GoogLenet
VGG fue propuesto por el famoso grupo de investigación de la Universidad de Oxford vGG (Grupo de Geometría Visual) en 2014, y ganó el primer lugar en la Tarea de Localización (tarea de posicionamiento) y el segundo lugar en la Tarea de Clasificación (tarea de clasificación) en la competencia imageNet ese año . El primer lugar en la Tarea de clasificación (tarea de clasificación) es GoogleNet. GoogleNet es una estructura de red profunda desarrollada por Google. La razón por la que se llama "GoogLeNet" es para rendir homenaje a "LeNet".
Aspectos destacados de la red GoogLenet
1. Introdujo la estructura Inception (fusión de información de características de diferentes escalas)
2. Use el núcleo de convolución 1x1 para la reducción de dimensiones y el procesamiento de mapas
3. Agregue dos clasificadores auxiliares para ayudar en el entrenamiento
4. Descarte la capa completamente conectada y use la capa de agrupación promedio ( reduce significativamente los parámetros del modelo)
Estructura de inicio
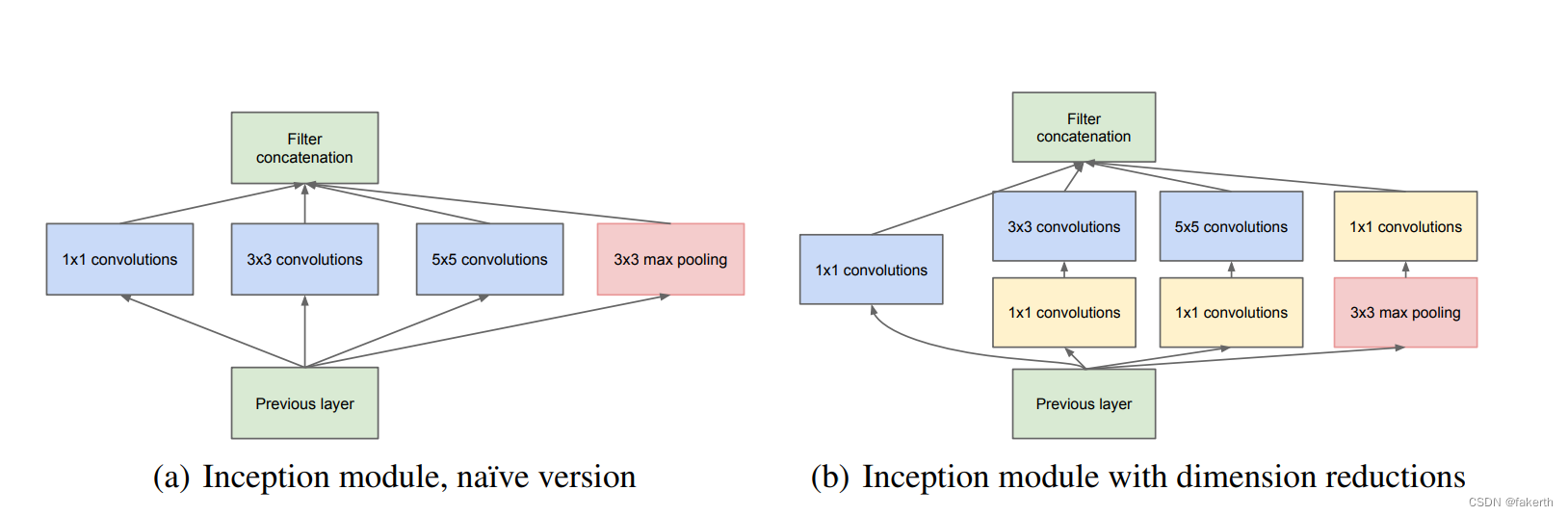
La estructura básica del Módulo de Inicio tiene cuatro componentes. convolución 1x1, convolución 3x3, convolución 5x5, agrupación máxima 3x3. Finalmente, la combinación de canales de los resultados de las operaciones de cuatro componentes es la idea central de Naive Inception (figura a arriba): use núcleos de convolución de diferentes tamaños para lograr la percepción de diferentes escalas, y finalmente realice la fusión para obtener una mejor representación de la imagen. Tenga en cuenta que la altura y el ancho de la matriz de características obtenida por cada rama deben ser iguales. Pero Naive Inception tiene dos problemas muy serios: primero, todas las capas convolucionales están directamente conectadas a la entrada de datos de la capa anterior, por lo que la cantidad de cálculo en la capa convolucional será grande; segundo, la agrupación máxima utilizada en esta unidad La capa conserva la profundidad del mapa de características de los datos de entrada, por lo que al fusionarse al final, la profundidad del mapa de características de salida total solo aumentará, lo que aumenta la cantidad de cálculo de la estructura de la red después de la unidad. Entonces, el objetivo principal de usar el kernel de convolución 1x1 aquí es comprimir y reducir la dimensionalidad y reducir la cantidad de parámetros, que es la figura b anterior, para hacer que la red sea más profunda y más amplia, y extraer mejor las características.Esta idea es también llamado Pointwise Conv, o PW para abreviar. .
Haga un pequeño cálculo, asumiendo que el canal de la imagen de entrada es 512, use 64 kernels de convolución 5x5 para la convolución, y los parámetros requeridos para la reducción de dimensión sin usar kernels de convolución 1x1 son 512x64x5x5=819200. Si se utilizan 24 núcleos de convolución 1x1 para la reducción de dimensionalidad, el canal de imagen es 24 y luego se convolucionó con 65 núcleos de convolución, los parámetros requeridos son 512x24x1x1+24x65x5x5=50688.
clasificador auxiliar
De acuerdo con los datos experimentales, se encuentra que la capa intermedia de la red neuronal también tiene una gran capacidad de reconocimiento. Para utilizar las características abstractas de la capa intermedia, se agrega un clasificador con múltiples capas a algunas capas intermedias. Como se muestra en la siguiente figura, el interior del borde rojo representa el clasificador auxiliar agregado. GoogLeNet ha agregado dos ramas auxiliares de softmax, que tienen dos funciones: una es evitar la desaparición del gradiente y conducir el gradiente hacia adelante. Si una capa de derivación es 0 durante la retropropagación, el resultado de la derivación en cadena es 0. El segundo es utilizar la salida de una capa intermedia como clasificación para desempeñar un papel en la fusión de modelos. La pérdida final = pérdida_2 + 0,3 * pérdida_1 + 0,3 * pérdida_0. En las pruebas reales, se eliminarán estas dos ramas auxiliares de softmax.
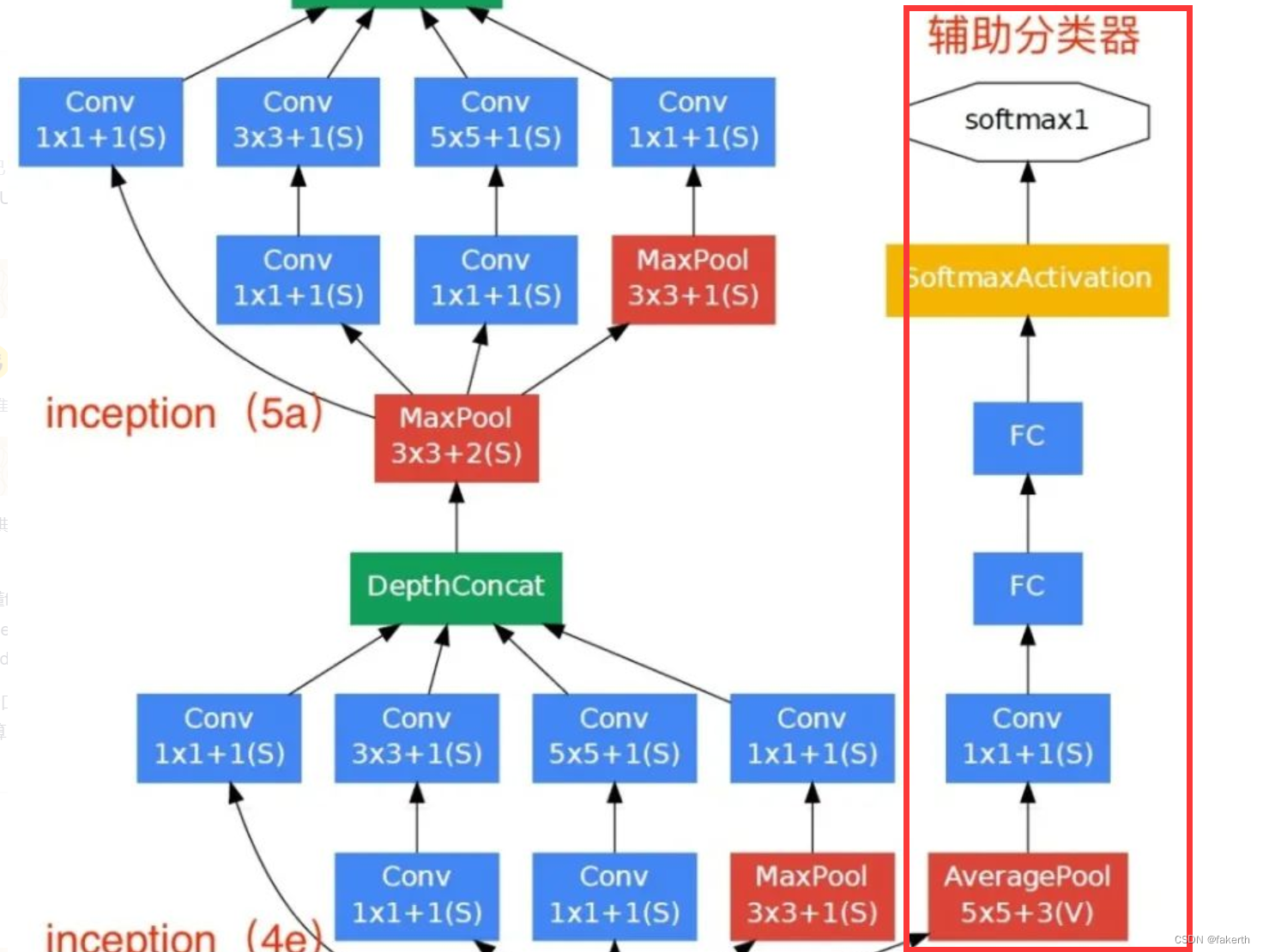
1. Capa de agrupación promedio
Con un tamaño de ventana de 5×5 y un paso de 3, el resultado es una salida de 4×4×512 para (4a) y 4×4×528 para el escenario (4d).
2. Capa de convolución
Se utilizan 128 núcleos de convolución 1 × 1 para convolución (reducción de dimensión), utilizando la función de activación ReLU.
3. Capa completamente conectada
La capa totalmente conectada de 1024 nodos también utiliza la función de activación de ReLU.
4.abandono
La deserción desactiva aleatoriamente las neuronas a una tasa del 70%.
5.softmax
Salida 1000 resultados de predicción a través de softmax.
Estructura de la red GoogLenet
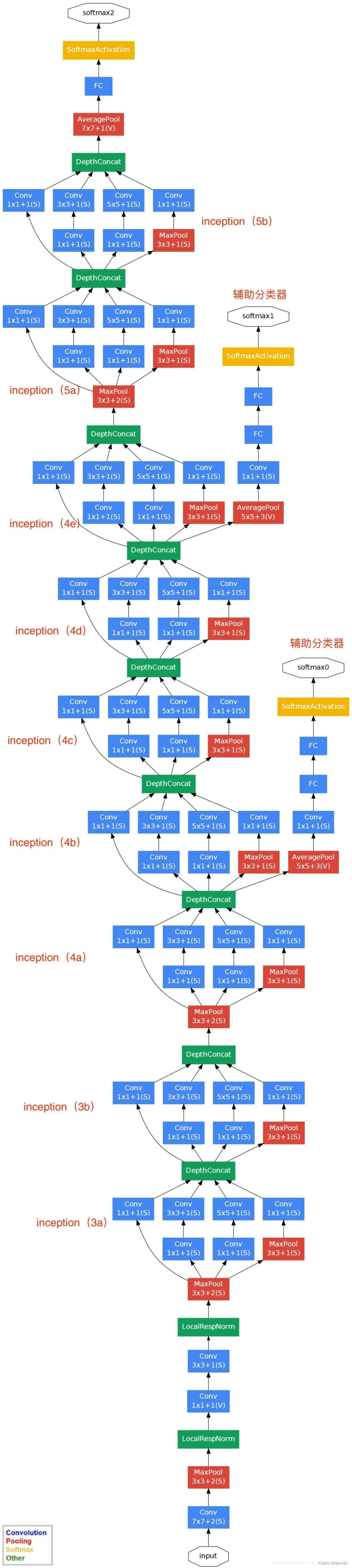
La estructura de red de GoogLeNet en forma de tabla es la siguiente: ¿
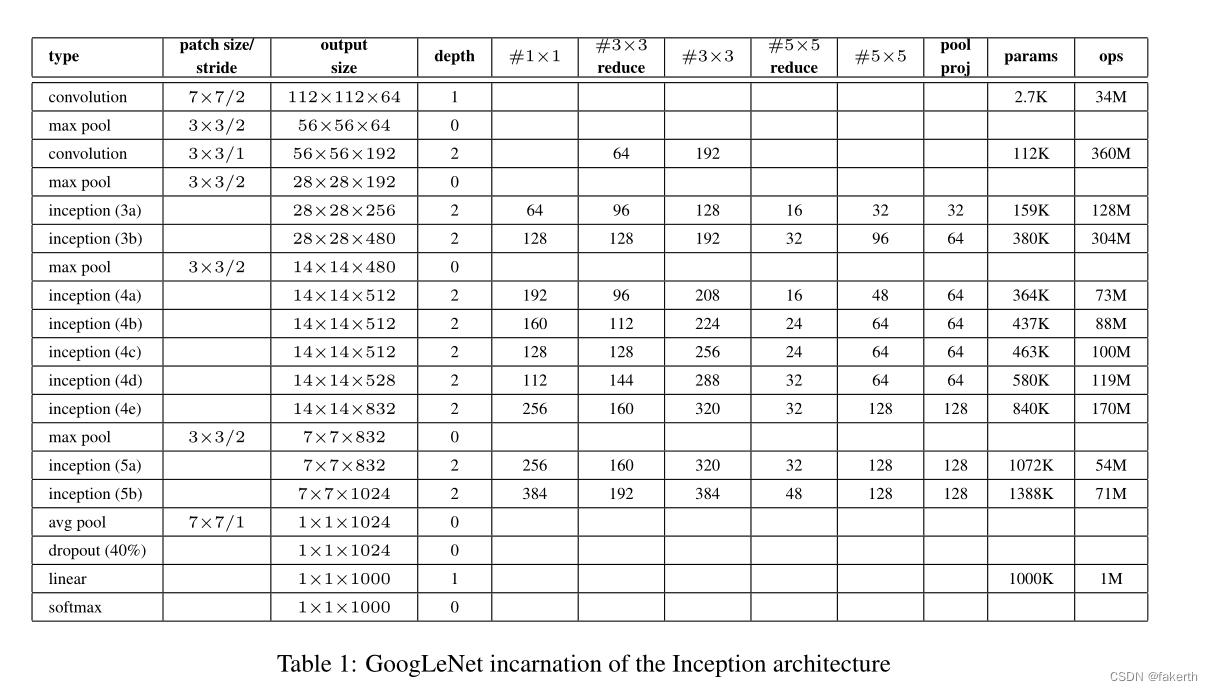
Cómo ve los parámetros de la estructura de Inception? Está marcado en la imagen de abajo.
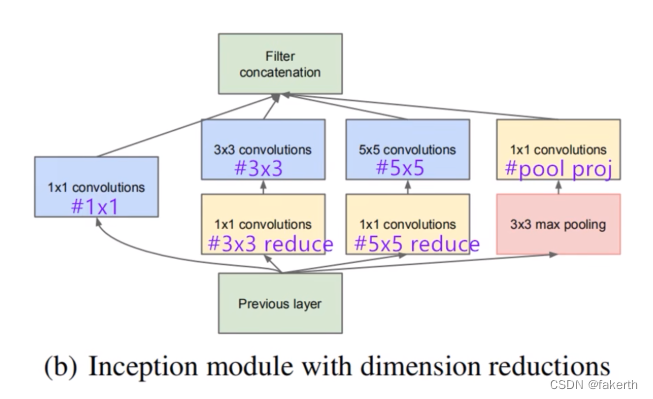
Presentemos la estructura del modelo de GoogLeNet en detalle.
1. Capa de convolución

La imagen de entrada es 224x224x3, el tamaño del kernel de convolución es 7x7, el tamaño del paso es 2, el relleno es 3, el número de canales de salida es 64 y el tamaño de salida es (224-7+3x2)/2+1=112.5 (redondeado hacia abajo) = 112, la salida es 112x112x64 y la operación ReLU se realiza después de la convolución.
2. Capa de agrupación máxima

El tamaño de la ventana es 3x3, el tamaño del paso es 2, el tamaño de salida es ((112 -3)/2)+1=55,5 (redondear hacia arriba)=56 y la salida es 56x56x64.
3. Dos capas convolucionales

La primera capa: use 64 núcleos de convolución 1x1 (reducción de la dimensión antes del núcleo de convolución 3x3) para cambiar el mapa de características de entrada (56x56x64) a 56x56x64 y luego realice la operación ReLU.
La segunda capa: use el kernel de convolución tamaño 3x3, el tamaño de paso es 1, el relleno es 1, el número de canales de salida es 192 y se realiza la operación de convolución. El tamaño de salida es (56-3+1x2)/1 +1=56, y la salida es 56x56x192, y luego realice la operación ReLU.
4. Capa de agrupación máxima

El tamaño de la ventana es 3x3, el tamaño del paso es 2, el número de canales de salida es 192, la salida es ((56 - 3)/2)+1=27,5 (redondear hacia arriba)=28 y la dimensión del mapa de características de salida es 28x28x192.
5.Inicio 3a

1. Use 64 núcleos de convolución 1x1, la salida después de la convolución es 28x28x64 y luego la operación RuLU.
2.96 Los núcleos de convolución 1x1 (reducción de la dimensión antes de los núcleos de convolución 3x3) están convolucionados y la salida es 28x28x96, y se realiza el cálculo ReLU, y luego se realizan 128 convoluciones 3x3 para generar 28x28x128.
3.16 Los núcleos de convolución 1x1 (reducción de la dimensión antes de los núcleos de convolución 5x5) están convolucionados y la salida es 28x28x16, y se realiza el cálculo ReLU, y luego se realizan 32 convoluciones 5x5, y la salida es 28x28x32.
4. La capa de agrupación máxima, el tamaño de la ventana es 3x3, la salida es 28x28x192 y luego se realizan 32 convoluciones 1x1, y la salida es 28x28x32.
6.Inicio 3b
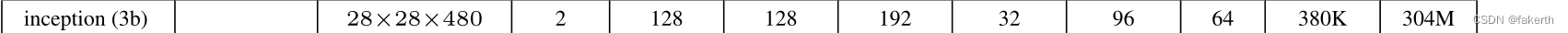
7. Capa de agrupación máxima

8. Inicio 4a 4b 4c 4d 4e

9. Capa máxima de agrupación

10.Inicio 5a 5b
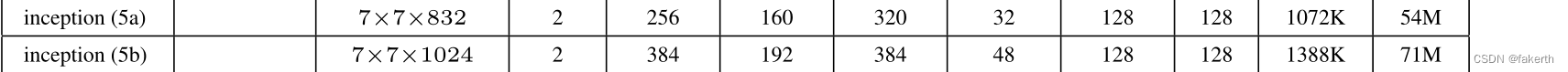
11. Capa de salida

GoogLeNet usa una capa de agrupación promedio para obtener una capa convolucional con una altura y un ancho de 1; luego, el abandono desactiva aleatoriamente las neuronas al 40 %; la función de activación de la capa de salida usa softmax.
Implementación de GoogLenet
Implementación de Inicio
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
# 在官方的实现中,其实是3x3的kernel并不是5x5,这里我也懒得改了,具体可以参考下面的issue
# Please see https://github.com/pytorch/vision/issues/906 for details.
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
Implementación de GoogLenet
import torch.nn as nn
import torch
import torch.nn.functional as F
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_logits: # eval model lose this layer
return x, aux2, aux1
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
# 在官方的实现中,其实是3x3的kernel并不是5x5,这里我也懒得改了,具体可以参考下面的issue
# Please see https://github.com/pytorch/vision/issues/906 for details.
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = self.averagePool(x)
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
x = F.dropout(x, 0.5, training=self.training)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes
return x
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
modelo de entrenamiento
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdm
from model import GoogLeNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(), # 随机左右翻转
# transforms.RandomVerticalFlip(), # 随机上下翻转
transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.1),
transforms.RandomRotation(degrees=5),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
train_dataset = datasets.ImageFolder(root='./Training',
transform=data_transform["train"])
train_num = len(train_dataset)
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
json_str = json.dumps(cla_dict, indent=4)
with open(
'class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 32
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root='./Test',
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num, val_num))
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
net = GoogLeNet(num_classes=131, aux_logits=True, init_weights=True) # num_classes根据分类的数量而定
# 如果要使用官方的预训练权重,注意是将权重载入官方的模型,不是我们自己实现的模型
# 官方的模型中使用了bn层以及改了一些参数,不能混用
# import torchvision
# net = torchvision.models.googlenet(num_classes=5)
# model_dict = net.state_dict()
# # 预训练权重下载地址: https://download.pytorch.org/models/googlenet-1378be20.pth
# pretrain_model = torch.load("googlenet.pth")
# del_list = ["aux1.fc2.weight", "aux1.fc2.bias",
# "aux2.fc2.weight", "aux2.fc2.bias",
# "fc.weight", "fc.bias"]
# pretrain_dict = {
k: v for k, v in pretrain_model.items() if k not in del_list}
# model_dict.update(pretrain_dict)
# net.load_state_dict(model_dict)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0003)
epochs = 30
best_acc = 0.0
save_path = './googleNet.pth'
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
logits, aux_logits2, aux_logits1 = net(images.to(device))
loss0 = loss_function(logits, labels.to(device))
loss1 = loss_function(aux_logits1, labels.to(device))
loss2 = loss_function(aux_logits2, labels.to(device))
loss = loss0 + loss1 * 0.3 + loss2 * 0.3
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device)) # eval model only have last output layer
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()