Los modelos de lenguaje grandes avanzan en lo último en procesamiento del lenguaje natural. Sin embargo, están diseñados principalmente para inglés o para un conjunto limitado de idiomas, lo que crea una gran brecha en su eficacia para los idiomas de bajos recursos. Para cerrar esta brecha, investigadores de la Universidad de Munich, la Universidad de Helsinki y otros investigadores abrieron conjuntamente MaLA-500, cuyo objetivo es cubrir una amplia gama de 534 idiomas.
MaLA-500 se basa en LLaMA 2 7B y luego utiliza el conjunto de datos multilingüe Glot500-c para el entrenamiento de expansión del idioma. Los resultados experimentales de los investigadores en SIB-200 muestran que MaLA-500 ha logrado resultados de aprendizaje contextual de última generación.
Glot500-c contiene 534 idiomas, que cubren 47 idiomas étnicos diferentes, con un volumen de datos de hasta 2 billones de tokens. Los investigadores dijeron que la razón para elegir el conjunto de datos Glot500-c es que puede ampliar en gran medida la cobertura lingüística de los modelos lingüísticos existentes y contiene una familia de lenguajes extremadamente rica, lo que es de gran ayuda para el modelo a la hora de aprender la gramática y la semántica inherentes. reglas de la lengua.
Además, aunque la proporción de algunos lenguajes con altos recursos es relativamente baja, el volumen general de datos de Glot500-c es suficiente para entrenar modelos de lenguaje a gran escala. En el preprocesamiento posterior, se realizó un muestreo aleatorio ponderado en el conjunto de datos del corpus para aumentar la proporción de idiomas de bajos recursos en los datos de entrenamiento y permitir que el modelo se centre más en idiomas específicos.
Basado en LLaMA 2-7B, MaLA-500 ha realizado dos importantes innovaciones tecnológicas:
- Para mejorar el vocabulario, los investigadores entrenaron un segmentador de palabras multilingüe a través del conjunto de datos Glot500-c, ampliando el vocabulario en inglés original de LLaMA 2 a 2,6 millones, mejorando en gran medida la capacidad del modelo para adaptarse a idiomas distintos del inglés y de bajos recursos.

- La mejora del modelo utiliza la tecnología LoRA para realizar una adaptación de bajo rango basada en LLaMA 2. Solo entrenar la matriz de adaptación y congelar los pesos del modelo básico puede lograr de manera efectiva la capacidad de aprendizaje continuo del modelo en nuevos idiomas y al mismo tiempo conservar el conocimiento original del modelo.
Proceso de entrenamiento
En términos de capacitación, los investigadores utilizaron 24 GPU N-card A100 para la capacitación y tres marcos de aprendizaje profundo convencionales, incluidos Transformers, PEFT y DeepSpeed.
Entre ellos, DeepSpeed brinda soporte para entrenamiento distribuido y puede lograr el paralelismo del modelo; PEFT implementa un ajuste eficiente del modelo; Transformers proporciona la implementación de funciones del modelo, como generación de texto, comprensión rápida de palabras, etc.
Para mejorar la eficiencia del entrenamiento, MaLA-500 también utiliza varios algoritmos de optimización informática y de memoria, como el optimizador redundante ZeRO, que puede maximizar el uso de los recursos informáticos de la GPU; y el formato numérico bfloat16 para un entrenamiento de precisión mixto para acelerar el proceso de entrenamiento.
Además, los investigadores también realizaron una gran cantidad de optimizaciones en los parámetros del modelo, utilizando entrenamiento SGD convencional con una tasa de aprendizaje de 2e-4 y usando una atenuación de peso L2 de 0,01 para evitar que el modelo sea demasiado grande, sobreajustado e inestable. salida de contenido, etc. Condición.
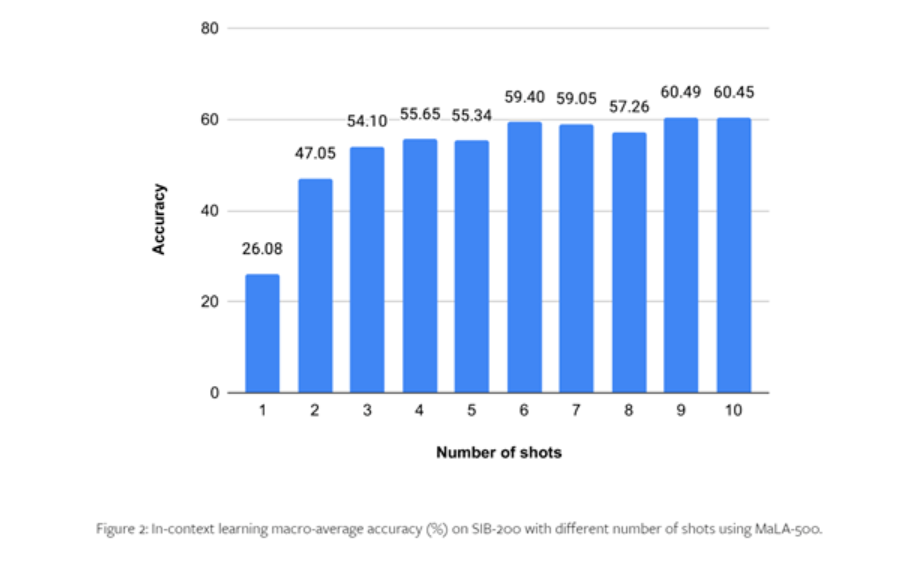
Para probar el rendimiento de MaLA-500, los investigadores realizaron experimentos exhaustivos con conjuntos de datos como el SIB-200.
Los resultados muestran que, en comparación con el modelo LLaMA 2 original, la precisión de MaLA-500 en tareas de evaluación como la clasificación de temas aumenta en un 12,16%, lo que demuestra que el multilenguaje de MaLA-500 es superior a muchos modelos de lenguajes grandes de código abierto existentes. .
Se pueden encontrar más detalles en el artículo completo .