Este artículo es un documento de CVPR2022. Práctica internacional, primero publique el texto original y el código fuente:
Dirección del artículo original ![]() https://arxiv.org/pdf/2111.13673.pdf Dirección del código fuente
https://arxiv.org/pdf/2111.13673.pdf Dirección del código fuente ![]() https://github.com/SysCV/transfiner
https://github.com/SysCV/transfiner
I. Resumen
Aunque las redes tradicionales de dos etapas, como Mask R-CNN, han logrado buenos resultados en la segmentación de instancias, sus máscaras aún son relativamente toscas. Mask Transfiner descompone las regiones de la imagen en quadtrees , y la red solo procesa los nodos de árbol propensos a errores detectados y corrige automáticamente sus errores. Esto permite a Mask Transfiner predecir máscaras de instancias de alta precisión al menor costo computacional.

2. Conceptos relacionados
En la segmentación de instancias, la mayoría de los errores de clasificación de píxeles se pueden atribuir a la pérdida de resolución espacial causada por la reducción de resolución . Esto da como resultado una máscara de menor resolución en los bordes del objeto. Para solucionar este problema, en este trabajo se proponen dos conceptos: Regiones Incoherentes y Quadtree .
1. Área de pérdida de información
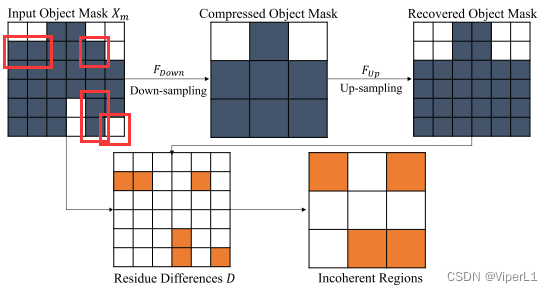
Para describir estas regiones, reducimos la resolución de la máscara para simular la pérdida de información causada por la reducción de resolución en la red. De la leyenda anterior, podemos ver que la máscara original se muestrea 2 veces menos y luego se muestrea más veces 2. La parte naranja (el cuadro rojo en la imagen original) es el punto de clasificación incorrecto. Después de los experimentos, la mayoría de los errores están en el área de pérdida de información.
Detección de áreas de pérdida de información : el módulo de detección liviano involucrado en este documento se muestra en la figura a continuación, que puede detectar efectivamente áreas de pérdida de información en pirámides de características de múltiples escalas.
Las características más pequeñas y las predicciones de máscara de objeto grueso pronosticadas se concatenan ( operación de concatenación ) como entrada.
① A través de una red totalmente convolucional (FCN, que consta de cuatro convoluciones de 3x3) y un clasificador binario para predecir la máscara de pérdida de información más aproximada .
② La máscara de baja resolución detectada se muestrea (usando convolución 1x1) y se fusiona con características de alta resolución en capas adyacentes .

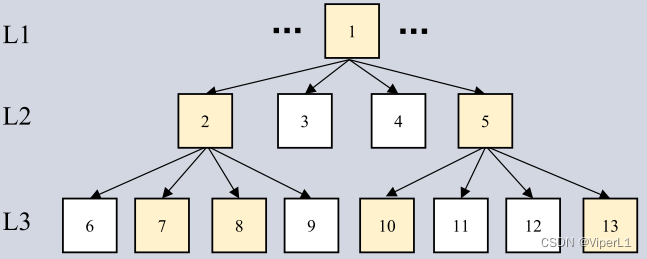
2. Árbol cuádruple
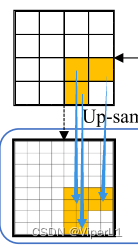
En este documento, los quadtrees se utilizan para refinar las regiones de pérdida de información en las imágenes. Concatena las máscaras de predicción en estos dos niveles diferentes de la pirámide de funciones. Como se muestra abajo. En función de los puntos de pérdida de información detectados, se puede construir un quadtree de varios niveles, con el mapa de características detectado de nivel más alto como nodo raíz, y estos nodos raíz se pueden asignar a cuatro cuadrantes subdivididos en el mapa de características de bajo nivel (estos los mapas tienen mayor resolución y detalle local).

3. Estructura de la red
La estructura de red de Mask Transfiner se muestra en la siguiente figura (la parte que pertenece al marco de red grande está marcada con un marco rojo):
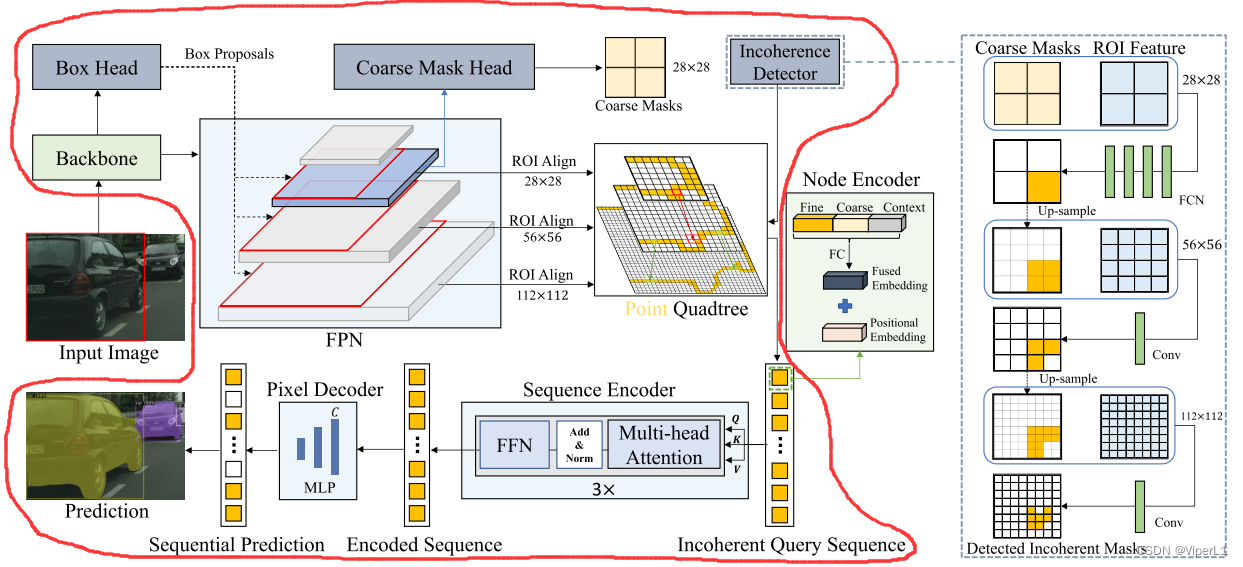
Esta red se basa en una FPN en capas (pirámide de funciones de redes piramidales de funciones). El objeto de Mask Transfiner no es una función FPN de un solo nivel, sino los puntos de funciones dispersos detectados en el área de pérdida de información en la pirámide de funciones de RoI como entrada. secuencia Y generar su etiqueta de segmentación correspondiente.
1. Pirámide de retorno de la inversión
Este documento utiliza mapas de características de las capas 2 a 5 en el mapa de características en capas extraído por la red troncal. Con base en la propuesta de instancia dada por el detector de objetos, las características de RoI son extraídas por FPN en los mapas de características de tres niveles diferentes { ,,
Donde, la fórmula de cálculo de la capa inicial i es: , donde
W y H son el ancho y la altura del RoI.
Las características de bajo nivel contienen más contexto e información semántica, mientras que las características de alto nivel contienen más características locales.
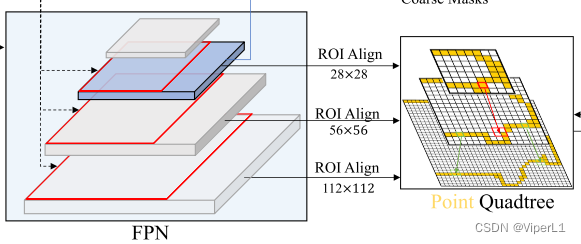
2. Secuencia de nodos de entrada
La secuencia consta de tres niveles diferentes de nodos de pérdida de información del quadtree. El tamaño de la secuencia es CxN, donde C es la dimensión del canal de funciones y N es el número total de nodos. La secuencia es comprimida por un codificador de nodo .
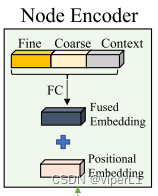
3. Codificador de nodos
El codificador de nodos utilizará la siguiente información para codificar cada nodo del quadtree.
①Características detalladas extraídas del nivel actual de FPN
②Información semántica proporcionada desde la región de predicción de máscara gruesa inicial
③Información de relación y distancia entre nodos (encapsulada por codificación de posición relativa en RoI)
④La información de contexto de cada nodo y su propia información
En este documento, las características se extraen en la vecindad de cada nodo y se comprimen utilizando una capa completamente conectada. Como se muestra en la figura a continuación, las características detalladas, las señales de segmentación gruesa y las características contextuales se fusionan primero a través de una capa completamente conectada y luego se le agregan incrustaciones de posición.
4. Codificador de secuencia y decodificador de píxeles
Cada codificador de secuencia tiene un módulo de atención de cabezales múltiples y una red neuronal de avance totalmente conectada.
El decodificador de píxeles es un pequeño MLP (perceptrón multicapa) de dos capas que decodifica la consulta de salida de cada nodo y predice la etiqueta de máscara final.
4. Función de pérdida
Basado en el quadtree, la función de pérdida utilizada en este documento es:
Entre ellas, representa la función de pérdida L1 entre el punto de pérdida de información previsto y la etiqueta real; es
la función de pérdida de entropía cruzada para detectar el área de pérdida de información;
incluye la pérdida de posicionamiento y clasificación del detector;
representa la pérdida de la predicción inicial de segmentación aproximada.