著者: Xiao Kang、SelectDBテクノロジー 担当副社長 、Apache Dorisコミッター
ログ データは、企業のビッグ データ システムの重要なコンポーネントの 1 つです。これらのデータは、ネットワーク デバイス、オペレーティング システム、アプリケーションの詳細な履歴動作を記録し、豊富な情報価値が含まれています。可観測性、ネットワーク セキュリティ、ビジネス分析に使用できます。主要なビジネス分野は、企業がシステムと業務運営をより深く理解し、問題を適時に発見して解決し、システムの安全で安定した運用を確保するのに役立つ重要な役割を果たします。具体的には、ログ データは次のような方法でビジネスに価値をもたらします。
- 可観測性: ログは可観測性の 3 つの基礎 (ロギング、メトリクス、トレース) の 1 つであり、そのデータ規模が最も大きな割合を占めており、アラームの監視、トラブルシューティング時の迅速な取得、トレースの関連付けなどによく使用されます。システムの安定した運用を確保し、運用と保守の効率を向上させます。
- ネットワーク セキュリティ: ログは、ネットワークとホスト上で発生するすべてのイベントと動作を記録し、セキュリティ分析、調査と証拠収集、セキュリティ検出などに使用され、システム セキュリティを向上させ、リスクを軽減するための重要な手段です。攻撃されること。
- ビジネス分析: ユーザー行動分析やユーザー ポートレート シナリオなどの一般的なビジネス分析では、通常、企業がユーザーの好みや行動の軌跡を理解し、ユーザー満足度をさらに向上させ、維持とコンバージョンを促進するために、ユーザー行動ログの複雑な分析が必要です。したがって、ログは運用保守やセキュリティに利用されるだけでなく、ビジネスの成長にとっても不可欠な役割を果たします。

ログ データの本質は、一連のシステム イベントを順序立てて記録したものであり、その生成方法と使用シナリオによって次の特性が決まります。
- スキーマ フリー: ログ データの初期形式は非構造化生ログであり、フリー テキスト形式で存在しますが、非構造化データは集計統計などの分析操作には不便です。これらのデータを保存して分析したい場合は、まず ETL を通じて非構造化データを構造化テーブルに処理してから、データベース/データ ウェアハウスで分析する必要があります。このプロセスでは、ログ構造が変更されると、それに対応して ETL と構造化テーブルを調整する必要があり、これには R&D チームと DBA チームの支援が必要ですが、このプロセスは複雑で時間がかかり、実行が困難です。その後、さらにJSONをベースとした半構造化ログが誕生し、ログジェネレーターはフィールドを独立して増減でき、ログストレージシステムはデータに応じてストレージ構造を調整します。
- 大量のデータ: ログ データの規模は通常非常に大きく、生産サイクルは中断されません。特に大企業や一般的なログ アプリケーションでは、毎日生成されるログ データは 10 テラバイトから数百テラバイトに達することがあります。同時に、ビジネス ニーズに応えたり、規制要件に準拠したりするために、ログ データは半年またはそれ以上保存する必要があることが多く、総ストレージ容量が PB レベルに達することが多く、企業に高額のストレージ コストをもたらします。時間の経過とともにログ データの価値は徐々に減少するため、ログ システムにとってストレージ コストはより重要になります。
- リアルタイムの書き込みと取得: ログ データは、トラブルシューティングやセキュリティ追跡など、時間がかかるシナリオでよく使用されます。そのため、データの書き込み遅延が長すぎると、最新のイベントを時間内に取得できなくなります。キーワードの取得応答が遅くなる場合は、遅いと要件を満たせない エンジニアやアナリストの対話型分析ニーズ。したがって、ログシステムには、高スループットな書き込みを前提としたクエリ応答時間1秒未満を確保し、第2段階の応答による全文検索機能や対話型クエリ機能を提供できることが求められます。 。
上記の要件を満たし、ログデータのより高い価値を引き出すために、業界にはログシナリオに対する多くのソリューションがあり、Elasticsearchを核としたELKシステムはその代表的なものです。ここでは、Elasticsearch を例として取り上げ、Elasticsearch に基づくログ システム アーキテクチャがどのように課題に直面しているかを共有します。
Elasticsearch ベースのログ システムの課題
Elasticsearch に基づくログ システムの典型的なアーキテクチャは上図に示されており、システム全体は次のモジュールに分割されます。

- ログ収集: Filebeat を通じてローカル ログ ファイルを収集し、Kafka メッセージ キューに書き込みます。
- ログ トランスポート: Kafka メッセージ キューを使用してログを一元化し、キャッシュします。
- ログ変換: LogStash は Kafka でログを消費し、データ フィルタリングや形式変換などの操作を実行します。
- ログ ストレージ: LogStash はログを JSON 形式で ES ストレージに書き込みます。
- ログ クエリ: Kibana を通じて ES のログを視覚的にクエリするか、ES DSL API を通じてクエリ リクエストを開始します。
Elasticsearch に基づくログ システム アーキテクチャは優れたリアルタイム ログ取得機能を備えていますが、このシステムには、書き込みスループットの低さ、ストレージ コストの高さ、複雑なクエリのサポート不能など、実際のアプリケーションではいくつかの問題点もあります。
スキーマフリーサポートだけでは十分ではない
Elasticsearch のインデックス マッピングは、フィールドの名前、データ型、インデックスを構築するかどうかなど、データのスキーマを定義します。

Elasticsearch の動的マッピングは、書き込まれた JSON データに従ってマッピング内のフィールドを自動的に増やすことができ、ログ データのスキーマ フリーをある程度サポートしますが、明らかな欠陥もあります。
- ダイナミック マッピングのパフォーマンスの低下: ダーティ データが発生すると、多数のフィールドが表示される傾向があり、システムのパフォーマンスと安定性に重大な影響を与えます。
- 固定フィールド タイプ: ビジネス タイプが変更されると、変更できません。さまざまなビジネス ニーズを満たすために、ユーザーは互換性のためにテキスト タイプを使用することがよくありますが、テキスト タイプのクエリ パフォーマンスは、バイナリ タイプのクエリ パフォーマンスよりもはるかに劣ります。整数。
- フィールドのインデックスは固定されており、要求に応じて特定のフィールドのインデックスを追加または削除することができず、柔軟性に乏しい。したがって、クエリ フィルタリングの速度を確保するために、ユーザーは通常、すべてのフィールドにインデックスを作成します。また、すべてのフィールドにインデックスを作成すると、書き込み速度の低下やストレージ容量の増加など、新たな問題が発生します。
分析力が弱い
Elasticsearch によって開発された ES DSL (Domain Specific Language) は、ほとんどのエンジニアやデータ アナリストにとって馴染みのあるテクノロジー スタックとはまったく異なります。ユーザーにとって学習と使用のしきい値が高く、概念や概念を学んだ後でも、多くの新しいことを学ぶ必要があります。文法を理解するには、正しい DSL ステートメントを作成するためにマニュアルを頻繁に参照する必要があります。同時に、Elasticsearch エコシステムは自己完結型で比較的閉鎖的であり、BI ツールなどの他のシステムと接続するのが困難です。さらに重要なのは、Elasticsearch は分析機能が弱く、単純な単一テーブル分析のみをサポートし、複数テーブルの JOIN、サブクエリ、ビューなどの複雑な分析をサポートしておらず、エンタープライズ ログ分析のニーズを満たすことができません。

高コスト、低コストパフォーマンス
Elasticsearch ベースのログ システムの使用コストが高いことも、ユーザーから長い間批判されてきた問題であり、そのコストは主に次の 2 つの側面から発生します。
- 書き込みの計算コスト: Elasticsearch は書き込み時に転置インデックスを構築する必要があり、単語のセグメンテーションや逆テーブルの並べ替えなどの計算集約型の操作を実行します。これにより多くの CPU リソースが消費され、シングルコアの書き込みパフォーマンスは約 2MB/秒です。Elasticsearch クラスターの CPU リソースのほとんどが書き込みによって消費されると、書き込みトラフィックのピークに遭遇したときに書き込み拒否がトリガーされやすくなり、その結果、データ遅延が長くなり、クエリ速度が遅くなります。
- データ ストレージ コスト: 取得と分析を高速化するために、Elasticsearch は前方インデックス、逆インデックス、Docvalue 列ストレージなどの元のデータの複数のコピーを保存するため、ストレージ コストが大幅に増加し、単一データの全体的な圧縮率が高くなります。・コピーストレージには制限があり、一般的なログデータの圧縮率5倍よりもはるかに低い約1.5倍です。
データとクラスター サイズの増大に伴い、Elasticsearch クラスターは安定性の問題にも直面します。
- 書き込みが不安定になる: 書き込みのピークに達すると、クラスターの負荷が高くなり、書き込みの安定性に影響を及ぼします。
- クエリの不安定性: クエリはメモリ内で処理されるため、大規模なクエリは簡単に JVM OOM をトリガーする可能性があり、その結果、クラスター全体の書き込みとクエリの安定性に影響します。
- 障害回復が遅い: Elasticsearch クラスターが障害後に回復する場合、インデックスの読み込みなどのリソースを大量に消費する操作を実行する必要があるため、障害回復時間は多くの場合数十分かかり、サービスの可用性と SLA に大きな課題が生じます。
Apache Doris をベースにした新世代のログ分析システムの構築
上記のソリューションから、Elasticsearch に基づくログ システム アーキテクチャは、アプリケーションの高スループット、低ストレージ コスト、およびリアルタイムの高性能の要件を同時に満たすことができず、複雑なクエリをサポートしていないことがわかります。それでは、コストとパフォーマンスのバランスをより良く保ち、より優れた分析機能を提供できる他のソリューションはあるのでしょうか? 答えは「はい」です。
複数のシナリオのデータ分析問題を 1 つのシステムで解決し、複雑な技術展示によってもたらされる運用保守コストと使用コストを削減することを決意し、ログ データ分析のシナリオ要件をより適切に満たすために、Apache Doris は多くの機能を導入しました。バージョン 2.0 の最適化: たとえば、ネイティブの半構造化データ型をサポートし、テキスト マッチング速度とテキスト アルゴリズムを最適化して、ログ データのインポートとクエリのパフォーマンスを向上させ、文字列の全文検索に対応する逆索引を追加します。型と通常の数値/日付型の等価性と範囲の取得。最後に、ベンチマーク テストと実用化検証の結果、Apache Doris をベースとした新世代のログ分析システムは、Elasticsearch と比較して最大 10 倍の費用対効果が向上することがわかりました。
Apache Doris に基づくログ システムの典型的なアーキテクチャを次の図に示します。これは、Elasticsearch のシステム アーキテクチャ全体よりもオープンです。
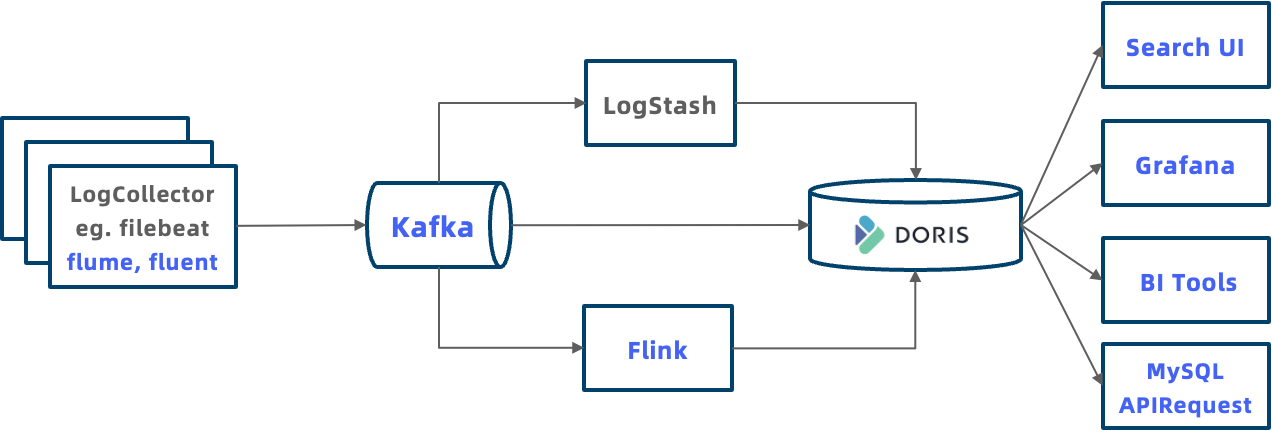
- より多くのログ アクセス方法: Doris は、さまざまなログ データ インポート方法を提供します。たとえば、HTTP 出力を介してログを Doris にプッシュする LogStash をサポートし、Doris に書き込む前にログを処理する Flink をサポートし、Kafka またはオブジェクト ストレージに保存されたログ データをインポートするためのルーチン ロードと S3 ロードをサポートします。
- 統合ストレージによりデータ アイランドが排除されます。ログ データは統合された方法で Doris に保存でき、分析のためにデータ ウェアハウス内の他のデータと関連付けることができ、独立したデータ アイランドではなくなります。
- オープンなエコロジー、より強力な分析機能: Doris は MySQL プロトコルと互換性があり、可観測性システム Grafana、一般的な BI 分析ツール Tableau など、さまざまなデータ分析ツールまたはクライアントが MySQL を介して Doris に接続できます。アプリケーションは、JDBC や ODBC などの標準 API を介して Doris に接続し、ビジネス固有のクエリ分析を行うこともできます。将来的には、ログ分析のエクスペリエンスをさらに向上させるために、Kibana と同様の視覚的なログ探索および分析システムも完成させる予定です。
さらに、Apache Doris ベースのログ システムには次の重要な利点もあります。
ネイティブの半構造化データのサポート
テキストおよび JSON 形式のログ スキーマ フリーの特性にさらに適応するために、Apache Doris は次の 2 つの側面で強化されました。
-
豊富なデータ型の提供: 既存の Text データ型を最適化し、ベクトル化テクノロジを通じて文字列検索と通常のマッチングのパフォーマンスを向上させ、これらの最適化により 2 ~ 10 倍のパフォーマンス向上を達成します。JSON データ型を増やし、必要に応じて JSON に書き込みます。データが書き込まれる 文字列が解析され、コンパクトで効率的なバイナリ形式で保存されるため、クエリのパフォーマンスが 4 倍向上します。Array Map 複合データ型を追加すると、もともと文字列のスプライシングを使用する複合型を構造化でき、ストレージの圧縮がさらに向上します。レートとクエリのパフォーマンス。
-
スキーマ進化のサポート: Elasticsearch とは異なり、Apache Doris は、オンラインでのフィールドの追加または削除、インデックスの追加または削除、フィールドのデータ型の変更など、ビジネス ニーズに応じたスキーマの調整をオンデマンドでサポートします。
-
Apache Doris によって起動された Light Schema Change 関数は、データの変更に応じてフィールドをミリ秒単位で増減できます。
-
-- 增加列,毫秒级返回,立即生效 ALTER TABLE lineitem ADD COLUMN l_new_column INT; -
ライト スキーマ変更により、すべてのフィールドのインデックスを作成せずに、オンデマンドで逆インデックスを追加することもでき、不必要な書き込みとストレージのオーバーヘッドを回避できます。インデックスを追加する場合、Doris はデフォルトで新しく書き込まれたデータのインデックスを生成し、履歴データのインデックスを生成するパーティションを選択でき、ユーザーはそれらを柔軟に制御できます。
-
-- 增加倒排索引,毫秒级返回,新写入数据自动生成索引
ALTER TABLE table_name ADD INDEX index_name(column_name) USING INVERTED;
-- 历史partition可以按需BUILD INDEX,后台增量生成索引
BUILD INDEX index_name ON table_name PARTITIONS(partition_name1, partition_name2);
SQLベースの分析エンジン
Apache Doris は標準 SQL をサポートし、MySQL プロトコルおよび構文と互換性があるため、Doris ベースのログ システムはログ分析に SQL を使用できます。これにより、ログ システムには次の利点があります。
- 使いやすさ: エンジニアとデータ アナリストは SQL に精通しており、経験を再利用でき、新しいテクノロジー スタックを学習することなくすぐに使い始めることができます。
- 豊富なエコシステム: MySQL エコシステムはデータベース分野で最も広く使用されている言語であるため、MySQL エコシステムの統合とアプリケーションにシームレスに接続できます。Doris は、MySQL コマンド ラインを使用して、さまざまな GUI ツール、BI ツール、その他のビッグ データ エコシステムと組み合わせて、より複雑で多様なデータ処理と分析のニーズを実現できます。
- 強力な分析能力: SQL言語はデータベースやビッグデータ分析のデファクトスタンダードとなっており、強力な表現力と機能を備え、検索、集計、複数テーブルJOIN、サブクエリ、UDF、論理ビュー、マテリアライズドビューなどの能力。
Elasticsearchと比較して5~10倍のコストパフォーマンス向上
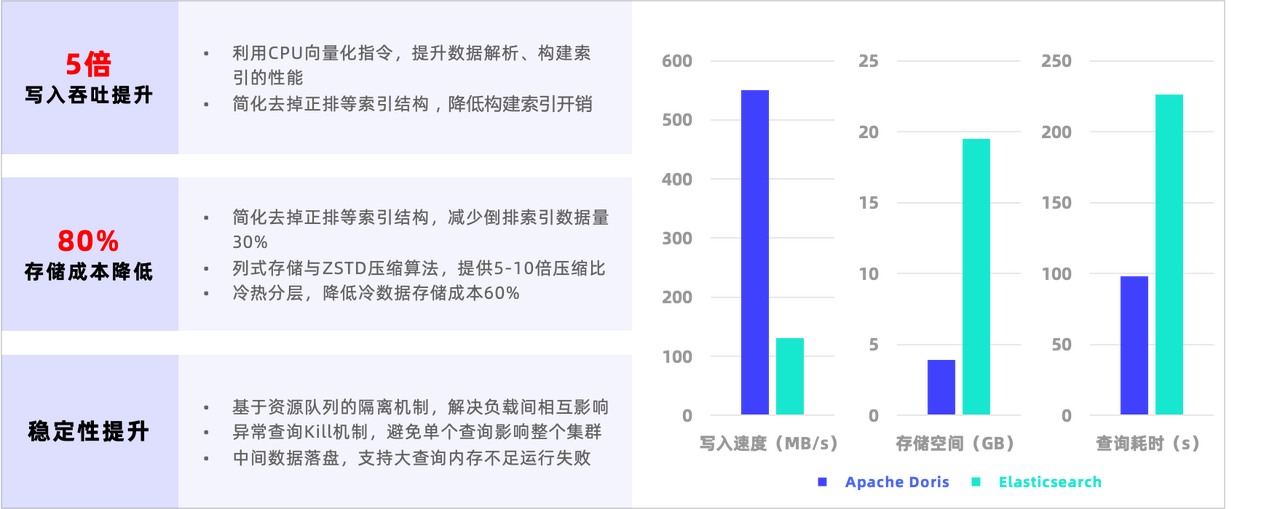
ベンチマークテストと本番検証を経て、Apache Dorisの高性能基本エンジンをベースにログシナリオを最適化した結果、ログシステムのコストパフォーマンスはElasticsearchの5~10倍となっています。
- 書き込みスループットの向上: Elasticsearch 書き込みのパフォーマンスのボトルネックは、データの解析と逆インデックスの構築による CPU 消費量にあります。対照的に、Doris は 2 つの側面で書き込みを最適化しました: 一方で、SIMD などの CPU ベクトル化命令を使用して JSON データの解析速度とインデックス構築パフォーマンスを向上させ、他方では、ログ シナリオのインデックス構造を簡素化し、インデックス構築のパフォーマンスを向上させます。シーン内で必要のない正の行などのデータ構造は、インデックス構築の複雑さを効果的に軽減します。
- ストレージコストの削減: Elasticsearch ストレージのボトルネックは、順方向ソート、逆方向ソート、ストレージの複数のコピーを含む Docvalue 列ストレージ、および圧縮率の低い一般的な圧縮アルゴリズムにあります。対照的に、Doris はストレージに対して次の最適化を実行しました: 正の行を削除し、インデックス データの量を 30% 削減し、列指向ストレージと ZSTD 圧縮アルゴリズムを使用すると、圧縮率は 5 ~ 10 倍に達し、圧縮率をはるかに上回ります。 Elasticsearch 1.5倍、ログデータ中のコールドデータのアクセス頻度が非常に低く、Dorisのホット・コールド階層化機能により、一定期間を超えたログを自動的に下位のオブジェクトストレージに保存でき、コールドデータの保管コストを削減できます。 70%以上増加しました。
Elasticsearch が提供する公式パフォーマンス ベンチマーク ラリーの HTTP ログ テスト セットで比較テストを実施しました。以下の図に示すように、Doris の書き込み速度は Elasticsearch の 5 倍であり、ストレージ容量は 80% 削減され、550 MB/s に達します。書き込み後のデータ圧縮率は 1:10 に近く、ストレージ容量は80% 以上節約され、クエリ時間は 57% 削減され、クエリ パフォーマンスは Elasticsearch の 2.3 倍です。ホット データとコールド データを分離してコールド データのストレージ コストを削減することと相まって、全体的な費用対効果は Elasticsearch と比較して 10 倍以上向上しました。
ユーザーの実践
実際のユーザーシナリオの検証においても、ドリス氏は予想を上回る費用対効果の優位性を示しました。たとえば、あるゲーム会社では元々 Elasticsearch を使用していましたが、ログ分析には標準の ELK が使用されており、非常にコストがかかりました。ストレージ コストが高いため、同社ではログ データの合理的なストレージと効率的な分析が大幅に制限され、ビジネス ニーズを満たすことができませんでした。Doris を使用してログ システムを構築した後、必要なストレージ容量は Elasticsearch の 1/6 のみとなり、ストレージ コストが大幅に削減されます。同時に、Doris の高いパフォーマンスと優れた分析機能により、ログ データをより効率的かつ柔軟に処理し、より優れたビジネス サポートを提供することも可能になります。さらに、あるセキュリティ会社は、Doris が提供した転置インデックスを使用して、元のサーバーの 1/5 のみを使用し、1 秒あたり 300,000 の書き込みトラフィックを伝送し、インポートとクエリの速度を高速化したログ分析システムを構築しました。Doris の導入により、企業の運用コストが削減されるだけでなく、分析の効率とシステムの安定性が大幅に向上し、ビジネスを強力にサポートします。
実用的なガイド
以下は、Apache Doris に基づいて新世代のログ システムを構築する実践的な手順の紹介です。
まず、 Apache Doris 公式 Web サイト ( https://dris.apache.org/zh-CN/download ) からバージョン 2.0 以降をダウンロードする必要があります。ダウンロード後、クラスターの展開に関する展開ドキュメントを参照してください: https://dris .apache.org/zh-CN/docs/dev/install/standard-deployment
-
テーブルを構築する
次の例を参照してテーブルを作成します。重要なポイントは次のとおりです。
- DATETIMEV2 型の時刻フィールドをキーとして使用すると、最新の N 個のログのクエリが大幅に高速化されます。
- 頻繁にクエリされるフィールドのインデックスを作成し、全文検索が必要なフィールドのワード ブレーカー パーサー パラメーターを指定します。
- パーティションは時間フィールドで RANGE パーティションを使用し、動的パーティションを有効にして日ごとにパーティションを自動的に管理します。
- RANDOM を使用してバケットをランダムに分割し、AUTO を使用してシステムがクラスターのサイズとデータ量に応じてバケットの数を自動的に計算できるようにします。
- ホットとコールドの分離を使用して、log_s3 オブジェクト ストレージと log_policy_1day ダンプ s3 ポリシーを 1 日以上構成する
CREATE DATABASE log_db;
USE log_db;
CREATE RESOURCE "log_s3"
PROPERTIES
(
"type" = "s3",
"s3.endpoint" = "your_endpoint_url",
"s3.region" = "your_region",
"s3.bucket" = "your_bucket",
"s3.root.path" = "your_path",
"s3.access_key" = "your_ak",
"s3.secret_key" = "your_sk"
);
CREATE STORAGE POLICY log_policy_1day
PROPERTIES(
"storage_resource" = "log_s3",
"cooldown_ttl" = "86400"
);
CREATE TABLE log_table
(
`ts` DATETIMEV2,
`clientip` VARCHAR(20),
`request` TEXT,
`status` INT,
`size` INT,
INDEX idx_size (`size`) USING INVERTED,
INDEX idx_status (`status`) USING INVERTED,
INDEX idx_clientip (`clientip`) USING INVERTED,
INDEX idx_request (`request`) USING INVERTED PROPERTIES("parser" = "english")
)
ENGINE = OLAP
DUPLICATE KEY(`ts`)
PARTITION BY RANGE(`ts`) ()
DISTRIBUTED BY RANDOM BUCKETS AUTO
PROPERTIES (
"replication_num" = "1",
"storage_policy" = "log_policy_1day",
"deprecated_dynamic_schema" = "true",
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-3",
"dynamic_partition.end" = "7",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "AUTO",
"dynamic_partition.replication_num" = "1"
);
-
ログインポート
Apache Doris は複数のデータ インポート方法をサポートしています。リアルタイム ログ データの場合は、次の 3 つのインポート方法が推奨されます。
- ログ データが Kafka メッセージ キューにある場合は、Kafka からリアルタイムでデータをプルするように Doris Routine Load を構成します。
- 以前に Logstash などのツールを使用して Elasticsearch にログを書き込んだことがある場合は、HTTP インターフェイスを通じて Doris にログを書き込むように Logstash を設定することを選択できます。
- カスタム ライターの場合は、HTTP インターフェイスを通じて Doris にログを書き込むこともできます。
カフカのインポート
Kafka メッセージ キューに JSON 形式でログを書き込み、Kafka ルーチン ロードを作成し、Doris が Kafka からデータをアクティブにプルできるようにします。例は次のとおりです。property.*構成はオプションです。
-- 准备好kafka集群和topic log _topic
-- 创建routine load,从kafka log _topic将数据导入log_table表
CREATE ROUTINE LOAD load_log_kafka ON log_db.log_table
COLUMNS(ts, clientip, request, status, size)
PROPERTIES (
"max_batch_interval" = "10",
"max_batch_rows" = "1000000",
"max_batch_size" = "109715200",
"strict_mode" = "false",
"format" = "json"
)
FROM KAFKA (
"kafka_broker_list" = "host:port",
"kafka_topic" = "log _topic",
"property.group.id" = "your_group_id",
"property.security.protocol"="SASL_PLAINTEXT",
"property.sasl.mechanism"="GSSAPI",
"property.sasl.kerberos.service.name"="kafka",
"property.sasl.kerberos.keytab"="/path/to/xxx.keytab",
"property.sasl.kerberos.principal"="[email protected]"
);
ルーチンロードの作成後、SHOW ROUTINE LOADで実行ステータスを確認できます。使用手順の詳細については、https://dris.apache.org/zh-CN/docs/dev/data-operate/import/import-way/routine-load-manual を参照してください。
Logstash インポート
Logstash の HTTP 出力を構成して、HTTP ストリーム ロードを通じてデータを Doris に送信します。
lo``gstash.ymlデータ書き込みパフォーマンスを向上させるためにバッチ保存バッチの数と時間を構成します。
pipeline.batch.size: 100000
pipeline.batch.delay: 10000
testlog.confログ収集構成ファイルに HTTP 出力と URL を追加して、Doris のストリーム ロード アドレスを構成します。
- 現在、Logstash は HTTP リダイレクトをサポートしていないため、BE アドレスを構成する必要があり、FE アドレスは使用できません。
- ヘッダーの権限は
http basic authコマンドによって計算されますecho -n 'username:password' | base64 来。 - ヘッダーのパラメーターを使用すると
load_to_single_tablet、インポートされる小さなファイルを減らすことができます。
output {
http {
follow_redirects => true
keepalive => false
http_method => "put"
url => "http://172.21.0.5:8640/api/logdb/logtable/_stream_load"
headers => [
"format", "json",
"strip_outer_array", "true",
"load_to_single_tablet", "true",
"Authorization", "Basic cm9vdDo=",
"Expect", "100-continue"
]
format => "json_batch"
}
}
カスタムプログラムのインポート
Http Stream Load インターフェイスを介して Doris にデータをインポートするには、次の方法を参照してください。重要なポイントは次のとおりです。
- HTTP 認証に使用し
basic auth、コマンドを使用してecho -n 'username:password' | base64計算します - を設定し
http header "format:json"、データ形式を JSON として指定します - 設定
http header "read_json_by_line:true"、1 行に 1 つの JSON を指定 - Set
http header "load_to_single_tablet:true"、一度に 1 つのバケットを書き込むように指定します - 現時点では、クライアント側で 100MB ~ 1GB のバッチを書き込むことが推奨されていますが、以降のバージョンでは、サーバー側のグループ コミットを通じてクライアント側のバッチ サイズが削減されます。
curl \
--location-trusted \
-u username:password \
-H "format:json" \
-H "read_json_by_line:true" \
-H "load_to_single_tablet:true" \
-T logfile.json \
http://fe_host:fe_http_port/api/log_db/log_table/_stream_load
-
お問い合わせ
Doris は標準 SQL をサポートしており、MySQL クライアントまたは JDBC を通じてクラスターに接続し、クエリ用の SQL を実行できます。
mysql -h fe_host -P fe_mysql_port -u root -Dlog_db
以下に、ログ分析シナリオにおける一般的なクエリをいくつか示します。
- 最新10件のデータを表示
SELECT * FROM log_table ORDER BY ts DESC LIMIT 10;
- clientip が「8.8.8.8」である最新の 10 個のデータをクエリします
SELECT * FROM log_table WHERE clientip = '8.8.8.8' ORDER BY ts DESC LIMIT 10;
- リクエスト フィールドにエラーまたは 404 が含まれる最新 10 件のデータを取得します。MATCH_ANYはDoris 全文検索の SQL 構文キーワードであり、パラメータ内の任意のキーワードと一致します。
SELECT * FROM log_table WHERE request MATCH_ANY 'error 404' ORDER BY ts DESC LIMIT 10;
- リクエスト フィールドに画像と FAQ を含む最新の 10 個のデータを取得します。MATCH_ALLはDoris 全文検索の SQL 構文キーワードであり、パラメータ内のすべてのキーワードと一致します。
SELECT * FROM log_table WHERE request MATCH_ALL 'image faq' ORDER BY ts DESC LIMIT 10;
要約する
Apache Doris はログ シナリオに対して複数の最適化を行い、最終的に 80% 以上のストレージ領域の節約、Elasticsearch の 5 倍の書き込み速度、Elasticsearch の 2.3 倍のクエリ パフォーマンスを達成しました。ホットデータとコールドデータの階層化機能の恩恵により、総合的な費用対効果はElasticsearchと比較して10倍以上向上しました。これらすべては、Apache Doris がさまざまな企業による新世代のログ システムの構築をサポートするのに十分であることを示しています。
後続の逆インデックスでは、JSON や Map などの複雑なデータ型のサポートも追加されます。BKD インデックスは多次元インデックスをサポートすることができ、Doris が将来 GEO 地理的位置データ タイプとインデックスを追加するための基礎を築きます。同時に、Apache Doris は、豊富な複雑なデータ型 (Array、Map、Struct、JSON) や高性能の文字列マッチング アルゴリズムなど、半構造化データ分析の機能をさらに拡張し、より豊富なログを満たすことができます。アプリケーションシナリオ。
最後に、この記事で説明されている記事が使用シナリオに適合する場合は、テストと使用のために Apache Doris 2.0 をダウンロードして、ユーザーに包括的な技術サポートとサービスを提供してください。質問、アンケート情報の送信を歓迎します。コア コミュニティの貢献者は、その際に1対1の特別サポートを提供します。
MyBatis-Flex の MyBatis-Plus 盗用に関する明確化 Chrome の代替品であると主張する Arc ブラウザ 1.0 が正式にリリース OpenAI が Android バージョンを正式にリリース ChatGPT VS Code で名前の難読化圧縮が最適化され、組み込み JS が 20% 削減されました。 LK-99: 最初の室温常圧超伝導体? マスク氏は「ゼロ元で購入」し、@x Twitter アカウントを強奪したPython 運営委員会は PEP 703 提案を受け入れる予定で、 グローバル インタープリタ ロックをオプションにする . システムのオープンソースで無料のパケット キャプチャ ソフトウェアへのアクセス数Stack Overflow大幅に下落し、マスク氏はLLMに取って代わられたと述べた