記事ディレクトリ
-
- 1.カフカとは
- 2.データファイルのパーティション(o ff set、MessageSize、data)
- 3.データファイルのセグメンテーション(シーケンシャルな読み取りと書き込み、セグメントコマンド、バイナリ検索)
- 4.負荷分散(パーティションは異なるブローカーに均等に分散されます)
- 5.バッチ送信
- 6.圧縮(GZIPまたはSnappy)
- 7.コンシューマーデザイン
- 8、消費者グループ
- 9.トピックのリストを取得する方法
- 10.プロデューサーとコンシューマーのコマンドラインは何ですか?
- 11.消費者は押したり引いたりしますか?
- 12.消費状況の追跡を維持するためのカフカの方法について話す
- 13、マスタースレーブ同期について話す
- 14.なぜメッセージシステムが必要なのですか?mysqlは要求を満たしていませんか?
- 15.カフカのZookeeperの役割は何ですか?
- 16.ノードがまだ生きているかどうかをKafkaが判断するための2つの条件は何ですか?
- 17. Kafkaと従来のMQメッセージングシステムの間には、3つの重要な違いがあります。
- 18.カフカのackの3つのメカニズムについて教えてください
- 19.消費者がオフセットを自動的に送信できないのに、アプリケーションがオフセットを送信する方法を教えてください。
- 20.消費者の失敗とライブロックの問題を解決するには?
- 21.消費の場所を制御する方法
- 22.(スタンドアロンではなく)分散されたKafkaの場合、メッセージの順次消費を確実にする方法は?
- 23. Kafkaの高可用性メカニズムとは何ですか?
- 24. Kafkaはどのようにデータ損失を削減しますか
- 25. Kafkaはどのようにして重複データを消費しないのですか?たとえば、控除は、控除を繰り返すことはできません。
- 拡張接続:**太字** [詳細については、ここをクリックしてください](https://blog.csdn.net/weixin_44395707/category_9792353.html)
1.カフカとは
Kafkaは、高スループットの分散型パブリッシュ/サブスクライブベースのメッセージングシステムです。もともとはLinkedInによって開発され、Scalaで記述されています。現在、Apacheのオープンソースプロジェクトです。
- ブローカー:メッセージの保存と転送を担当するKafkaサーバー
- トピック:メッセージカテゴリ、Kafkaはトピックに従ってメッセージを分類します
- パーティション:トピックのパーティション。トピックには複数のパーティションを含めることができ、トピックメッセージは各パーティションに格納されます。
- o ff set:ログ内のメッセージの位置。パーティション上のメッセージのオフセットであると理解でき、メッセージを表す一意のシーケンス番号でもあります。
- プロデューサー:メッセージプロデューサー
- 消費者:メッセージ消費者
- 消費者グループ:消費者グループ、各消費者はグループに属している必要があります
- Zookeeper:クラスターブローカー、トピック、パーティションなどのメタデータを保存します。さらに、ブローカーの障害検出、パーティションリーダーの選択、負荷分散、その他の機能も行います。
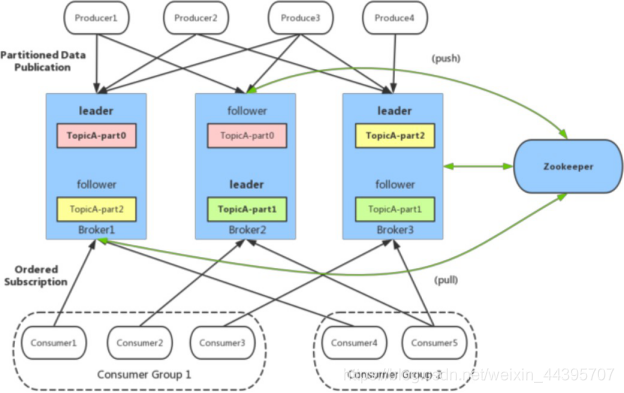
2.データファイルのパーティション(o ff set、MessageSize、data)
パーティション内の各メッセージには、o ff set、MessageSize、dataという3つの属性が含まれています。off setはこのパーティション内のメッセージのオフセットを表し、o ff setはパーティションデータファイル内のメッセージの実際の格納場所ではなく、論理的にパーティション内のメッセージを一意に決定する値。off setはパーティション内のメッセージのID、MessageSizeはメッセージコンテンツデータのサイズ、データはメッセージの特定のコンテンツと見なすことができます。
3.データファイルのセグメンテーション(シーケンシャルな読み取りと書き込み、セグメントコマンド、バイナリ検索)
Kafkaは、セグメント化されたデータファイルごとにインデックスファイルを作成します。ファイル名はデータファイル名と同じですが、ファイル拡張子は.indexです。インデックスファイルは、データファイル内のメッセージごとにインデックスを確立するのではなく、スパースストレージ方式を使用して、データの特定のバイトごとにインデックスを確立します。これにより、インデックスファイルが多くの領域を占有することがなくなり、インデックスファイルをメモリに保持できます。

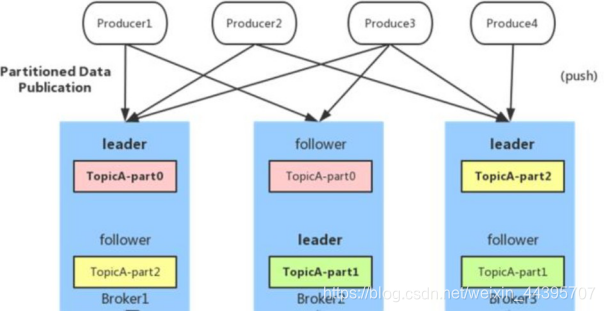
4.負荷分散(パーティションは異なるブローカーに均等に分散されます)
メッセージトピックは複数のパーティションで構成されており、パーティションは異なるブローカーに均等に分散されるため、ブローカークラスターのパフォーマンスを効果的に利用し、メッセージのスループットを向上させるために、プロデューサーはランダムまたはハッシュ方式で複数のブローカーにメッセージを均等に送信できます。負荷分散を実現するパーティション。
5.バッチ送信
これは、メッセージのスループットを向上させる重要な方法です。プロデューサーは、メモリ内の複数のメッセージをマージし、1回のリクエストでメッセージのバッチをブローカーに送信できるため、ブローカーがメッセージを保存するためのIO操作の数を大幅に削減できます。ただし、メッセージのリアルタイムパフォーマンスにもある程度影響します。これは、遅延を犠牲にしてスループットを向上させることと同じです。
6.圧縮(GZIPまたはSnappy)
プロデューサーは、GZIPまたはSnappy形式でメッセージコレクションを圧縮できます。プロデューサー側で圧縮した後、コンシューマー側で解凍する必要があります。圧縮の利点は、送信されるデータの量を削減し、ネットワーク送信への圧力を軽減することです。ビッグデータの処理では、ボトルネックがCPUではなくネットワークに反映されることがよくあります(圧縮と解凍により、CPUリソースが消費されます)。
7.コンシューマーデザイン
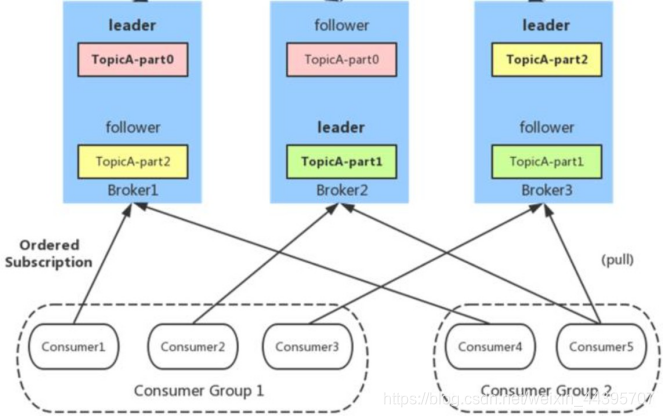
8、消費者グループ
同じコンシューマグループ内の複数のコンシューマインスタンスは、同じパーティションを同時に消費しません。これは、キューモードと同じです。パーティション内のメッセージは順序付けられ、コンシューマーはプルモードでメッセージを消費します。Kafkaは、消費されたメッセージを削除しません。パーティションの場合、ディスクデータを順番に読み書きし、O(1)の時間の複雑さを備えたメッセージ永続性機能を提供します。
9.トピックのリストを取得する方法
bin / kafka-topics.sh --list --zookeeper localhost:2181
10.プロデューサーとコンシューマーのコマンドラインは何ですか?
プロデューサーはトピックに関するメッセージを公開します。
bin/kafka-console-producer.sh --broker-list 192.168.43.49:9092 --topic
Hello-Kafa
ここでのIPは、server.properties内のリスナーの構成であることに注意してください。次の各改行は、新しいメッセージを入力することです。消費者はメッセージを受け入れます:
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic
Hello-Kafka --from-beginning
11.消費者は押したり引いたりしますか?
Kafkaが最初に検討した問題は、顧客がブロークからメッセージをプルするか、ブローカープッシュメッセージをコンシューマーにプッシュするか、つまりプルするかプッシュするかです。この点で、Kafkaはほとんどのメッセージングシステムに共通の従来の設計に従います。プロデューサーはブローカーにメッセージをプッシュし、コンシューマーはブローカーからメッセージをプルします。
ScribeやApache Flumeなどの一部のメッセージングシステムは、プッシュモードを使用してメッセージをダウンストリームコンシューマーにプッシュします。これには長所と短所があります。ブローカーがメッセージプッシュのレートを決定するため、消費率の異なるコンシューマーを処理することは容易ではありません。メッセージングシステムは、コンシューマーが最高の速度で最速でメッセージを消費できるようにすることを約束していますが、残念ながら、プッシュモードでは、ブローカーのプッシュ速度がコンシューマーの消費速度よりもはるかに大きい場合、コンシューマーが崩壊する可能性があります。最後に、Kafkaは従来のプルモードを選択しました。
プルモードのもう1つの利点は、ブローカーからバッチでデータをプルするかどうかをコンシューマーが独自に決定できることです。プッシュモードでは、ダウンストリームコンシューマーの消費容量と消費戦略を知らずに、各メッセージをすぐにプッシュするか、キャッシュ後にバッチプッシュするかを決定する必要があります。消費者のクラッシュを回避するために低いプッシュレートを使用すると、一度にプッシュするメッセージが少なくなり、無駄が生じる可能性があります。プルモードでは、消費者は自分の消費力に応じてこれらの戦略を決定できます。
プルの欠点は、ブローカーが使用できるメッセージがない場合、コンシューマーは新しいメッセージがtに達するまでループ内でポーリングを継続することです。これを回避するために、Kafkaには、コンシューマーが新しいメッセージが到着するまでブロックできるようにするパラメーターがあります(もちろん、メッセージの数が特定の量に達するまでブロックして、バッチで送信できるようにすることもできます)。
12.消費状況の追跡を維持するためのカフカの方法について話す
ほとんどのメッセージングシステムは、ブローカー側でのメッセージ消費の記録を維持します。メッセージがコンシューマーに配信された後、ブローカーはすぐにそれをマークするか、顧客の通知がマークするのを待ちます。このようにして、使用後すぐにメッセージを削除して、スペース使用量を削減できます。
しかし、これは問題でしょうか?メッセージが送信直後に消費済みとしてマークされている場合、コンシューマーがメッセージの処理に失敗すると(プログラムのクラッシュなど)、メッセージは失われます。この問題を解決するために、多くのメッセージングシステムは別の機能を提供します。メッセージが送信されると、メッセージは送信済み状態としてのみマークされ、コンシューマーがメッセージを正常に消費したことが通知されると、消費済み状態としてマークされます。これにより、メッセージ損失の問題は解決されますが、新しい問題が発生します。まず、コンシューマがメッセージの処理に成功したが、ブローカへの応答の送信に失敗した場合、メッセージは2回消費されます。2番目の質問では、ブローカーは各メッセージの状態を維持する必要があり、毎回最初にメッセージをロックしてから状態を変更してからロックを解放する必要があります。大量の状態データの維持は言うまでもなく、この種の問題が再び発生します。たとえば、メッセージが送信されたが正常な消費の通知が受信されなかった場合、メッセージは常にロックされます。Kafkaは別の戦略を使用します。トピックはいくつかのパーティションに分割されており、各パーティションは同時に1つのコンシューマーだけが使用します。つまり、各パーティションで消費されるメッセージのログ内の位置は、単純な整数であるo ff setです。このように、各パーティションの使用状況をマークするのは簡単で、整数のみが必要です。このように、消費状況の追跡は非常に簡単です。これにはもう1つの利点があります。コンシューマは古い値にo-setを調整して、古いメッセージを再度消費できます。これは、従来のメッセージングシステムには信じられないように思えるかもしれませんが、実際には非常に便利です。メッセージは一度しか消費できないと誰が規定しているのですか?
13、マスタースレーブ同期について話す
https://blog.csdn.net/honglei915/article/details/37565289
14.なぜメッセージシステムが必要なのですか?mysqlは要求を満たしていませんか?
1.デカップリング:
同じインターフェース制約に準拠していることを確認する限り、両側の処理を個別に拡張または変更できます。
2.冗長性:
メッセージキューは、データが完全に処理されるまでデータを保持するため、データ損失のリスクを回避できます。多くのメッセージキューで採用されている「挿入-取得-削除」パラダイムでは、キューからメッセージを削除する前に、データが安全に保存されるように、処理システムはメッセージが処理されたことを明確に示す必要があります。使い終わるまで。
3.スケーラビリティ:
メッセージキューは処理プロセスを分離するため、処理プロセスを増やす限り、メッセージのエンキューおよび処理の頻度を増やすことは簡単です。
4.柔軟性とピーク処理能力:
トラフィックが急増した場合でも、アプリケーションは引き続き機能する必要がありますが、そのようなバーストトラフィックは一般的ではありません。そのようなピークの訪問を処理するためにいつでもリソースを投資することは間違いなく巨大な無駄です。メッセージキューを使用すると、主要なコンポーネントが突然のアクセスの負荷に耐えることができ、突然の過負荷の要求が原因で完全に崩壊することはありません。
5.回復可能性:
システムの一部に障害が発生しても、システム全体には影響しません。メッセージキューはプロセス間のカップリングを減らすため、メッセージ処理プロセスがハングした場合でも、キューに追加されたメッセージは、システムが復元された後も処理できます。
6.順序の保証:
ほとんどの使用シナリオでは、データ処理の順序が重要です。ほとんどのメッセージキューは本質的にソートされており、データが特定の順序で処理されることが保証されています。(Kafkaは、パーティション内のメッセージの順序を保証します)
7.バッファリング:
システムを通過するデータフローの速度を制御および最適化し、本番メッセージと消費メッセージの処理速度の不整合を解決します。
8.非同期通信:
多くの場合、ユーザーはメッセージをすぐに処理したくない、または処理する必要がありません。メッセージキューは、ユーザーがメッセージをキューに入れることができる非同期処理メカニズムを提供しますが、すぐには処理しません。必要な数のメッセージをキューに入れ、必要に応じて処理します。
15.カフカのZookeeperの役割は何ですか?
Zookeeperは、オープンソースの高性能調整サービスであり、Kafka分散アプリケーションで使用されます。Zookeeper Kafkaは主に通信で使用され、オフセットを送信するために使用されるため、クラスター内の異なるノード間でノードに障害が発生した場合、以前に
追加で送信されたオフセットから利用できます。さらに、リーダーの検出、分散同期、構成管理、新しいノードの離脱または接続の識別、クラスター、ノードのリアルタイムステータスなど、他のアクティビティも実行します。
- データ送信の3つのタイプのトランザクション定義は何ですか?MQTTのような3種類のトランザクション定義があります。
- 最大で1回:メッセージは繰り返し送信されず、最大で1回送信されますが、一度に送信されない可能性があります
- 少なくとも1回:メッセージは見逃されず、少なくとも1回送信されますが、繰り返し送信される場合があります。
- 正確に1回:送信の失敗や繰り返しの送信はありません。各メッセージは1回だけ送信されます。これは誰もが期待することです
16.ノードがまだ生きているかどうかをKafkaが判断するための2つの条件は何ですか?
- ノードはZooKeeperとの接続を維持できる必要があります。Zookeeperはハートビートメカニズムを介して各ノードの接続をチェックします
- ノードがフォロワーの場合、リーダーはリーダーの書き込み操作を時間内に同期できなければならず、遅延が長すぎてはなりません。
17. Kafkaと従来のMQメッセージングシステムの間には、3つの重要な違いがあります。
- Kafka永続ログ。これらのログは繰り返し読み取り、無期限に保持できます
- Kafkaは分散システムです。クラスターで実行され、柔軟にスケーリングでき、内部的にデータを複製してフォールトトレランスと高可用性を向上させます。
- Kafkaはリアルタイムストリーミングをサポート
18.カフカのackの3つのメカニズムについて教えてください
request.required.acksには3つの値があります0 1 -1(すべて)
0:プロデューサーはブローカーのackを待機しません。この遅延は最小ですが、ストレージ保証は最も弱いです。サーバーがダウンするとデータが失われます。
1:サーバーは、ack値を持つリーダーコピーがメッセージを受信したことを確認してackを送信するのを待ちますが、リーダーが電話を切った場合、レプリケーションが完了したことを保証せず、新しいリーダーもデータを損失します。
-1(すべて):サーバーは、リーダーからACKを受信する前に、フォロワーのすべてのコピーがデータを受信するのを待機するため、データが失われることはありません。
19.消費者がオフセットを自動的に送信できないのに、アプリケーションがオフセットを送信する方法を教えてください。
auto.commit.o ff setをfalseに設定し、メッセージのバッチ処理後にcommitSync()または非同期にcommitAsync()を送信します
。
ConsumerRecords<> records = consumer.poll();
for (ConsumerRecord<> record : records){
。。。
tyr{
consumer.commitSync()
} 。
。。
}
20.消費者の失敗とライブロックの問題を解決するには?
「ライブロック」の場合は、ハートビートを送信し続けますが、処理しません。この状況でコンシューマーがパーティションを保持できないようにするために、max.poll.interval.msアクティブ検出メカニズムを使用します。これに基づいて、呼び出すポーリング頻度が最大間隔より大きい場合、クライアントはグループをアクティブに脱退して、他のコンシューマーがパーティションを引き継ぐことができるようにします。これが発生すると、o ff set commit failure(
commitSync()の呼び出しによって引き起こされるCommitFailedException)が表示されます。これは、アクティブなメンバーだけがOsetを送信できるようにするための安全メカニズムです。したがって、グループにとどまるには、ポーリングを呼び出し続ける必要があります。
コンシューマーは、ポーリングサイクルを制御する2つの構成設定を提供します
。max.poll.interval.ms:ポーリング間隔を増やすと、コンシューマーに返されるメッセージを処理するためのより多くの時間を提供できます(call poll(long)の戻り通常、返されるメッセージはバッチです)。欠点は、値を大きくするとグループの再調整が遅れることです。
max.poll.records:この設定は、ポーリングの呼び出しごとに返されるメッセージの数を制限するため、各ポーリング間隔で処理される最大値を予測するのが簡単になります。この値を調整することにより、ポーリング間隔を短縮し、グループの再調整を行うことができます
メッセージの処理時間が予測できない状況では、これらのオプションでは不十分です。この状況を処理するための推奨される方法は、メッセージ処理を別のスレッドに移動し、コンシューマーにポーリングの呼び出しを継続させることです。ただし、提出されたセットが実際の位置を超えないように注意する必要があります。さらに、スレッドが処理を完了した後でのみ、自動送信を無効にし、手動でレコードのオフセットを送信する必要があります(それはあなた次第です)。また、パーティションを一時停止するには一時停止する必要があります。ポーリングから新しいメッセージを受信せず、スレッドが以前に返されたメッセージの処理を完了するようにします(処理能力がメッセージのプルよりも遅い場合、新しいスレッドを作成すると、マシンがオーバーフローします。 )。
21.消費の場所を制御する方法
Kafkaはseek(TopicPartition、long)を使用して新しい消費位置を指定します。サーバーによって予約されている最も古いおよび最も新しいo-setを見つけるための特別なメソッドも利用できます(seekToBeginning(Collection)および
seekToEnd(Collection))
22.(スタンドアロンではなく)分散されたKafkaの場合、メッセージの順次消費を確実にする方法は?
Kafkaの分散ユニットはパーティションであり、同じパーティションが先読みログによって編成されるため、FIFOの順序が保証されます。異なるパーティション間での順序は保証されません。ただし
、同じキーのメッセージは同じパーティションにのみ送信されることが保証されているため、ほとんどのユーザーはメッセージキーで定義できます。
Kafkaでメッセージを送信する場合、3つのパラメーター(トピック、パーティション、キー)を指定できます。パーティションとキーはオプションです。パーティションを指定すると、すべてのメッセージが同じパーティションに送信されます。そして消費者側では、Kafkaは1つのパーティションが1つの消費者によってのみ消費されることを保証します。または、キー(注文IDなど)を指定すると、同じキーを持つすべてのメッセージが同じパーティションに送信されます。
23. Kafkaの高可用性メカニズムとは何ですか?
この質問はより体系的であり、カフカのシステム特性、リーダーとフォロワーの関係、メッセージの読み書きの順序に答えます。
https://www.cnblogs.com/qingyunzong/p/9004703.html
https://www.tuicool.com/articles/BNRza2E
https://yq.aliyun.com/articles/64703
24. Kafkaはどのようにデータ損失を削減しますか
https://www.cnblogs.com/huxi2b/p/6056364.html
25. Kafkaはどのようにして重複データを消費しないのですか?たとえば、控除は、控除を繰り返すことはできません。
実際、あなたはまだビジネスについて考える必要があります。ここでいくつかのアイデアを説明します。たとえば
、データベースに書き込むデータの一部を取得する場合、最初に主キーに基づいてそれをチェックします。データが使用可能な場合は、挿入して更新しないでください。
たとえば、Redisを作成している場合は問題ありませんが、とにかく毎回設定されるため、当然のことながらべき等です。
たとえば、上記の2つのシナリオを使用していない場合は、少し複雑になります。プロデューサーに各データを送信するように依頼する必要がある場合は、注文IDと同様にグローバルに一意のIDを追加し、それをここで使用した後、最初に、たとえばこのIDに基づいてRedisで確認します。以前にそれを消費したことがありますか?消費していない場合は、それを処理し、このIDをRedisに書き込みます。消費した場合は処理せず、同じメッセージを繰り返し処理しないようにしてください。
たとえば、データベースの一意のキーに基づいて、重複したデータが複数のエントリに繰り返し挿入されないようにします。一意のキー制約があるため、データ挿入を繰り返してもエラーが報告されるだけで、データベースにダーティデータが発生することはありません
拡張接続:より太字のスタイルについては、ここをクリックしてください
ブロガーのパブリックアカウントプログラマXiaoyang は、インタビュー関連のツイートのみを投稿します
