1. Introducción

2. Modelo
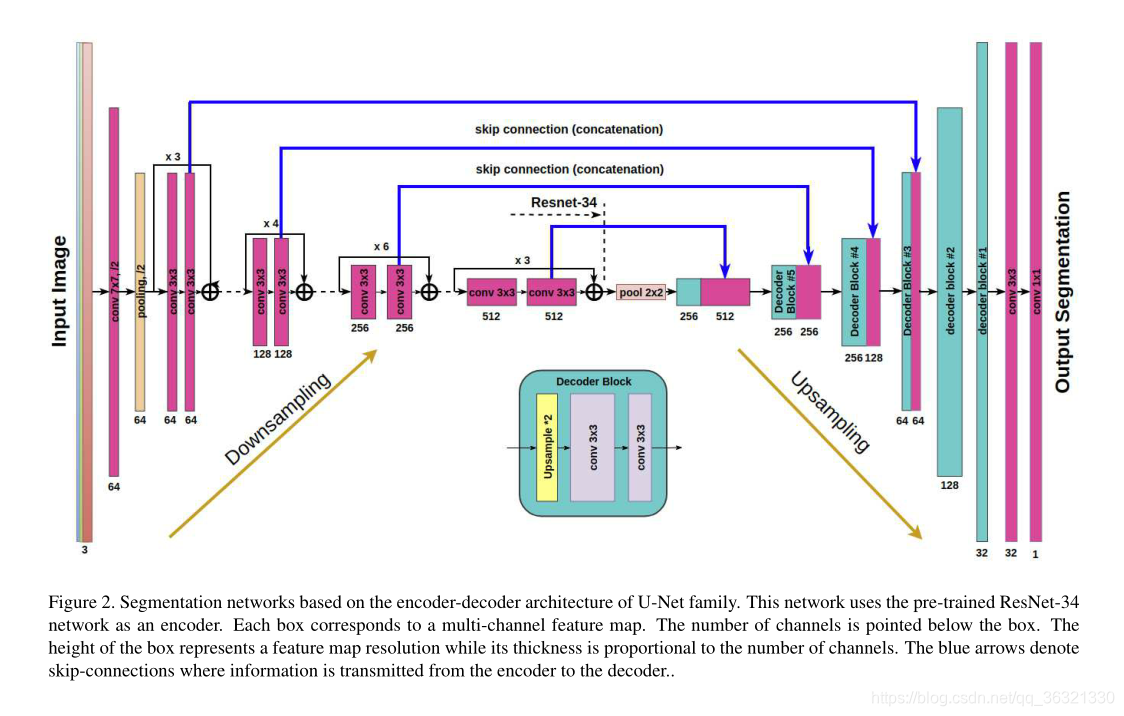
Hemos mejorado la red U-Net original, utilizando una red similar y un codificador similar, utilizando la red ResNet-34 previamente entrenada como codificador. El tamaño del núcleo de convolución es 7x7, zancada = 2. En cada bloque residual, el primer paso de convolución es 2, y los pasos restantes de la operación de convolución son todos 1.
3. Entrenamiento
Utilizando el índice de Jaccard (IOU) como una evaluación índice
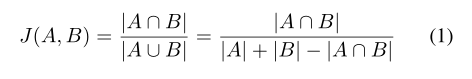
fórmula dispersión son :( pixel binario i y la probabilidad predicha)
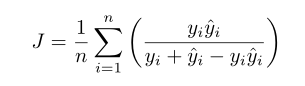
función de pérdida (H: BCE):
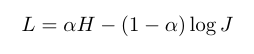
Minimizar L, corresponde al mínimo de H, J y maximizando
probado, α = 0.7
Usando el optimizador Adam, el valor de predicción del IOU cambia significativamente entre iteraciones. Se usa Dropout (0.3) y TTA (aumento del tiempo de prueba), que gira la imagen 90 grados para obtener cuatro imágenes. La predicción se promedia. .
Referencias
[1] http://deepglobe.org/.
[2] http://ods.ai/.
[3] I. Demir, K. Koperski, D. Lindenbaum, G. Pang, J. Huang, S. Basu, F. Hughes, D. Tuia y R. Raskar. Deepglobe 2018: un desafío para analizar la tierra a través de imágenes de satélite. preimpresión de arXiv arXiv: 1805.06561, 2018.
[4] M. Everingham, SA Eslami, L. V an Gool, CK Williams, J. Winn y A. Zisserman. El desafío de las clases de objetos visuales pascales: una retrospectiva. Revista internacional de visión informática, 111 (1): 98–136, 2015.
[5] K. He, X. Zhang, S. Ren y J. Sun. Aprendizaje residual profundo para el reconocimiento de imágenes. En Actas de la conferencia IEEE sobre visión por computadora y reconocimiento de patrones, páginas
770–778, 2016.
[6] V. Iglovikov, S. Mushinskiy y V. Osin Detección de características de imágenes satelitales utilizando una red neuronal convolucional profunda: una competencia de kaggle. preimpresión de arXiv arXiv: 1706.06169, 2017.
[7] V. Iglovikov y A. Shvets. Ternausnet: U-net con codificador vgg11 pre-entrenado en imagenet para la segmentación de imágenes. ArXiv preprint arXiv: 1801.05746, 2018.
[8] D. P. Kingma y J. Ba. Adam: un método para la optimización estocástica. preimpresión de arXiv arXiv: 1412.6980, 2014.
[9] J. Long, E. Shelhamer y T. Darrell. Redes totalmente convolucionales para la segmentación semántica. En Actas de la conferencia IEEE sobre visión por computadora y reconocimiento de patrones, páginas 3431–3440, 2015.
[10] O. Ronneberger, P. Fischer y T. Brox. U-net: redes convolucionales para la segmentación de imágenes biomédicas. En la Conferencia internacional sobre computación de imágenes médicas e intervención asistida por computadora, páginas 234–241, 2015.
[11] W. Wang, N. Y ang, Y. Zhang, F. Wang, T. Cao y P. Eklund. Una revisión de la extracción de carreteras a partir de imágenes de teledetección. Journal of Traffic and Transportation Engineering (Edición en inglés), 3 (3): 271–282, 2016.
[12] Z. Zhang, Q. Liu e Y. Wang Extracción de carreteras por red u profunda residual. IEEE Geoscience and Remote Sensing Letters, 2018.
[13] Z. Zhong, J. Li, W. Cui y H. Jiang. Redes totalmente convolucionales para la construcción y extracción de carreteras: resultados preliminares. En Geoscience and Remote Sensing Symposium (IGARSS), 2016 IEEE International, páginas 1591–1594.IEEE, 2016.
