Modelo de predicción GRU basado en la autoatención
Características: 1. Entrada de variable única y variable múltiple, conmutación libre
2. Pronóstico de un solo paso, pronóstico de varios pasos, cambio automático
3. Basado en la arquitectura Pytorch
4. Múltiples indicadores de evaluación (MAE, MSE, R2, MAPE, etc.)
5. Los datos se leen del archivo de Excel, fácil de reemplazar
6. Marco estándar, los datos se dividen en conjunto de entrenamiento, conjunto de verificación y conjunto de prueba
Todo el código completo, el código que está garantizado para ejecutar se puede ver aquí.
http://t.csdn.cn/obJlC ![]() http://t.csdn.cn/obJlC
http://t.csdn.cn/obJlC
! ! ! Si no se puede abrir el primer enlace, haga clic en la página de inicio personal para ver mi presentación personal.
(Después de buscar el producto, haga clic en el avatar para ver todos los códigos)
Blog de Black Technology Little Potato_CSDN Blog-Deep Learning, Blogger en 32 MCU Field

1. Introducción a los antecedentes del modelo GRU-selfAttention
El nombre completo de GRU es Gated Recurrent Units, que es una variante de la red neuronal recurrente. Cambia la estructura de las celdas de memoria y las puertas en LSTM, usa solo dos puertas (puerta de reinicio y puerta de actualización) y pasa directamente el estado actual a la salida.
El mecanismo de autoatención también es aplicable a la red GRU, que puede calcular de forma adaptativa el peso de cada paso de tiempo según la secuencia de entrada.
Por lo tanto, el modelo GRU-selfAttention utiliza la red GRU combinada con el mecanismo de autoatención para resolver mejor la compleja relación entre las dependencias a largo plazo y las dependencias locales en los datos de secuencia.
2. Resumen de las ventajas del modelo GRU-selfAttention
Las ventajas de este modelo son:
- En comparación con LSTM, la estructura GRU es más liviana y tiene una velocidad de cálculo más rápida, por lo que se puede entrenar y predecir más rápido;
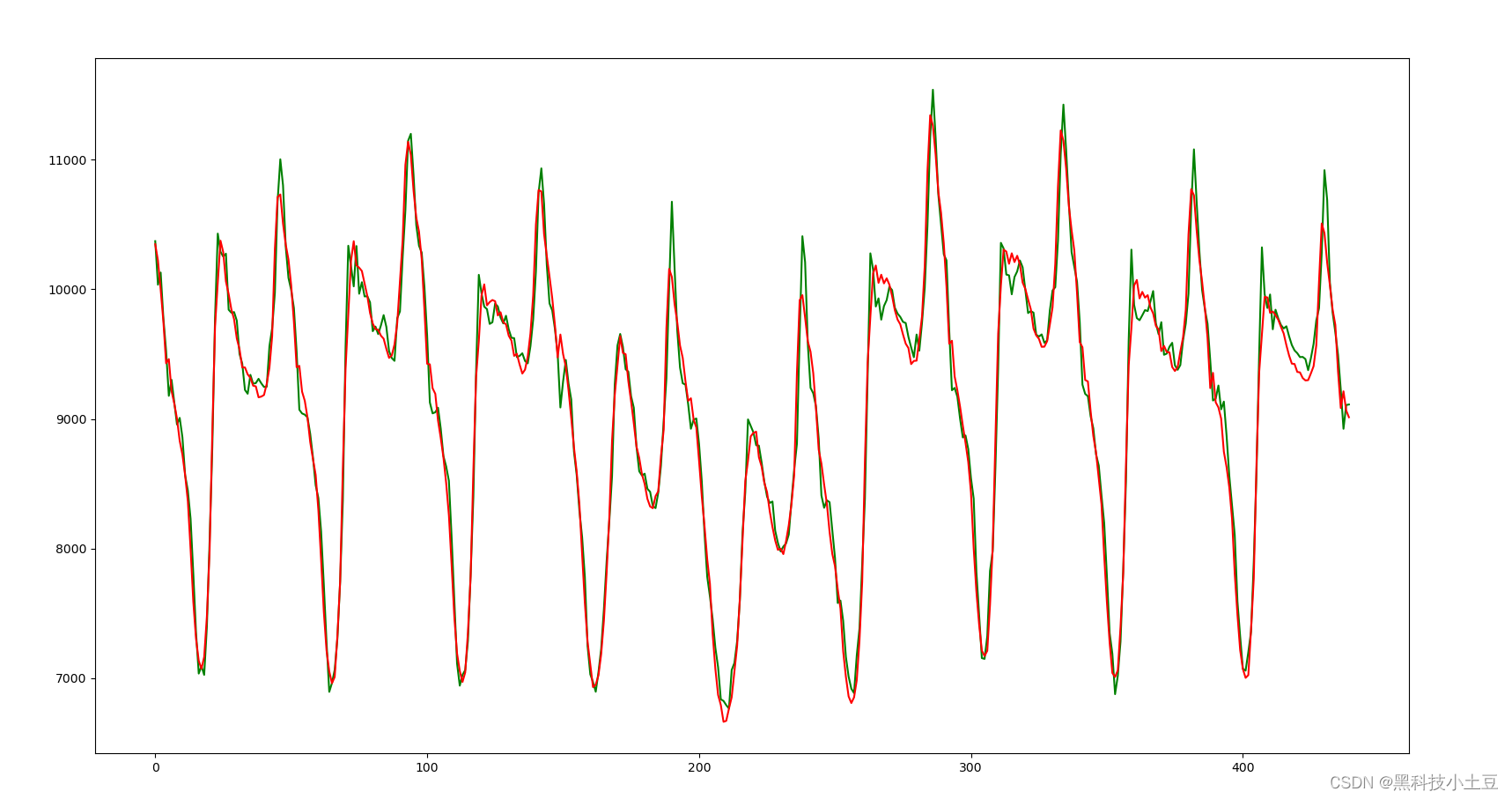
- El mecanismo de autoatención puede manejar mejor la relación entre los datos de secuencia, proporcionar información auxiliar diferente para cada paso de tiempo para la red GRU y ayudar a mejorar la precisión de la predicción.
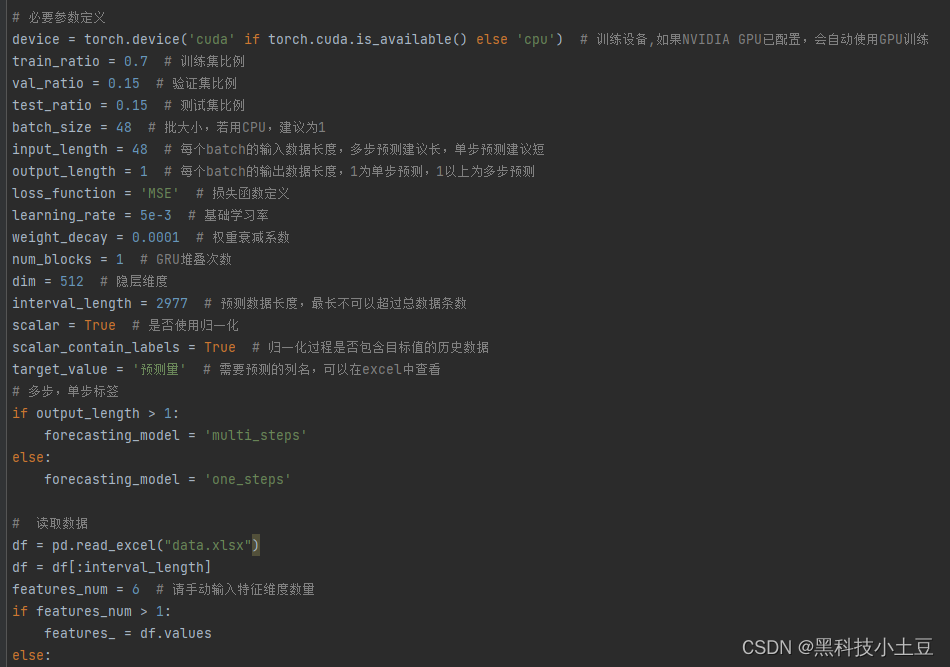
train_ratio = 0.7 # 训练集比例
val_ratio = 0.15 # 验证集比例
test_ratio = 0.15 # 测试集比例
input_length = 48 # 输入数据长度,多步预测建议长,单步预测建议短
output_length = 1 # 输出数据长度,1为单步预测,1以上为多步预测 请注意,随着输出长度的增长,模型训练时间呈指数级增长
learning_rate = 0.1 # 学习率
estimators = 100 # 迭代次数
max_depth = 5 # 树模型的最大深度
interval_length = 2000 # 预测数据长度,最长不可以超过总数据条数
scalar = True # 是否使用归一化
scalar_contain_labels = True # 归一化过程是否包含目标值的历史数据
target_value = 'load' # 需要预测的列名,可以在excel中查看