Tabla de contenido
1. Introducción general al proyecto.
2. Introducción a la estructura de la red.
1. Diagrama de estructura general
YOLOv7是一种优秀的端到端检测算法。YOLOv7由Propuesto en 2022 por Alexey Bochkovskiy y Chien-Yao Wang y otros (equipo YOLOv4). YOLOv7 supera a todos los detectores de objetos conocidos en velocidad y precisión en el rango de 5 FPS a 120 FPS, con la precisión más alta del 56,8% AP entre todos los detectores de objetos en tiempo real conocidos a 30 FPS.
1. Introducción general al proyecto.
La carpeta del proyecto yolov7 y la carpeta del conjunto de datos están en el mismo nivel. Los conjuntos de datos se dividen en imágenes (imágenes) y etiquetas (etiquetas). Las imágenes y etiquetas se dividen en prueba (conjunto de prueba), tren (conjunto de entrenamiento), val ( conjunto de validación) tres carpetas.



La primera carpeta cfg en la carpeta yolov7 almacena el archivo de configuración del modelo (model.yaml). En la carpeta de datos se almacenan el archivo de configuración del conjunto de datos (data.yaml) y el archivo de configuración de hiperparámetros (hyperparameters.yam). La demostración implementada para el servidor de inferencia nvidia triton en la carpeta de implementación. La carpeta de figuras contiene algunas imágenes de resultados de demostración de yolov7 (detección 3D, detección de puntos clave, etc.). La inferencia almacena datos con inferencia (imágenes, carpetas). En los modelos se almacenan códigos de uso común para la composición de la estructura de la red yolov7. El documento es el documento yolov7. Las carreras son el resultado del entrenamiento y las pruebas. Herramientas incluye algunas herramientas en formato de archivo ipynb (conversión de modelos, comparación de modelos, etc.). Las funciones de utilidad (funciones de activación, funciones de dibujo, etc.) se almacenan en utilidades. .gitignore es el archivo ignorado de Docker. LICENSE.md es el archivo de licencia. README.md es el archivo de instrucciones de uso. Código de detección detect.py. Código de exportación del modelo export.py. hubconf.py es el archivo central de pytorch. requisitos.txt depende del archivo de entorno. archivo de prueba test.py. train.py es el archivo de entrenamiento para yolov7-tiny y yolov7. train_aux.py es el archivo de entrenamiento para yolov7-w6 y yolov7-e6. 
2. Introducción a la estructura de la red.
1. Diagrama de estructura general
La estructura general de yolov7 consta de cuatro partes: Entrada, Backbone, Head y Detect. La entrada es 640*640*3 entrada de datos. Backbone es la red troncal compuesta por CBS, ELAN y MP-1. El jefe está formado por CBS, SPPCSPC, E-ELAN, MP-2 y RepConv. Detectar son tres cabezales de detección. Excepto el código del módulo Detectar que está en models/yolo.py, los otros códigos del módulo están todos en models/common.py.
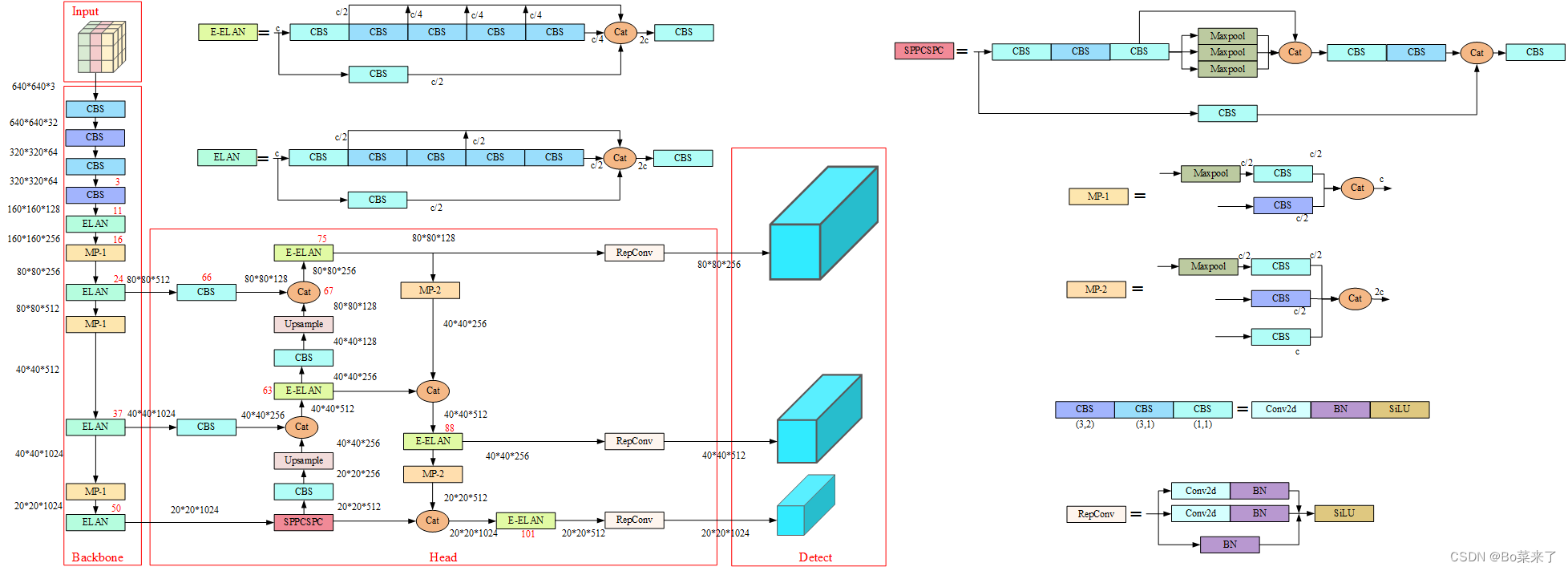
2.CBS
El código se muestra a continuación:
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))结构如下:

Entre ellos (3,2) hay un núcleo de convolución de 3 * 3 con un paso de 2. Se compone de convolución bidimensional, normalización por lotes y función de activación SiLU.
3.ELAN y E-ELAN
El módulo ELAN se compone de las rutas de gradiente más largas y más cortas. Se apilan más bloques a través de las rutas más cortas para aprender más funciones.

La estructura es la siguiente (E-ELAN a la izquierda, ELAN a la derecha):
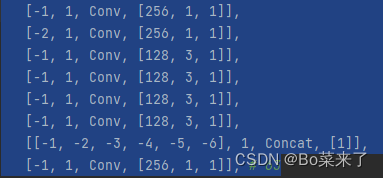
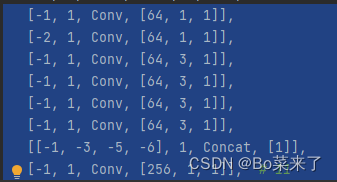

4.MP
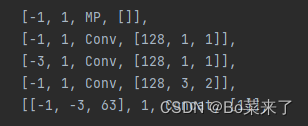
El papel general de MP: lograr una reducción de resolución que reduzca la pérdida de características. El módulo MP-1 consta de 2 ramas y el módulo MP-2 consta de 3 ramas. La primera rama primero usa Maxpool (agrupación máxima) para implementar la reducción de resolución y luego usa una convolución 1 * 1 para cambiar el número de canales. La otra rama de MP-1 es una convolución 3*3 con un tamaño de paso del núcleo de convolución de 2, que implementa la reducción de resolución.
Estructura de red (MP-1 a la izquierda, MP-2 a la derecha):


5. SPPCSP
La función de SPP es realizar la fusión de información de diferentes escalas de características, utilizando la agrupación máxima en cuatro escalas diferentes para el procesamiento. Los tamaños del núcleo de agrupación de la agrupación máxima son 13x13, 9x9, 5x5 y 1x1 (1x1 significa sin procesamiento). El módulo CSP se divide en dos partes: una parte realiza el procesamiento de la estructura SPP y la otra parte realiza el procesamiento del número de canal mediante convolución 1 * 1. Finalmente, las dos partes se concatenan. SPPCSP realiza la fusión de información de diferentes escalas de características, reduce la cantidad de cálculo y mejora la velocidad.
El código se muestra a continuación:
class SPPCSPC(nn.Module):
# CSP https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)):
super(SPPCSPC, self).__init__()
c_ = int(2 * c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c_, 3, 1)
self.cv4 = Conv(c_, c_, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
self.cv5 = Conv(4 * c_, c_, 1, 1)
self.cv6 = Conv(c_, c_, 3, 1)
self.cv7 = Conv(2 * c_, c2, 1, 1)
def forward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
y1 = self.cv6(self.cv5(torch.cat([x1] + [m(x1) for m in self.m], 1)))
y2 = self.cv2(x)
return self.cv7(torch.cat((y1, y2), dim=1))La estructura de la red es la siguiente:

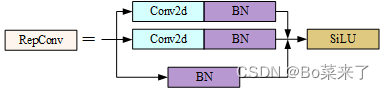
6.RepConv
yolov7 reemplaza Conv con RepConv al final del encabezado. La fase de entrenamiento consta de múltiples ramas, 3x3, 1x1 e identidad (mapeo), y la fase de inferencia se convierte en una sola convolución de 3x3, lo que reduce la cantidad de parámetros y acelera la inferencia. El proceso de capacitación de RepConv aprende más funciones y el proceso de inferencia se acelera.
El código se muestra a continuación:
class RepConv(nn.Module):
# Represented convolution
# https://arxiv.org/abs/2101.03697
def __init__(self, c1, c2, k=3, s=1, p=None, g=1, act=True, deploy=False):
super(RepConv, self).__init__()
self.deploy = deploy
self.groups = g
self.in_channels = c1
self.out_channels = c2
assert k == 3
assert autopad(k, p) == 1
padding_11 = autopad(k, p) - k // 2
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
if deploy:
self.rbr_reparam = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=True)
else:
self.rbr_identity = (nn.BatchNorm2d(num_features=c1) if c2 == c1 and s == 1 else None)
self.rbr_dense = nn.Sequential(
nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False),
nn.BatchNorm2d(num_features=c2),
)
self.rbr_1x1 = nn.Sequential(
nn.Conv2d( c1, c2, 1, s, padding_11, groups=g, bias=False),
nn.BatchNorm2d(num_features=c2),
)
def forward(self, inputs):
if hasattr(self, "rbr_reparam"):
return self.act(self.rbr_reparam(inputs))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.act(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)El proceso de formación se estructura de la siguiente manera:
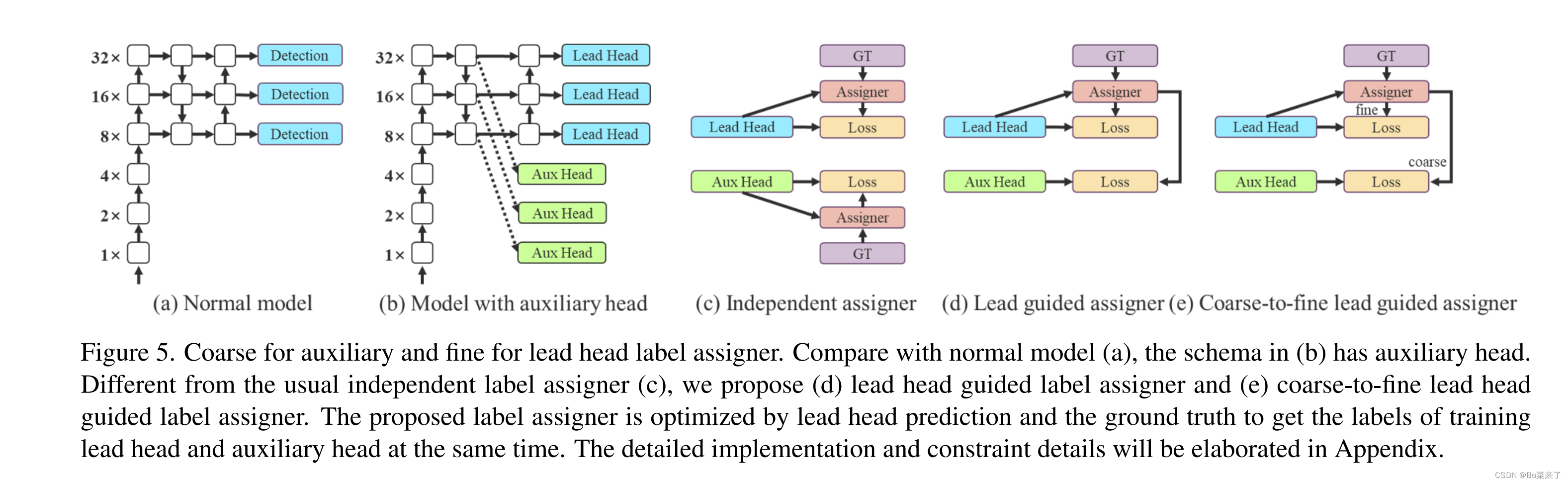
7.Detectar
El código está en la clase IDetect(nn.Module) de yolo.py. (d) El cabezal de detección genera etiquetas suaves a través del optimizador en función de los resultados del cabezal principal (cabezal líder) y GT (valor verdadero de la etiqueta). Las etiquetas suaves se utilizan al entrenar modelos para cabezales auxiliares (cabezales auxiliares) y cabezales principales. La razón de esto es que el líder principal tiene una capacidad de aprendizaje relativamente fuerte, por lo que las etiquetas suaves que genera deberían ser más representativas de la distribución y correlación entre los datos de origen y los datos de destino. Además, se agrega aprendizaje residual, lo que permite que el cabezal auxiliar menos profundo aprenda directamente la información aprendida por el cabezal principal, de modo que el cabezal principal pueda concentrarse mejor en aprender la información residual que no se ha aprendido. (e) Se agregaron ajustes.
3. Entrena tus propios datos
El proceso de formación es muy diferente al de otros YOLO. Consulte README.md directamente ![]() https://github.com/WongKinYiu/yolov7#readme
https://github.com/WongKinYiu/yolov7#readme