
みなさん、こんにちは。シャオFです〜
棒グラフは、データの視覚化で頻繁に使用されるグラフです。
非常に便利ですが、まだ欠点があります。たとえば、棒グラフのエントリが多すぎると、肥大化して直感的ではないように見えます。
ロリポップチャートは棒グラフを改良したもので、小さくて新鮮なデザインで、データを明確に表現しています。
次の小さなFは、Pythonを使用してロリポップチャートを描画する方法を紹介します。
私の国の1949年から2019年までの出生人口のデータが使用されており、データは国家統計局からのものです。
最初にデータを読み取ります。
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据
df = pd.read_csv('data.csv')
print(df)
結果は以下のとおりです。

データセットは単純で、各行には1年と1つの値しかありません。
各年の値を使用して棒グラフをプロットすることから始めます。
# 绘制柱状图
plt.bar(df.Year, df.value)
plt.show()
棒グラフを取得するための2行のコード。これは少し混雑しているようです。
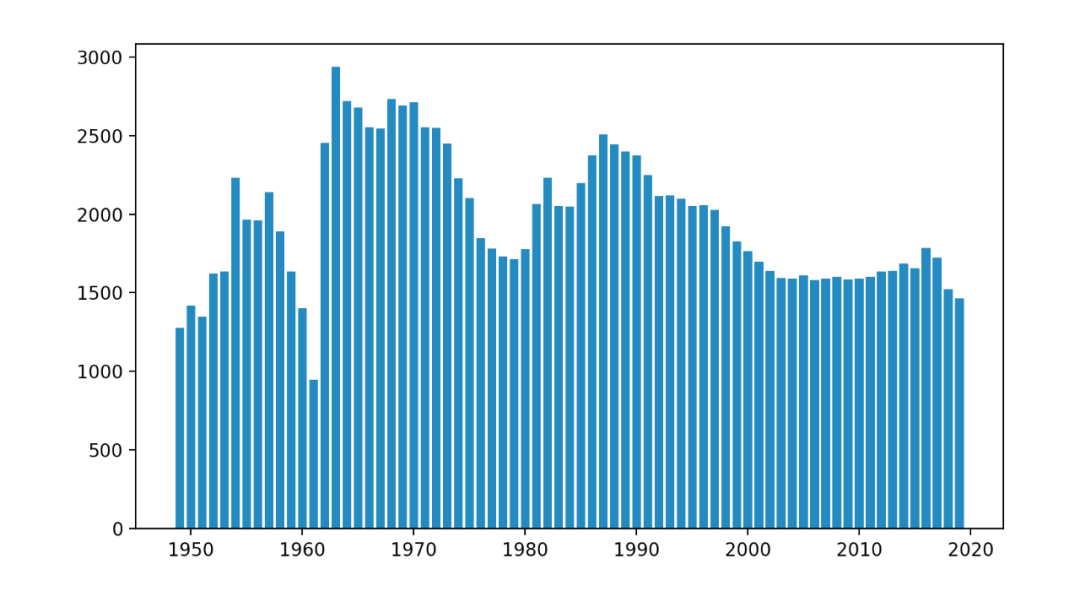
昨年の2019年のデータは、以下のように区別されています。
2019年はバーを黒に、その他の年はライトグレーに色を付けます。
また、散布図をグラフに追加すると、バーの上に円が描画されます。
# 新建画布
fig, ax = plt.subplots(1, figsize=(12, 8))
# 年份数
n = len(df)
# 颜色设置
colors = ['black'] + ((n-1)*['lightgrey'])
plt.bar(df.Year, df.value, color=colors)
plt.scatter(df.Year, df.value, color=colors)
plt.show()
得られた結果は以下のとおりです。
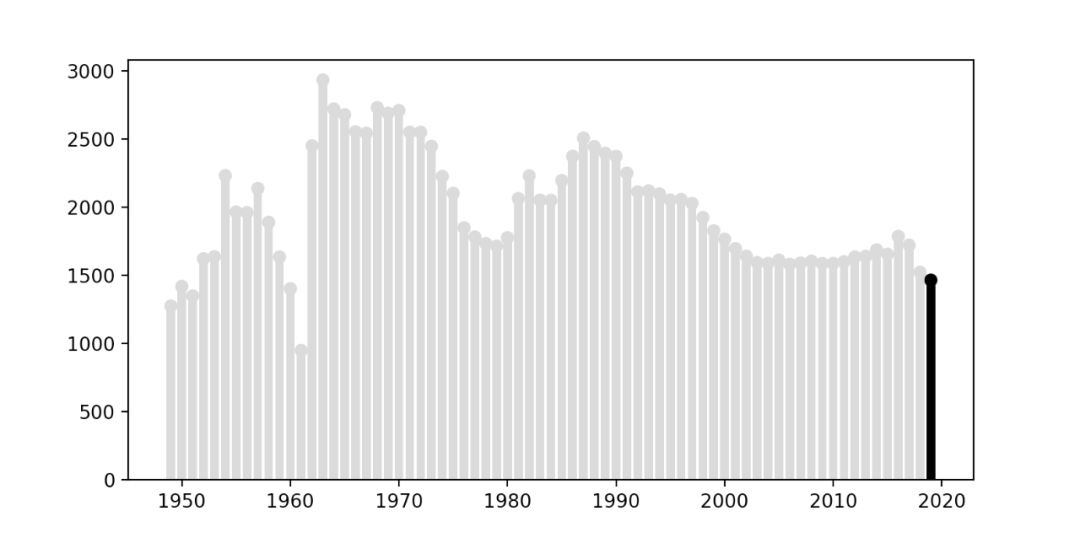
色が正常に変更されたため、棒グラフの幅と上の円のサイズを調整する必要があります。
# width: 条形图宽度 s: 散点图圆圈大小
plt.bar(df.Year, df.value, color=colors, width=0.2)
plt.scatter(df.Year, df.value, color=colors, s=10)
plt.show()
結果は以下のとおりです。
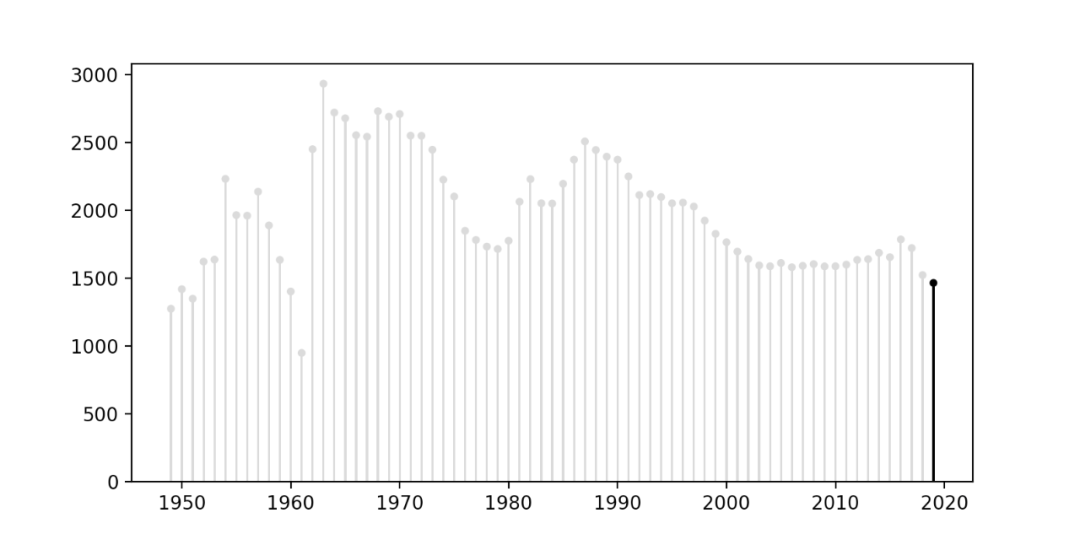
前の青い棒グラフと比較して、ロリポップチャートは確かにはるかに優れています。
ロリポップチャートに棒グラフを使用する代わりに、全体の幅がより一貫するように線を使用することもできます。
Xは年(年)データを開始点と終了点として使用し、Yは-20と各年のデータを開始点と終了点として使用します。
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据
df = pd.read_csv('data.csv')
print(df)
# 新建画布
fig, ax = plt.subplots(1, figsize=(12, 8))
# 年份数
n = len(df)
# 颜色设置
colors = ['black'] + ((n-1)*['lightgrey'])
# 使用线条
for idx, val in df.iterrows():
plt.plot([val.Year, val.Year],
[-20, val.value],
color=colors[idx])
plt.show()
得られた結果は以下のとおりです。

上に散布図を生成するだけでなく、パラメータマーカーを使用して端に円を描くことができます。
次に、y-limitパラメータを変更することにより、一番下の円を非表示にできます。
# 新建画布
fig, ax = plt.subplots(1, figsize=(12, 8))
# 年份数
n = len(df)
# 颜色设置
colors = ['black'] + ((n-1)*['lightgrey'])
# 使用线条, markersize设置标记点大小
for idx, val in df.iterrows():
plt.plot([val.Year, val.Year],
[-20, val.value],
color=colors[idx],
marker='o',
markersize=3)
# 设置y轴最低值
plt.ylim(0,)
plt.show()
結果は以下のとおりです。

さらに、lwを調整したり、パラメータをマーカー化したり、線の太さやマーカーのサイズを定義したり、線を2回描画してアウトライン効果を作成したりすることもできます。
# 新建画布
fig, ax = plt.subplots(1, figsize=(12, 8))
color = 'b'
# 年份数
n = len(df)
# 颜色设置
colors = ['black'] + ((n-1)*['lightgrey'])
# 使用线条
for idx, val in df.iterrows():
plt.plot([val.Year, val.Year],
[-20, val.value],
color='black',
marker='o',
lw=4,
markersize=6)
plt.plot([val.Year, val.Year],
[-20, val.value],
color=colors[idx],
marker='o',
markersize=4)
# 移除上边框、右边框
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
# 设置x、y轴范围
plt.xlim(1948, 2020)
plt.ylim(0,)
# 中文显示
plt.rcParams['font.sans-serif'] = ['Songti SC']
plt.title('中国历年出生人口数据(万)', loc='left', fontsize=16)
plt.text(2019, -220, '来源:国家统计局', ha='right')
# 2019年出生人口数(显示)
value_2019 = df[df['Year'] == 2019].value.values[0]
plt.text(2019, value_2019+80, value_2019, ha='center')
# 保存图片
plt.savefig('chart.png')
得られた結果は以下のとおりです。

黒は特に見栄えが良くないので、色を変えて見てください。
# 新建画布
fig, ax = plt.subplots(1, figsize=(12, 8))
# 年份数
n = len(df)
# 颜色设置
color = 'b'
colors = ['#E74C3C'] + ((len(df)-1)*['#F5B7B1'])
# 使用线条
for idx, val in df.iterrows():
plt.plot([val.Year, val.Year],
[-20, val.value],
color=colors[idx],
marker='o',
lw=4,
markersize=6,
markerfacecolor='#E74C3C')
# 移除上边框、右边框
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
# 设置x、y轴范围
plt.xlim(1948, 2020)
plt.ylim(0,)
# 中文显示
plt.rcParams['font.sans-serif'] = ['Songti SC']
plt.title('中国历年出生人口数据(万)', loc='left', fontsize=16)
plt.text(2019, -220, '来源:国家统计局', ha='right')
# 2019年出生人口数(显示)
value_2019 = df[df['Year'] == 2019].value.values[0]
plt.text(2019, value_2019+80, value_2019, ha='center')
# 保存图片
plt.savefig('chart.png')
得られた結果は以下のとおりです。

棒グラフの場合、別のオプションであるロリポップグラフがあります。
また、中国の新生児人口はますます少なくなっていることもわかります。2020年の出生人口は10%以上減少し、今後数年間で1,000万人を下回る可能性があると言われています。年...
最後に、公式アカウントで「ロリポップ」に返信して、今回使用したコードとデータを入手すれば、自分で学ぶことができます。
エンドブック
今回は、XiaoFと[PekingUniversity Press]が、Pythonビッグデータに関連する5冊の本をお届けします。
「エントリーからマスタリーまでのPythonビッグデータ分析」では、3層の技術アーキテクチャ+3セットのクラシックデータ+ビッグデータプラットフォームツール/エンジンの5つのPythonライブラリ+2つの統合方向を通じてビッグデータ分析を簡単に実行できるようになります。下の画像をクリックして詳細/購入をご覧ください????
本の寄付ルール:この記事が気に入ったら(「私は見ています」は不要です)、以下のQRコードをスキャンして、XiaoFのWeChatを追加します。いいねのスクリーンショットを送ってください。5月10日の21:00までラッキードローコードをお送りします。

Fをご愛顧いただき、誠にありがとうございます!
おすすめの読み物



・・・ 終わり ・・・
