Für weiteren technischen Austausch und Stellenangebote folgen Sie bitte dem offiziellen WeChat-Konto der ByteDance Data Platform und antworten Sie [1], um der offiziellen Kommunikationsgruppe beizutreten
Der Artikel stellt die Bucket-Optimierungstechnologie und ihre Anwendung im tatsächlichen Geschäft vor, einschließlich der Grundprinzipien von Spark Bucket, und konzentriert sich auf den integrierten Analysedienst LAS (im Folgenden als LAS bezeichnet) von Volcano Engine Der Einsatzbereich wurde erheblich verbessert, der Optimierungsbereich wurde erweitert und es gab erfolgreiche Anwendungsfälle innerhalb von Byte. Die im Artikel erwähnten Fähigkeitsverbesserungen können direkt auf LAS verwendet werden. Jeder ist herzlich eingeladen, die offizielle Website von Volcano Engine zu besuchen und zu kaufen ( klicken Sie hier, um zu gehen ). Am Ende des Artikels gibt es exklusive Easter Eggs und ermäßigte Einkäufe Vorteile für Neulinge, die darauf warten, von Ihnen freigeschaltet zu werden!
Die Gliederung dieses Artikels lautet wie folgt:
- Einführung in die Bucket-Optimierungstechnologie
- Erweiterung des LAS-Buckets
- Anwendung der Bucket-Optimierung innerhalb von Bytes
- Zusammenfassen
Einführung in die Bucket-Optimierungstechnologie
Bucket-Optimierung ist eine Technologie, die die Abfragegeschwindigkeit durch Bucketing und Sortieren von Daten optimiert.
Bucketing ist eine Möglichkeit, Daten zu organisieren. Sie müssen das Bucket-Feld und die Anzahl der Buckets angeben; es hasht den Wert des Bucket-Felds, nimmt den Rest und speichert Daten mit demselben Rest im selben Bucket. Durch Angabe des Bucket-Felds, der Bucket-Nummer und der Sortierspalte verwendet die Bucket-Tabelle Shuffle, um die geschriebenen Daten in Buckets aufzuteilen, die Buckets zu sortieren und sie dann in die Datei zu schreiben.
Die Syntax zum Erstellen einer Bucket-Tabelle lautet wie folgt: clustered by (id)Geben Sie die Bucket-Spalte an, sorted by (id)geben Sie die Sortierspalte an und into 4 buckets**** geben Sie die Anzahl der Buckets an.
create table user(id Int, info String) clustered by (id) sorted by (id) into 4 buckets;
Die SQL-Syntax zum Lesen und Schreiben von Bucket-Tabellen ist dieselbe wie die von Nicht-Bucket-Tabellen und erfordert keine Benutzeränderung.
insert overwrite table user select id, info from ... where ...
Der Ausführungsplan für die von der oben genannten SQL geschriebene Bucket-Tabelle lautet wie folgt: Wenn die Verteilung der ursprünglichen Job-Ausgabedaten die Bucket-Bucketing-Anforderungen nicht erfüllt, wird ein zusätzlicher Shuffle- und Sort-Overhead eingeführt.

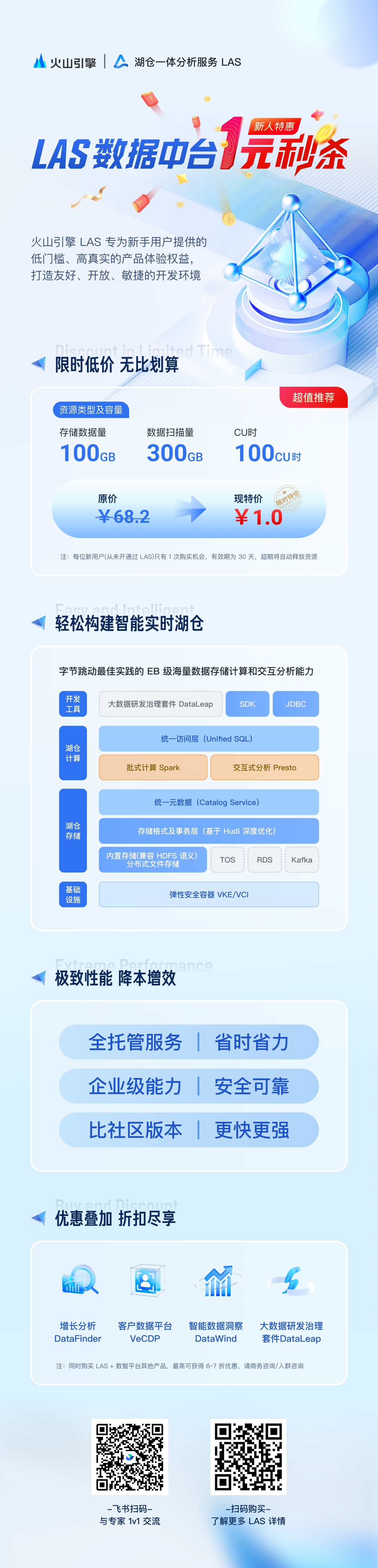
Der Vergleich des schematischen Diagramms der Ausgabe einer Nicht-Bucket-Tabelle und einer Bucket-Tabelle ist wie folgt.
Wenn nachgelagerte Aufgaben nach Bucket-Spalten zusammengeführt, gruppiert oder angezeigt werden, kann der Mehraufwand für „Shuffle“ und „Sort“ eingespart werden. Die folgende Abbildung zeigt den Ausführungsplan von SortMerge Join mit bzw. ohne Bucket-Optimierung; bei Bucket-Optimierung können Shuffle und Sort der Tabellen A und B weggelassen werden.

Erweiterung des LAS-Buckets
In Kombination mit tatsächlichen Geschäftsszenarien hat das LAS Spark-Team die Bucket-Optimierung von Spark weiter verbessert:
- Kompatibel mit der Hive-Bucket-Optimierung und unterstützt motorübergreifendes Lesen
- Unterstützt beim Lesen und Schreiben von Bucket-Tabellen die Shuffle-Eliminierung in weiteren Szenarien
- Kompatibel mit historischen Nicht-Bucket-Partitionen
- Unterstützt das Festlegen der Anzahl von Buckets auf Partitionsebene
Kompatibel mit der Hive-Bucket-Optimierung
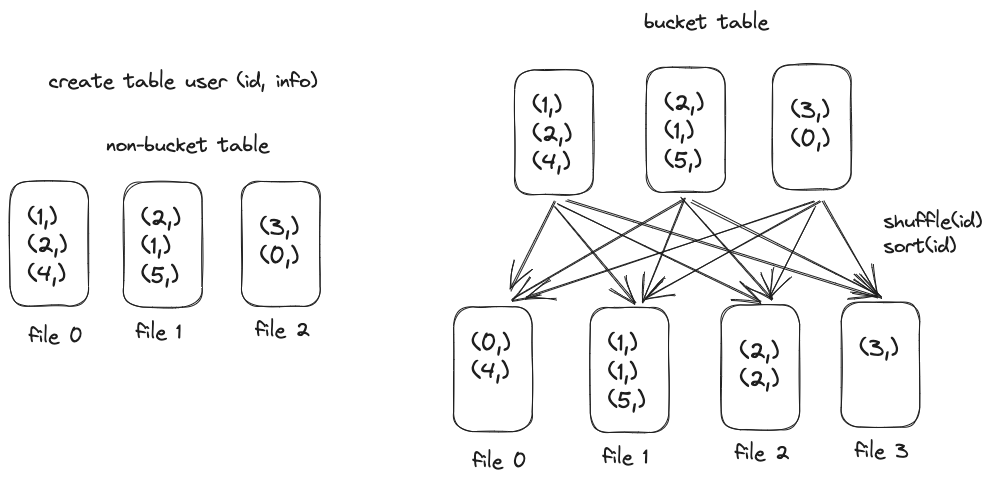
Tabellen im Data Warehouse können von mehreren Computer-Engines gelesen werden. Derzeit unterstützt Byte sowohl SparkSQL- als auch Presto OLAP-Engines. Damit verschiedene Computer-Engines die Bucket-Informationen der Tabelle zur Optimierung von Abfragen verwenden können, müssen die Bucket-Implementierungen jeder Engine angepasst werden. Die folgende Abbildung zeigt den Vergleich zwischen der Hive/Presto-Schreib-Bucket-Tabelle und der nativen Spark-Schreib-Bucket-Tabelle.
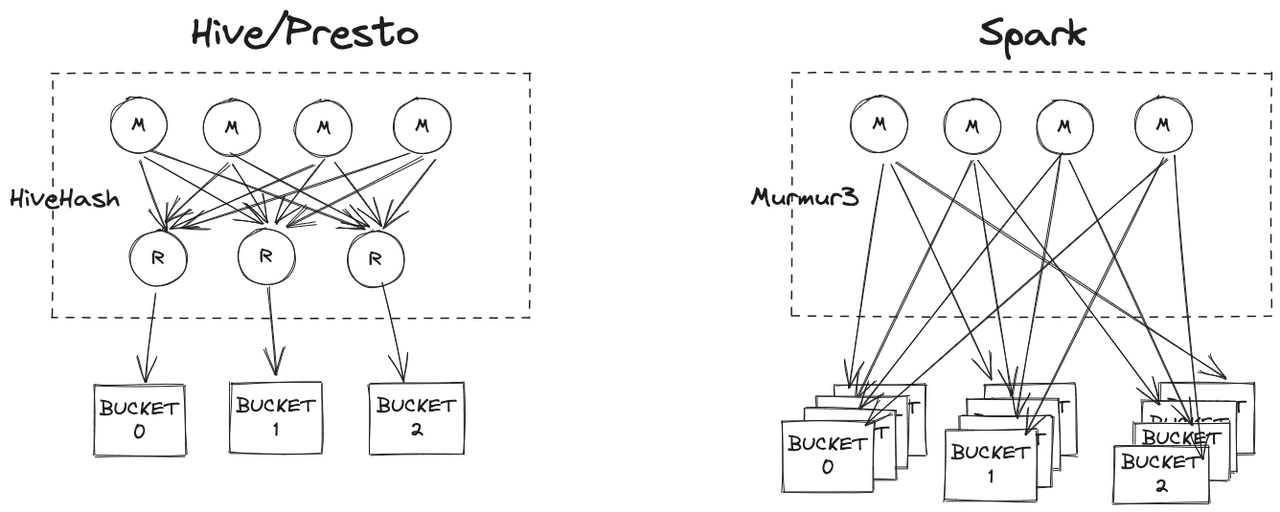
Wie aus der obigen Abbildung ersichtlich ist, schreibt Hive vor dem Schreiben der Bucket-Tabelle dieselben Bucket-Daten durch den Reduzierungsvorgang in eine Datei. Die native Bucket-Optimierung von Spark verfügt jedoch nicht über diesen Schritt, sodass die folgenden Probleme auftreten:
Problem 1 – Zu viele kleine Dateien : Die native Implementierung von Spark beim Schreiben der Bucket-Tabelle besteht darin, die Daten in die Datei auf der Mapper-Seite zu schreiben, und jede Map-Aufgabe kann mehrere Buckets mit Daten enthalten. Im schlimmsten Fall wird M generiert B-Dateien, M ist die Anzahl der Kartenaufgaben und B ist die Anzahl der Buckets. Gemäß dieser Logik sind die Daten in jedem Bucket in M Teile unterteilt, sodass es sich bei den meisten davon möglicherweise um kleine Dateien handelt. Wenn die Task-Parallelität 1000 und die Anzahl der Buckets 128 beträgt, werden im schlimmsten Fall MB = 128000 Dateien generiert. Eine so große Anzahl von Dateien erhöht den Druck auf den HDFS-NameNode erheblich und erhöht die Latenz beim HDFS-Lesen.
Problem 2 – Die Reihenfolge der Daten in einem einzelnen Bucket kann nicht garantiert werden : In der nativen Bucket-Tabelle von Spark befinden sich unter jedem Bucket mehrere Dateien und die Reihenfolge der Daten im Bucket kann nicht garantiert werden. Daher ist vor der Ausführung von SortMerge immer noch eine Sortierung erforderlich Verbinden. .
Da Presto mit der Hive-Bucket-Optimierung kompatibel ist und die native Bucket-Optimierung von Spark die beiden oben genannten Probleme aufweist, hat sich das LAS Spark-Team schließlich dafür entschieden, Spark mit der Hive-Bucket-Optimierung kompatibel zu machen. Die Implementierungsschritte sind wie folgt
- Fügen Sie dynamisch einen Shuffle hinzu, wobei die Bucket-Spalte als Reduzierungsschlüssel dient und der Parallelitätsgrad mit der Anzahl der Buckets übereinstimmt. Sortieren Sie die Daten vor dem Ausschreiben und stellen Sie sicher, dass die Daten im selben Bucket nur in eine Datei geschrieben werden Die Daten im Bucket sind in Ordnung.
- Unterstützt die HiveHash-Hash-Funktion für Spark, sodass mit Hive kompatible Bucket-Tabellen geschrieben, Hive-Bucket-Tabellen gelesen und Bucket-Informationen verwendet werden können, um Shuffle zu eliminieren.
Unterstützen Sie die Shuffle-Eliminierung in weiteren Szenarien
Die Anzahl der Buckets steht in einem multiplen Verhältnis
Spark erfordert, dass nur Bucket-Tabellen mit der gleichen Anzahl von Buckets den Shuffle vor ShuffledJoin eliminieren können. Bei zwei Tabellen mit sehr unterschiedlicher Größe, z. B. einer Dimensionstabelle mit Hunderten von GB und einer Faktentabelle mit Dutzenden von TB (einzelne Partition), ist die Anzahl der Buckets häufig unterschiedlich und die Anzahl ist sehr unterschiedlich. Standardmäßig sind die Buckets vor dem Join kann nicht entfernt werden. Shuffle. Um den durch Shuffle verursachten Overhead so weit wie möglich zu reduzieren, unterstützt LAS Spark „Shuffle before Join of Bucket“-Tabellen, die die Beziehung, die ein Vielfaches der Anzahl von Buckets ist, auf zwei Arten eliminieren.
Bei der ersten Methode entspricht die Anzahl der Aufgaben der Anzahl der Buckets in der kleinen Tabelle . Wie in der folgenden Abbildung dargestellt, enthält Tabelle A 3 Buckets und Tabelle B 6 Buckets. Zu diesem Zeitpunkt sollte die Datenerfassung von Bucket 0 und Bucket 3 von Tabelle B mit Bucket 0 von Tabelle A verknüpft werden. In diesem Fall können 3 Aufgaben gestartet werden. Verknüpfen Sie in Aufgabe 0 Bucket 0 von Tabelle A und Bucket 0 + Bucket 3 von Tabelle B. Hier müssen Sie die Zusammenführungssortierung erneut für die Daten in Bucket 0 und Bucket 3 von Tabelle B durchführen, um sicherzustellen, dass die Sammlung in Ordnung ist.
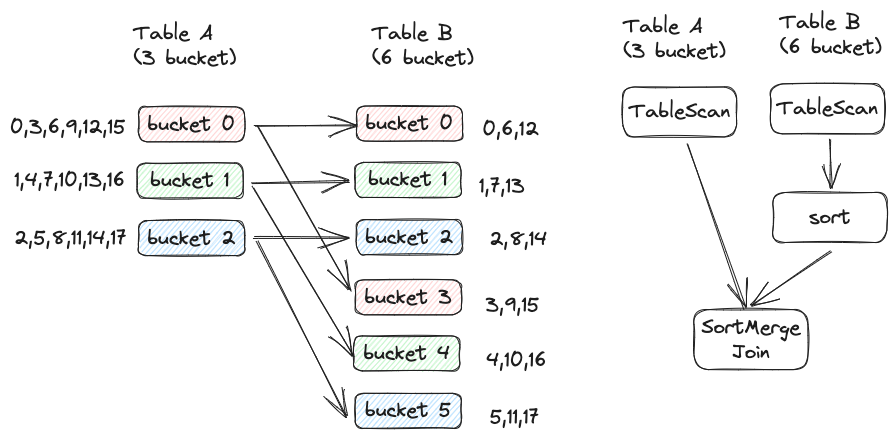
Wenn die Anzahl der Buckets in Tabelle A und Tabelle B nicht sehr unterschiedlich ist, können Sie die obige Methode verwenden. Wenn die Anzahl der Buckets in Tabelle B zehnmal so hoch ist wie die Anzahl der Buckets in Tabelle A, kann die obige Methode zwar Shuffle vermeiden, aufgrund unzureichender Parallelität jedoch langsamer sein als der SortMerge Join einschließlich Shuffle. Zu diesem Zeitpunkt kann eine andere Methode verwendet werden, d. h. die Anzahl der Aufgaben entspricht der Anzahl der Buckets in der großen Tabelle , wie in der folgenden Abbildung dargestellt:
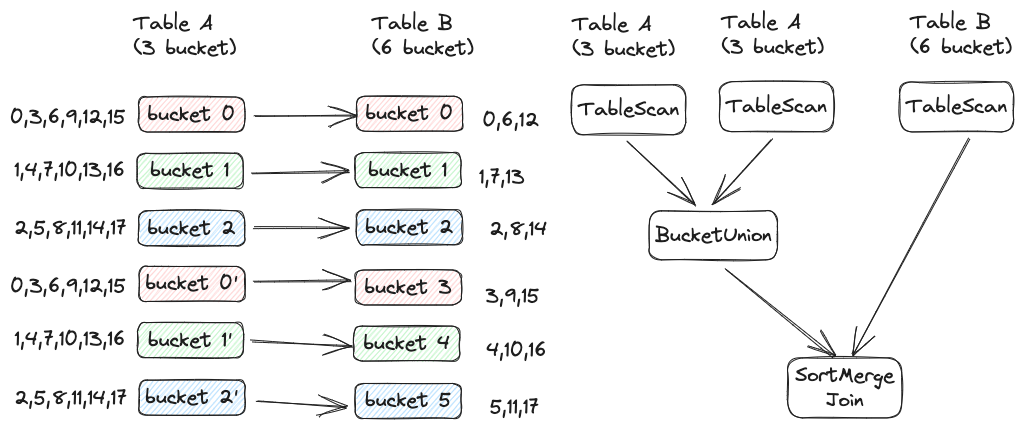
In diesem Szenario können die drei Buckets der Tabelle A mehrmals gelesen werden. In der obigen Abbildung wird BucketUnion direkt für Tabelle A ausgeführt (ein neuer Operator, ähnlich wie Union, behält jedoch die Bucket-Eigenschaften bei). Das Ergebnis entspricht dem Einteilen von Tabelle A in 6 Buckets, was dem Bucketing von Tabelle B entspricht . Die Zahlen sind gleich.
Shuffle Key ist eine Obermenge von Bucket-Spalten
Eine gemeinsame Tabelle kann mit einer anderen Tabelle basierend auf dem Feld „Benutzer“ verknüpft werden, sie kann mit einer anderen Tabelle basierend auf den Feldern „Benutzer“ und „App“ verknüpft werden und sie kann mit anderen Tabellen basierend auf den Feldern „Benutzer“ und „Element“ verknüpft werden. Die native Bucket-Optimierung von Spark erfordert, dass der Join-Schlüsselsatz genau mit der Bucket-Spalte der Tabelle übereinstimmt, um den Shuffle vor ShuffledJoin zu eliminieren. In diesem Szenario sind die Schlüsselsätze verschiedener Joins unterschiedlich, sodass die Bucket-Optimierung nicht gleichzeitig verwendet werden kann. Dies schränkt die anwendbaren Szenarien der Bucket-Optimierung erheblich ein.
Um dieses Problem anzugehen, unterstützt das LAS Spark-Team die Bucket-Optimierung in Superset-Szenarien. Solange der Join-Schlüsselsatz die Bucketing-Spalte enthält, kann der Shuffle vor dem Shuffled Join eliminiert werden.
Wie in der folgenden Abbildung dargestellt, werden die Tabellen X und Y entsprechend Feld A in Gruppen eingeteilt. Die Abfrage muss Tabelle X und Tabelle Y verknüpfen, und der Join-Schlüsselsatz ist A und B. Da zu diesem Zeitpunkt die gleichen Daten von A in den beiden Tabellen dieselbe Bucket-ID haben, müssen die gleichen Daten von A und B in den beiden Tabellen auch dieselbe Bucket-ID haben. Daher erfüllt die Datenverteilung die Join-Anforderungen und erfordert kein Shuffle. Gleichzeitig muss die Bucket-Optimierung auch sicherstellen, dass die beiden Tabellen gemäß dem Join-Schlüsselsatz, also A und B, sortiert werden. Zu diesem Zeitpunkt müssen nur Tabelle X und Tabelle Y innerhalb der Partition sortiert werden. Da beide Seiten nach Feld A sortiert wurden, ist der Aufwand für die Sortierung nach Feld A und B relativ gering.
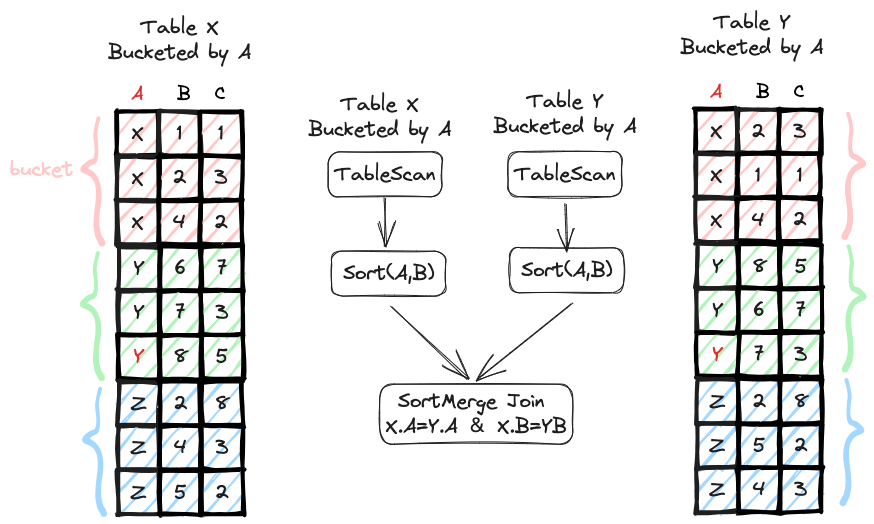
Shuffle-Eliminierung beim Schreiben der Bucket-Tabelle
Nach der Kompatibilität mit der Hive-Bucket-Optimierung ist ein weiterer Shuffle erforderlich, bevor in die Bucket-Tabelle geschrieben wird. Wenn die Verteilung der geschriebenen Daten jedoch die Bucketing-Anforderungen erfüllt, ist kein zusätzlicher Shuffle erforderlich. LAS Spark identifiziert zwei solcher Szenarien
- Fall 1: Wenn der zuvor in die Bucket-Tabelle geschriebene Operator „Gruppieren nach/Fenster/Inner Join/Links-Join/Rechts-Join“ ist, wird die Shuffle-Eliminierung unterstützt. In einigen Szenarios ist der zuvor in die Bucket-Tabelle geschriebene Operator „Full Out“. Shuffle-Eliminierung wird auch beim Beitreten unterstützt. Der oben erwähnte Join bezieht sich auf Shuffled Join.
- Fall 2: Nur wenn der zuvor in die Bucket-Tabelle geschriebene Operator „Gruppieren nach“ ist, wird die Eliminierung von Shuffle beim Schreiben von Obermengen unterstützt.
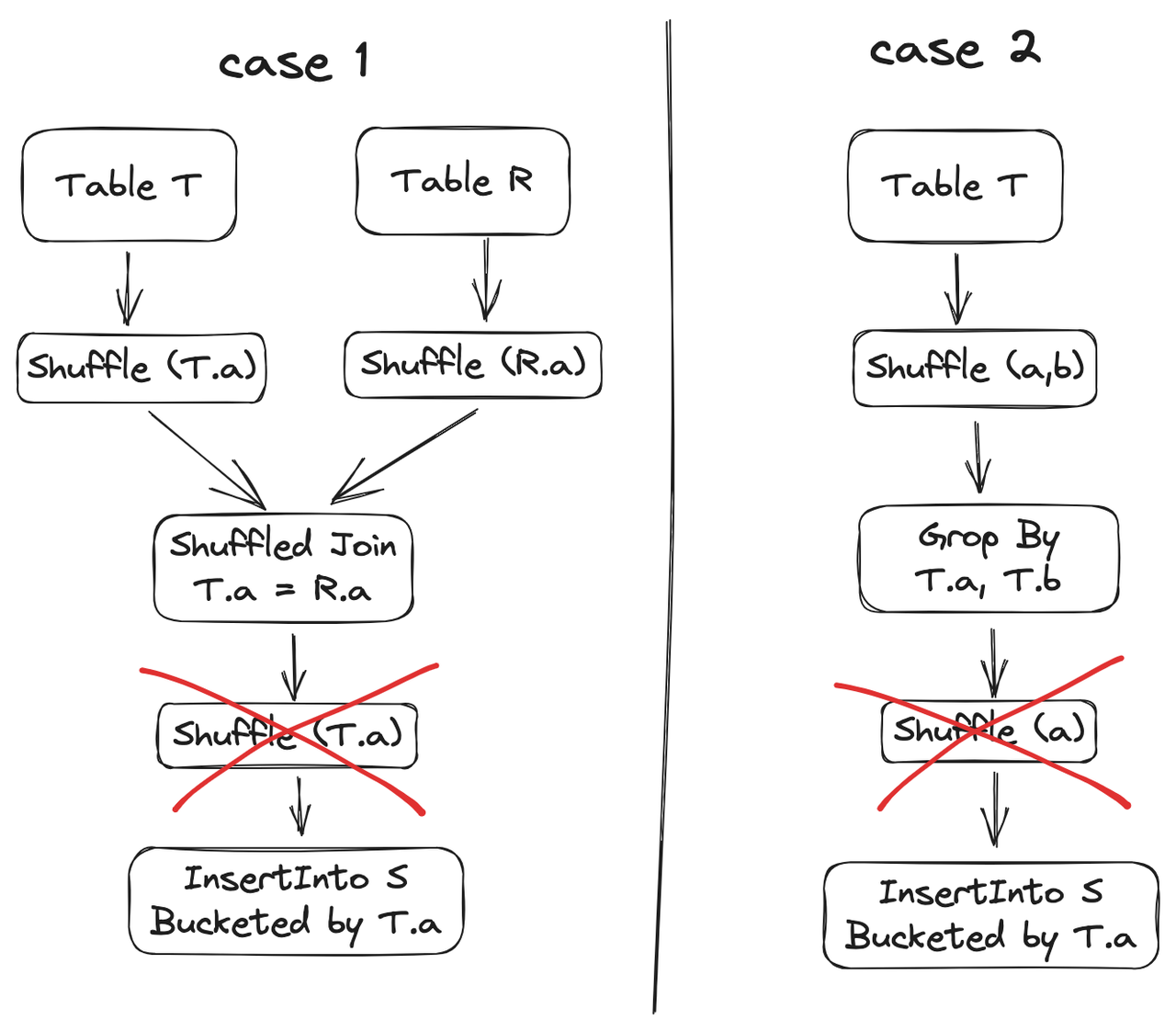
Kompatibel mit historischen Nicht-Bucket-Partitionen
Bei der Förderung der Bucket-Optimierung zur Abdeckung weiterer Aufgaben hoffen Benutzer, dass auch die Inventartabelle transformiert werden kann, um die Vorteile der Bucket-Optimierung zu nutzen. Wenn Sie Bucket-Informationen direkt in die Metainformationen der Tabelle schreiben, wird beim Abfragen historischer Partitionsdaten ein Fehler gemeldet, da diese nicht gemäß den Anforderungen der Bucket-Tabelle verteilt werden. Allerdings sind die historischen Daten in der Inventartabelle relativ groß und der Aufwand für die Neugenerierung gemäß der Bucket-Verteilung ist zu hoch, was die Implementierung erschwert. Um die oben genannten Probleme zu lösen, hat das LAS Spark-Team die Syntax von SparkSQL erweitert, um die Änderung von Tabellenattributen durch DDL zu ermöglichen, sodass die Tabelle ab einem bestimmten Punkt die Umwandlung in eine Bucket-Tabelle unterstützt.
alter table tbl clustered by (a) sorted by (a) into 8 buckets;
Wenn das oben genannte DDL ausgeführt wird, werden das Datum der DDL-Ausführung und die Bucket-Informationen in den Metainformationen der Tabelle aufgezeichnet. Wenn anschließend Daten geschrieben werden, werden die Daten gemischt, um der Bucket-Verteilung zu entsprechen. Wenn Sie ShuffledJoin ausführen, prüfen Sie zunächst, ob die abgefragten Daten nur Partitionen nach dem DDL-Ausführungsdatum enthalten. Wenn dies der Fall ist, wird sie als Bucket-Tabelle behandelt und unterstützt die Bucket-Optimierung; andernfalls wird sie als gewöhnliche Tabelle behandelt.
Unterstützt das Festlegen der Anzahl von Buckets auf Partitionsebene
Da die Datenmenge mit dem Unternehmenswachstum zunimmt, führt dies dazu, dass eine einzelne Aufgabe übermäßig viele Daten verarbeiten muss. Daher unterstützt LAS Spark das Festlegen der Anzahl der Buckets nach Partitionsebene. Bei Partitionen mit großen Mengen an Geschäftsdaten kann die Anzahl der Buckets größer eingestellt werden, um den Shuffle-Overhead zu reduzieren und die Parallelität zu verbessern.
Angenommen, es gibt eine Bucket-Tabelle, die von mehreren Geschäftsbereichen in derselben Abteilung verwendet wird, und die Anzahl der auf Tabellenebene definierten Buckets beträgt 1024.
create table department (
user_id int ,
user_info string
) partitioned by ( date string, business string)
clustered by(user_id) sorted by(user_id) into 1024 buckets;
Unter diesen speichert die Partition „business = ‚ hot ‘“ die Daten beliebter Unternehmen, und die Datenmenge ist etwa doppelt so hoch wie die anderer Unternehmen . LAS Spark unterstützt das Festlegen einer größeren Anzahl von Buckets für diese Partition durch Erweiterung der SparkSQL-Syntax wie folgt:
ALTER TABLE department PARTITION(business='hot') SET NUM_BUCKETS = 2048;
Datenschreiben: Wenn beim Schreiben von Daten in die Tabelle die aktuelle Partition über Informationen zur Anzahl der Buckets auf Partitionsebene verfügt, werden die Daten entsprechend der Anzahl der Buckets auf Partitionsebene geschrieben. Andernfalls werden die Daten entsprechend ausgeschrieben die Anzahl der Buckets auf Tabellenebene.
Datenauslesung:
- Die Situation beim Lesen einer einzelnen Partition ist einfacher zu verstehen. Beim Lesen werden die Bucketing-Informationen auf Partitionsebene bevorzugt. Wenn nicht, werden die Bucketing-Informationen auf Tabellenebene ausgewählt.
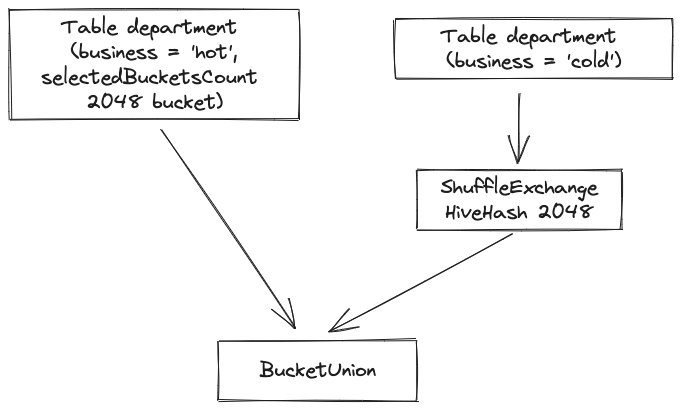
- Wenn beim Lesen mehrerer Partitionen alle Partitionen die gleiche Anzahl von Buckets haben, werden sie als gewöhnliche Bucket-Tabellen behandelt. Andernfalls behält die Partition mit der größten Anzahl von Buckets die Bucket-Informationen bei und die Daten der verbleibenden Partitionen werden als gelesen gewöhnliche Partitionen. Die folgende Abbildung ist ein Beispiel. Die Hot- und Cold-Partitionen der Abteilungstabelle werden gleichzeitig gelesen. Ersteres hat 2048 Buckets und letzteres 1024 Buckets. Beim Lesen der Partitionen werden die Bucket-Informationen der Hot-Partition und die Daten gelesen der kalten Partition bleibt erhalten. Führen Sie Shuffle aus und führen Sie dann BucketUnion (Union-Operator, der Bucket-Informationen behält) für die beiden Datenteile aus, damit die Abteilungstabelle wie eine Bucket-Tabelle mit der Bucket-Nummer 2048 aussieht. Bucket-Optimierung kann sein später verwendet.

Anwendung der Bucket-Optimierung innerhalb von Bytes
Business-Hintergrund
Die Stabilität der Datenproduktionsverbindung ist besonders wichtig. Sobald Aufgaben in der Verbindung fehlschlagen oder die Ausgabe verzögern, führt dies zu vielen Problemen für das Unternehmen. Wenn am Beispiel von Videodaten die Stabilität der Videodaten-Produktionsverbindung nicht gewährleistet werden kann, entstehen folgende Risiken:
- Das Risiko einer SLA-Verletzung ist hoch: Das Datenvolumen ist groß, Ressourcen werden verbraucht und eine einzelne Ausführung dauert lange. Sobald sie fehlschlägt und erneut ausgeführt wird, kann es leicht zu einer SLA-Verletzung kommen;
- Hohe Betriebs- und Wartungskosten: Nachts kann es leicht zu Alarmen kommen, und wenn sich die Bereitschaftszeiten für Aufgaben erheblich verzögern, ist nach der Planung ein manuelles Eingreifen erforderlich, um eine Überlastung der Warteschlangen zu vermeiden. Der gesamte Prozess erfordert viel Personal.
Bei einer bestimmten Link-Aufgabe innerhalb von Byte ist der zeitaufwändige und risikoreiche Prozess hauptsächlich der Shuffle-Link. Derzeit ist das Shuffle-Datenvolumen der Aufgabe groß, sodass die Wahrscheinlichkeit steigt, auf verschiedene Problemknoten zu stoßen. Es treten häufig Probleme wie fehlerhafte Knoten und langsame Knoten auf, die zu Shuffle-Fehlern führen. Gleichzeitig ist es einfach, die Knoten des Shuffle-Dienstes zu füllen, was dazu führt, dass die Aufgabe einen erneuten Versuch mit Abruffehler ausführt. Wenn die Wiederholungsversuche mehr als dreimal dauern, wird die gesamte Spark-Anwendung beendet.
Bucket-Transformation
Durch logische Analyse von Link-Aufgaben und kombiniert mit Bucket-Eigenschaften wird die Bucket-Optimierung auf den gesamten Link angewendet. Der vollständige Link bezieht sich hier auf die ODS-Schicht bis hin zur DM-Schicht. Solange die Bucket-Funktion im Link verwendet werden kann, wurde sie umgewandelt; insgesamt wurden mehr als die Hälfte der Tabellen im Link in Bucket-Tabellen umgewandelt. Nutzen Sie bei der Transformation so viele Bucket-Optimierungen wie möglich durch die folgenden Methoden:
- Durch die Analyse der Aufgaben im Link wurde festgestellt, dass die Schlüssel der meisten Join- und Group By-Vorgänge die Arbeits-ID enthalten. Daher wird die Arbeits-ID als Bucketing-Spalte ausgewählt, sodass der durch Join/ eingeführte Shuffle-Schlüssel verwendet wird. „Gruppieren nach/Fenster“ ist die Bucketing-Spalte. Eine Obermenge von Bucket-Spalten, wodurch diese Mischvorgänge vermieden werden.
- Stellen Sie sicher, dass die Anzahl der Buckets zwischen den Upstream- und Downstream-Links ein Vielfaches beträgt, um alle möglichen Shuffles zu vermeiden. Insbesondere muss die Anzahl der festzulegenden Buckets eine Potenz von 2 sein, um sicherzustellen, dass die Anzahl der Buckets in verschiedenen Bucket-Tabellen in einer Mehrfachbeziehung steht.
Vorteile bei Renovierungen
Nach der Full-Link-Bucket-Transformation ergeben sich auf der Full-Link-Ebene folgende Vorteile :
- Reduzieren Sie das Shuffle großer Aufgaben : Beseitigen Sie das Problem des Shuffle großer Tabellen und reduzieren Sie eine große Menge an Shuffle-Daten.
- Die Stabilität des Verbindungsbetriebs wurde verbessert : Es gibt kein Shuffle-Fehlerproblem bei nächtlichen Produktionsverbindungen.
Die Vorteile auf der Ebene der einzelnen Aufgaben sind wie folgt:
- Reduzierung von Long-Tail -Aufgaben: Die Zeit einer einzelnen Aufgabe kann um durchschnittlich 20 % verkürzt werden.
- Ressourceneinsparung: CPU- und Speicherressourcen können um 10–20 % eingespart werden.
- Laufzeit: Es gibt keine zusätzliche Erhöhung der Task-Laufzeit. Einige Tasks können durch die Reduzierung von Long-Tail-Tasks um 20 % verkürzt werden.
Zusammenfassen
Die Bucket-Optimierung ist ein sehr effektives technisches Mittel zur Eliminierung von Exchange und zur Optimierung der Shuffle-Ebene. Der native Spark-Bucket unterstützt jedoch keine Inventartabellenmigration, kann die Anzahl der Buckets nicht erweitern, nachdem das Datenvolumen zunimmt, und die Optimierungsabdeckungsszenarien sind ebenfalls relativ begrenzt. Für die oben genannten Punkte hat das Scenario LAS Spark-Team eine Reihe von Verbesserungen vorgenommen, die die Benutzerfreundlichkeit von Bucket erheblich verbessert und den Optimierungsbereich erweitert haben. Die oben genannten erweiterten Funktionen können direkt auf LAS verwendet werden. Jeder ist willkommen, es aktiv auszuprobieren Kommen Sie vorbei und machen Sie Vorschläge. Wertvolle Kommentare und Vorschläge.
Lakehouse Analytics Service LAS (Lakehouse Analytics Service) ist ein serverloser Datenverarbeitungs- und Analysedienst für die integrierte Lakehouse-Architektur. Er bietet umfangreiche Datenspeicherberechnungen und interaktive Analysefunktionen auf EB-Ebene aus einer Hand, basierend auf den Best Practices von ByteDance. Er ist kompatibel mit Spark und Presto Ecology hilft Unternehmen beim einfachen Aufbau intelligenter Echtzeit-Lagerhäuser am See. Der Newcomer-Rabatt kommt! Es gibt exklusive Vorteile für alle neuen Benutzer. Die spezielle 1-Yuan-Flash-Sale-Veranstaltung von LAS Data für Neulinge in China und Taiwan ist neu gestartet! Es warten auch viele Stapelrabatte darauf, von Ihnen ergattert zu werden! Wir danken Ihnen allen für Ihre anhaltende Unterstützung und Ihre Liebe zu uns. Wir werden Ihnen weiterhin bessere Inhalte bieten. (Klicken Sie auf den Link für ein reibungsloses Erlebnis)
Link: zjsms.com/jVCr5bp/