Clasificación de enfermedades de la piel basada en métodos detallados débilmente supervisados
Título del artículo
Mire más de cerca para ver mejor: red neuronal convolucional de atención recurrente para el reconocimiento de imágenes detallado
Fuente del artículo
CVPR2019
motivación del autor
La localización de regiones y el aprendizaje de características detalladas son dos desafíos importantes en los problemas detallados. Los métodos existentes (antes de 19 años) se centran principalmente en resolver estos dos problemas de forma independiente, pero ignoran la correlación entre los dos, por lo que se propone una nueva arquitectura: RA-CNN.
ideas del autor
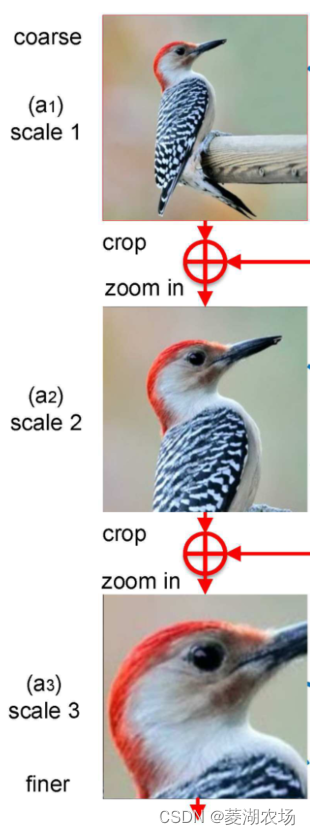
Una imagen de entrada se recorta a través de la Red de propuesta de atención (APN) y luego se amplía mediante interpolación bilineal. El efecto equivale a descartar otra información en la imagen y ampliar lo que "yo" quiero ver. El efecto es el siguiente:
Red de arquitectura
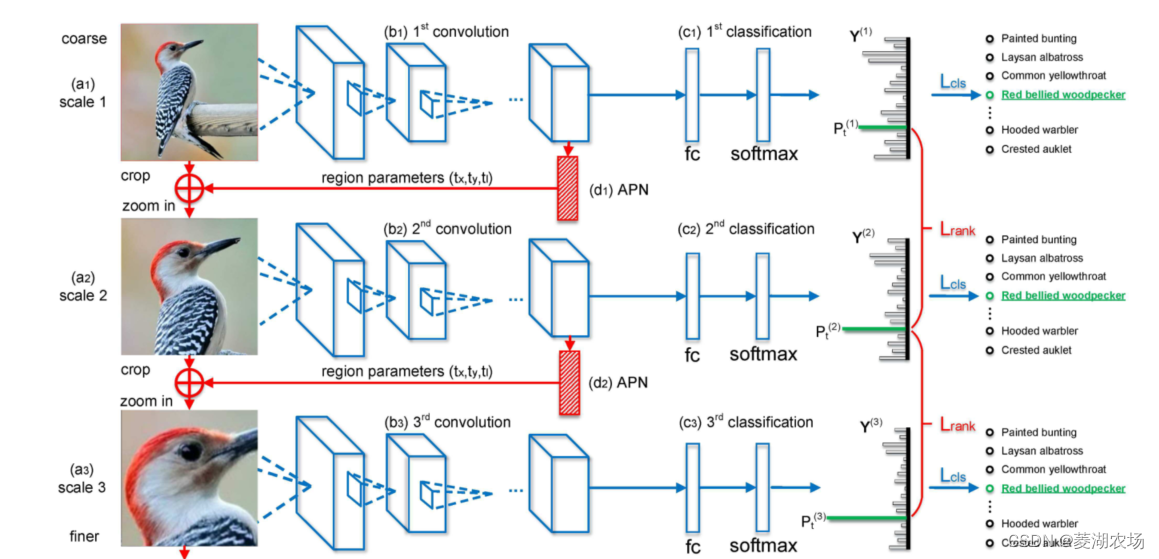
Explicación aproximada:
ingrese una imagen original. Hay dos tareas para la imagen original. Una es clasificar la imagen original mediante convolución-totalmente conectada-softmax como la clasificación de imágenes convencional y obtener las probabilidades de una serie de categorías; la segunda es obtener las probabilidades de una serie de categorías después de la convolución Una serie de mapas de características obtenidos después de la producción se pasan a través de la Red de propuesta de atención (APN) para obtener los resultados de la atención. Como se muestra en la imagen de arriba, nuestra atención está en la cabeza del pájaro, por lo que recortamos otras partes, dejando solo la cabeza del pájaro, y luego ampliamos la cabeza del pájaro mediante agrupación bilineal. Haciendo eco del título del artículo: cuanto más cerca ves, mejor ves
Explicación detallada:
para una imagen A, después de la extracción de características (operación de convolución) - conexión completa - softmax, se obtiene la probabilidad P de diferentes categorías, como se muestra a continuación: La pérdida

L (X) 1 es:
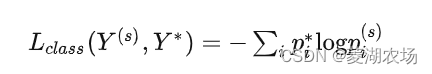
Al mismo tiempo, después de la característica extracción Se obtiene una serie de mapas de características y, a través del módulo de propuesta de atención
(APN), se obtiene un bloque de atención cuadrado, registrado como:

tx representa la coordenada x del centro de atención, ty representa la coordenada y del centro de atención, y tl representa el bloque de atención, la mitad de la longitud del lado. Esto es lo que debemos dejar en la imagen original.