El último año se han producido avances explosivos en los campos del aprendizaje automático y la inteligencia artificial . Las soluciones de IA generativa de alta calidad como ChatGPT han despertado el interés del público y se han extendido al sector comercial. Tanto las organizaciones como los individuos están considerando cómo aprovechar esta tecnología para acelerar el impacto y deleitar a los clientes.
Si bien estos modelos generales son excelentes, a menudo no son perfectos para casos de uso específicos de la industria. Los datos de capacitación disponibles públicamente no pueden proporcionar modelos con la experiencia necesaria para resolver cada caso de uso específico de la empresa. Para satisfacer estas demandas, muchas organizaciones están invirtiendo en ajustar y entrenar sus propios modelos. Para ello, necesitan ampliar su espacio informático más allá de la computadora portátil de un ingeniero o las herramientas de construcción existentes. Los científicos de datos y los ingenieros de aprendizaje automático necesitan herramientas que les ayuden a escalar sus cargas de trabajo con acceso controlable a los recursos informáticos que les corresponden.
Para abordar estos desafíos, nos complace anunciar una asociación entre VMware y Anyscale, el creador de Ray. Ray es un programador de cargas de trabajo distribuido de Python optimizado para cargas de trabajo de aprendizaje automático , que brinda escalabilidad sin servidor a cargas de trabajo de capacitación e inferencia. En términos de procesamiento paralelo y computación distribuida, Ray tiene una amplia gama de aplicaciones y un rendimiento excelente.
Anyscale y VMware se han asociado para crear un complemento de código abierto para ejecutar Ray en vSphere usando una máquina virtual. El complemento permite a los administradores de sistemas proporcionar a los equipos de ciencia de datos una infraestructura informática que satisfaga sus necesidades. Cuando los equipos de ciencia de datos pueden utilizar la computación para ejecutar las cargas de trabajo que respaldan su exploración, limpieza y experimentación de modelos de datos, las empresas pueden reducir el tiempo que lleva pasar de datos sin procesar a un modelo optimizado y diferenciado, impulsando resultados comerciales específicos. El proceso es como DevOps, pero esta vez el objetivo es entregar un modelo funcional a producción.
¿Como funciona?
Un clúster de Ray consta de un nodo principal y nodos trabajadores.

El nodo principal es responsable de administrar el clúster y ajustar la cantidad de nodos de trabajo en el clúster. Estos nodos trabajadores distribuidos son responsables de capacitar, ajustar y servir modelos.
Para comenzar a trabajar, el escalador automático del nodo principal necesita saber qué tamaño y dónde puede servir al clúster, lo que requiere un archivo de configuración del clúster.
Para lograr esto, nuestro complemento extiende Ray Autoscaler para que funcione directamente con máquinas virtuales en vSphere.

Para coordinar las cargas de trabajo de Ray, el complemento Ray Autoscaler invoca un clúster de vSphere. Un clúster de vSphere es un grupo de hosts cuyos recursos pasan a formar parte de los recursos del clúster. Un clúster gestiona los recursos de todos los hosts que lo componen. El clúster admite vSphere High Availability (HA) y vSphere Distributed Resource Scheduler (DRS). Estas características garantizan que los clústeres de Ray sean tolerantes a fallas, estén aislados de otras cargas de trabajo de misión crítica y asignen de manera óptima los recursos informáticos.
Configurar proveedores de vSphere
La siguiente figura muestra un archivo de configuración de clúster Ray de muestra para usar con vSphere. En la sección Proveedor, debemos especificar el tipo como vSphere y especificar las credenciales para el clúster de vSphere y el almacén de datos donde se implementará el clúster de Ray.
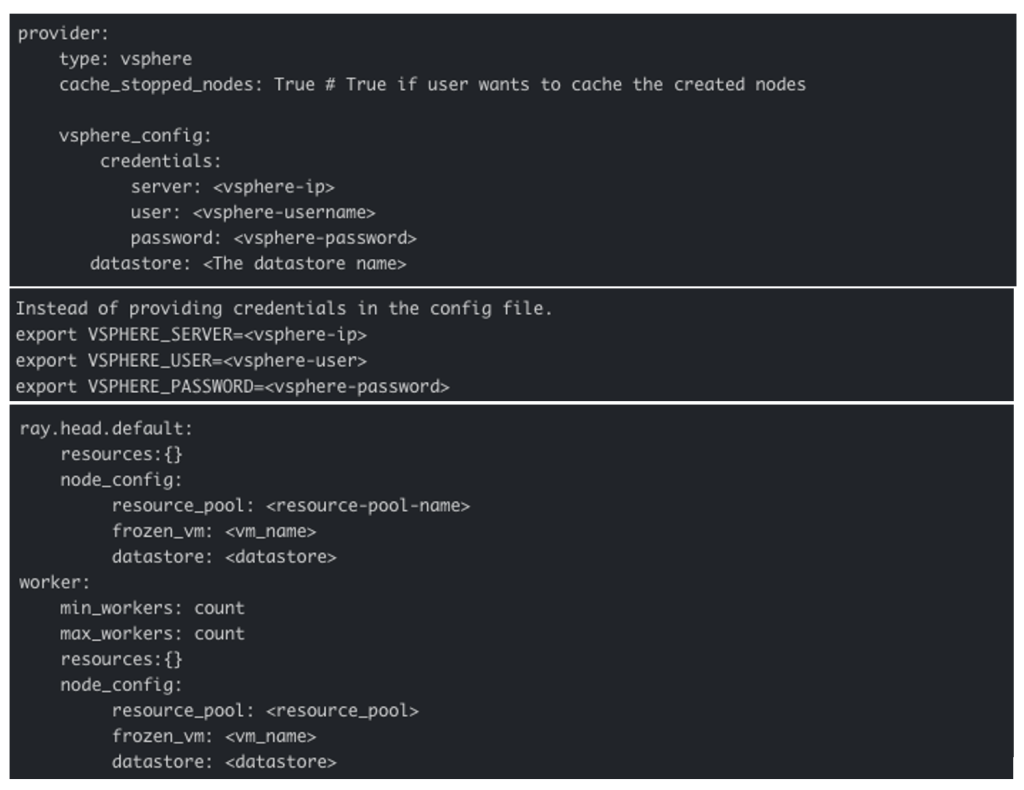
Además, en la configuración del nodo trabajador y del cabezal, podemos configurar grupos de recursos para aislar a Ray Workers de otras cargas de trabajo. Para mejorar el rendimiento, también podemos especificar congelar la máquina virtual (Frozen VM). Esta máquina virtual congelada se utilizará como un clon instantáneo (clon instantáneo) para expandir rápidamente los nodos trabajadores.
¿Que sigue?
Lo que compartimos hoy es sólo el primer paso. Actualmente estamos explorando cómo aprovechar la computación no utilizada para entrenar modelos de aprendizaje automático cuando los centros de datos están inactivos, lo que permite a las organizaciones obtener más valor de sus centros de datos sin afectar las cargas de trabajo de producción. ¡También es bueno para el planeta!
Estamos listos para marcar el comienzo de una nueva era de automatización y simplificar el acceso al aprendizaje automático con nuestro complemento Ray on vSphere. Se aceptan pruebas y comentarios; envíe sus preguntas a [email protected] .
Este artículo fue escrito por Ala Dewberry, gerente senior de productos de OCTO xLabs y Sean Huntley, ingeniero de productos de OCTO.
Fuente del contenido | Cuenta pública: Centro de investigación y desarrollo de VMware China
Si tiene alguna pregunta, escanee la cuenta oficial a continuación para contactarnos ~
