Directorio de artículos
prefacio
SqueezeNet es un modelo CNN liviano y eficiente con 50 veces menos parámetros que AlexNet, pero el rendimiento del modelo (precisión) es cercano al de AlexNet. Como sugiere el nombre, Squeeze significa compresión y extrusión en chino, por lo que podemos adivinar por el nombre del algoritmo que el algoritmo debe reducir la cantidad de parámetros del modelo comprimiéndolo. Por supuesto, la mejora de cualquier algoritmo es mejorar la precisión o reducir los parámetros del modelo sobre la base original, por lo que el objetivo principal del algoritmo es reducir la cantidad de parámetros del modelo mientras se mantiene la precisión del modelo.
Mi entorno:
- Entorno básico: python3.7
- Compilador: pycharm
- Marco de aprendizaje profundo: pytorch
- Adquisición del código del conjunto de datos: enlace (código de extracción: 2357)
1. Preparación de datos
El conjunto de datos utilizado en este caso es el conjunto de datos de reconocimiento de enfermedades oculares iChallenge-PM.
1.1 Introducción al conjunto de datos
iChallenge-PMEs un conjunto de datos médicos sobre la miopía patológica (Pathologic Myopia, PM) proporcionado en la competencia iChallenge organizada conjuntamente por Baidu Brain y el Centro de Oftalmología Zhongshan de la Universidad Sun Yat-sen, que incluye imágenes del fondo de ojo de la retina de 1200 sujetos, capacitación, verificación y pruebas. Hay 400 conjuntos de datos cada uno.
- Training.zip: contiene imágenes y etiquetas de entrenamiento.
- validation.zip: contiene imágenes del conjunto de validación
- valid_gt.zip: contiene etiquetas para el conjunto de validación
El conjunto de datos se descarga de la plataforma AI Studio, la información específica es la siguiente:

1.2 Estructura de archivos del conjunto de datos
Hay tres archivos comprimidos en el conjunto de datos, a saber:
- entrenamiento.zip
├── PALM-Training400
│ ├── PALM-Training400.zip
│ │ ├── H0002.jpg
│ │ └── ...
│ ├── PALM-Training400-Annotation-D&F.zip
│ │ └── ...
│ └── PALM-Training400-Annotation-Lession.zip
└── ...
- valid_gt.zip: PM_Lable_and_Fovea_Location.xlsx en la ubicación marcada es el archivo marcado
├── PALM-Validation-GT
│ ├── Lession_Masks
│ │ └── ...
│ ├── Disc_Masks
│ │ └── ...
│ └── PM_Lable_and_Fovea_Location.xlsx
- validation.zip: conjunto de datos de prueba
├── PALM-Validation
│ ├── V0001.jpg
│ ├── V0002.jpg
│ └── ...
2. Proyecto de combate real.
La estructura del proyecto es la siguiente:
2.1 División de etiquetas de datos
El formato del conjunto de datos de enfermedades oculares es un poco complicado. Aquí procesé el conjunto de datos yo mismo y escribí el conjunto de entrenamiento y el conjunto de verificación en el texto txt, correspondientes a su ruta de imagen y etiqueta respectivamente.
import os
import pandas as pd
# 将训练集划分标签
train_dataset = r"F:\SqueezeNet\data\PALM-Training400\PALM-Training400"
train_list = []
label_list = []
train_filenames = os.listdir(train_dataset)
for name in train_filenames:
filepath = os.path.join(train_dataset, name)
train_list.append(filepath)
if name[0] == 'N' or name[0] == 'H':
label = 0
label_list.append(label)
elif name[0] == 'P':
label = 1
label_list.append(label)
else:
raise('Error dataset!')
with open('F:/SqueezeNet/train.txt', 'w', encoding='UTF-8') as f:
i = 0
for train_img in train_list:
f.write(str(train_img) + ' ' +str(label_list[i]))
i += 1
f.write('\n')
# 将验证集划分标签
valid_dataset = r"F:\SqueezeNet\data\PALM-Validation400"
valid_filenames = os.listdir(valid_dataset)
valid_label = r"F:\SqueezeNet\data\PALM-Validation-GT\PM_Label_and_Fovea_Location.xlsx"
data = pd.read_excel(valid_label)
valid_data = data[['imgName', 'Label']].values.tolist()
with open('F:/SqueezeNet/valid.txt', 'w', encoding='UTF-8') as f:
for valid_img in valid_data:
f.write(str(valid_dataset) + '/' + valid_img[0] + ' ' + str(valid_img[1]))
f.write('\n')
2.2 Preprocesamiento de datos
El preprocesamiento de datos utilizado aquí incluye principalmente cambio de tamaño de imagen, volteo aleatorio, normalización, etc.
import os.path
from PIL import Image
from torch.utils.data import DataLoader, Dataset
from torchvision.transforms import transforms
transform_BZ = transforms.Normalize(
mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5]
)
class LoadData(Dataset):
def __init__(self, txt_path, train_flag=True):
self.imgs_info = self.get_images(txt_path)
self.train_flag = train_flag
self.train_tf = transforms.Compose([
transforms.Resize(224), # 调整图像大小为224x224
transforms.RandomHorizontalFlip(), # 随机左右翻转图像
transforms.RandomVerticalFlip(), # 随机上下翻转图像
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transform_BZ # 执行某些复杂变换操作
])
self.val_tf = transforms.Compose([
transforms.Resize(224), # 调整图像大小为224x224
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transform_BZ # 执行某些复杂变换操作
])
def get_images(self, txt_path):
with open(txt_path, 'r', encoding='utf-8') as f:
imgs_info = f.readlines()
imgs_info = list(map(lambda x: x.strip().split(' '), imgs_info))
return imgs_info
def padding_black(self, img):
w, h = img.size
scale = 224. / max(w, h)
img_fg = img.resize([int(x) for x in [w * scale, h * scale]])
size_fg = img_fg.size
size_bg = 224
img_bg = Image.new("RGB", (size_bg, size_bg))
img_bg.paste(img_fg, ((size_bg - size_fg[0]) // 2,
(size_bg - size_fg[1]) // 2))
img = img_bg
return img
def __getitem__(self, index):
img_path, label = self.imgs_info[index]
img_path = os.path.join('', img_path)
img = Image.open(img_path)
img = img.convert("RGB")
img = self.padding_black(img)
if self.train_flag:
img = self.train_tf(img)
else:
img = self.val_tf(img)
label = int(label)
return img, label
def __len__(self):
return len(self.imgs_info)
2.3 Construir el modelo
import torch
import torch.nn as nn
import torch.nn.init as init
class Fire(nn.Module):
def __init__(self, inplanes, squeeze_planes,
expand1x1_planes, expand3x3_planes):
super(Fire, self).__init__()
self.inplanes = inplanes
self.squeeze = nn.Conv2d(inplanes, squeeze_planes, kernel_size=1)
self.squeeze_activation = nn.ReLU(inplace=True)
self.expand1x1 = nn.Conv2d(squeeze_planes, expand1x1_planes,
kernel_size=1)
self.expand1x1_activation = nn.ReLU(inplace=True)
self.expand3x3 = nn.Conv2d(squeeze_planes, expand3x3_planes,
kernel_size=3, padding=1)
self.expand3x3_activation = nn.ReLU(inplace=True)
def forward(self, x):
x = self.squeeze_activation(self.squeeze(x))
return torch.cat([
self.expand1x1_activation(self.expand1x1(x)),
self.expand3x3_activation(self.expand3x3(x))
], 1)
class SqueezeNet(nn.Module):
def __init__(self, version='1_0', num_classes=1000):
super(SqueezeNet, self).__init__()
self.num_classes = num_classes
if version == '1_0':
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=7, stride=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(96, 16, 64, 64),
Fire(128, 16, 64, 64),
Fire(128, 32, 128, 128),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 32, 128, 128),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(512, 64, 256, 256),
)
elif version == '1_1':
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(64, 16, 64, 64),
Fire(128, 16, 64, 64),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(128, 32, 128, 128),
Fire(256, 32, 128, 128),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
Fire(512, 64, 256, 256),
)
else:
# FIXME: Is this needed? SqueezeNet should only be called from the
# FIXME: squeezenet1_x() functions
# FIXME: This checking is not done for the other models
raise ValueError("Unsupported SqueezeNet version {version}:"
"1_0 or 1_1 expected".format(version=version))
# Final convolution is initialized differently from the rest
final_conv = nn.Conv2d(512, self.num_classes, kernel_size=1)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
final_conv,
nn.ReLU(inplace=True),
nn.AdaptiveAvgPool2d((1, 1))
)
for m in self.modules():
if isinstance(m, nn.Conv2d):
if m is final_conv:
init.normal_(m.weight, mean=0.0, std=0.01)
else:
init.kaiming_uniform_(m.weight)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return torch.flatten(x, 1)
2.4 Iniciar entrenamiento
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset
from model import SqueezeNet
import torchsummary
from dataloader import LoadData
import copy
device = "cuda:0" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = SqueezeNet(num_classes=2).to(device)
# print(model)
#print(torchsummary.summary(model, (3, 224, 224), 1))
# 加载训练集和验证集
train_data = LoadData(r"F:\SqueezeNet\train.txt", True)
train_dl = torch.utils.data.DataLoader(train_data, batch_size=16, pin_memory=True,
shuffle=True, num_workers=0)
test_data = LoadData(r"F:\SqueezeNet\valid.txt", True)
test_dl = torch.utils.data.DataLoader(test_data, batch_size=16, pin_memory=True,
shuffle=True, num_workers=0)
# 编写训练函数
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
print('num_batches:', num_batches)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
# 编写验证函数
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
# 开始训练
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0 # 设置一个最佳准确率,作为最佳模型的判别指标
loss_function = nn.CrossEntropyLoss() # 定义损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 定义Adam优化器
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_function, optimizer)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_function)
# 保存最佳模型到 best_model
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 获取当前的学习率
lr = optimizer.state_dict()['param_groups'][0]['lr']
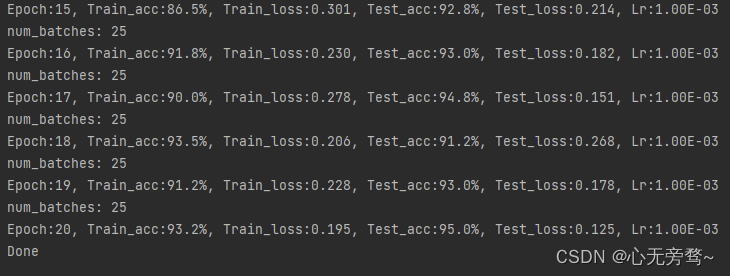
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss,
epoch_test_acc * 100, epoch_test_loss, lr))
# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(best_model.state_dict(), PATH)
print('Done')
2.5 Visualización de resultados
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Test Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Test Loss')
plt.show()
Los resultados de la visualización son los siguientes:
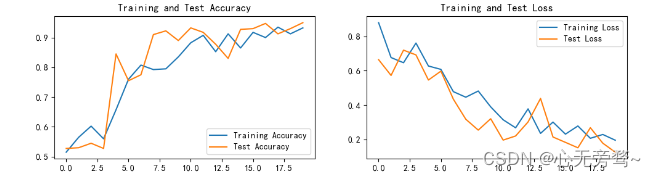
puede ajustar la tasa de aprendizaje y el tamaño del lote usted mismo, y mis hiperparámetros no se ajustan aquí.
3. Predicción individual del conjunto de datos
import matplotlib.pyplot as plt
from PIL import Image
from torchvision.transforms import transforms
from model import SqueezeNet
import torch
data_transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Resize((224, 224)),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
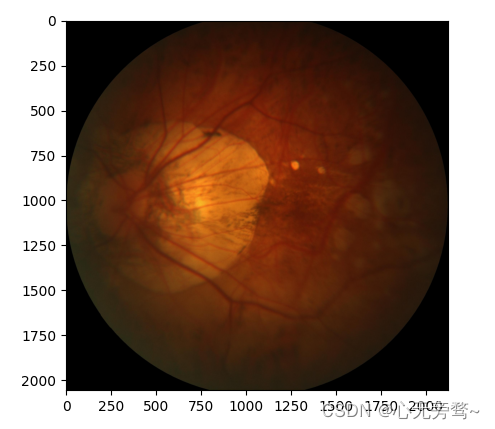
img = Image.open("F:\SqueezeNet\data\PALM-Validation400\V0008.jpg")
plt.imshow(img)
img = data_transform(img)
img = torch.unsqueeze(img, dim=0)
name = ['非病理性近视', '病理性近视']
model_weight_path = r"F:\SqueezeNet\best_model.pth"
model = SqueezeNet(num_classes=2)
model.load_state_dict(torch.load(model_weight_path))
model.eval()
with torch.no_grad():
output = torch.squeeze(model(img))
predict = torch.softmax(output, dim=0)
# 获得最大可能性索引
predict_cla = torch.argmax(predict).numpy()
print('索引为', predict_cla)
print('预测结果为:{},置信度为: {}'.format(name[predict_cla], predict[predict_cla].item()))
plt.show()
索引为 1
预测结果为:病理性近视,置信度为: 0.9768268465995789
Para obtener más detalles, consulte la implementación de la versión paddle: Caso básico práctico de aprendizaje profundo: reconocimiento de enfermedades oculares de red neuronal convolucional (CNN) basado en SqueezeNet