Nota: Nadie ha introducido en detalle las estructuras generadora y discriminadora de CycleGAN. Aquí agregaré algunas. Existen
diferencias entre la pérdida del modelo y el modelo. Lo complementaré según el código fuente. Por favor, preste más atención.
Introducción
[Dirección de descarga del artículo] [ https://arxiv.org/abs/1703.10593 ]
Prefacio
CycleGan es una red GAN que implementa la función de conversión de estilo de imagen. Pix2Pix existía mucho antes de que apareciera implementar la conversión de estilos de imagen, pero pip2pip tiene grandes limitaciones, principalmente para que los dos estilos de imágenes aparezcan correspondientemente. En realidad, es difícil encontrar algunas imágenes con diferentes estilos y el mismo estilo, y puede También será difícil de cambiar. Después de disparar, CycleGan implementa esta función y convierte entre dos tipos de imágenes sin necesidad de correspondencia. ¡Es muy potente y práctico! ! !
Esta también es una imagen generada por datos no emparejados, lo que significa que tiene algunas obras de celebridades y algunas imágenes reales cuyo estilo desea cambiar, y no hay intersección entre las dos imágenes. La clave del método Pix2Pix mencionado en el artículo anterior (Aumentar la imaginación humana con IA) es proporcionar muestras de entrenamiento con los mismos datos en ambos dominios. La innovación de CycleGAN es que puede lograr este tipo de migración entre el dominio de origen y el dominio de destino sin establecer un mapeo uno a uno entre los datos de entrenamiento. Para lograr esto, hay dos puntos
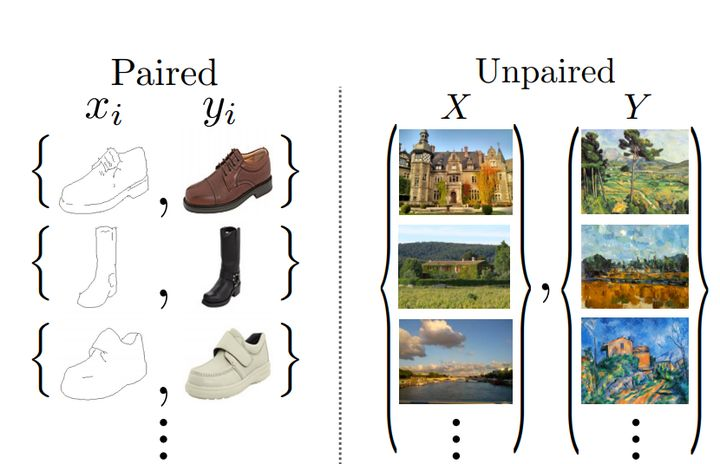
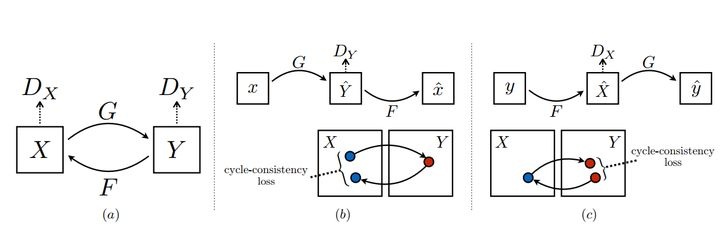
importantes: el primero es un doble discriminador. . Como se muestra en la Figura a a continuación, las dos distribuciones X, Y, los generadores G, F son las asignaciones de X a Y e Y a X respectivamente, y los dos discriminadores Dx, Dy pueden discriminar las imágenes convertidas. El segundo punto es la pérdida de coherencia del ciclo. Utilice otras imágenes en el conjunto de datos para probar el generador. Esto es para evitar que G y F se sobreajusten. Por ejemplo, si desea convertir una foto de un cachorro al estilo Van Gogh, si hay sin pérdida de coherencia del ciclo, el generador podría generar una pintura real de Van Gogh para engañar a Dx, ignorando la entrada del cachorro.
Estructura generadora y discriminadora.
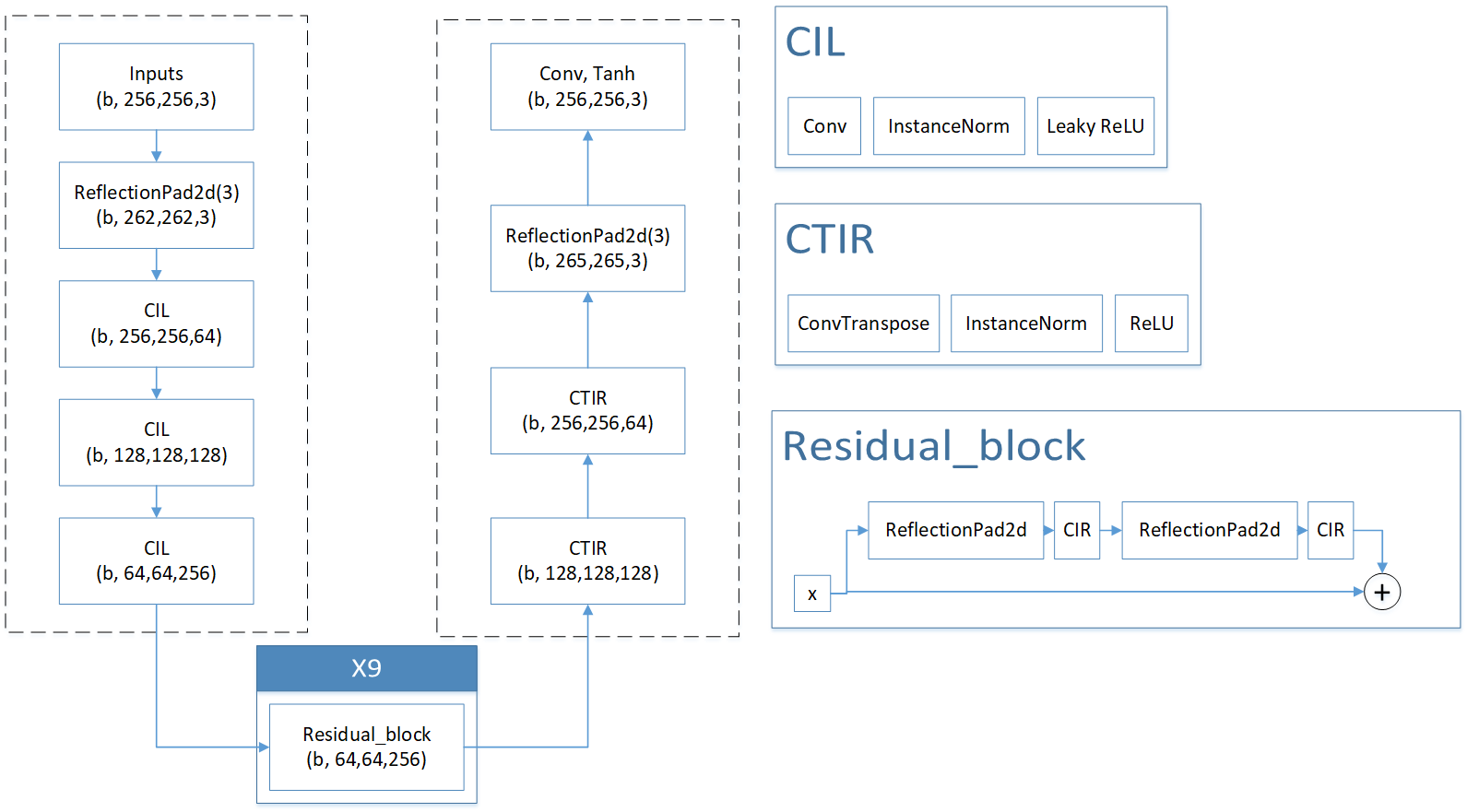
La siguiente figura es el diagrama de estructura del generador que dibujé en base al código correspondiente. Se puede ver claramente que la estructura del generador es relativamente simple. Se divide principalmente en estructuras de codificador. Entre ellas, el decodificador usa CIL ( convolución, regularización IN, función de activación Leaky ReLU) y mejora de imagen (ReflectionPad2d, que es un método de simetría de la imagen hacia arriba, abajo, izquierda y derecha a lo largo del borde para aumentar la resolución de la imagen). Utilice el módulo de bloque residual en las dos áreas de enlace estructural. El valor predeterminado es 9 módulos repetidos para restaurar y mejorar los datos. La parte del codificador utiliza funciones de deconvolución, normalización IN y activación ReLU para restaurar el tamaño de la imagen. Finalmente, la resolución de la imagen aumenta a través de ReflectionPad2d y la imagen se restaura al tamaño original a través de la convolución, resolviendo efectivamente la información del borde del objeto.
El discriminador original en la figura siguiente es un discriminador que utiliza la estructura patchGAN. El objetivo de este discriminador es comparar la matriz de salida con una estructura NxN. Esto genera el concepto de comparación global y tiene en cuenta la diferencia en la información del campo receptivo global.

Nota: La siguiente imagen es una versión simplificada de PatchGAN, que se simplifica directamente en un discriminador. La estructura del discriminador es muy simple. Es directamente una estructura de cadena, se transforma y finalmente se aplana en una estructura (b, 1). el segundo discriminador vinculado a github.

descarga de Internet
Enlace de Github: https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
Este es el autor original del artículo, que contiene dos modelos Cyclegan y pix2pix, implementados en base a Pytorch.
Configure el entorno de acuerdo con los requisitos del autor y configure el código en ejecución para que se ejecute ¿El efecto es bueno? De hecho, esto depende principalmente de la complejidad de la conversión entre estilos: si la conversión es demasiado compleja, el efecto será pobre y si es simple, el efecto será mejor.
El modelo anterior parece ser relativamente complicado. Aquí proporciono un enlace de GitHub reproducido que será más fácil de entender.
https://github.com/aitorzip/PyTorch-CycleGAN
La estructura de red del modelo anterior también la dibujé yo en base al código. Por favor haga cualquier pregunta y la corregiré a la brevedad.
pérdida de modelo
Las funciones de pérdida del generador y discriminador son las mismas que las de GAN: el discriminador D hace todo lo posible para detectar las imágenes falsas generadas por el generador G, y el generador hace todo lo posible para generar imágenes para engañar al discriminador.
Contra la pérdida:
Resumen:

LGAN ( G , DY , X , Y ) = E y pdata ( y ) [ DY ( y ) ] 2 + E x pdata ( x ) [ DY ( G ( x ) ) − 1 n ∗ n ] 2 L_{GAN}(G,D_Y,X,Y) = E_{y~p_{datos(y)}}[D_Y(y)]^2 + E_{x~p_{datos(x)}}[D_Y( G(x))-1_{n*n}]^2lgan _ _( G ,DY,x ,Sí )=miyp _ data(y)[ DY( y ) ]2+mixp _ d a t a ( x )[ DY( G ( x ))−1norte ∗ norte]2
DY D_YDYLo que se genera es una matriz, por lo que lo que se compara aquí es una matriz y la pérdida de MSE se utiliza para calcular la pérdida.
así como

Pérdida de consistencia del ciclo
Los autores dicen: En teoría, el entrenamiento adversario puede aprender a mapear las salidas G y F, que producen la misma distribución que los dominios objetivo Y y X, respectivamente. Sin embargo, con una capacidad lo suficientemente grande, la red puede asignar el mismo conjunto de imágenes de entrada a cualquier permutación aleatoria de imágenes en el dominio de destino. Por lo tanto, no se garantiza que la pérdida adversa por sí sola mapee una sola entrada. Se necesita una pérdida adicional para garantizar que G y F no solo puedan satisfacer sus respectivos discriminadores, sino que también puedan aplicarse a otras imágenes. En otras palabras, G y F pueden trabajar juntos para hacer trampa y darle una foto a G. G convierte secretamente al cachorro en un autorretrato de Van Gogh, y F convierte el autorretrato de Van Gogh en una entrada. La llegada de la pérdida de consistencia del ciclo detuvo este comportamiento oportunista. Probó FG con otras pinturas de Van Gogh y probó GF con otras fotos reales para ver si se podía cambiar a su apariencia original. Esto aseguró que GF estuviera en toda la X. Y Universalidad del intervalo de distribución.

en general:
Por lo tanto, toda la pérdida es la siguiente fórmula, al igual que entrenar dos codificadores automáticos:

preste atención a dos detalles:
-
La función de pérdida utilizada en la pérdida adversaria es BCELoss.

Cuando el autor entrenó la pérdida adversaria, no usó BCELoss (función de pérdida de entropía cruzada de dos clases), sino que usó MSE (error cuadrático medio). El autor explicó que El efecto de entrenamiento del error cuadrático medio es mejor. -
La pérdida de identidad no está escrita en el documento, pero el código fuente refleja la pérdida de identidad. Esta pérdida se utiliza principalmente para entrenar la capacidad de reconocimiento de la red, expresada como A a B (real B ) AtoB (real_B)A a B ( real a l _B) , para explicar, es ingresar el B real en el discriminador que genera B a partir de A y verificar la pérdida de reconocimiento del discriminador. ¡Espero que cuanto más pequeño, mejor! Esto muestra que la red generadora realmente comprende la estructura de B. De la misma manera , B a A (real A) BtoA(real_A)también existeBt o A ( real a lun)。
L identidad = E y pdata ( y ) [ ∣ ∣ DY ( G ( y ) ) − y ∣ ∣ 1 ] + E x pdata ( x ) [ ∣ ∣ DX ( G ( x ) ) − x ∣ ∣ 1 ] L_{identidad} = E_{y~p_{datos(y)}}[||D_Y(G(y))-y||_1]+E_{x~p_{datos(x)}}[||D_X (G(x))-x||_1]li d e n t i t y=miyp _ data(y)[ ∣∣D _Y( G ( y ))−y ∣ ∣1]+mixp _ d a t a ( x )[ ∣∣D _X( G ( x ))−x ∣ ∣1]
准确的说,
Pérdida = LGAN ( G , DY , X , Y ) + LGAN ( G , DX , Y , X , ) + L cyc + L identidad Pérdida = L_{GAN}(G,D_Y,X,Y ) + L_{GAN}(G,D_X,Y,X,)+L_{cyc} + L_{identidad}pérdida _=lgan _ _( G ,DY,x ,Sí )+lgan _ _( G ,DX,Y ,x ,)+lciclo+li d e n t i t y
Después de leer el código fuente, resuma la implementación de Loss:
LGAN = 1 2 ∗ E x − pdata ( x ) [ DY ( G ( X ) ) − 1 ] 2 + 1 2 ∗ E y − pdata ( y ) [ DX ( F ( Y ) ) − 1 ] 2 L_{GAN} = \frac{1}{2}*E_{x-p_{data}(x)}[D_Y(G(X))-1]^2+\frac { 1}{2}*E_{y-p_{datos}(y)}[D_X(F(Y))-1]^2lgan _ _=21∗mix - pd a t a( x )[ DY( G ( X ))−1 ]2+21∗miy−pd a t a( y )[ DX( F ( Y ))−1 ]2
L ciclo = E x − pdata ( x ) [ ∣ ∣ F ( G ( X ) ) − X ∣ ∣ 1 ] + E y − pdata ( y ) [ ∣ ∣ G ( F ( Y ) ) − Y ∣ ∣ 1 ] L_{ciclo}=E_{x-p_{datos}(x)}[||F(G(X))-X||_1]+E_{y-p_{datos}(y)}[|| G(F(Y))-Y||_1]lciclo _ _=mix - pd a t a( x )[ ∣∣ F ( GRAMO ( X ))−X ∣ ∣1]+miy−pd a t a( y )[ ∣∣ G ( F ( Y ))−Y ∣ ∣1]
L identidad = E x − pdata ( x ) [ ∣ ∣ F ( X ) − X ∣ ∣ 1 ] + E y − pdata ( y ) [ ∣ ∣ G ( Y ) − Y ∣ ∣ 1 ] L_{identidad}= E_{x-p_{datos}(x)}[||F(X)-X||_1]+E_{y-p_{datos}(y)}[||G(Y)-Y||_1 ]li d e n t i t y=mix - pd a t a( x )[ ∣∣ F ( X )−X ∣ ∣1]+miy−pd a t a( y )[ ∣∣ G ( Y )−Y ∣ ∣1]
L = LGAN + L ciclo + L identidad L=L_{GAN}+L_{ciclo}+L_{identidad}l=lgan _ _+lciclo _ _+li d e n t i t y
Resumir
CycleGAN tiene muchas y ricas aplicaciones, creo que se puede combinar con todos los campos, especialmente si se puede ampliar el conjunto de datos, definitivamente se lograrán buenos resultados. Además, creo que la red CycleGAN también se puede ajustar. Todavía hay muchas deficiencias. ¡Mejorar el modelo es una buena sugerencia!