Documento: Dual Path Networks
Enlace del artículo: https://arxiv.org/abs/1707.01629
Código: https://github.com/cypw/DPNs
Código DPN para modelos entrenables bajo el marco MXNet: https://github.com/ milagrowkf /DPN
Sabemos que ResNet, ResNeXt, DenseNet y otras redes tienen efectos obvios en el campo de la clasificación de imágenes, y se puede decir que DPN integra las ideas centrales de ResNeXt y DenseNet: Dual Path Network (DPN) utiliza ResNet como marco principal para garantizar Grado de baja redundancia de funciones y se le agrega una rama DenseNet muy pequeña para generar nuevas funciones.
¿Cuáles son las ventajas de la DPN? Puede ver los dos puntos siguientes:
1. Con respecto a la complejidad del modelo , el texto original del autor decía: El DPN-92 cuesta aproximadamente un 15% menos de parámetros que ResNeXt-101 (32 4d), mientras que el DPN-98 cuesta alrededor de 26 % menos parámetros que ResNeXt-101 (64 4d)
2. Con respecto a la complejidad computacional , el texto original del autor decía: DPN-92 consume aproximadamente un 19% menos FLOP que ResNeXt-101 (32 4d), y el DPN-98 consume aproximadamente 25% menos FLOP que ResNeXt-101(64 4d).
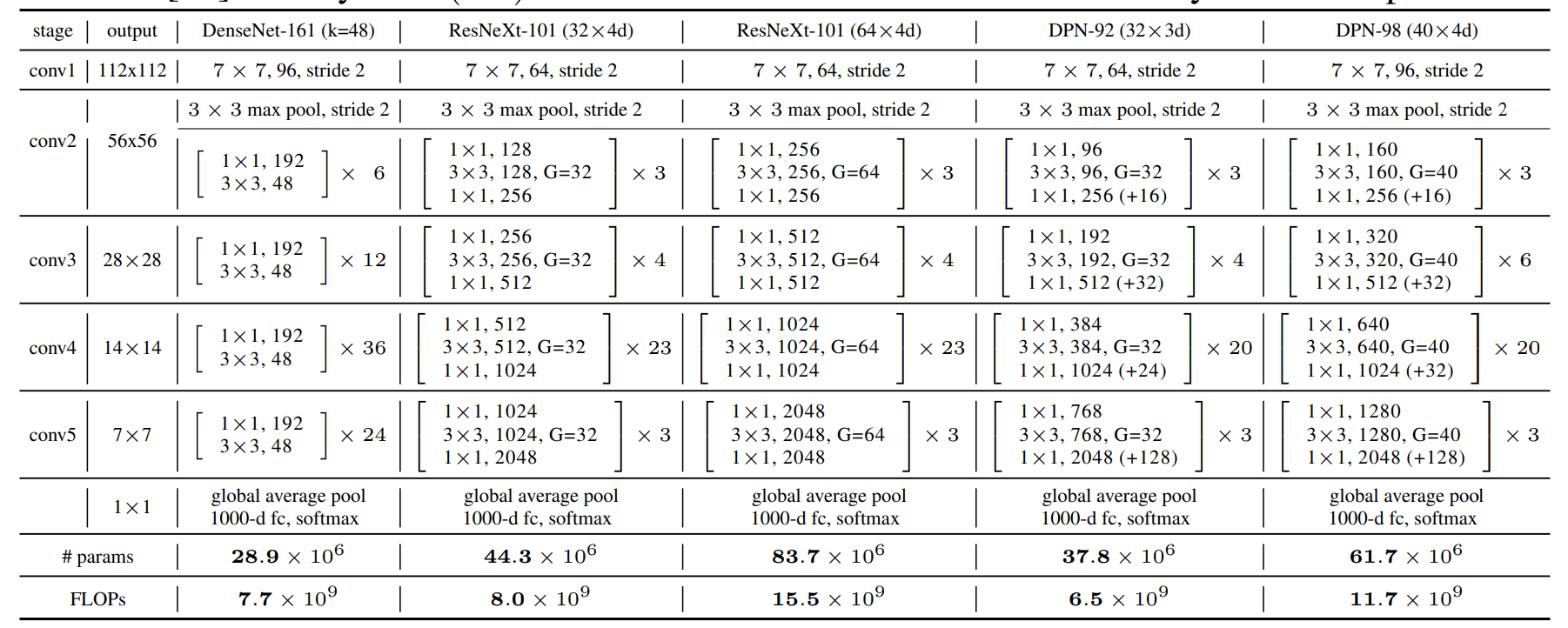
Coloque primero la estructura de red Tabla 1 (arriba) y tenga una impresión intuitiva.
De hecho, la estructura de DPN y ResNeXt (ResNet) es muy similar. Al principio, una capa convolucional de 7 * 7 y una capa de agrupación máxima, luego 4 etapas, cada etapa contiene varias subetapas (descritas más adelante), seguidas de una agrupación promedio global y una capa de conexión completa, y finalmente una capa softmax. La atención se centra en el contenido del escenario, que también es el núcleo del algoritmo DPN.
Debido a que el algoritmo DPN es simplemente para integrar ResNeXt y DenseNet en una red, antes de presentar la estructura en cada etapa de DPN, repasemos brevemente ResNet (la subestructura de ResNeXt y ResNet es la misma macroscópicamente) y DenseNet.
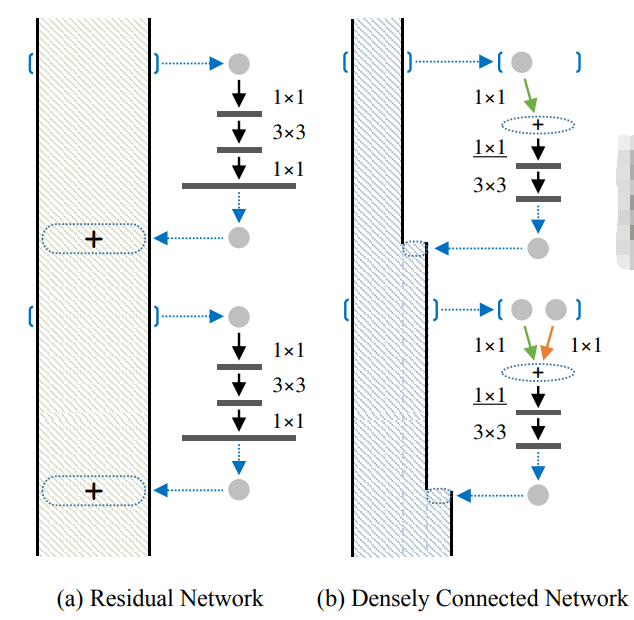
(a) en la figura siguiente es parte de una etapa de ResNet. El cuadro rectangular grande en el lado izquierdo de (a) indica el contenido de entrada y salida. Para una entrada x, se divide en dos líneas. Una línea es x en sí misma y la otra línea es x después de una convolución 1 × 1 y 3 Convolución ×3., convolución 1 × 1 (la combinación de estas tres capas convolucionales también se llama cuello de botella), y luego haga una suma por elementos de la salida de estas dos líneas, es decir, agregue los valores correspondientes, que es el Además en (a) No., el resultado obtenido se convierte en la entrada del siguiente mismo módulo, y varios de esos módulos se combinan para formar una etapa (como conv3 en la Tabla 1).
(b) representa el contenido principal de DenseNet. El cuadro poligonal vertical en el lado izquierdo de (b) representa el contenido de entrada y salida. Para la entrada x, solo se toma una línea, es decir, después de varias capas de convolución, se fusiona con x en un canal (cancat) , y el resultado se convierte en el siguiente La entrada de un módulo pequeño, de modo que la entrada de cada módulo pequeño se acumula continuamente, por ejemplo: la entrada del segundo módulo pequeño incluye la salida del primer módulo pequeño y la entrada del primero módulo pequeño, etc.
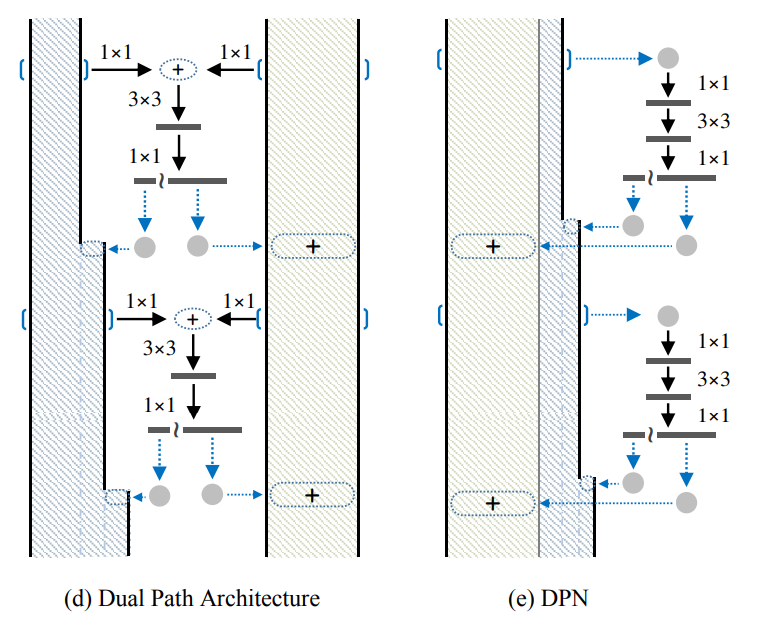
¿Cómo lo hace la DPN? En pocas palabras, es la fusión de Red Residual y Red Densamente Conectada. (d) y (e) en la siguiente figura tienen el mismo significado, así que hablemos de (e). Los rectángulos verticales y polígonos en (e) tienen el mismo significado que antes. Específicamente en el código, para una entrada x (en dos casos: uno es si x es la salida de la primera capa convolucional de toda la red o la salida de una determinada etapa, se realizará una convolución en x y luego se cortará, Es decir, dividir la salida en dos partes según el canal: data_o1 y data_o2, que pueden entenderse como el marco rectangular vertical y el marco poligonal en (e); la otra es la salida de un subescenario dentro del escenario, y la salida en sí contiene dos partes: data_o1 y data_o2), tome dos líneas, una línea es para mantener data_o1 y data_o2 en sí, similar a ResNet; la otra línea es para hacer convolución 1 × 1, convolución 3 × 3, convolución 1 × 1 en x, y luego haga un corte para obtener dos partes c1 y c2, y finalmente agregue c1 y data_o1 (suma de elementos) para obtener la suma, similar a la operación en ResNet; c2 y data_o2 fusionan los canales (concat) para volverse densos. (de modo que la siguiente capa Puede obtener la salida de esta capa y la entrada de esta capa), es decir, finalmente devolver dos valores: suma y denso.
El proceso anterior es una subetapa de una etapa en DPN. Hay dos detalles, uno es que la convolución 3 × 3 utiliza una operación de grupo, similar a ResNeXt, y el otro es que se realizará una operación de ampliación de canal en la parte densa al principio y al final de cada subetapa.
El autor implementó el algoritmo DPN bajo el marco MXNet, el símbolo específico se puede ver en: https://github.com/cypw/DPNs/tree/master/settings, que es muy detallado y fácil de entender.
Resultados experimentales:
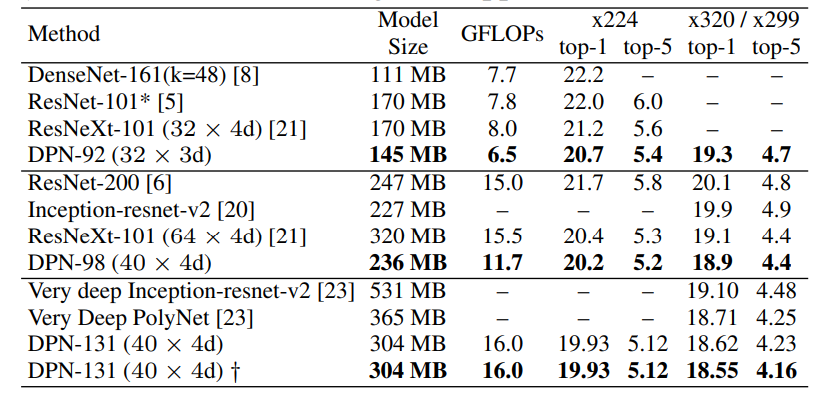
la Tabla 2 es una comparación entre el conjunto de datos ImageNet-1k y los mejores algoritmos actuales: ResNet, ResNeXt, DenseNet. Se puede ver que la red DPN es mejor en términos de tamaño del modelo, GFLOP y precisión. Sin embargo, en esta comparación, parece que el desempeño de DenseNet no es tan gratificante como el presentado en el artículo de DenseNet, probablemente porque DenseNet requiere más habilidades de capacitación.
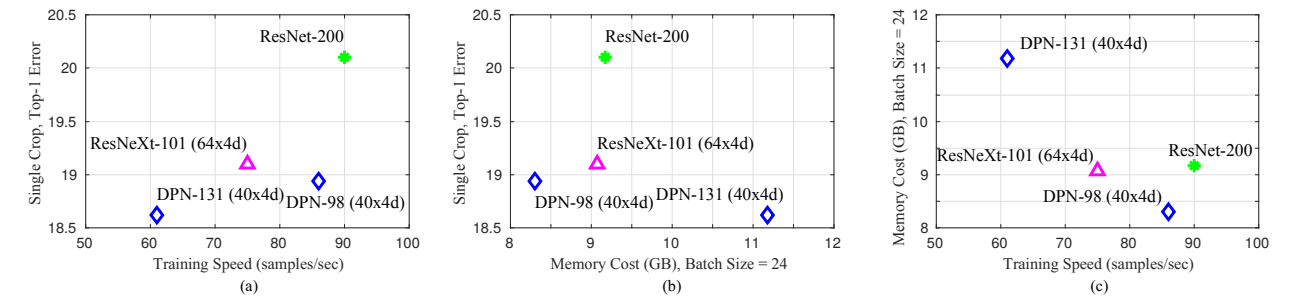
La Figura 3 es una comparación de la velocidad de entrenamiento y el espacio de almacenamiento. Ahora, para mejorar el modelo, puede ser difícil mejorar la tasa de precisión como un punto de innovación obvio, porque el rango no es grande, por lo que la mayoría de ellos todavía están optimizados en términos de tamaño del modelo y complejidad computacional. , siempre que se pueda mejorar un poco la tasa de precisión.
Resumen:
Se puede entender que la red DPN propuesta por el autor introduce el contenido central de DenseNet sobre la base de ResNeXt, lo que hace que el modelo utilice más plenamente las funciones. El principio no es difícil de entender y es más fácil de entrenar en el proceso de ejecución del código. Al mismo tiempo, los experimentos en el artículo también muestran que el modelo tiene buenos resultados en los conjuntos de datos de clasificación y detección.