Escriba aquí el título del directorio
introducción
En los problemas de aprendizaje profundo que hemos encontrado en el pasado, la entrada a la red neuronal es generalmente un vector y la salida puede ser una categoría. Si aumenta la complejidad de la entrada, por ejemplo, se ingresan múltiples vectores, o la cantidad de vectores ingresados cada vez cambiará. Por ejemplo, en el procesamiento de textos, si cada palabra de una oración se considera como un vector, entonces una entrada tendrá múltiples vectores y, debido a que las longitudes de las oraciones de diferentes muestras son diferentes, el número de vectores ingresados cada vez también será diferente. cambió.
Entonces, ¿cuál será el resultado?
La primera posibilidad es que cada vector de entrada corresponda a una salida, y las longitudes de entrada y salida sean las mismas. Por ejemplo, ingrese una oración y deje que la máquina determine la parte gramatical de cada palabra en la oración, entonces la longitud de la entrada y la salida serán la misma.
El segundo caso es que solo es necesario generar una etiqueta. Por ejemplo, análisis de sentimiento de texto, ingrese una oración y deje que la máquina juzgue si la oración es positiva o negativa, etc.
La tercera situación es que no se sabe cuánta producción se requiere y la propia máquina determina la cantidad de producción. Por ejemplo, en la traducción automática, la entrada y la salida están en diferentes idiomas.
Este artículo presenta principalmente la solución a la primera situación, que también se llama Etiquetado de secuencia .
Etiquetado de secuencia
Si desea ingresar múltiples vectores y generar la misma cantidad de etiquetas, una solución es FC (una red neuronal completamente conectada), que ejecuta FC una vez para cada vector y luego genera la etiqueta correspondiente.
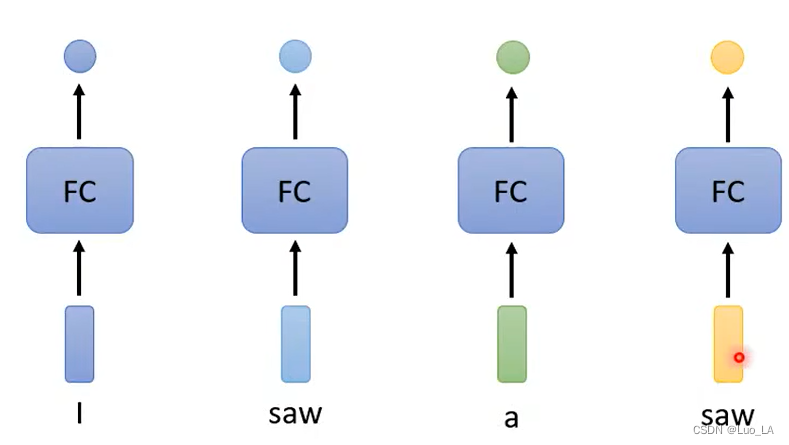
Pero hacerlo tiene grandes inconvenientes. Por ejemplo, en el ejemplo de determinación de parte del discurso, tomamos una oración como entrada, y una oración consta de varias palabras, cada palabra tiene su vector correspondiente (hay dos formas de generar vectores, codificación one-hot e incrustación de palabras ). Dejamos que cada palabra pase por FC una vez para obtener su parte gramatical correspondiente. Pero en el ejemplo anterior, las dos sierras en una oración tienen diferentes partes del discurso, pero no hay ninguna razón por la cual las salidas obtenidas a través de la misma red sean diferentes, porque los vectores de entrada son exactamente iguales.
Luego puedes considerar la información contextual de esta oración y tener en cuenta las palabras adyacentes de una palabra. Ingrese los vectores dentro de la ventana uno a la vez.
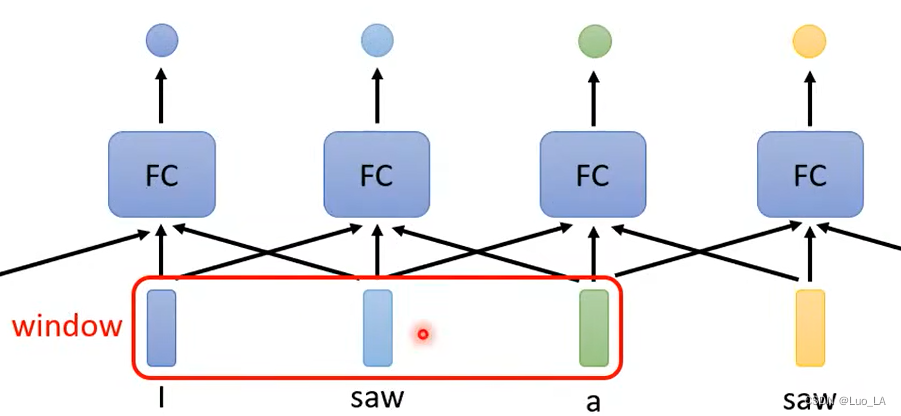
Sin embargo, este método todavía tiene desventajas: si tenemos una tarea, no se puede resolver considerando una ventana, sino considerando la oración completa. Entonces, ¿está bien configurar la ventana a la longitud de una oración? Evidentemente no, porque como decíamos al principio, la longitud de cada muestra de entrada es variable. Entonces, ¿está bien configurar la ventana con la longitud de la muestra más larga entre todas las entradas de muestra? Parece posible, pero hacerlo requerirá aprender demasiados parámetros, lo que puede provocar un sobreajuste. Entonces ¿cuál es la solución? Esto requiere el uso del mecanismo de autoatención presentado en este artículo .
Autoatención
¿Cómo se aplica la Autoatención? Primero, todos los vectores de la oración completa deben pasarse por la atención propia: se ingresan varios vectores y se emiten varios vectores. El vector de salida resultante tiene en cuenta toda la información contextual de la oración completa. Luego, se utiliza como entrada el vector que considera la información completa de la oración y se realiza FC para obtener la etiqueta de salida correspondiente.
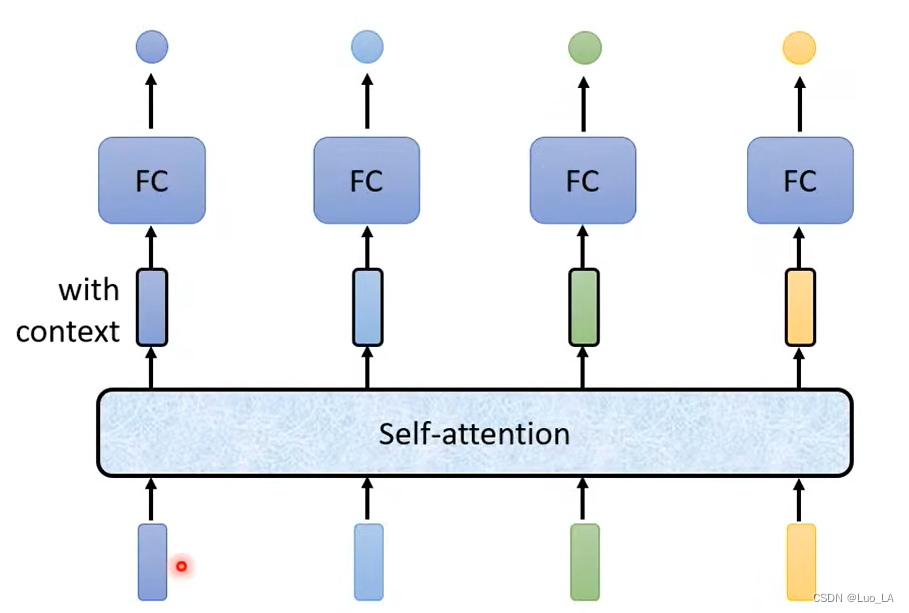
¿Cómo funciona la autoatención?
En primer lugar, la entrada de la autoatención son múltiples vectores, que pueden ser la entrada de una red neuronal completa o la salida de una capa oculta, por lo que aquí se usa aa .a para representar la entrada. El vector de salida esbbrepresentado por b , cadabbb toma todoaagenerado por un . A continuación presentamosbbCómo se genera b , con b 1 b^1b1 como ejemplo.
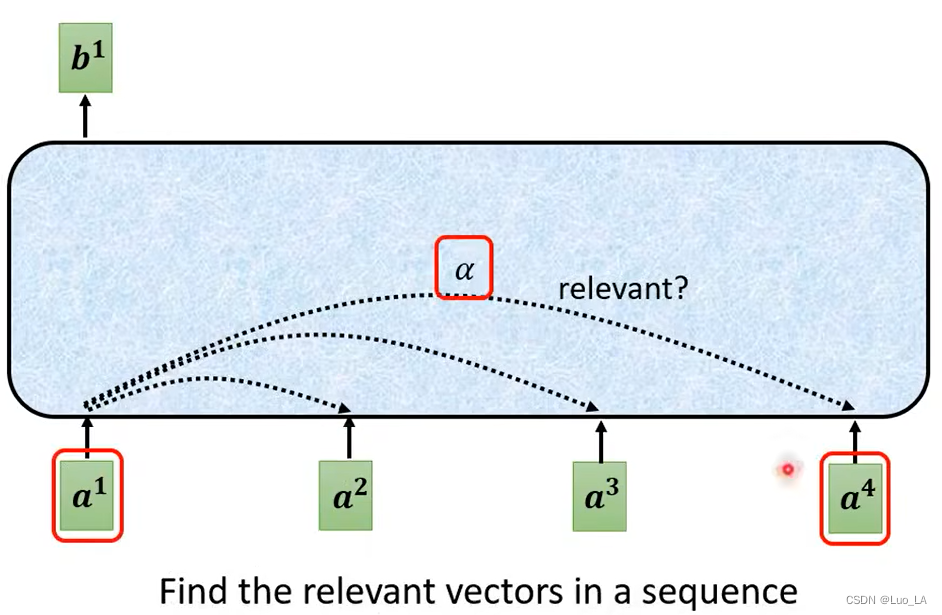
Primero tenemos que usarun 1 a^1a1Encuentra la oración completa que neutralizaa 1 a^1a1 otros vectores relacionados. Cada vector asociado sumaa 1 a^1aEl grado de correlación de 1 está representado por un valor numérico α \alphapara representar α .
Entonces, ¿cómo encontramos los otros vectores y a 1 a^1 ?a¿Cuál es la correlación entre 1 ? Usamos el método de cálculo del producto escalar para obtenerα \alphaα . Tome dos vectores como entrada, multiplíquelos por una matriz respectivamente y obtenga dos nuevas matricesq y kq y kq y k , entoncesq y kq y kHaga el producto interno de q y k y el valor obtenido esα \alphaα .
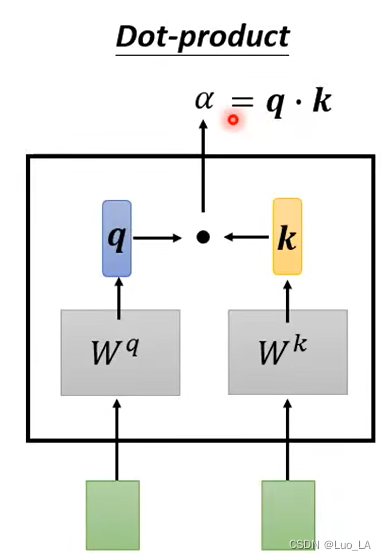
Así que ahora convertimos esto para obtenerα \alphaEl método alfa se aplica a nuestra autoatención. porun 1 un ^ 1a1 , necesitamos compararlo cona 2 a^2a2 un 3 un^3a3 un 4 un^4a4 Calcula la correlación. Primeroun 1 un^1a1 vecesW q W^qW.q obtieneq 1 q^1q1 vector,q 1 q^1q1 tiene un nombre llamado consulta. Siguienteun 2 un^2a2 un 3 un^3a3 un 4 un^4a4 debe multiplicarse porW k W^kW.k obtienekkvector k , kkk tiene un nombre llamado clave. q y kq y kHaz el producto interno de q y k para obteneralfa alfaa lp ha,alfa alfaun lp ha también se llamapuntuación de atención. α 1 , 2 {\alpha}_{1,2}a1 , 2significa un 1 a^1a1 sumaa 2 a^2apuntuación de atención entre 2 .
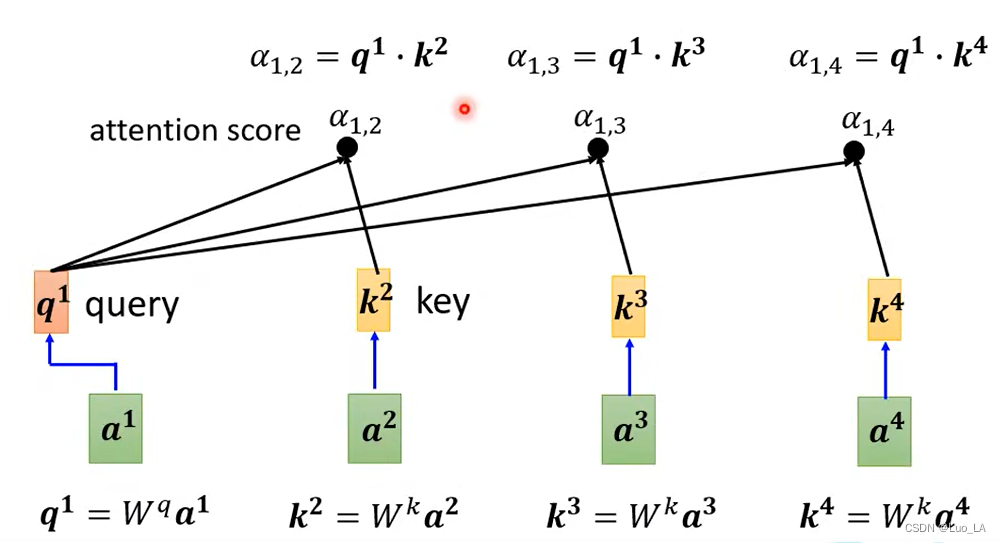
En la práctica,a 1 a^1a1 también necesita calcular la correlación consigo mismo y también calculara 1 a^1a1 vecesWk W^kW.k obtienek 1 k^1k1 y luego calcule su propia correlación.
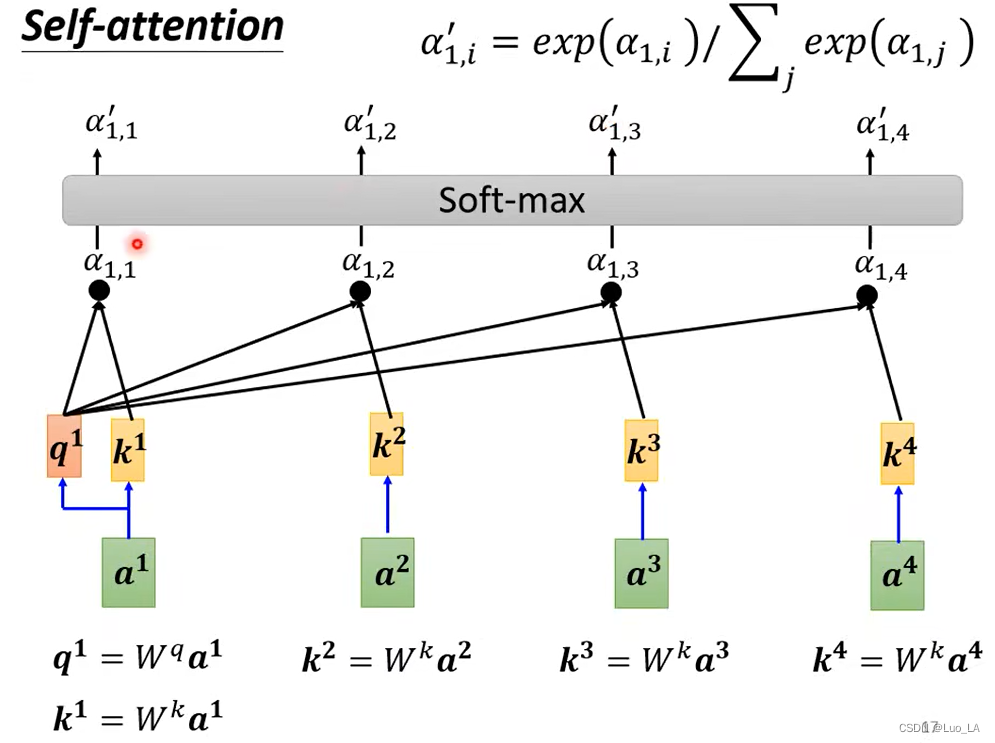
Calculara 1 a^1aDespués de la correlación entre 1 y todos los vectores, luego haga un soft-maxpara obtenerα ′ \alpha'a′。
Entonces usamos α ′ \alpha'a' Extrae la información importante de esta frase. Primero multiplicamos cada vector de entrada por una matrizW v W^vW.v obtiene el nuevo vectorvvv , y luego para cadavvv veces el correspondienteα ′ \alpha'a′ Sumados obtenemos el vectorb 1 b_1b1.
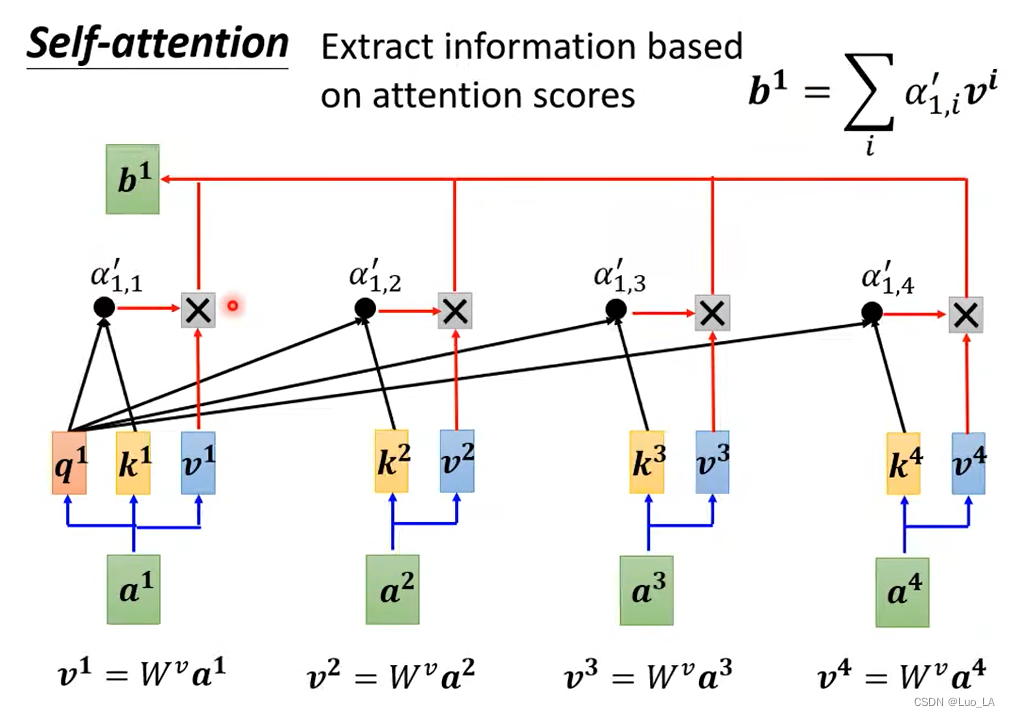
Según la introducción anterior, imaginaremos que si a 1 a^1a1 sumaa 2 a^2aLa correlación de 2 es relativamente fuerte, α 1 , 2 ′ {\alpha}_{1,2}^{'}a1 , 2′El valor obtenido es relativamente grande, entonces el valor final obtenido es b 1 b^1bEl valor de 1 puede estar más cerca de2 a^2a2 .
Multiplicación de matrices
Ahora echemos un vistazo a cómo funciona la autoatención desde la perspectiva de la multiplicación de matrices.
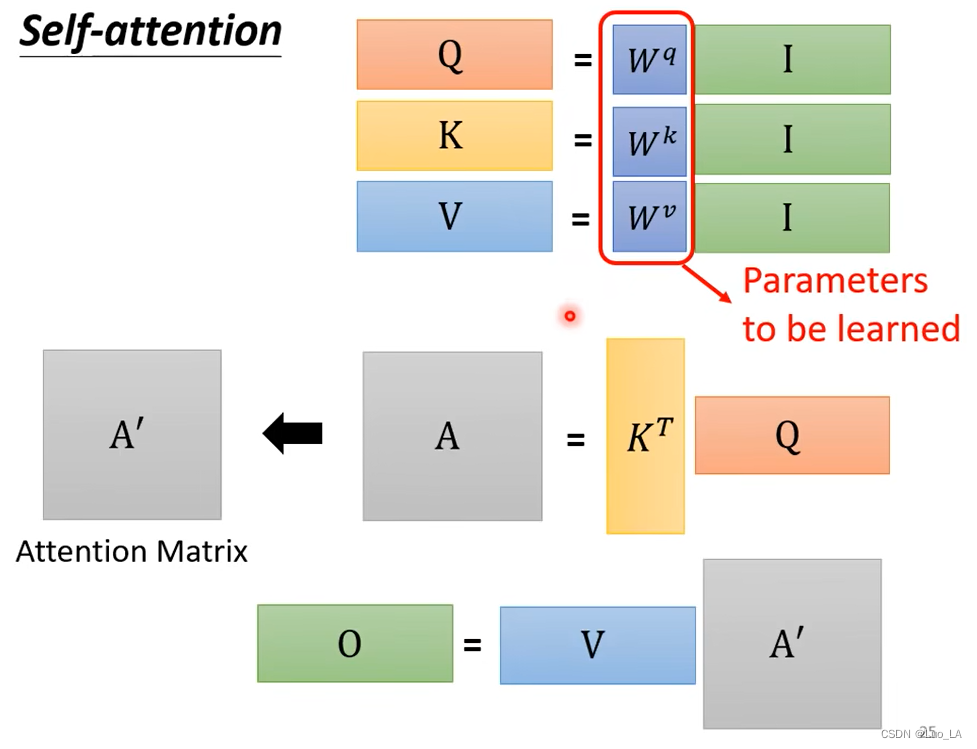
El primer paso es usar qq.Tome q como ejemplo, porque cadaaia^iai se multiplica por una matriz para obtener elqiq^iqi,qi = W qaiq^{i}=W^{q}a^iqi=W.q unyo . Yo soyaia^iai está concatenado y visto como una matrizIII , CuadradoIICada columna de I es cada entrada de autoatención, y luego paraIISalí multiplicado por la matrizW q W^qW.q , obtenga la matrizQQQ ,QQCada columna de Q es qiq^iqyo . De la misma manera podemos obtenerK, VK,V.k ,V._ _
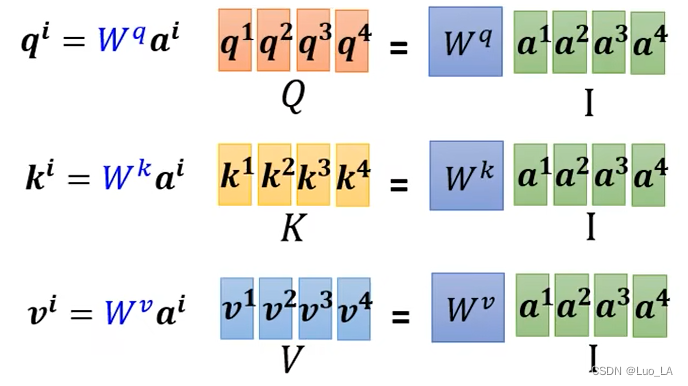
El segundo paso es calcular la puntuación de atención. Ponemoskik^ikEstoy concatenado para formar una matrizKTK^TkT , cadakik^iki se trata como una fila de esta matriz y luego se multiplica por la matrizq 1 q^1q1 , obtienes una matriz, cada fila de esta matriz esun 1 a^1a1 por cada puntuación de atención asociada a ella.
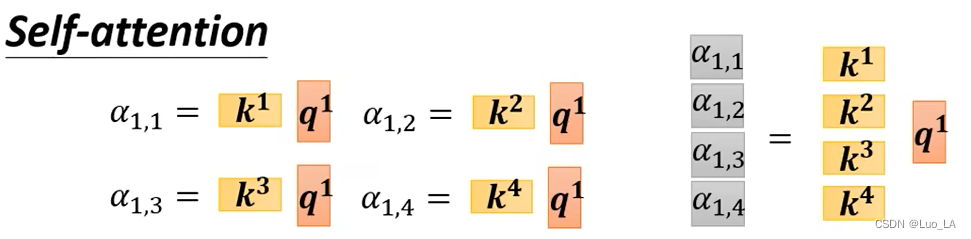
De la misma manera,a 2, a 3, a 4 a^2,a^3,a^4a2 ,a3 ,a4 también necesita calcular el puntaje de atención, ponemosqiq^iqi se trata como una columna de una matriz y se concatena en una matrizQQQ. QQ_Q dejada porKTK^TkT obtiene la puntuación de atención de todos los vectores de entrada, expresada como la matrizAAUn __Haga soft-max para cada columna de A.

En el tercer paso, calculamos la salida. Ponemosviv^ivEstoy empalmado para formar la matrizVV.V , luego multiplica por la matrizA ′ A'A′ , obtiene la matriz de salidaOOO._ _

En resumen, el mecanismo operativo de la autoatención es en realidad una serie de multiplicaciones de matrices. En esta serie de matrices, solo hay matricesW q , W k , W v W^{q}, W^{k}, W^{v}W.q ,W.k ,W.v es desconocido y es un parámetro que debe aprenderse mediante entrenamiento.
Autoatención de múltiples cabezales (mecanismo de atención de múltiples cabezales)
Tomando 2 cabezas como ejemplo, primero coloque el vector de entrada aaa multiplicado por una matriz daqqq , entoncesqqMultiplicar q por dos matrices diferentes da dosqqq , estos dosqqq se utiliza para representar dos correlaciones diferentes. qqHay dos qs , correspondientes ak y vk y vTambién hay dos k y v . Luego calcule respectivamentebi, 1, bi, 2 b^{i,1}, b^{i,2}byo , 1 ,segundoyo , 2 .
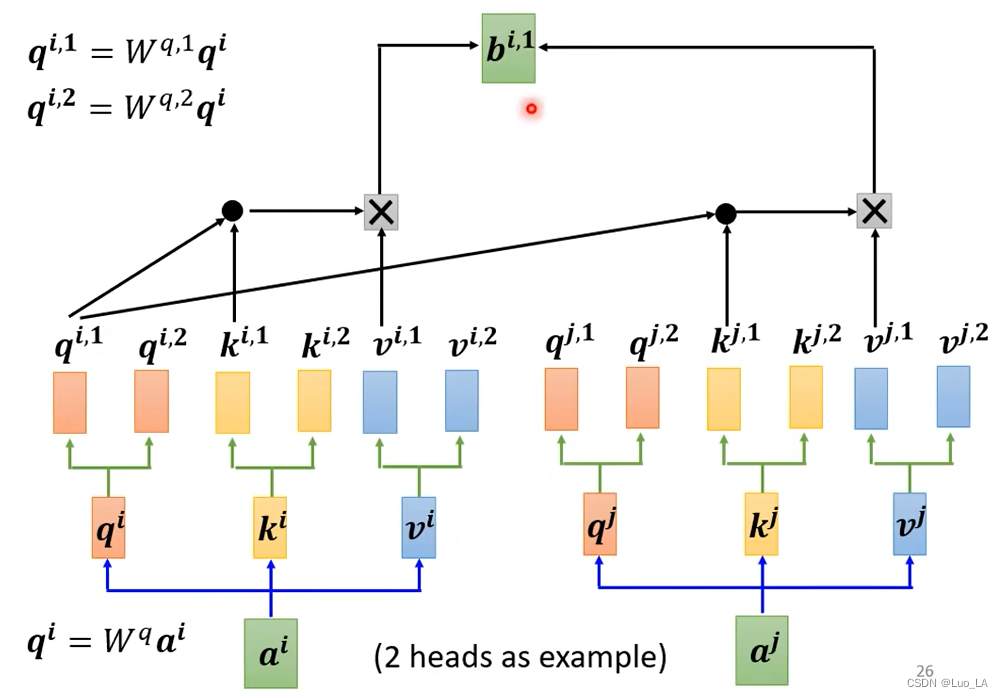
agarrarbi, 1, bi, 2 b^{i,1},b^{i,2}byo , 1 ,segundoi , 2 se concatenan y se multiplican por una matriz para obtenerbib^ibyo .
