロジーに基づいて、一部のユーザーは、異なるリソース グループを異なる物理的なコンピューター ルームに配置して、同じ都市内の 2 つのコンピューター ルームのアクティブ/アクティブ操作を実現します。
ただし、次のような制限もあります。
- 読み取り/書き込み分離シナリオでは、書き込み負荷が停止すると、書き込みタグを持つマシンはアイドル状態になり、クラスター全体のリソース使用率が低下します。これでは明らかに、リソースの完全な使用率に対するユーザーの期待に応えることができません。
- マルチテナントのシナリオでは、同じテナント内の複数のビジネス パーティの負荷も相互に影響します。たとえビジネス パーティごとに個別の物理マシンを構成することで分離を実現できたとしても、コストが高くつく、リソースの使用率が低いなどの問題が発生します。
- 柔軟性が低く、実際にはテナントの数はレプリカの数に制限されます。5 つのテナントを確立する場合は、少なくとも 5 つのレプリカが必要となり、ある程度のストレージ領域が無駄になります。
ワークロード グループに基づく負荷管理ソリューション
上記の問題を解決するために、Apache Doris はワークロード グループに基づく管理ソリューションを開始しました。これは、よりきめ細かいリソース分離メカニズム、つまりプロセス内リソース分離をサポートします。つまり、同じ BE 内の複数のクエリ ルームでも、ある程度分離すると、プロセス内のリソースの競合が効果的に回避され、リソースの使用率が向上します。
ワークロード グループは、ワークロードをグループで管理し、メモリと CPU リソースの高度な管理と制御を実現します。ユーザーが実行するクエリをワークロード グループに関連付けることにより、単一 BE ノード上の単一クエリの CPU およびメモリ リソースの割合を制限します。同時に、メモリ リソース制限を構成して有効にすることができます。クラスター リソースが不足している場合、グループ内でメモリ使用量が多いクエリは自動的に終了され、負荷が軽減されます。リソースがアイドル状態の場合、複数のワークロード グループがアイドル状態のリソースを共有し、制限を自動的に突破して安定したクエリの実行を保証します。
CPU リソースの制限は、ソフト リミットとハード リミットに分類できます。CPU ソフト リミットは、リソース使用率が高く、リソースがアイドル状態のときにリソースを柔軟に割り当てることができるという特徴があります。一方、CPU ハード リミットは、パフォーマンスの安定性を確保し、グループが確実にパフォーマンスを維持できるようにすることに重点を置いています。負荷の変化によって相互に干渉しません。
( CPU ハード リミットとソフト リミットの 2 つの分離方法は、さまざまな使用シナリオに適合しますが、同時に適用することはできません。ユーザーは自分のニーズに応じて柔軟に選択できます)
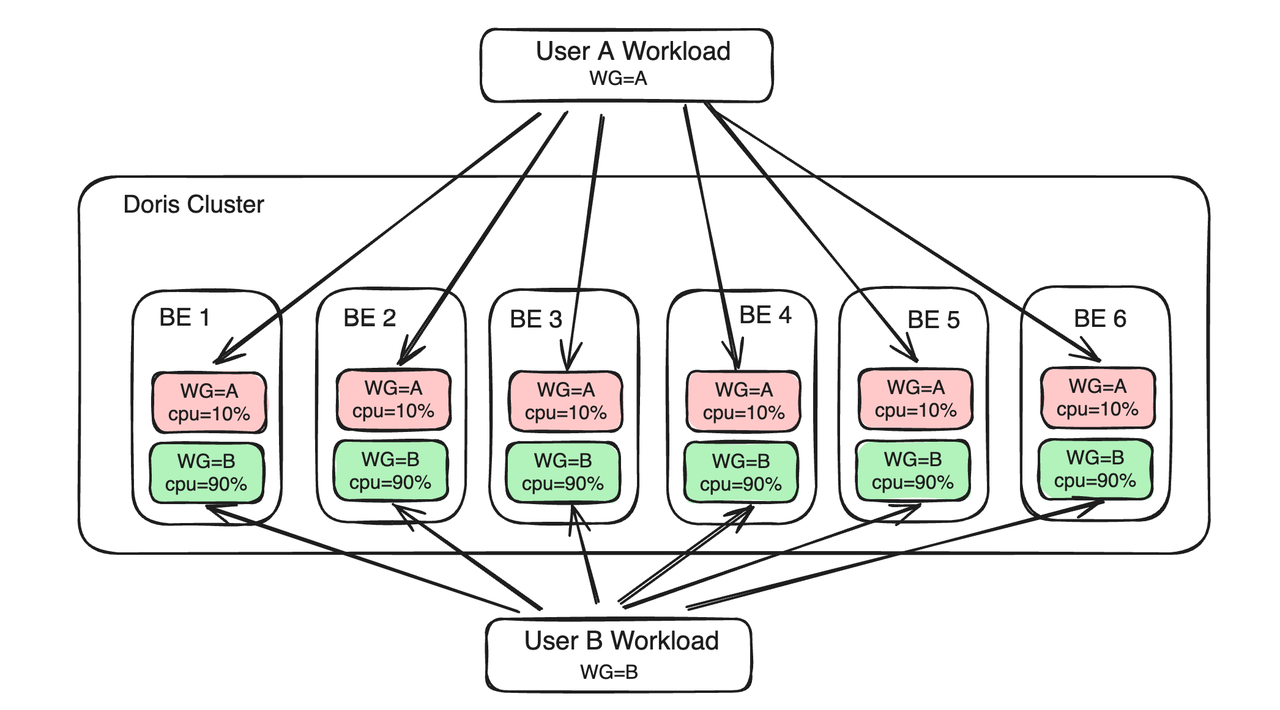
ワークロード グループ ソリューションとリソース タグ ソリューションの主な違いは次のとおりです。
- コンピューティング リソースの観点から見ると、ワークロード グループは BE プロセス内の CPU リソースとメモリ リソースをさらに分割し、複数のワークロード グループが同じ BE 上のリソースを競合する必要があります。リソース タグは BE ノードをグループ化し、異なるビジネス パーティの負荷は異なるグループ内の BE に送信されて、リソースの分離が実現されます。異なる BE グループ内のビジネス ロード間でリソースが直接競合することはありません。
- ストレージ リソースの観点から見ると、ワークロード グループはストレージ リソースに注意を払う必要はなく、単一 BE 内のコンピューティング リソースの割り当てのみに焦点を当てます。リソース タグでは、分離する必要があるビジネス側のデータが異なる BE に確実に分散されるように、データのコピーをグループ化する必要があります。
01 CPUソフトリミット
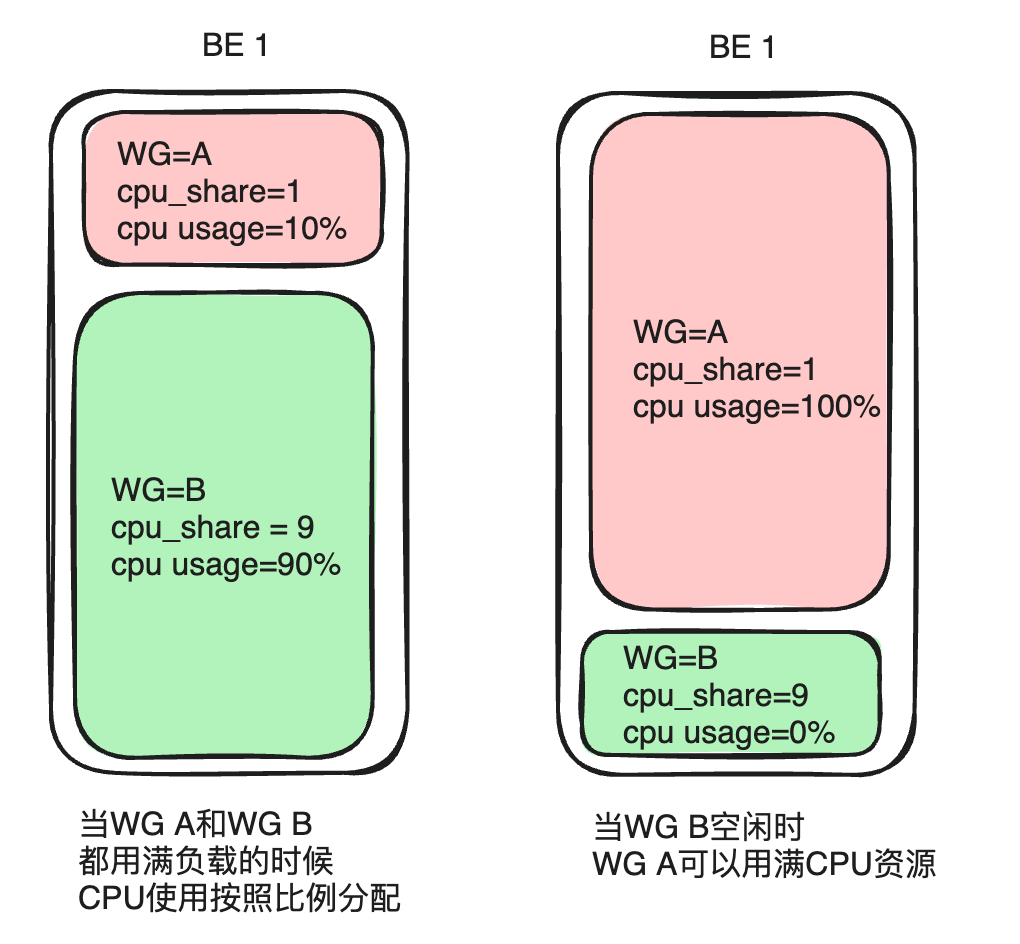
CPU の優先度は主にcpu_shareパラメータを通じて反映され、これは重みの概念にたとえることができます。同じ期間内で、重みが高いグループはより多くの CPU 時間を取得できます。
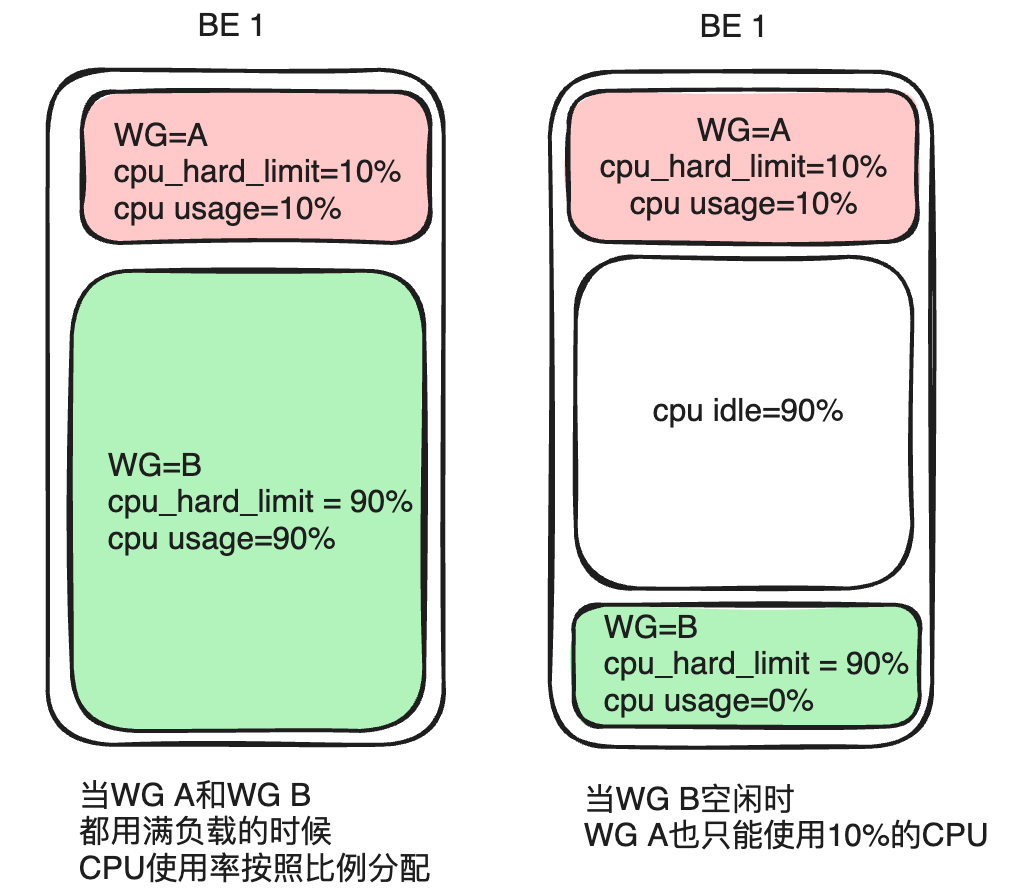
グループ A とグループ B を例に挙げます。グループ A がcpu_share1 に設定され、グループ B がcpu_share9 に設定されている場合、期間は 10 秒になります。両方の負荷が飽和した場合、重みの高いグループ B は 9 秒間 (全リソースの 90%) の CPU 時間を取得でき、グループ A は 1 秒間 (全リソースの 10%) の CPU 時間を取得できます。実際の使用では、すべてのサービスがフル負荷で実行されるわけではありません。グループ B の負荷が低いか無負荷の場合、グループ A が 10 秒間 CPU 時間を独占する可能性があります。この方法により、リソース割り当ての柔軟性が向上し、クラスター CPU リソースの全体的な使用率が向上します。
02 CPUハードリミット
システム負荷が高い場合や CPU リソースが不足している場合、CPU ソフト時間制限を使用すると、クエリのパフォーマンスが変動する可能性があります。安定したクエリ パフォーマンスに対するユーザーの高い要件を満たすために、Apache Doris は最新バージョン 2.1 でワークロード グループの CPU ハード制限を実装しました。これは、現在の物理マシンの CPU 全体がアイドル状態であるかどうか、最大 CPU 使用率に関係なく、ワークロード グループの CPU ハード制限を実装しています。ハード制限が設定されたグループは、事前に設定された制限値を超えることはできません。
グループ A とグループ B を例に挙げて、グループ Acpu_hard_limit=10%とグループ Bを設定しますcpu_hard_limit=90%。両方の単一マシンの CPU リソースが飽和に達すると、グループ A の CPU 使用率は 10%、グループ B の CPU 使用率は 90% になり、これは CPU ソフト リミットと同じになります。ただし、グループ B の負荷が減少するか負荷がなくなると、グループ A がクエリ負荷を増やしても、最大 CPU 使用率は依然として 10% に厳しく制限され、それ以上のリソースを取得できません。このアプローチではリソース割り当ての柔軟性が犠牲になりますが、クエリ パフォーマンスの安定性も確保されます。
03 メモリリソースの制限
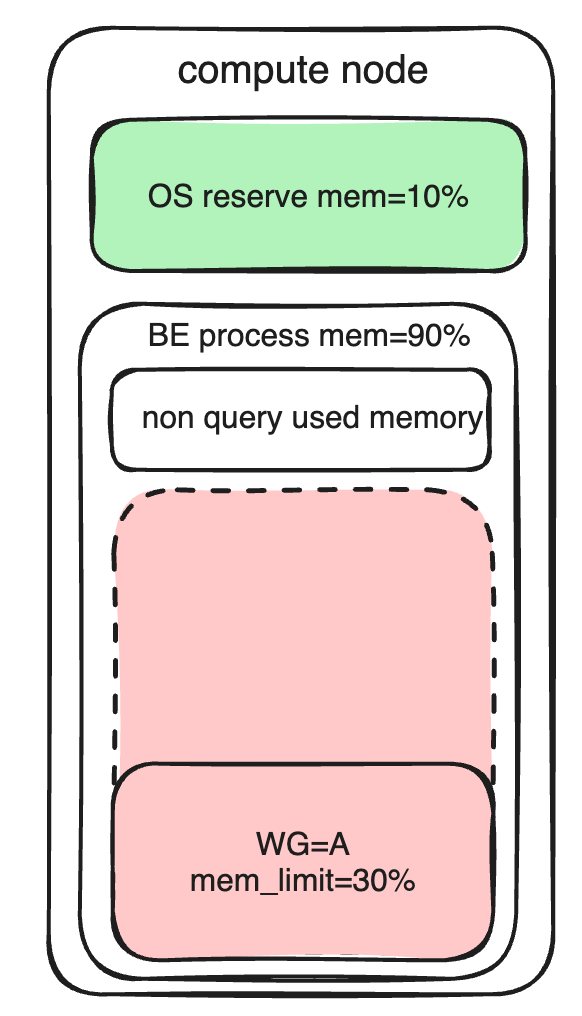
使用説明: BE ノードのメモリは主に次の部分に分かれています。
- オペレーティング システムがメモリを予約する
- BE プロセスのメモリの非クエリ部分は、当面はワークロード グループでカウントできません。
- BE プロセス内のクエリ部分のメモリ (インポート操作を含む) は、ワークロード グループによってカウントおよび管理できます。
メモリ リソースの制限は、主にmemory_limitパラメータ (使用できる BE メモリの割合の設定) によって制限されます。事前構成されたメモリ使用量を設定できるだけでなく、オーバーコミット後にメモリを返す優先順位にも影響を与えることができます。
初期状態では、優先度の高いリソース グループにはより多くのメモリが割り当てられ、優先度の低いリソース グループにはより少ないメモリが割り当てられます。メモリ使用率を向上させるために、enable_memory_overcommitシステムに空きメモリ リソースがある場合は、リソース グループのメモリ ソフト制限を有効にし、制限を超えて使用できます。
システムの安定した動作を確保するために、システム全体のメモリ リソースが不足している場合、システムは大量のメモリを占有するタスクを優先的にキャンセルし、オーバーコミットされたメモリ リソースを再利用します。このプロセス中、システムは優先度の高いリソース グループのメモリ リソースを予約しようとし、優先度の低いリソース グループの余分なメモリはより速く再利用されます。
04 クエリキュー
ビジネス負荷がシステムの上限を超えた場合、新しいクエリを送信し続けると、効果的に実行できないだけでなく、実行中のクエリにも影響を及ぼします。この問題を回避するために、ワークロード グループはクエリ キューイングをサポートしています。クエリが事前に設定された最大同時実行数に達すると、新しい送信プランはキュー ロジックに入り、キューがいっぱいになるか待機がタイムアウトになると、高負荷時のシステムへの負担を軽減するためにクエリが拒否されます。
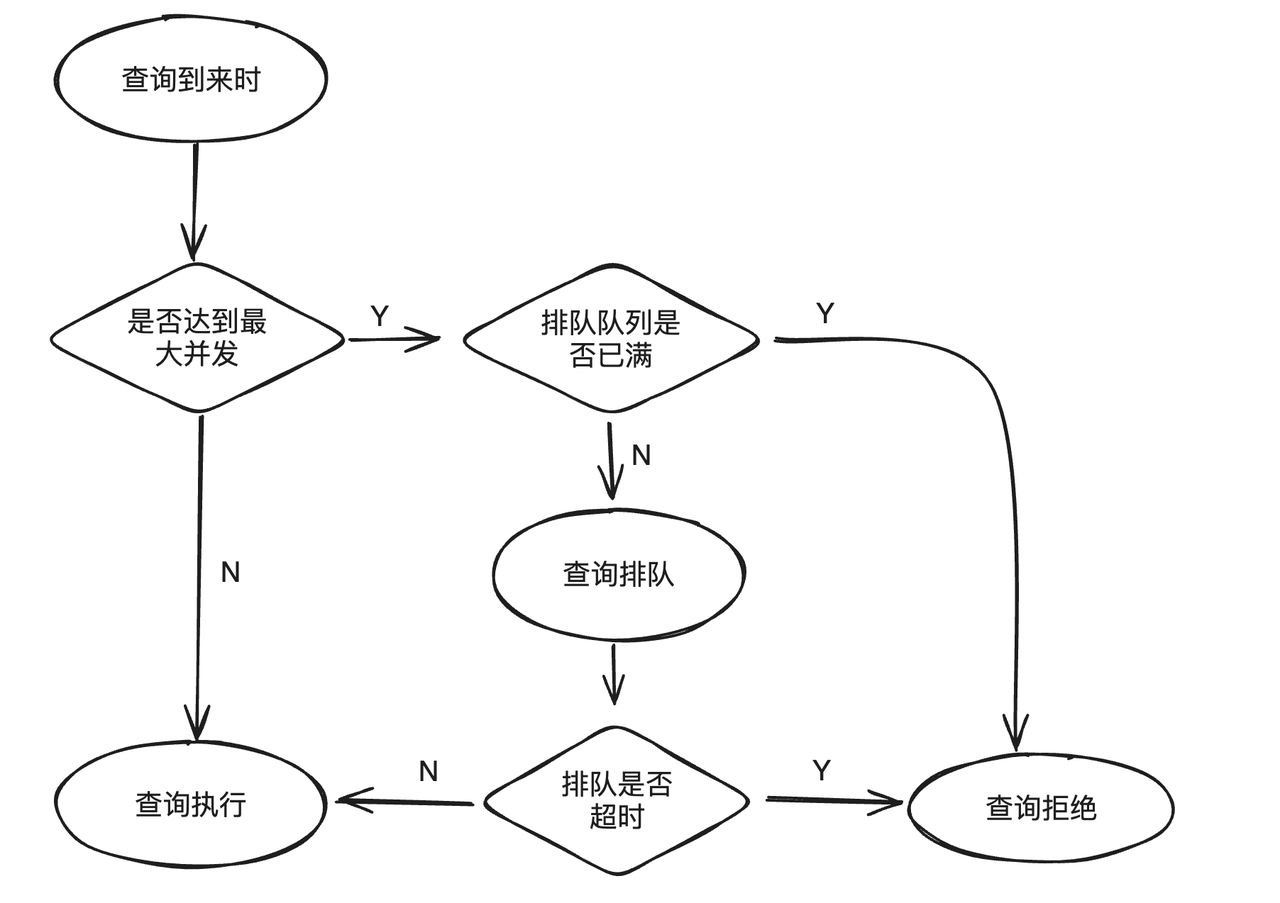
クエリキューイング機能には主に 3 つの属性があります。
max_concurrency: 現在のグループで同時に実行できる SQL ステートメントの最大数。最大数を超えると、キューイング ロジックが開始されます。max_queue_size: キュー内で許可されるクエリの最大数。キューがいっぱいの場合、クエリは拒否され、実行は失敗します。queue_timeout: キューのキューイングの制限時間。単位はミリ秒です。
参考ドキュメント: https://dris.apache.org/zh-CN/docs/admin-manual/workload-group
ワークロード グループの使用テスト
次に、ワークロード グループの CPU ソフト リミットとハード リミットについて詳細なテストを実行し、同じハードウェア条件下でのこれら 2 つの制限の負荷管理効果とパフォーマンスをユーザーに明確に示します。
- テスト環境: 16 コア 64G メモリの単一物理マシン
- 展開方法: 1 FE、1 BE
- テストデータセット: クリックベンチ、TPCH
- 応力測定ツール:JMeter
01 CPUソフトリミットテスト
2 つのクライアント (1、2) を起動して、それぞれ CPU ソフト リミットを使用せずに、負荷管理に対する CPU ソフト リミットの影響をテストします。このテストでは、ページ キャッシュがテスト結果に影響するため、理想的なテスト結果を得るにはページ キャッシュをオフにする必要があることに注意してください。
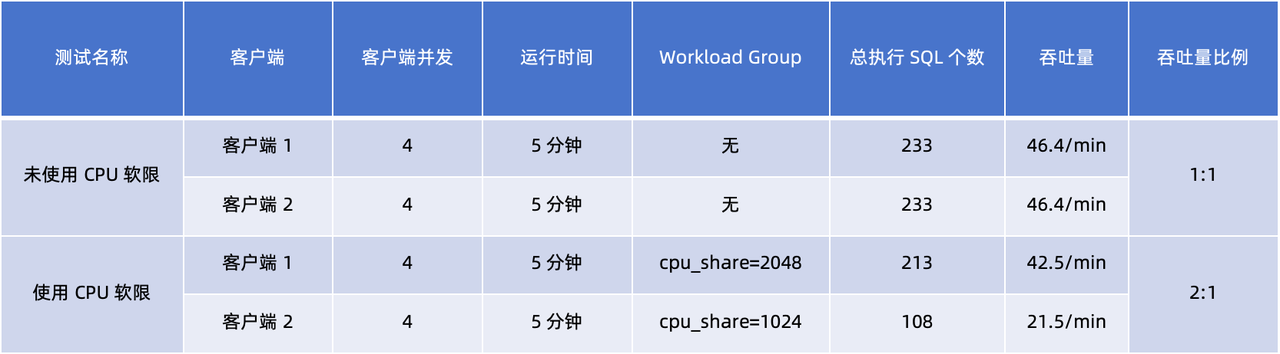
2 つのテストのクライアント スループット データを比較および分析することにより、次の結論を導き出すことができます。
- Workload Group を使用しない場合、2 つのクライアントのスループット比は 1:1 となり、同じ実行時間中に同じ CPU リソースを受け取ることを示します。
- ワークロード グループを使用し、それらをそれぞれ
cpu_share2048 と 1024 に設定すると、結果はスループット比が 2:1 になることを示しています。これは、パラメータが大きいクライアント 1 が、同じ実行時間内でcpu_shareより高い割合の CPU リソースを取得していることを示しています。
02 CPUハードリミットテスト
上記の紹介からわかるように、CPU ハード リミットにより、負荷が高いときに適切な分離が確保されます。したがって、ハード制限を使用して CPU 使用率を 50% に制限し ( cpu_hard_limit=50%)、同時実行数が 1、2、および 4 のときに同じクライアントを使用して q23 クエリ テストを実行します (各テストの実行をシミュレートします)。 5分間。

上記のテスト結果から、同時クエリの数が増加しても、CPU 使用率は常に約 800% で安定していることがわかります (16 コア マシンでは、800% は 8 コアの使用を意味し、実際の CPU 使用率は 50 % )。 CPU リソースはハード的に制限されているため、同時実行性が増加すると tp99 レイテンシが増加することが予想されます。
03 本番環境テストのシミュレーション
実際の運用環境では、ユーザーは純粋なスループットよりもクエリ レイテンシのパフォーマンスに注意を払うことがよくあります。実際のアプリケーション シナリオに近づけ、パフォーマンスを正確に評価するために、待ち時間が約 1 秒の一連のクエリ SQL (CKBench の q15、q17、q23 および TPCH の q3、q7、q19 を含む) を選択して SQL セットを形成しました。これらのクエリは、単一テーブルの集計や結合計算などのさまざまな機能をカバーしており、使用される TPCH データ セット サイズは 100G です。
ワークロード グループなしのシナリオとワークロード グループありのシナリオをそれぞれシミュレートする 2 セットのテストを設計しました。 tp90 と tp99 のレイテンシに焦点を当てて、クライアント 1 とクライアント 2 で 4 つのテストが実行されました。
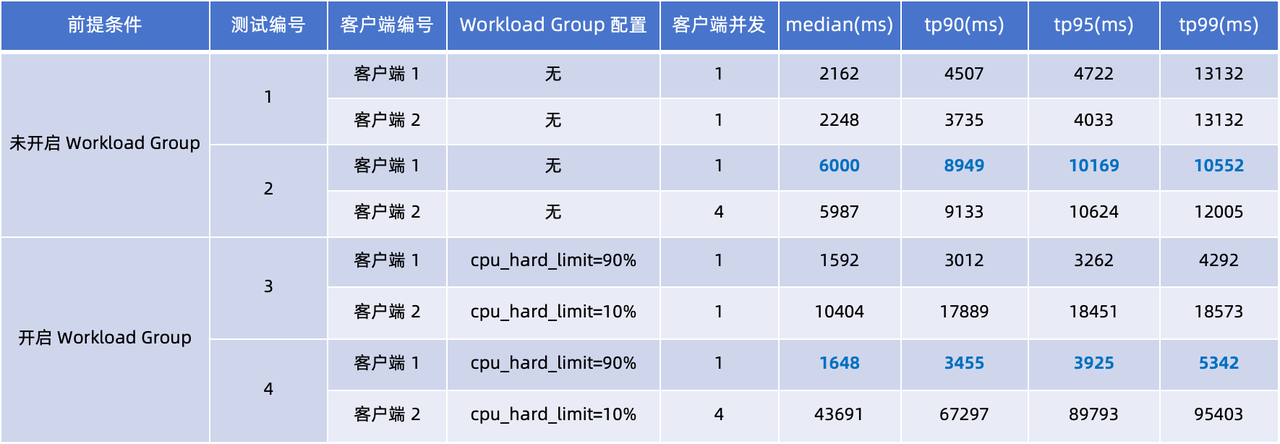
上の表の 4 つのテストでクエリの遅延を観察すると、次の結論を導き出すことができます。
- ワークロード グループは使用されません (テスト 1 および 2) : クライアント 2 の同時実行数が 1 から 4 に増加すると、クライアント 1 と 2 のクエリ遅延が大幅に増加します。クライアント 1 のパフォーマンスを比較すると、tp90 および tp95 クエリ応答時間の中央値は 2 ~ 3 倍増加しています。
- ワークロード グループの使用 (テスト 3、4): CPU ハード制限は、次の 2 つのテストに適用されました: Set Client 1
cpu_hard_limit=90%、 Client 2cpu_hard_limit=90%。テスト結果から、クライアント 2 の同時実行性が増加しても、クライアント 1 のクエリ遅延はわずかに増加するだけであり、テスト 2 のパフォーマンスよりも大幅に優れていることがわかります。この結果は、負荷の分離とパフォーマンスの安定性の保証におけるワークロード グループの有効性を十分に示しています。
結論
現在、リソース タグとワークロード グループの機能は複数のコミュニティ ユーザーの実稼働サービスで開始されており、リソース分離が必要なユーザーに推奨されています。
リソース タグでもワークロード グループでも、その目標は、リソースの分離とリソースの使用の独立性のバランスをとることです。前者ではより徹底した分離ソリューションが採用され、後者ではリソースを最大限に活用しながら分離を実現し、システムの安定性をさらに確保します。クエリ キューとタスク キューイング メカニズムによる高ワークロード シナリオ。
実際にリソース分離を使用する場合は、ビジネス シナリオに応じて 2 つのソリューションを組み合わせて適用することをお勧めします。
- 同じクラスターがシステム間/ビジネス部門間で共有されており、リソースとデータの物理的な分離を実現したい場合は、リソース タグ ソリューションを採用できます。
- 同じクラスター内で同時に複数の種類のクエリ負荷に直面している場合、ワークロード グループを通じて異なる負荷を区別し、柔軟なリソース割り当てを通じてさまざまなクエリ負荷が適切なリソースを確実に取得できるようにすることができます。
今後の機能改善については、まだ多くの計画があります。
- 現在のメモリ制限は、クエリのキャンセルを通じてメモリを解放するために使用されます。将来的には、演算子の配置により、大規模なクエリの安定性がさらに向上し、リソースが不足している場合のクエリ タスクの失敗を回避できるようになります。
- 現在、BE プロセスのメモリ モデルではクエリ以外のメモリの一部がカウントされていないため、BE プロセスのメモリとユーザーから見えるワークロード グループで使用されるメモリに差異が生じる可能性があります。これを解決する予定です。将来のバージョンで問題が発生します。
- クエリ キューイング機能は、同時クエリの最大数に基づくキューイングのみをサポートします。将来的には、同時クエリの最大数は BE のリソース使用量によって制限されるため、クライアントに自動的なバック プレッシャーが形成され、Doris の可用性が向上します。クライアントが高負荷を送信し続けるとき。
- リソース タグ機能は BE マシン リソースを分割し、ワークロード グループは単一マシン プロセス内のリソースを分割します。これらのリソース分割方法はどちらも BE ノードの概念をユーザーに公開します。ユーザーがリソース管理機能を使用する場合、基本的に注意する必要があるのは、使用可能なリソースの量と、セット全体における自分のワークロードに対するリソース割り当ての優先順位だけです。将来的には、ユーザーの理解と使用コストを削減するために、リソースを分割する新しい方法が検討されます。
謝辞
ワークロード グループ機能は、オープン ソース コミュニティによって共同開発されたプロジェクトです。Luo Zenglin (luozenglin)、Liu Lijia (liutang123)、Zhao Liwei (levy5307) の学生の貢献に感謝します。
私はオープンソース紅蒙を諦めることにしました 、オープンソース紅蒙の父である王成露氏:オープンソース紅蒙は 中国の基本ソフトウェア分野における唯一の建築革新産業ソフトウェアイベントです - OGG 1.0がリリースされ、ファーウェイがすべてのソースコードを提供します。 Google Readerが「コードクソ山」に殺される Fedora Linux 40が正式リリース 元Microsoft開発者:Windows 11のパフォーマンスは「ばかばかしいほど悪い」 馬化騰氏と周宏毅氏が「恨みを晴らす」ために握手 有名ゲーム会社が新たな規制を発行:従業員の結婚祝いは10万元を超えてはならない Ubuntu 24.04 LTSが正式リリース Pinduoduoが不正競争の罪で判決 賠償金500万元