
1. Descripción
La idea es que obtengamos los pesos de la última capa densa y luego los multipliquemos por la capa final de CNN. Esto requiere que funcione Global Average Pooling (GAP).
2. Seleccionar modelo
En este tutorial, utilizamos Keras con Tensorflow y ResNet50.
Debido a que ResNet50 tiene una capa de agrupación promedio global (GAP) (que se explica más adelante), es adecuado para nuestra demostración. Esto es perfecto.

3. Cómo funcionan los mapas de calor
Mapa de calor de CNN, también conocido como Mapa de activación de clases ( CAM ). La idea es que recopilemos cada salida de la capa convolucional (como una imagen) y la combinemos en una sola toma. (Más adelante mostraremos el código paso a paso)

Entonces, así es como funciona Global Average Pooling (GAP) o Global Max Pooling (dependiendo de cuál uses, pero son la misma idea).
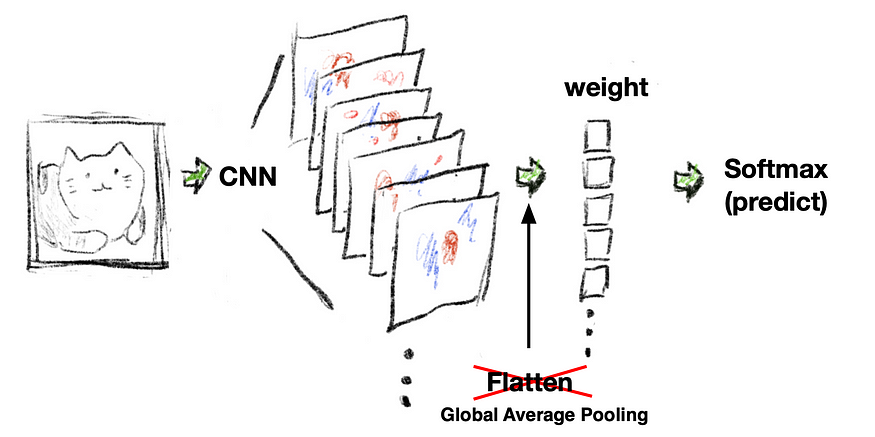
En algunos modelos de extracción posterior a funciones, utilizamos capas aplanadas (completamente conectadas) con redes neuronales para predecir resultados. Pero este paso es como descartar las dimensiones de la imagen y cierta información.
Por el contrario, aquí funciona el uso de Global Average Pooling (GAP) o Global Max Pooling (GMP). Conserva la información de las dimensiones de la imagen y permite que la red neuronal decida qué canal CNN (imagen característica) es más crítico para el resultado de la predicción.
4. Ejemplos y código
Comencemos con ResNet50 en Keras.
from tensorflow.keras.applications import ResNet50
res_model = ResNet50()
res_model.summary() 
Como puedes ver (arriba):
- Rojo: Usaremos esta capa como "Inclinación de transferencia".
- Verde: Pooling Promedio Global (GAP). Este trabajo es crítico.
e importar bibliotecas e imágenes para su uso posterior.
import cv2
import matplotlib.pyplot as plt
from scipy.ndimage import zoom
from tensorflow.keras.applications.resnet50 import preprocess_input, decode_predictions
img = cv2.imread('./test_cat.png')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
X = np.expand_dims(img, axis=0).astype(np.float32)
X = preprocess_input(X)Usamos "desde scipy.ndimage import zoom ". Para cambiar el tamaño del mapa de calor gracias a CNN, la forma de la imagen extraída de la característica es más pequeña que la imagen original.
4.1 Transferir el aprendizaje
Ahora extrae la capa que usaremos.
PD: Puedes entrenar tu modelo desde cero, pero llevará mucho tiempo y la extracción de funciones también puede requerir muchos ajustes.
from tensorflow.keras.models import Model
conv_output = res_model.get_layer("conv5_block3_out").output
pred_ouptut = res_model.get_layer("predictions").output
model = Model(res_model.input, outputs=[conv_ouptut, pred_layer])Aquí tenemos dos salidas (como se mencionó, roja en el diagrama).
- La primera es la salida de la red convolucional.
- El segundo es el resultado de la predicción.
y hacer predicciones
conv, pred = model.predict(X)
decode_predictions(pred)Los resultados se muestran a continuación. nada mal
[[('n02123159', 'tiger_cat', 0.7185241),
('n02123045', 'tabby', 0.1784818),
('n02124075', 'Egyptian_cat', 0.034279127),
('n03958227', 'plastic_bag', 0.006443105),
('n03793489', 'mouse', 0.004671723)]]4.2 Salida
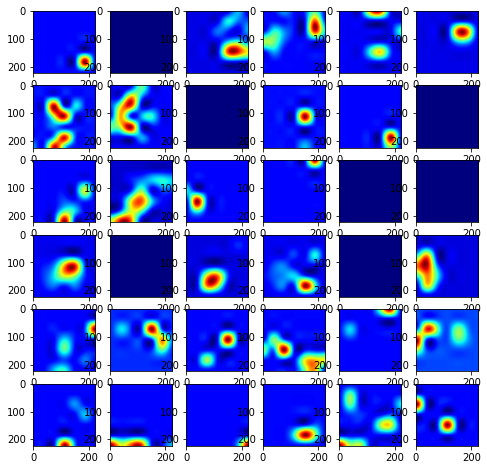
Ahora, veamos algunos resultados de CNN.
scale = 224 / 7
plt.figure(figsize=(16, 16))
for i in range(36):
plt.subplot(6, 6, i + 1)
plt.imshow(img)
plt.imshow(zoom(conv[0, :,:,i], zoom=(scale, scale)), cmap='jet', alpha=0.3)
salida de CNN
Primero mostramos la imagen del suelo ( plt.imshow(img) ) para poder compararla con la imagen del suelo.
(Si no haces esto, obtendrás el resultado como este)
4.3 Combinación única de salidas
Esto es fundamental. Utilizamos el índice de resultado previsto (objetivo) para obtener las ponderaciones. y multiplique cada mapa de características con peso (producto escalar)
target = np.argmax(pred, axis=1).squeeze()
w, b = model.get_layer("predictions").weights
weights = w[:, target].numpy()
heatmap = conv.squeeze() @ weightsA continuación se muestra el mapa de calor con la imagen del terreno.
scale = 224 / 7
plt.figure(figsize=(12, 12))
plt.imshow(img)
plt.imshow(zoom(heatmap, zoom=(scale, scale)), cmap='jet', alpha=0.5)
Este es el resultado que queremos.
5. Recursos de referencia
- Aprendizaje residual profundo para el reconocimiento de imágenes: https://arxiv.org/abs/1512.03385
- Grad-CAM: interpretación visual de redes profundas mediante localización basada en gradientes: https://arxiv.org/abs/1610.02391
- Red dentro de la red: https://arxiv.org/abs/1312.4400
- Aprendizaje de funciones profundas para una localización discriminativa: https://arxiv.org/abs/1512.04150