Introducción al lenguaje Java para los capítulos de dominio.
- Notas de estudio: Java-Basics (Parte 1)_blog-CSDN de blog de ljtxy.love
- Notas de estudio: Java-Intermedio (Parte 2)_Blog-CSDN de blog de ljtxy.love
- Notas de estudio: Java avanzado (tercera parte): se busca programador
- Notas de estudio: Java-Avanzado (1) (Parte 4) - Se busca programador
- Notas de estudio: Java-Avanzado (2) (Parte 5) - Se busca programador
- Notas de estudio: nuevas funciones del blog Blog-CSDN de Java8_ljtxy.love
Directorio de artículos
- 25. subprocesos múltiples
-
- 25.1 Descripción general
- 25.2 Método de implementación
- 25.3 Métodos de miembros comunes
- 25.4 Ciclo de vida
- 25.5 Problemas de seguridad de subprocesos
- 25.6 Productores y consumidores
- 25.7 Cola de bloqueo
- 25.8 Estado del hilo
- 25.9 Pila de hilos
- 25.10 Grupo de lotería de casos
- Grupo de subprocesos 25.11
- 25.12 Grupo de subprocesos personalizados
- 25.13 Preguntas frecuentes sobre hilos
- 25.13 Herramientas
- 26.Programación de red
-
- 26.1 Descripción general
- 26.2Clase InetAddress
- Programa de comunicación 26.3UDP
- Programa de comunicación 26.4TCP
- 27.Reflexión
- 28. Proxy dinámico
- 29.Registro
- 30.Anotaciones
- 30. Algoritmo (actualmente entendido, se complementará en el futuro)
- 30. Suplemento (entendido actualmente, se complementará en el futuro)
25. subprocesos múltiples
Resumen de notas: ver cada sección
25.1 Descripción general
Resumen de notas:
- Proceso: es un programa en ejecución
- Hilo: es un flujo de control secuencial único en un proceso , una ruta de ejecución
- Paralelismo: al mismo tiempo, se ejecutan varias instrucciones simultáneamente en varias CPU
- Concurrencia: al mismo tiempo, se ejecutan varias instrucciones alternativamente en una sola CPU
- Modelo de programación preventiva: priorice los subprocesos con alta prioridad para usar la CPU
- Modelo de programación de tiempo compartido: todos los subprocesos se turnan para usar la CPU y los intervalos de tiempo ocupados por cada subproceso en la CPU se distribuyen uniformemente.
- Daemon Thread es un hilo especial que proporciona un servicio general en segundo plano.
25.1.1 Procesos y Subprocesos
Proceso: es un programa en ejecución
- Independencia: un proceso es una unidad básica que puede ejecutarse de forma independiente y también es una unidad independiente para que el sistema asigne recursos y programe.
- Dinámica: La esencia de un proceso es el proceso de ejecución de un programa: un proceso se genera dinámicamente y muere dinámicamente.
- Concurrencia: cualquier proceso puede ejecutarse simultáneamente con otros procesos.
Hilo: es un flujo de control secuencial único en un proceso, una ruta de ejecución
-
Subproceso único: si un proceso tiene solo una ruta de ejecución, se denomina programa de subproceso único.
-
Multiproceso: si un proceso tiene varias rutas de ejecución, se denomina programa multiproceso.
Thread es la unidad más pequeña que el sistema operativo puede realizar en la programación de cálculos. Está incluido en el proceso y es la unidad operativa real en el proceso.
25.1.2 Concurrencia y Paralelismo
-
Paralelismo: al mismo tiempo, se ejecutan varias instrucciones simultáneamente en varias CPU .

-
Concurrencia: al mismo tiempo, se ejecutan varias instrucciones alternativamente en una sola CPU .

25.1.3 Programación de subprocesos
Modelo de programación preventiva: priorice los subprocesos con mayor prioridad para usar la CPU. Si los subprocesos tienen la misma prioridad, se seleccionará uno al azar. El subproceso con mayor prioridad obtendrá relativamente más intervalos de tiempo de CPU.

ilustrar:
La probabilidad de que la CPU llame a un subproceso es aleatoria y el tiempo de llamada también es incierto.
Modelo de programación de tiempo compartido: todos los subprocesos se turnan para usar la CPU y el intervalo de tiempo ocupado por cada subproceso en la CPU se distribuye uniformemente.

ilustrar:
La CPU llama a los subprocesos secuencialmente y la duración de la llamada es relativamente fija.
25.1.4 Hilo de demonio
En Java, un hilo de demonio (Daemon Thread) es un hilo especial que proporciona un servicio general en segundo plano . Cuando solo queden subprocesos de demonio en la máquina virtual Java (JVM), la JVM se cerrará. A diferencia de los subprocesos de usuario, los subprocesos de demonio no impiden que la JVM salga.
ilustrar:
Mientras chateas, también puedes transferir archivos
25.2 Método de implementación
Resumen de notas:
- Método de implementación: heredar la clase Thread e implementar las interfaces Runnable y Callable
- Uso: Reciba el resultado de retorno del hilo a través del hilo object.start() o
FutureTask<String> ft = new FutureTask<>(mc);. Consulte cada sección para obtener más detalles.
25.2.1 Descripción general

- Implementar interfaces ejecutables y llamables
- Ventajas: gran escalabilidad, también puede heredar otras clases al implementar esta interfaz
- Desventajas: la programación es relativamente complicada y los métodos de la clase Thread no se pueden utilizar directamente.
- Heredar la clase Thread
- Ventajas: la programación es relativamente simple, puede usar directamente los métodos en la clase Thread
- Desventajas: poca escalabilidad, no puede heredar otras clases
25.2.2 Heredar la clase Thread
25.2.2.1 Método de construcción
| nombre del método | ilustrar |
|---|---|
| Hilo (objetivo ejecutable) | Asignar un nuevo objeto Thread |
| Hilo (objetivo ejecutable, nombre de cadena) | Asignar un nuevo objeto Thread |
25.2.2.2 Métodos de miembros comunes
| nombre del método | ilustrar |
|---|---|
| ejecución vacía () | Una vez iniciado el hilo, este método será llamado y ejecutado. |
| inicio nulo () | Haga que este hilo comience la ejecución y la máquina virtual Java llame al método de ejecución () |
25.2.2.3 Caso: Hilo de impresión
Pasos de implementación:
- Definir una clase MyThread que herede la clase Thread
- Anular el método run() en la clase MyThread
- Crear un objeto de la clase MyThread
- Iniciar hilo
public class MyThread extends Thread {
@Override
public void run() {
for(int i=0; i<100; i++) {
System.out.println(i);
}
}
}
public class MyThreadDemo {
public static void main(String[] args) {
MyThread my1 = new MyThread();
MyThread my2 = new MyThread();
// my1.run();
// my2.run();
//void start() 导致此线程开始执行; Java虚拟机调用此线程的run方法
my1.start();
my2.start();
}
}
Aviso:
- Anule el método de ejecución en la clase, porque run () se usa para encapsular el código ejecutado por el hilo.
- La diferencia entre los métodos run() y start() es
- run(): encapsula el código ejecutado por el hilo y lo llama directamente, lo que equivale a llamar a un método normal.
- start(): inicia el hilo; luego la JVM llama al método run() de este hilo
25.2.3 Implementar interfaz ejecutable
25.2.3.1 Métodos de miembros comunes
25.2.3.3 Caso: Hilo de impresión
Pasos de implementación:
- Defina una clase MyRunnable para implementar la interfaz Runnable
- Anular el método run() en la clase MyRunnable
- Crea un objeto de la clase MyRunnable
- Cree un objeto de la clase Thread y use el objeto MyRunnable como parámetro del método constructor
- Iniciar hilo
public class MyRunnable implements Runnable {
@Override
public void run() {
for(int i=0; i<100; i++) {
// 此处通过线程来进行获取名称,不能直接使用getName()方法
System.out.println(Thread.currentThread().getName()+":"+i);
}
}
}
public class MyRunnableDemo {
public static void main(String[] args) {
//创建MyRunnable类的对象
MyRunnable my = new MyRunnable();
//创建Thread类的对象,把MyRunnable对象作为构造方法的参数
//Thread(Runnable target)
// Thread t1 = new Thread(my);
// Thread t2 = new Thread(my);
//Thread(Runnable target, String name)
Thread t1 = new Thread(my,"坦克");
Thread t2 = new Thread(my,"飞机");
//启动线程
t1.start();
t2.start();
}
}
25.2.4 Implementar la interfaz invocable
25.2.4.1 Métodos de miembros comunes
| nombre del método | ilustrar |
|---|---|
| V llamada() | Calcula el resultado o lanza una excepción si el resultado no se puede calcular |
| FutureTask(Invocable invocable) | Crea una FutureTask que ejecuta el Callable dado una vez ejecutado. |
| V obtener() | Si es necesario, espere a que se complete el cálculo y luego obtenga su resultado. |
25.2.4.3 Caso: Hilo de impresión
Pasos de implementación:
- Defina una clase MyCallable para implementar la interfaz Callable
- Anular el método call() en la clase MyCallable
- Cree un objeto de parámetro clase MyCallable para que lo ejecuten varios subprocesos
- Cree un objeto FutureTask de clase de implementación del objeto administrador Future para resultados de ejecución de subprocesos múltiples y use el objeto MyCallable como parámetro del método constructor.
- Cree una clase Thread de objeto de hilo y use el objeto FutureTask como parámetro del método constructor
- Iniciar hilo
- Luego llame al método get para obtener el resultado una vez que finalice el hilo.
public class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
for (int i = 0; i < 100; i++) {
System.out.println("跟女孩表白" + i);
}
//返回值就表示线程运行完毕之后的结果
return "答应";
}
}
public class Demo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//线程开启之后需要执行里面的call方法
MyCallable mc = new MyCallable();
//Thread t1 = new Thread(mc);
//可以获取线程执行完毕之后的结果.也可以作为参数传递给Thread对象
FutureTask<String> ft = new FutureTask<>(mc);
//创建线程对象
Thread t1 = new Thread(ft);
String s = ft.get();
//开启线程
t1.start();
//String s = ft.get();
System.out.println(s);
}
}
25.3 Métodos de miembros comunes
Resumen de notas:
- Objeto de hilo. Los métodos de miembros comúnmente utilizados en subprocesos múltiples generalmente incluyen
getName(),currentEhread()
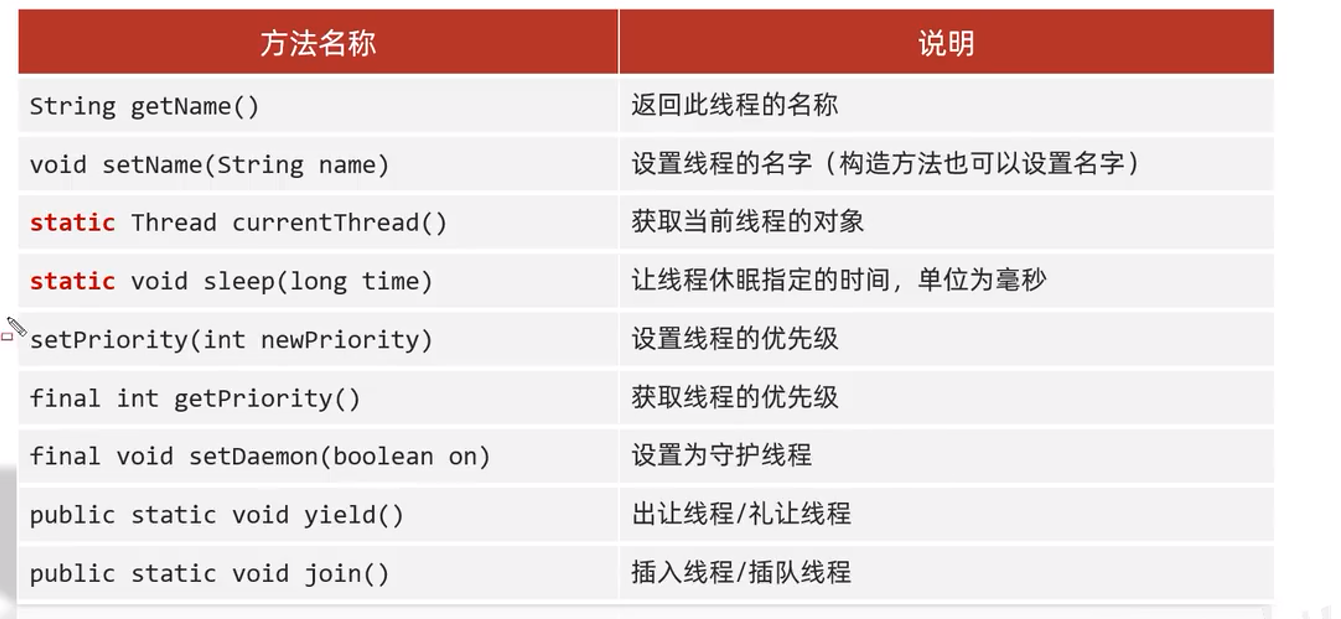
25.3.1 Descripción general
Objeto de hilo. Métodos de miembros comúnmente utilizados en subprocesos múltiples
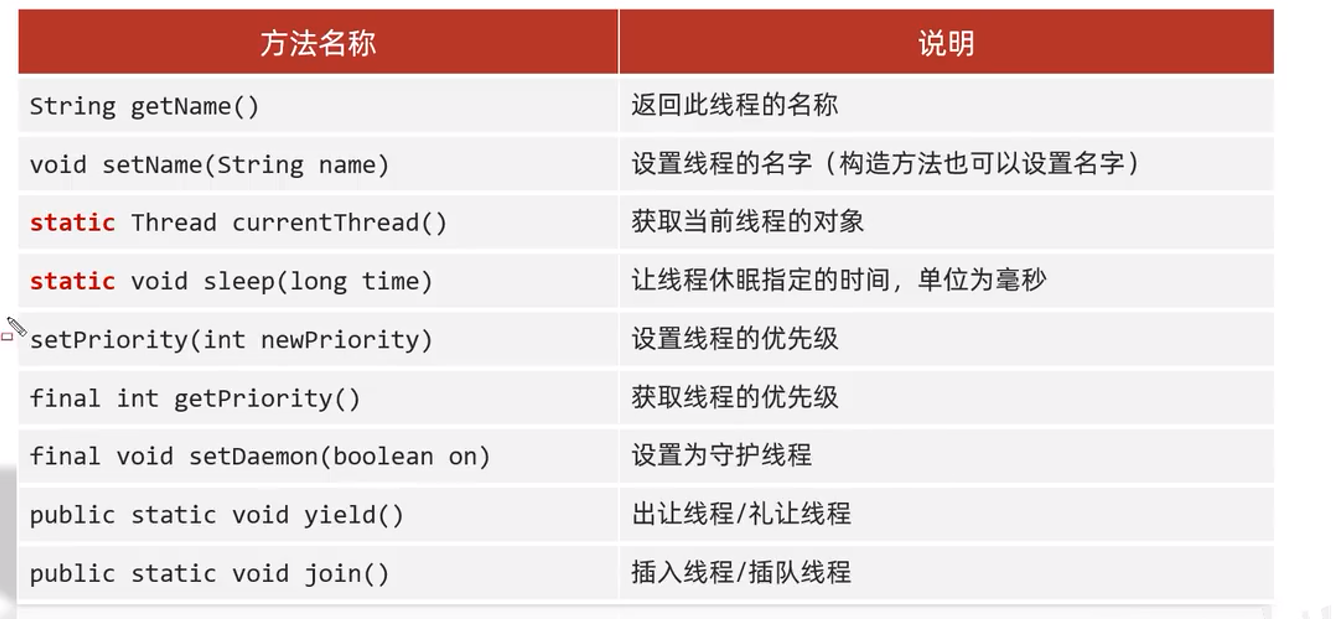
Reponer:
Establezca el rango de prioridad del hilo en 1-10
25.3.2setName(nombre de cadena)
/* 格式:
Thread对象.setName(String name)
作用:为线程起名字*/
thred.setName("玥玥");
detalle:
Si no configuramos un nombre para el hilo, el hilo también tendrá un nombre predeterminado.
格式:Thread-X(X序号,从0开始的)Si queremos establecer un nombre para el hilo, podemos usar el método set para configurarlo, o podemos configurarlo usando el método constructor.
25.3.3obtenerNombre()
/* 格式:
Thread对象.getName()
作用:获取线程的名字*/
thred.getName()
25.3.4 hilo actual()
/* 格式:
Thread对象.currentThread()
作用:获取对当前正在执行的线程对象的引用*/
thred.currentThread()
detalle:
- Cuando se inicia la máquina virtual JVM, se iniciarán automáticamente varios subprocesos.
- Uno de los hilos se llama hilo principal.
- Su función es llamar al método principal y ejecutar el código dentro.
- En el pasado, todo el código que escribíamos se ejecutaba en el hilo principal.
25.3.5dormir(milis largos)
/6 格式:
Thread对象.sleep(long millis)
作用:使当前正在执行的线程停留(暂停执行)指定的毫秒数*/
thred.sleep(1000)
25.3.6obtenerPrioridad()
/* 格式:
Thread对象.getPriority()
作用:返回此线程的优先级*/
thred.getPriority() // 5
detalle:
- La prioridad mínima de Java es 1, la predeterminada es 5 y la máxima es 10
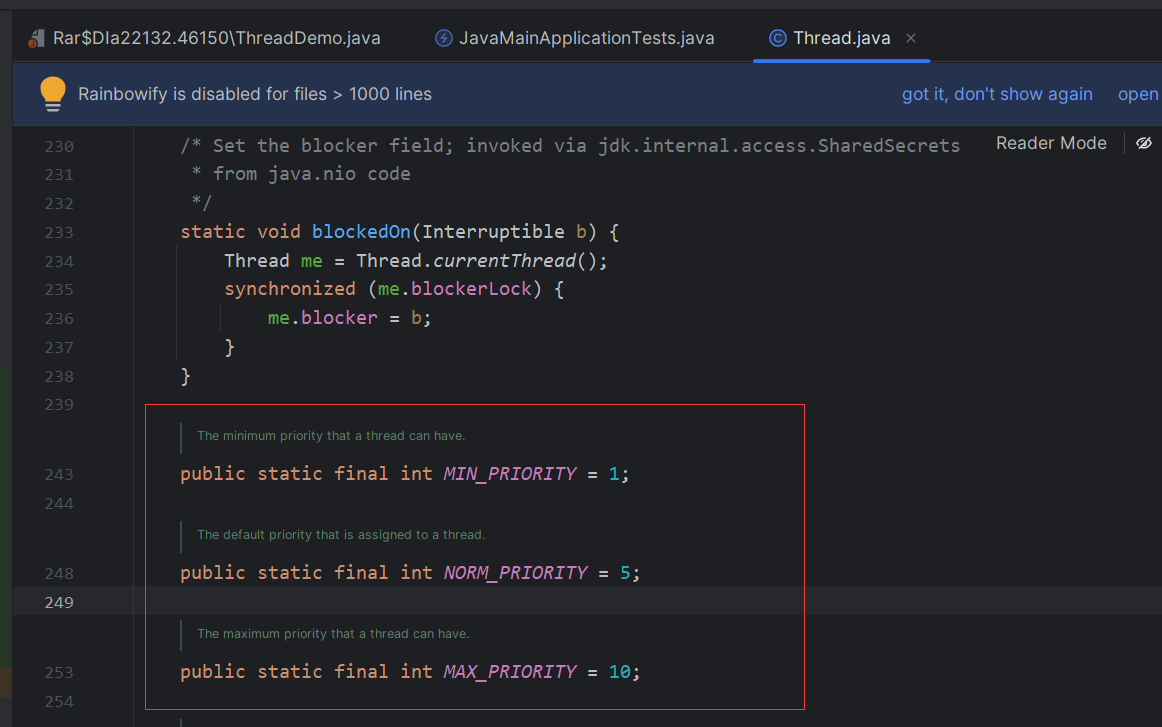
25.3.7establecerPrioridad(int nuevaPrioridad)
/* 格式:
Thread对象.setPriority(int newPriority)
作用:更改此线程的优先级,范围1-10*/
thred.setPriority(10) // 5
ilustrar:
Cuanto mayor sea la prioridad, no significa que deba ejecutarse primero, pero la probabilidad de preferencia es mayor.
25.3.8setDaemon(booleano activado)
/* 格式:
Thread对象.setDaemon(boolean on)
作用:将此线程标记为守护线程,当运行的线程都是守护线程时,Java虚拟机将退出*/
thred.setDaemon(True)
25.3.9rendimiento()
/* 格式:
Thread对象.yield()
作用:让线程输出更均衡一点*/
thred.yield()
ilustrar:
Hilo cortés, agregar este método al hilo puede hacer que la salida del hilo sea más equilibrada. No se usa comúnmente, solo comprenda
25.3.10jión()
/* 格式:
Thread对象.jion()
作用:将此线程在某线程之前插队执行完成*/
thred.jion()
ilustrar:
Inserte un hilo, agregue este método al hilo y este hilo podrá ponerse en cola y ejecutarse antes que un hilo determinado. No se usa comúnmente, solo entiéndelo.
25.4 Ciclo de vida
Resumen de notas: consulte esta sección
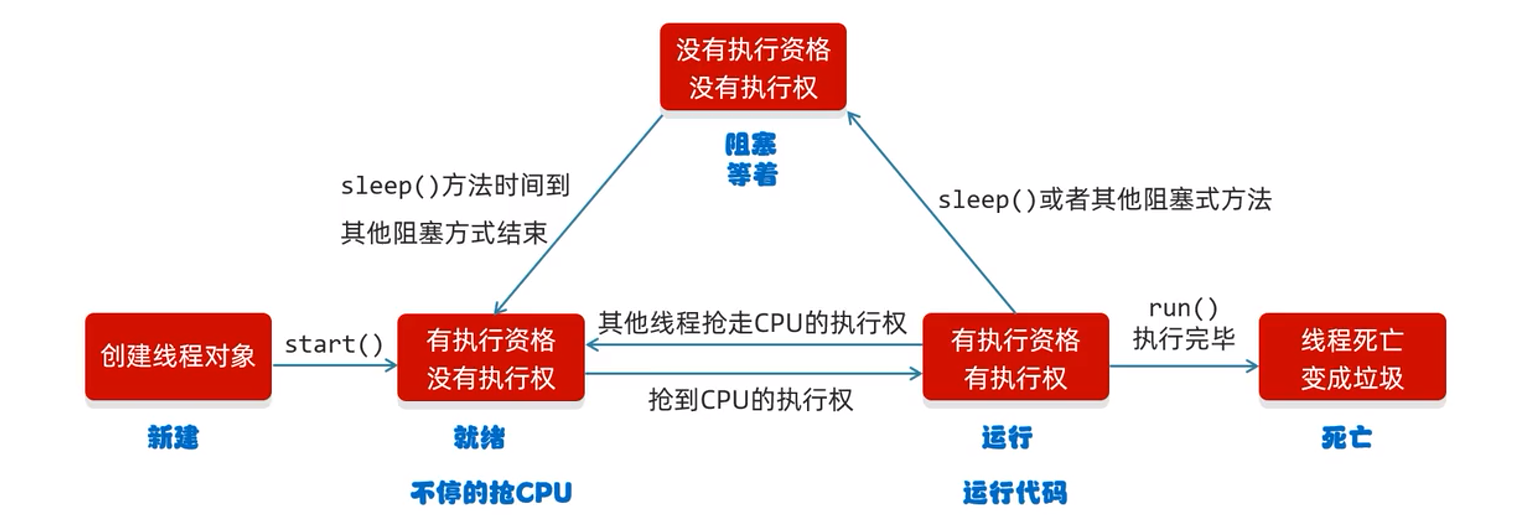
ilustrar:
Crea un objeto de hilo y llama
start()a un método. En este momento, el hilo continuará capturando la CPU hasta que tenga la calificación de ejecución y la ejecución correcta al mismo tiempo. En este momento, el hilo ejecutará la tarea y, una vez ejecutada la tarea, el hilo se convertirá en un hilo sin calificación de ejecución ni derecho de ejecución. Ciclo de ida y vuelta. Si se completa la ejecución de la tarea total, el hilo muere
Reponer:
El método de suspensión hará que el hilo duerma. Una vez transcurrido el tiempo de suspensión, ¿se ejecutará inmediatamente el siguiente código? La respuesta es no y el hilo entrará en el estado listo en este momento.
25.5 Problemas de seguridad de subprocesos
Resumen de notas:
La palabra clave sincronizada implementa el bloqueo de código.
static Object object = new Object(); // 注意:此时锁的对象需要确保唯一,否则加锁失效 synchronized (object) { …… }Método de sincronización:
public synchronized boolean method() { // 此时锁对象不能够自定义 …… }Bloqueo de bloqueo:
ReentrantLock lock = new ReentrantLock(); //创建锁对象 lock.lock(); // 加锁 lock.unlock(); // 释放锁Punto muerto: los subprocesos se esperan entre sí , lo que da como resultado un estado de bloqueo mutuo , lo que imposibilita que el programa continúe ejecutándose.
25.5.1 Bloques de código sincronizados
25.5.1.1 Descripción general
25.5.1.1.1 Definición
Código de bloqueo que opera con datos compartidos
25.5.1.1.2 Características
- El candado está abierto por defecto, si entra un hilo, el candado se cierra automáticamente.
- Se ejecuta todo el código interno, sale el hilo y el candado se abre automáticamente.
25.5.1.2 Casos de uso básicos
public class MyThread extends Thread {
//表示这个类所有的对象,都共享ticket数据
static int ticket = 0;//0 ~ 99
@Override
public void run() {
while (true) {
synchronized (MyThread.class) {
//同步代码块
if (ticket < 100) {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
ticket++;
System.out.println(getName() + "正在卖第" + ticket + "张票!!!");
} else {
break;
}
}
}
}
}
detalle:
En términos generales, el archivo de código de bytes de un objeto de clase, es decir, MyThread.class, es único. Por lo tanto, cumplir con el objeto de bloqueo es la única condición.
25.5.1.3 Métodos comunes
/* 格式:
synchronized (锁) {
操作共享数据的代码} */
// 锁对象,一定需要是唯一的
static Object object = new Object();
synchronized (object) {
……
}
detalle:
El objeto de bloqueo sincronizado debe ser único. Si es un objeto de bloqueo diferente en este momento, entonces el bloqueo agregado a este código no tiene sentido.
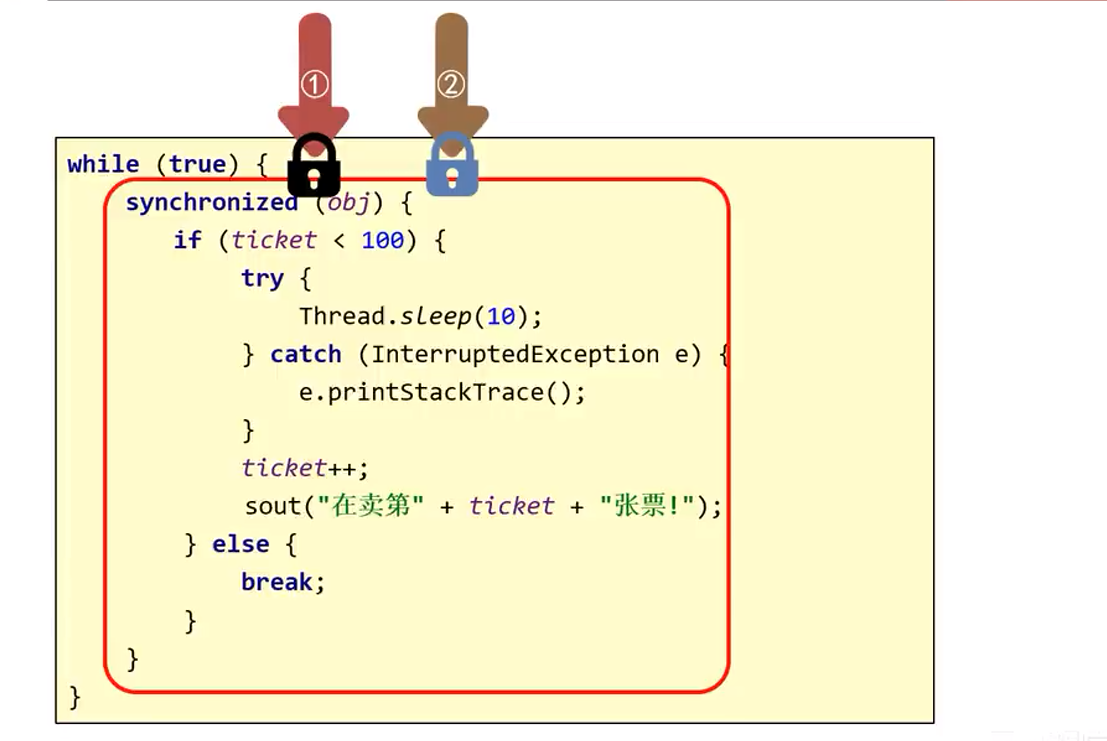
25.5.1.4 Escenarios de aplicación

ilustrar:
Si varios subprocesos compran boletos al mismo tiempo, cuando se ejecuta el código ticket ++, se quita el derecho de ejecución de la CPU y el método soout no se ejecuta, lo que provocará un error lógico.
25.5.2 Métodos síncronos
25.5.2.1 Descripción general
25.5.2.1.1 Definición
El método de sincronización en Java se refiere a un mecanismo que puede garantizar la exactitud de los datos cuando acceden a ellos varios subprocesos .
25.5.2.1.2Características
- El método de sincronización adquirirá automáticamente el bloqueo del objeto actual cuando se ejecute.
- Si un subproceso ha adquirido el bloqueo del objeto actual, otros subprocesos deben esperar a que el subproceso complete la ejecución y libere el bloqueo antes de poder adquirir el bloqueo y ejecutar el método sincronizado.
- Los métodos de sincronización pueden garantizar la seguridad de los subprocesos y evitar el problema de que varios subprocesos modifiquen el mismo objeto al mismo tiempo.
- Los métodos sincrónicos también pueden causar bloqueo de subprocesos y degradación del rendimiento , por lo que deben usarse con precaución.
- El objeto de bloqueo no puede ser especificado por usted mismo
25.5.2.4 Casos de uso básicos
public class MyRunnable implements Runnable {
int ticket = 0;
@Override
public void run() {
//1.循环
while (true) {
//2.同步代码块(同步方法)
if (method()) break;
}
}
//this
private synchronized boolean method() {
//3.判断共享数据是否到了末尾,如果到了末尾
if (ticket == 100) {
return true;
} else {
//4.判断共享数据是否到了末尾,如果没有到末尾
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
ticket++;
System.out.println(Thread.currentThread().getName() + "在卖第" + ticket + "张票!!!");
}
return false;
}
}
25.5.2.5 Métodos comunes
/* 格式:
修饰符 synchronized 返回值类型 方法名(方法参数) {
方法体; } */
public synchronized boolean method() {
……
}
detalle:
- El objeto de bloqueo no puede ser especificado por usted mismo
- Método estático: el objeto de bloqueo es el archivo de código de bytes del objeto actual
- Método no estático: el objeto de bloqueo es este
25.5.2.6 Reserva de billete-caso
public class MyRunnable implements Runnable {
int ticket = 0;
@Override
public void run() {
//1.循环
while (true) {
//2.同步代码块(同步方法)
if (method()) break;
}
}
//this
private synchronized boolean method() {
//3.判断共享数据是否到了末尾,如果到了末尾
if (ticket == 100) {
return true;
} else {
//4.判断共享数据是否到了末尾,如果没有到末尾
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
ticket++;
System.out.println(Thread.currentThread().getName() + "在卖第" + ticket + "张票!!!");
}
return false;
}
}
MyRunnable mr = new MyRunnable();
Thread t1 = new Thread(mr);
Thread t2 = new Thread(mr);
Thread t3 = new Thread(mr);
t1.setName("窗口1");
t2.setName("窗口2");
t3.setName("窗口3");
t1.start();
t2.start();
t3.start();
ilustrar:
En este momento, el objeto de bloqueo pasado por cada hilo es único, todos los cuales son mr. Por lo tanto, se garantiza que el objeto de bloqueo en el método estático del método de sincronización será único.
25.5.3 Bloqueo de bloqueo
25.5.3.1 Descripción general
25.5.3.1.1 Definición
Lock Lock es un mecanismo de sincronización en la programación concurrente de Java que se puede utilizar para controlar el acceso a recursos compartidos.
25.5.3.1.2 Características
- Adquirir y liberar bloqueos explícitamente: la palabra clave sincronizada adquiere y libera bloqueos implícitamente, mientras que los bloqueos Lock requieren la adquisición y liberación manual de bloqueos.
- Se pueden implementar bloqueos justos y bloqueos injustos: la palabra clave sincronizada es un bloqueo injusto, es decir, el orden en que se adquieren los bloqueos es incierto. Los bloqueos de bloqueo pueden implementar bloqueos justos y bloqueos injustos, es decir, el orden en que se adquieren los bloqueos es predecible.
- Los subprocesos que esperan el bloqueo pueden interrumpirse: durante el proceso de adquisición del bloqueo, si el subproceso espera demasiado, el hilo que espera el bloqueo puede interrumpirse.
- Admite múltiples variables de condición: Lock puede admitir múltiples variables de condición, es decir, se pueden realizar diferentes operaciones de activación en subprocesos en diferentes condiciones.
- Puede mejorar el rendimiento: en escenarios de alta concurrencia, el uso de Lock puede mejorar el rendimiento del sistema, que es más eficiente que la palabra clave sincronizada.
25.5.3.4 Casos de uso básicos
public class MyThread extends Thread{
static int ticket = 0;
// 此处需要将Lock锁变为静态,以保证全局唯一,而不会创建多个Lock锁
static Lock lock = new ReentrantLock();
@Override
public void run() {
//1.循环
while(true){
//2.同步代码块
//synchronized (MyThread.class){
lock.lock(); //2 //3
try {
//3.判断
if(ticket == 100){
break;
//4.判断
}else{
Thread.sleep(10);
ticket++;
System.out.println(getName() + "在卖第" + ticket + "张票!!!");
}
// }
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
}
detalle:
Cuando el bloqueo está a punto de finalizar, se recomienda utilizar try...catch...finally. Debido a que el método finalmente siempre se ejecutará, es más apropiado ponerlo aquí.
25.5.3.5 Métodos comunes
/* 格式:
构造方法:ReentrantLock()
加锁解锁方法:获得锁 void lock()、释放锁 void unlock()*/
ReentrantLock lock = new ReentrantLock();
lock.lock();
lock.unlock();
paso:
- Crear objeto de bloqueo
- obtener bloqueo
- desbloquear bloqueo
25.5.4 Punto muerto
El punto muerto se refiere a un fenómeno en el que dos o más subprocesos se esperan entre sí debido a la competencia por los recursos durante la ejecución . Sin fuerza externa, no podrán continuar con la ejecución. En pocas palabras, dos o más subprocesos esperan entre sí para liberar el bloqueo primero, lo que genera un estado de bloqueo mutuo y hace que el programa no pueda continuar con la ejecución.

ilustrar:
Cuando un niño y una niña reciben un palillo al mismo tiempo, el niño espera a que la niña deje los palillos y la niña espera a que el niño deje los palillos.
Ejemplo:
public class MyThread extends Thread {
static Object objA = new Object();
static Object objB = new Object();
@Override
public void run() {
//1.循环
while (true) {
if ("线程A".equals(getName())) {
synchronized (objA) {
System.out.println("线程A拿到了A锁,准备拿B锁");//A
synchronized (objB) {
System.out.println("线程A拿到了B锁,顺利执行完一轮");
}
}
} else if ("线程B".equals(getName())) {
if ("线程B".equals(getName())) {
synchronized (objB) {
System.out.println("线程B拿到了B锁,准备拿A锁");//B
synchronized (objA) {
System.out.println("线程B拿到了A锁,顺利执行完一轮");
}
}
}
}
}
}
}
ilustrar:
Cuando el hilo A obtiene el bloqueo A, el hilo B obtiene el bloqueo B. Al mismo tiempo, el subproceso A está esperando obtener el bloqueo B y el subproceso B está esperando obtener el bloqueo A, por lo que el programa se atascará, lo que se denomina punto muerto.
Si desea evitar un punto muerto, no utilice bloqueos anidados.
25.6 Productores y consumidores
Resumen de notas:
Descripción general: Productor-consumidor es un modelo de concurrencia común que se utiliza para resolver problemas de intercambio de datos entre productores y consumidores.
Métodos de miembros comunes:
nombre del método ilustrar espera nula() Hace que el hilo actual espere hasta que otro hilo llame al método notify() o al método notifyAll() del objeto. notificación nula() Activar un único hilo que está esperando en un monitor de objetos anular notificar a todos() Despierta todos los hilos que esperan en el monitor de objetos.
25.6.1 Descripción general
25.6.1.1 Definición
Productor-consumidor es un modelo de concurrencia común que se utiliza para resolver problemas de intercambio de datos entre productores y consumidores .
25.6.1.2 Modelo productor-consumidor
- Productor: Responsable de producir datos y almacenarlos en una estructura de datos compartida.
- Consumidor: Responsable de obtener datos de la estructura de datos compartida y consumirlos.
25.6.1.3 Esperando el mecanismo de activación

25.6.2 Métodos de miembros de uso común
| nombre del método | ilustrar |
|---|---|
| espera nula() | Hace que el hilo actual espere hasta que otro hilo llame al método notify() o al método notifyAll() del objeto. |
| notificación nula() | Activar un único hilo que está esperando en un monitor de objetos |
| anular notificar a todos() | Despierta todos los hilos que esperan en el monitor de objetos. |
25.6.3 Caso-Foodie y Chef
1. Crea una clase de tabla
public class Desk {
/*
* 作用:控制生产者和消费者的执行
*
* */
//是否有面条 0:没有面条 1:有面条
public static int foodFlag = 0;
//总个数
public static int count = 10;
//锁对象
public static Object lock = new Object();
}
2. Crear consumidores (amantes de la gastronomía)
public class Foodie extends Thread{
@Override
public void run() {
/*
* 1. 循环
* 2. 同步代码块
* 3. 判断共享数据是否到了末尾(到了末尾)
* 4. 判断共享数据是否到了末尾(没有到末尾,执行核心逻辑)
* */
while(true){
synchronized (Desk.lock){
if(Desk.count == 0){
break;
}else{
//先判断桌子上是否有面条
if(Desk.foodFlag == 0){
//如果没有,就等待
try {
Desk.lock.wait();//让当前线程跟锁进行绑定
} catch (InterruptedException e) {
e.printStackTrace();
}
}else{
//把吃的总数-1
Desk.count--;
//如果有,就开吃
System.out.println("吃货在吃面条,还能再吃" + Desk.count + "碗!!!");
//吃完之后,唤醒厨师继续做
Desk.lock.notifyAll();
//修改桌子的状态
Desk.foodFlag = 0;
}
}
}
}
}
}
detalle:
Cuando el consumidor está esperando, necesita llamar
Desk.lock.wait();al método del objeto de bloqueo intermediario, cuyo propósito es vincular el hilo actual al bloqueo para facilitar laDesk.lock.notifyAll();operación de activación de este hilo.
3. Crea un productor (chef)
public class Cook extends Thread{
@Override
public void run() {
/*
* 1. 循环
* 2. 同步代码块
* 3. 判断共享数据是否到了末尾(到了末尾)
* 4. 判断共享数据是否到了末尾(没有到末尾,执行核心逻辑)
* */
while (true){
synchronized (Desk.lock){
if(Desk.count == 0){
break;
}else{
//判断桌子上是否有食物
if(Desk.foodFlag == 1){
//如果有,就等待
try {
Desk.lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}else{
//如果没有,就制作食物
System.out.println("厨师做了一碗面条");
//修改桌子上的食物状态
Desk.foodFlag = 1;
//叫醒等待的消费者开吃
Desk.lock.notifyAll();
}
}
}
}
}
}
detalle:
Lo mismo que arriba
4.Uso
public class ThreadDemo {
public static void main(String[] args) {
/*
*
* 需求:完成生产者和消费者(等待唤醒机制)的代码
* 实现线程轮流交替执行的效果
*
* */
//创建线程的对象
Cook c = new Cook();
Foodie f = new Foodie();
//给线程设置名字
c.setName("厨师");
f.setName("吃货");
//开启线程
c.start();
f.start();
}
}
25.7 Cola de bloqueo
Resumen de notas: vea este resumen en detalle
25.7.1 Descripción general
25.7.1.1 Definición
Una cola de bloqueo es una cola especial que tiene la característica de bloquear y esperar al insertar y eliminar elementos . Las colas de bloqueo se utilizan a menudo en la programación de subprocesos múltiples como canal de intercambio de datos entre diferentes subprocesos.
25.7.1.2 Estructura de herencia
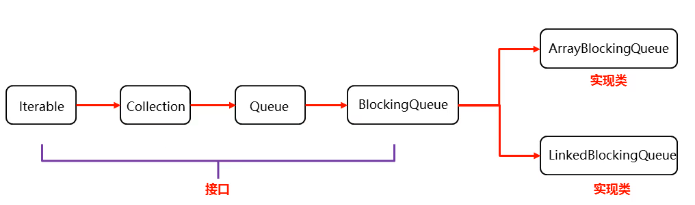
ilustrar:
ArrayBlockingQueue: la capa inferior es una matriz, limitada
LinkedBlockingQueue: la capa inferior es una lista vinculada, ilimitada, pero no es verdaderamente ilimitada, el valor máximo es el valor máximo de int.
25.7.2 Caso-Foodie y Chef
Paso 1: crear consumidores (amantes de la gastronomía)
public class Foodie extends Thread{
ArrayBlockingQueue<String> queue;
public Foodie(ArrayBlockingQueue<String> queue) {
this.queue = queue;
}
@Override
public void run() {
while(true){
//不断从阻塞队列中获取面条
try {
String food = queue.take();
System.out.println(food);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
ilustrar:
Cuando utilice una cola de bloqueo, utilice el método take() del objeto para obtener datos de la cola de bloqueo.
Paso 2: Crea un productor (chef)
public class Cook extends Thread{
ArrayBlockingQueue<String> queue;
public Cook(ArrayBlockingQueue<String> queue) {
this.queue = queue;
}
@Override
public void run() {
while(true){
//不断的把面条放到阻塞队列当中
try {
queue.put("面条");
System.out.println("厨师放了一碗面条");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
ilustrar:
Cuando utilice una cola de bloqueo, utilice el método put() del objeto para insertar datos de la cola de bloqueo
Paso 3: demostración
ublic class ThreadDemo {
public static void main(String[] args) {
/*
*
* 需求:利用阻塞队列完成生产者和消费者(等待唤醒机制)的代码
* 细节:
* 生产者和消费者必须使用同一个阻塞队列
*
* */
//1.创建阻塞队列的对象
ArrayBlockingQueue<String> queue = new ArrayBlockingQueue<>(1);
//2.创建线程的对象,并把阻塞队列传递过去
Cook c = new Cook(queue);
Foodie f = new Foodie(queue);
//3.开启线程
c.start();
f.start();
}
}
ilustrar:
Cree un objeto de bloqueo y páselo a productores y consumidores, el propósito es unificar las colas de bloqueo utilizadas por chefs (productores) y amantes de la comida (consumidores).
25.8 Estado del hilo
Resumen de notas: vea esta sección en detalle
En Java, el estado de un hilo se refiere a los diferentes estados de un objeto hilo durante su ciclo de vida. El estado del hilo de Java incluye:

- NUEVO: un hilo recién creado que aún no ha comenzado a ejecutarse.
- EJECUTABLE: estado en ejecución, puede ejecutarse o puede estar esperando el intervalo de tiempo de la CPU.
- BLOQUEADO: El hilo está bloqueado, esperando un bloqueo u otro recurso de sincronización.
- ESPERANDO: El subproceso está en estado de espera, esperando que otros subprocesos realicen una operación o esperando un tiempo de espera.
- TIMED_WAITING: el hilo está en un estado de espera por tiempo limitado, como Thread.sleep ().
- TERMINADO: el subproceso completó la ejecución y salió del ciclo de vida del subproceso.

ilustrar:
Los términos “calificación para ejecutar” y “derecho a ejecutar” en este diagrama se agregan para facilitar la comprensión. En Java, solo los seis estados restantes serán coordinados por Java. Cuando existan calificaciones de ejecución y derechos de ejecución, Java ya no asumirá el control.
25.9 Pila de hilos
Resumen de la nota: consulte la descripción general de esta sección para obtener más detalles.
25.9.1 Descripción general
Thread Stack es un área de memoria asignada a los subprocesos por el sistema operativo y se utiliza para almacenar información como llamadas a métodos de subprocesos y variables locales . Cada hilo tiene su propia pila de hilos , que son independientes y no se afectan entre sí .
25.9.2 Mapa de memoria
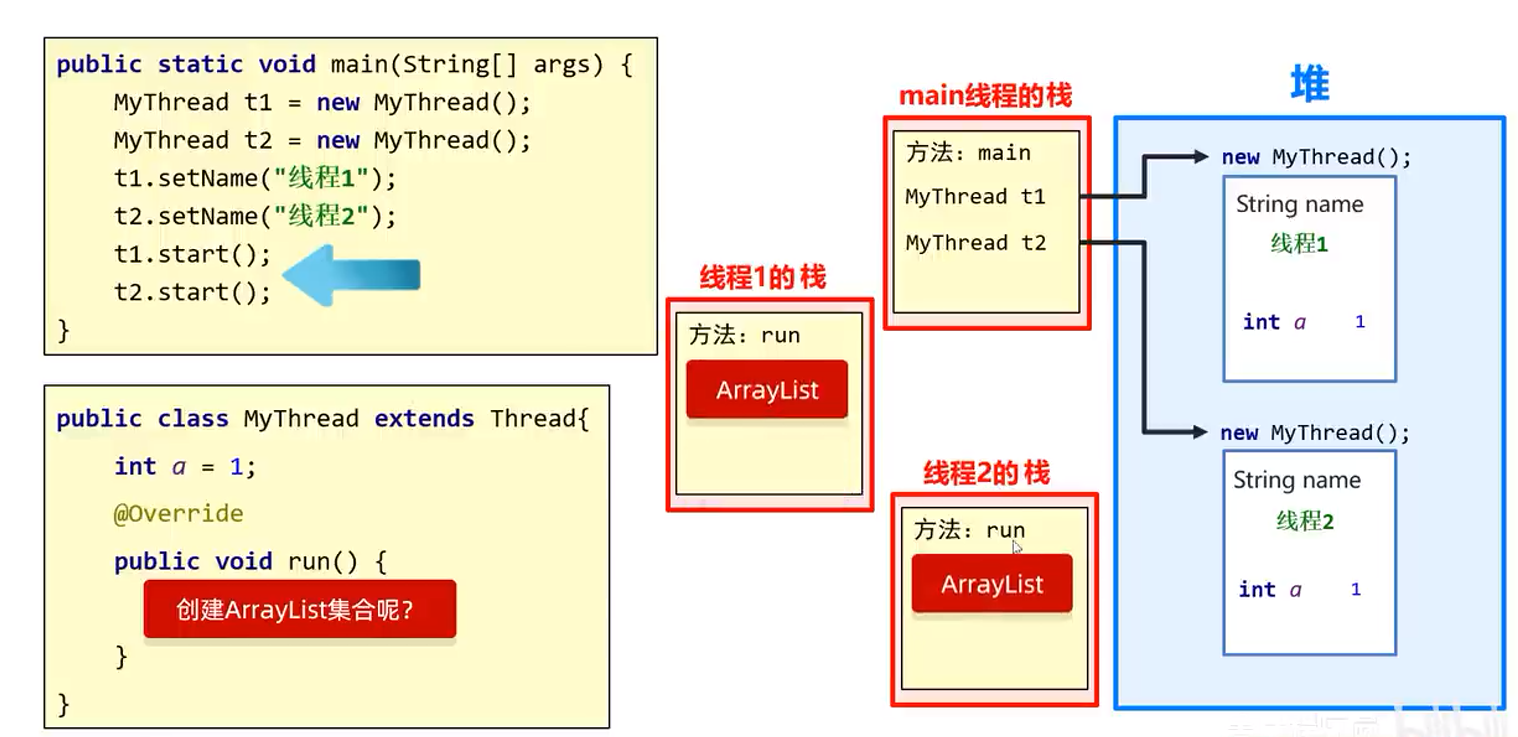
ilustrar:
Cada vez que se crea un hilo, se crean varias pilas en la memoria
25.9.3 Grupo de lotería de casos
1. Crea un hilo
public class MyThread extends Thread {
ArrayList<Integer> list;
public MyThread(ArrayList<Integer> list) {
this.list = list;
}
@Override
public void run() {
ArrayList<Integer> boxList = new ArrayList<>();//1 //2
while (true) {
synchronized (MyThread.class) {
if (list.size() == 0) {
System.out.println(getName() + boxList);
break;
} else {
//继续抽奖
Collections.shuffle(list);
int prize = list.remove(0);
boxList.add(prize);
}
}
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
2.Demostración
public class Test {
public static void main(String[] args) {
/*
有一个抽奖池,该抽奖池中存放了奖励的金额,该抽奖池中的奖项为 {10,5,20,50,100,200,500,800,2,80,300,700};
创建两个抽奖箱(线程)设置线程名称分别为“抽奖箱1”,“抽奖箱2”
随机从抽奖池中获取奖项元素并打印在控制台上,格式如下:
每次抽的过程中,不打印,抽完时一次性打印(随机) 在此次抽奖过程中,抽奖箱1总共产生了6个奖项。
分别为:10,20,100,500,2,300最高奖项为300元,总计额为932元
在此次抽奖过程中,抽奖箱2总共产生了6个奖项。
分别为:5,50,200,800,80,700最高奖项为800元,总计额为1835元
*/
//创建奖池
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list,10,5,20,50,100,200,500,800,2,80,300,700);
//创建线程
MyThread t1 = new MyThread(list);
MyThread t2 = new MyThread(list);
//设置名字
t1.setName("抽奖箱1");
t2.setName("抽奖箱2");
//启动线程
t1.start();
t2.start();
}
}
25.10 Grupo de lotería de casos
1. Crea un hilo
public class MyCallable implements Callable<Integer> {
ArrayList<Integer> list;
public MyCallable(ArrayList<Integer> list) {
this.list = list;
}
@Override
public Integer call() throws Exception {
ArrayList<Integer> boxList = new ArrayList<>();//1 //2
while (true) {
synchronized (MyCallable.class) {
if (list.size() == 0) {
System.out.println(Thread.currentThread().getName() + boxList);
break;
} else {
//继续抽奖
Collections.shuffle(list);
int prize = list.remove(0);
boxList.add(prize);
}
}
Thread.sleep(10);
}
//把集合中的最大值返回
if(boxList.size() == 0){
return null;
}else{
return Collections.max(boxList);
}
}
}
ilustrar:
- El método shuffle(); de la clase de herramienta Colecciones se utiliza aquí para mezclar los datos de la colección.
- El método max en la clase de herramienta Colecciones se utiliza aquí para obtener el valor máximo en la colección.
2.Demostración
public class Test {
public static void main(String[] args) throws ExecutionException, InterruptedException {
/*
有一个抽奖池,该抽奖池中存放了奖励的金额,该抽奖池中的奖项为 {10,5,20,50,100,200,500,800,2,80,300,700};
创建两个抽奖箱(线程)设置线程名称分别为 "抽奖箱1", "抽奖箱2"
随机从抽奖池中获取奖项元素并打印在控制台上,格式如下:
在此次抽奖过程中,抽奖箱1总共产生了6个奖项,分别为:10,20,100,500,2,300
最高奖项为300元,总计额为932元
在此次抽奖过程中,抽奖箱2总共产生了6个奖项,分别为:5,50,200,800,80,700
最高奖项为800元,总计额为1835元
在此次抽奖过程中,抽奖箱2中产生了最大奖项,该奖项金额为800元
核心逻辑:获取线程抽奖的最大值(看成是线程运行的结果)
以上打印效果只是数据模拟,实际代码运行的效果会有差异
*/
//创建奖池
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list,10,5,20,50,100,200,500,800,2,80,300,700);
//创建多线程要运行的参数对象
MyCallable mc = new MyCallable(list);
//创建多线程运行结果的管理者对象
//线程一
FutureTask<Integer> ft1 = new FutureTask<>(mc);
//线程二
FutureTask<Integer> ft2 = new FutureTask<>(mc);
//创建线程对象
Thread t1 = new Thread(ft1);
Thread t2 = new Thread(ft2);
//设置名字
t1.setName("抽奖箱1");
t2.setName("抽奖箱2");
//开启线程
t1.start();
t2.start();
Integer max1 = ft1.get();
Integer max2 = ft2.get();
System.out.println(max1);
System.out.println(max2);
//在此次抽奖过程中,抽奖箱2中产生了最大奖项,该奖项金额为800元
if(max1 == null){
System.out.println("在此次抽奖过程中,抽奖箱2中产生了最大奖项,该奖项金额为"+max2+"元");
}else if(max2 == null){
System.out.println("在此次抽奖过程中,抽奖箱1中产生了最大奖项,该奖项金额为"+max1+"元");
}else if(max1 > max2){
System.out.println("在此次抽奖过程中,抽奖箱1中产生了最大奖项,该奖项金额为"+max1+"元");
}else if(max1 < max2){
System.out.println("在此次抽奖过程中,抽奖箱2中产生了最大奖项,该奖项金额为"+max2+"元");
}else{
System.out.println("两者的最大奖项是一样的");
}
}
}
Grupo de subprocesos 25.11
Resumen de notas:
El grupo de subprocesos es un mecanismo para implementar subprocesos múltiples . Puede crear una cierta cantidad de subprocesos cuando se inicia la aplicación . Una vez procesada la tarea, los subprocesos no destruirán.
// 1.创建一个默认的线程池对象.池子中默认是空的.默认最多可以容纳int类型的最大值. ExecutorService executorService = Executors.newCachedThreadPool();//Executors --- 可以帮助我们创建线程池对象 // 2.ExecutorService --- 可以帮助我们控制线程池 executorService.submit(()->{ System.out.println(Thread.currentThread().getName() + "在执行了"); }); // 3.销毁线程池 executorService.shutdown();
25.11.1 Descripción general
25.11.1.1 Significado
En Java, el grupo de subprocesos es un mecanismo para implementar subprocesos múltiples . Puede crear una cierta cantidad de subprocesos cuando se inicia la aplicación y guardarlos en el grupo de subprocesos. Luego, cuando es necesario procesar una tarea, se saca un subproceso inactivo del grupo de subprocesos para procesar la tarea. Una vez procesada la tarea, el hilo no está bloqueado, destrúyalo, pero regrese al grupo de hilos y espere la llegada de la siguiente tarea
25.11.1.2 Principios básicos principales

25.11.1.3 Ventajas
- Mejore el rendimiento del sistema: el grupo de subprocesos puede controlar automáticamente la cantidad de subprocesos en función de la situación real de los recursos del sistema, haciendo un mejor uso de los recursos de CPU y memoria del sistema, mejorando así el rendimiento del sistema.
- Mejore la reutilización de subprocesos: los subprocesos en el grupo de subprocesos se pueden reutilizar, lo que puede evitar la sobrecarga causada por la creación y destrucción de subprocesos, mejorando así la reutilización de subprocesos.
- Mejore la capacidad de administración de subprocesos: los subprocesos en el grupo de subprocesos se pueden administrar de manera uniforme y la cantidad de subprocesos se puede controlar configurando parámetros para evitar recursos insuficientes del sistema causados por demasiados subprocesos.
- Mejore la confiabilidad del programa: el grupo de subprocesos puede crear nuevos subprocesos según sea necesario y los subprocesos en el grupo de subprocesos pueden recuperarse automáticamente para evitar que todo el programa falle debido a un bloqueo de subprocesos.
25.11.2 Casos de uso básicos
package com.itheima.mythreadpool;
//static ExecutorService newCachedThreadPool() 创建一个默认的线程池
//static newFixedThreadPool(int nThreads) 创建一个指定最多线程数量的线程池
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class MyThreadPoolDemo {
public static void main(String[] args) throws InterruptedException {
//1,创建一个默认的线程池对象.池子中默认是空的.默认最多可以容纳int类型的最大值.
ExecutorService executorService = Executors.newCachedThreadPool();
//Executors --- 可以帮助我们创建线程池对象
//ExecutorService --- 可以帮助我们控制线程池
executorService.submit(()->{
System.out.println(Thread.currentThread().getName() + "在执行了");
});
//Thread.sleep(2000);
executorService.submit(()->{
System.out.println(Thread.currentThread().getName() + "在执行了");
});
//销毁线程池
executorService.shutdown();
}
}
ilustrar:
Aquí se utiliza el método de la clase de herramienta Executors.
- Obtener el método estático newCachedThreadPool() del objeto
- Enviar método de miembro de tarea enviar()
- Método Shudown() para cerrar el grupo de subprocesos
25.12 Grupo de subprocesos personalizados
Resumen de notas:
Objeto de grupo de subprocesos personalizado: nuevo
ThreadPoolExecutorobjetoThreadPoolExecutor pool = new ThreadPoolExecutor( 3, //核心线程数量,能小于0 6, //最大线程数,不能小于0,最大数量 >= 核心线程数量 60,//空闲线程最大存活时间 TimeUnit.SECONDS,//时间单位 new ArrayBlockingQueue<>(3),//任务队列 Executors.defaultThreadFactory(),//创建线程工厂 new ThreadPoolExecutor.AbortPolicy()//任务的拒绝策略 );
25.12.1 Descripción general
En Java, puede administrar la cantidad de subprocesos en el grupo de subprocesos, el modo de ejecución de los subprocesos, etc. personalizando el objeto del grupo de subprocesos . El proceso de creación de objetos de grupo de subprocesos personalizados debe ThreadPoolExecutorimplementarse mediante clases.
25.12.2 Método de construcción
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
corePoolSize: La cantidad de subprocesos mantenidos en el grupo de subprocesos , que no se destruirán incluso si el subproceso está inactivo.maximumPoolSize: El número máximo de subprocesos permitidos en el grupo de subprocesos . Cuando el número de subprocesos en el grupo de subprocesos alcance este valor, las tareas posteriores se bloquearán.keepAliveTime: El tiempo de supervivencia de los subprocesos inactivos en el grupo de subprocesos .unit: La unidad de tiempokeepAliveTimedel parámetro .workQueue: Cola de tareas en el grupo de subprocesos .threadFactory: Crea un objeto de fábrica para subprocesos .handler: Estrategia de rechazo , cómo manejar nuevas tareas cuando la cola de tareas está llena y ya no puede aceptar nuevas tareas.

25.12.3 Casos de uso básicos
ThreadPoolExecutor pool = new ThreadPoolExecutor(
3, //核心线程数量,能小于0
6, //最大线程数,不能小于0,最大数量 >= 核心线程数量
60,//空闲线程最大存活时间
TimeUnit.SECONDS,//时间单位
new ArrayBlockingQueue<>(3),//任务队列
Executors.defaultThreadFactory(),//创建线程工厂
new ThreadPoolExecutor.AbortPolicy()//任务的拒绝策略
);
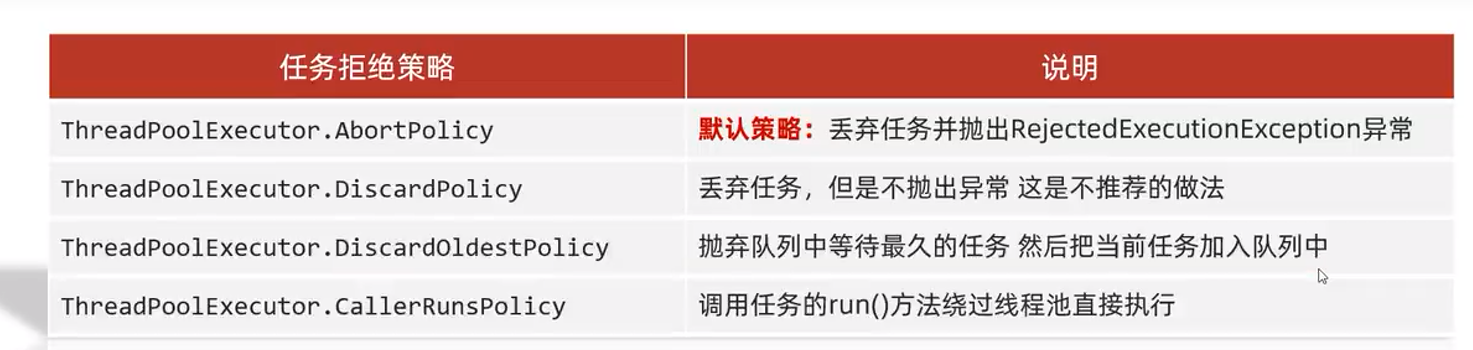
25.12.4 Política de denegación
25.13 Preguntas frecuentes sobre hilos
Resumen de notas:
- Paralelismo máximo: el paralelismo máximo se refiere al número máximo de subprocesos o tareas que se ejecutan al mismo tiempo.
- Tamaño del grupo de subprocesos: ajuste el tamaño inicial del grupo de subprocesos correspondiente de acuerdo con el rendimiento del hardware de la máquina de implementación , como CPU, memoria, etc.
- Conocimiento ampliado: este capítulo no ampliará ni ampliará el contenido de este capítulo, ¡se agregará en el futuro!
25.13.1 Número máximo de paralelismo
25.13.1.1 Descripción general
El paralelismo máximo se refiere al número máximo de subprocesos o tareas que se ejecutan simultáneamente
25.13.1.2 Casos de uso básicos
public class MyThreadPoolDemo2 {
public static void main(String[] args) {
//向Java虚拟机返回可用处理器的数目
int count = Runtime.getRuntime().availableProcessors();
System.out.println(count);
}
}
ilustrar:
Obtenga la cantidad de procesadores permitidos actualmente en el entorno
25.13.2 Tamaño del grupo de subprocesos

25.13.3 Conocimiento ampliado adicional del grupo de subprocesos

ilustrar:
Este capítulo no ampliará ni ampliará el contenido de esta dama. ¡Se agregará en el futuro!
25.13 Herramientas
Resumen de notas:
Descripción general: el subproceso múltiple generalmente usa la clase de herramienta Ejecutores para crear y usar grupos de subprocesos
25.13.1 Descripción general
clase de ejecutores
Ejecutores: la clase de herramienta del grupo de subprocesos devuelve diferentes tipos de objetos del grupo de subprocesos llamando a métodos.
25.13.2 Método de construcción

26.Programación de red
Resumen de notas:
- Descripción general:
- Definición: La programación de red permite la transmisión de datos y la comunicación entre diferentes computadoras a través de la red , permitiendo que las computadoras remotas interactúen entre sí y compartan información .
- Arquitectura de software: B/S, C/S
- Tres elementos de programación: IP, puerto, protocolo.
InetAddressamable:
- Descripción general: una clase que representa una dirección de red . Proporciona un conjunto de métodos para obtener nombres de host y direcciones IP y resolver nombres de dominio en direcciones IP.
- Métodos de miembros comunes: getByName, getHostName, getHostAddress
- Programa de comunicación UDP:
- Descripción general: el protocolo UDP es un protocolo de red poco confiable
- Método de construcción:
new DatagramSocket()- Métodos de miembros comunes: enviar, recibir, cerrar, obtener datos
- Implementación de multidifusión y transmisión: simplemente entiéndalo y profundice más cuando lo use
- Programa de comunicación TCP:
- Descripción general: el protocolo TCP es un protocolo de red confiable con protocolo de enlace de tres vías y garantía de comunicación de ondas de cuatro vías .
- Método de construcción:
new Socket()- Métodos de miembros comunes: aceptar, getInputStream, cerrar
26.1 Descripción general
26.1.1 Definición
En Java, la programación de red se refiere al proceso de utilizar el lenguaje de programación Java y bibliotecas de clases relacionadas para implementar la comunicación de red. La programación en red permite la transmisión de datos y la comunicación entre diferentes computadoras a través de la red , permitiendo que las computadoras remotas interactúen entre sí y compartan información.
Según el protocolo de comunicación de red, los programas que se ejecutan en diferentes computadoras pueden transmitir datos.
26.1.2 Arquitectura del software
La arquitectura del software se divide en B/S y C/S.

Ventajas y desventajas de la arquitectura BS/CS
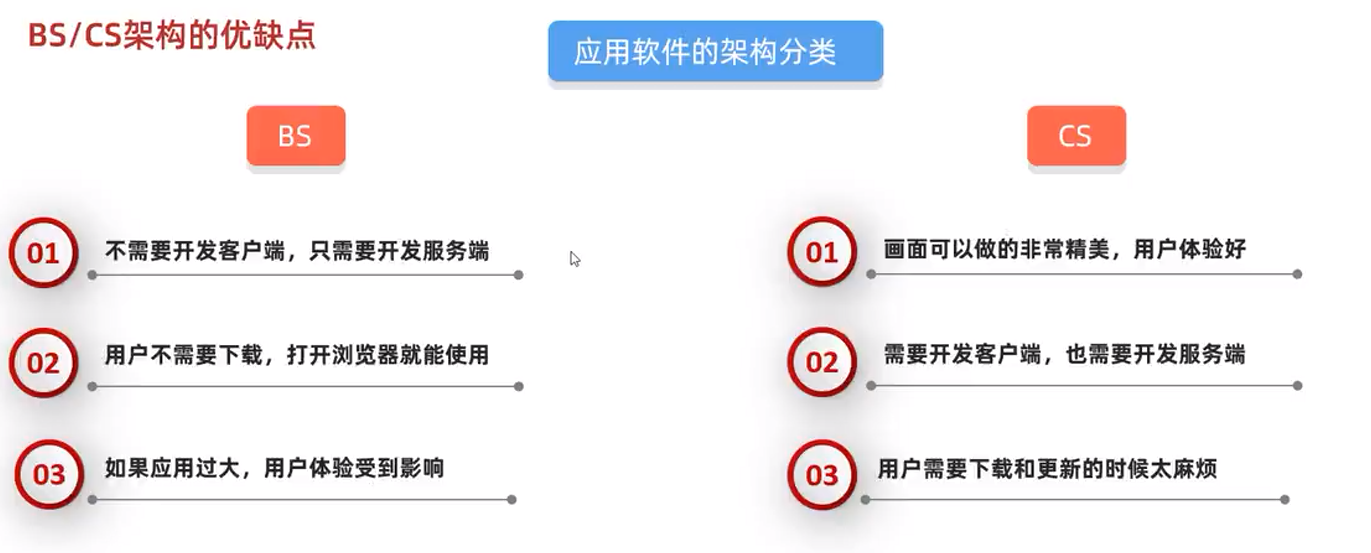
26.1.3 Tres elementos de la programación de la red

26.2Clase InetAddress
26.2.1 Descripción general
InetAddress es una clase utilizada para representar direcciones de red en Java. Proporciona un conjunto de métodos para obtener nombres de host y direcciones IP y resolver nombres de dominio en direcciones IP.
26.2.2 Métodos de miembros comunes
| nombre del método | ilustrar |
|---|---|
| Dirección Inet estática getByName (host de cadena) | Determine la dirección IP del nombre de host. El nombre del host puede ser el nombre de una máquina o una dirección IP. |
| Cadena getHostName() | Obtenga el nombre de host de esta dirección IP |
| Cadena getHostAddress() | Devuelve la cadena de dirección IP en la pantalla de texto. |
26.2.3 Caso - Obtener información básica
public class InetAddressDemo {
public static void main(String[] args) throws UnknownHostException {
//InetAddress address = InetAddress.getByName("itheima");
InetAddress address = InetAddress.getByName("192.168.1.66");
//public String getHostName():获取此IP地址的主机名
String name = address.getHostName();
//public String getHostAddress():返回文本显示中的IP地址字符串
String ip = address.getHostAddress();
System.out.println("主机名:" + name);
System.out.println("IP地址:" + ip);
}
}
Programa de comunicación 26.3UDP
26.3.1 Descripción general
26.3.1.1 Definición
El protocolo UDP es un protocolo de red poco confiable. Establece un objeto Socket en cada extremo de la comunicación. Sin embargo, estos dos Sockets son solo objetos para enviar y recibir datos. Por lo tanto, para ambas partes que se comunican según el protocolo UDP, no No importa El concepto de cliente y servidor.
Java proporciona la clase DatagramSocket como un Socket basado en el protocolo UDP
26.3.1.2UDP tres métodos de comunicación
-
Unidifusión
Unicast se utiliza para la comunicación de un extremo a otro entre dos hosts.
-
multidifusión
La multidifusión se utiliza para comunicarse con un grupo específico de hosts.
-
transmisión
La transmisión se utiliza para la comunicación de datos desde un host a todos los hosts en toda la LAN.

26.3.2 Método de construcción
| nombre del método | ilustrar |
|---|---|
| DatagramaSocket() | Crea un socket de datagrama y lo vincula a cualquier puerto disponible en la dirección de la máquina local |
| Paquete de datagramas (byte [] buf, int len) | Cree un DatagramPacket para recibir paquetes de longitud len |
| DatagramPacket (byte [] buf, int len, InetAddress add, int puerto) | Cree un paquete de datos y envíe un paquete de datos con una longitud de len al puerto especificado del host especificado |
detalle:
- Construcción de parámetros vacíos: use uno aleatorio de todos los puertos disponibles
- Construcción parametrizada: especifique el número de puerto para el enlace
26.3.3 Métodos de miembros comunes
| nombre del método | ilustrar |
|---|---|
| envío nulo (DatagramPacket p) | enviar paquete de datagramas |
| cierre vacío() | Cerrar el socket de datagrama |
| recepción nula (DatagramPacket p) | Aceptar paquetes de datagramas de este socket |
| byte[] obtenerDatos() | Búfer de datos de retorno |
| int obtenerLongitud() | Devuelve la longitud de los datos a enviar o la longitud de los datos a recibir |
26.3.4 Caso de uso básico: envío de datos
paso:
- Cree el objeto Socket (DatagramSocket) del extremo emisor: cree una empresa de mensajería
- Crear datos y empaquetar los datos – Crear paquete
- 调用DatagramSocket对象的send方法发送数据–快递公司发送数据
- 调用DatagramSocket对象的close方法释放资源–摧毁快递公司
public class SendMessageDemo {
public static void main(String[] args) throws IOException {
//发送数据
//1.创建DatagramSocket对象(快递公司)
//细节:
//绑定端口,以后我们就是通过这个端口往外发送
//空参:所有可用的端口中随机一个进行使用
//有参:指定端口号进行绑定
DatagramSocket ds = new DatagramSocket();
//2.打包数据
String str = "你好威啊!!!";
byte[] bytes = str.getBytes();
InetAddress address = InetAddress.getByName("127.0.0.1");
int port = 10086;
DatagramPacket dp = new DatagramPacket(bytes,bytes.length,address,port);
//3.发送数据
ds.send(dp);
//4.释放资源
ds.close();
}
}
说明:
- 在创建DatagramSocket时,指定的端口号是发送方端口号
- 在创建DatagramPacket时,指定的端口号是接收方端口号
26.3.5基本用例-接收数据
步骤:
- 创建接收端的Socket对象(DatagramSocket)–创建快递公司
- 创建一个数据包,用于接收数据–创建空包裹
- 调用DatagramSocket对象的receive方法接收数据–快递公司接收数据
- 解析数据包,并把数据在控制台显示–拆包裹
- 调用DatagramSocket对象的close方法释放资源–摧毁快递公司
public class ReceiveMessageDemo {
public static void main(String[] args) throws IOException {
//接收数据
//1.创建DatagramSocket对象(快递公司)
//细节:
//在接收的时候,一定要绑定端口
//而且绑定的端口一定要跟发送的端口保持一致
DatagramSocket ds = new DatagramSocket(10086);
//2.接收数据包
byte[] bytes = new byte[1024];
DatagramPacket dp = new DatagramPacket(bytes,bytes.length);
//该方法是阻塞的
//程序执行到这一步的时候,会在这里死等
//等发送端发送消息
System.out.println(11111);
ds.receive(dp);
System.out.println(2222);
//3.解析数据包
byte[] data = dp.getData();
int len = dp.getLength();
InetAddress address = dp.getAddress();
int port = dp.getPort();
System.out.println("接收到数据" + new String(data,0,len));
System.out.println("该数据是从" + address + "这台电脑中的" + port + "这个端口发出的");
//4.释放资源
ds.close();
}
}
注意:
- 在创建DatagramSocket时,指定的端口号是接收方端口号,注意此端口号需要跟发送的端口号保持一致
- 在创建DatagramPacket时,无需指定IP地址或者端口号,只需要创建空包裹即可
26.3.6案例-UDP组播实现
26.3.6.1基本用例-发送数据
// 发送端
public class ClinetDemo {
public static void main(String[] args) throws IOException {
// 1. 创建发送端的Socket对象(DatagramSocket)
DatagramSocket ds = new DatagramSocket();
String s = "hello 组播";
byte[] bytes = s.getBytes();
InetAddress address = InetAddress.getByName("224.0.1.0");
int port = 10000;
// 2. 创建数据,并把数据打包(DatagramPacket)
DatagramPacket dp = new DatagramPacket(bytes,bytes.length,address,port);
// 3. 调用DatagramSocket对象的方法发送数据(在单播中,这里是发给指定IP的电脑但是在组播当中,这里是发给组播地址)
ds.send(dp);
// 4. 释放资源
ds.close();
}
}
细节:
在发送数据时,创建的包裹指定IP,需要填写指定组播的地址
26.3.6.2基本用例-接收数据
// 接收端
public class ServerDemo {
public static void main(String[] args) throws IOException {
// 1. 创建接收端Socket对象(MulticastSocket)
MulticastSocket ms = new MulticastSocket(10000);
// 2. 创建一个箱子,用于接收数据
DatagramPacket dp = new DatagramPacket(new byte[1024],1024);
// 3. 把当前计算机绑定一个组播地址,表示添加到这一组中.
ms.joinGroup(InetAddress.getByName("224.0.1.0"));
// 4. 将数据接收到箱子中
ms.receive(dp);
// 5. 解析数据包,并打印数据
byte[] data = dp.getData();
int length = dp.getLength();
System.out.println(new String(data,0,length));
// 6. 释放资源
ms.close();
}
}
细节:
需要把当前计算机绑定一个组播地址,表示添加到这一组中
26.3.7案例UDP广播实现
26.3.7.1基本用例-发送数据
// 发送端
public class ClientDemo {
public static void main(String[] args) throws IOException {
// 1. 创建发送端Socket对象(DatagramSocket)
DatagramSocket ds = new DatagramSocket();
// 2. 创建存储数据的箱子,将广播地址封装进去
String s = "广播 hello";
byte[] bytes = s.getBytes();
InetAddress address = InetAddress.getByName("255.255.255.255");
int port = 10000;
DatagramPacket dp = new DatagramPacket(bytes,bytes.length,address,port);
// 3. 发送数据
ds.send(dp);
// 4. 释放资源
ds.close();
}
}
细节:
发送数据,发送IP指定为 255.255.255.255
26.3.7.2基本用例-接收数据
// 接收端
public class ServerDemo {
public static void main(String[] args) throws IOException {
// 1. 创建接收端的Socket对象(DatagramSocket)
DatagramSocket ds = new DatagramSocket(10000);
// 2. 创建一个数据包,用于接收数据
DatagramPacket dp = new DatagramPacket(new byte[1024],1024);
// 3. 调用DatagramSocket对象的方法接收数据
ds.receive(dp);
// 4. 解析数据包,并把数据在控制台显示
byte[] data = dp.getData();
int length = dp.getLength();
System.out.println(new String(data,0,length));
// 5. 关闭接收端
ds.close();
}
}
26.4TCP通信程序
26.4.1概述
26.4.1.1定义
Java中的TCP通信程序是一种基于Socket套接字的网络通信方式,其中客户端和服务器通过TCP协议进行数据的传输和交互

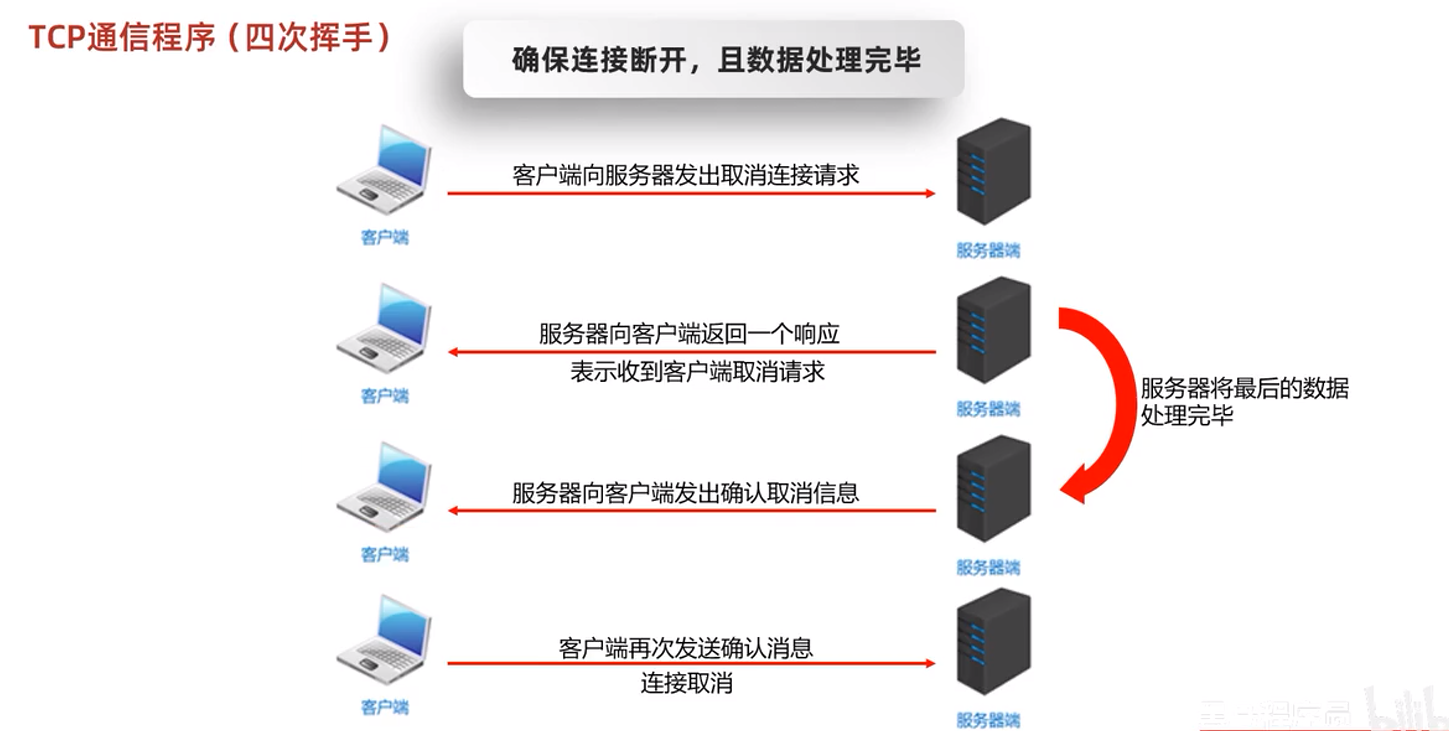
在Socket进行发送与读取数据时,在底层会进行三次握手与四次挥手的协议,确保所传输的数据是能够被正常接收到
26.4.1.2三次握手
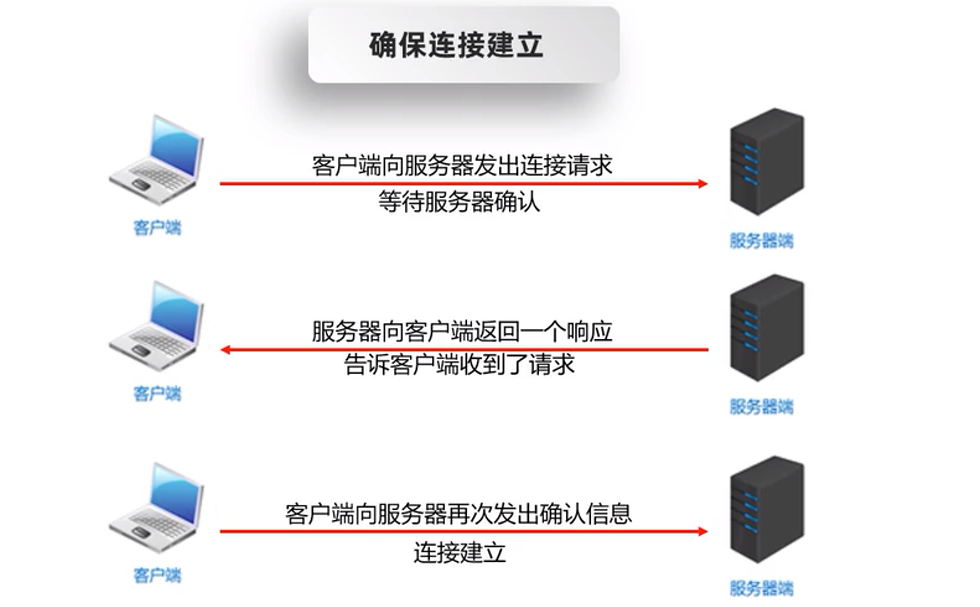
26.4.1.3四次挥手
26.4.2基本用例-发送数据
public class Client {
public static void main(String[] args) throws IOException {
//TCP协议,发送数据
//1.创建Socket对象
//细节:在创建对象的同时会连接服务端
// 如果连接不上,代码会报错
Socket socket = new Socket("127.0.0.1",10000);
//2.可以从连接通道中获取输出流
OutputStream os = socket.getOutputStream();
//写出数据
os.write("aaa".getBytes());
//3.释放资源
os.close();
socket.close();
}
}
26.4.3基本用例-接收数据
public class Server {
public static void main(String[] args) throws IOException {
//TCP协议,接收数据
//1.创建对象ServerSocker
ServerSocket ss = new ServerSocket(10000);
//2.监听客户端的链接
Socket socket = ss.accept();
//3.从连接通道中获取输入流读取数据
InputStream is = socket.getInputStream();
// InputStreamReader isr = new InputStreamReader(is);
// BufferedReader br = new BufferedReader(isr); // 将字符输入流用缓冲字符输入流进行读取,可加快读取的速度
int b;
while ((b = is.read()) != -1){
System.out.println((char) b);
}
//4.释放资源
socket.close();
ss.close();
}
}
细节:
在接收中文数据时,会产生中文乱码,是由于IDEA平台默认使用UTF-8的编码方式。InputStream在读取字节流时默认是用一个字节一个字节的读,而不能根据编码表的方式进行读取。因此,使用字符流可以根据编码进行读取,解决中文乱码。
27.反射
笔记小结:
- 概述:反射允许对封装类的字段,方法和构造函数的信息进行编程访问。
- 作用:可以结合配置文件,动态的创建对象并调用方法,就像Java设计模式中的工程模式创建就会运用
- 获取构造方法:getDeclaredConstructors()、getConstructors()
- 获取成员变量:getDeclaredFields()、getFields()
- 获取成员方法:getDeclaredMethods()、getMethods()
27.1概述
27.1.1定义
反射允许对封装类的字段,方法和构造函数的信息进行编程访问
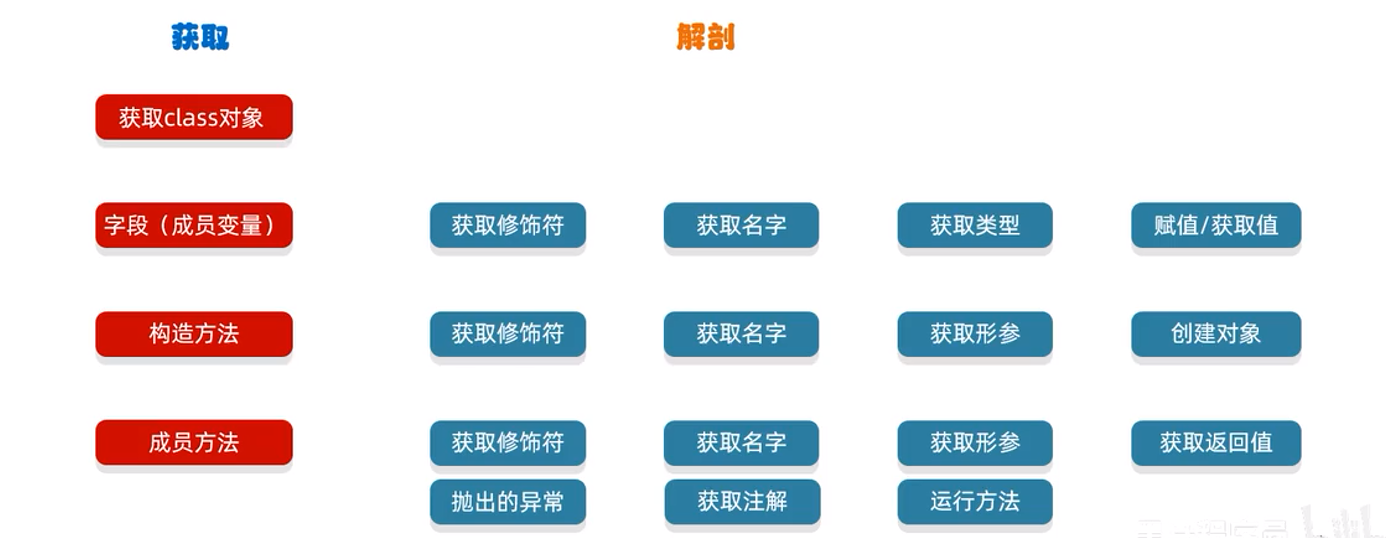
27.1.2作用
- 获取一个类里面所有的信息,获取到了之后,再执行其他的业务逻辑
- 结合配置文件,动态的创建对象并调用方法
27.2获取字节码方式
27.2.1概述
三种方式:
- Class这个类里面的静态方法forName(“全类名”)(最常用)
- 通过class属性获取
- 通过对象获取字节码文件对象

27.2.2基本用例-获取字节码
//1. 第一种方式
//全类名 : 包名 + 类名
//最为常用的
Class clazz1 = Class.forName("com.itheima.myreflect1.Student");
//2. 第二种方式
//一般更多的是当做参数进行传递
Class clazz2 = Student.class;
//3.第三种方式
//当我们已经有了这个类的对象时,才可以使用。
Student s = new Student();
Class clazz3 = s.getClass();
说明:
第一种方式Class.forName(“xxx”)的方式是常用方式
27.3获取构造方法
27.3.1概述
| 方法名 | 说明 |
|---|---|
| Constructor<?>[] getConstructors() | 获得所有的构造(只能public修饰) |
| Constructor<?>[] getDeclaredConstructors() | 获得所有的构造(包含private修饰) |
| Constructor getConstructor(Class<?>… parameterTypes) | 获取指定构造(只能public修饰) |
| Constructor getDeclaredConstructor(Class<?>… parameterTypes) | 获取指定构造(包含private修饰 |
说明:
获取构造方法名称解析,get获取,Constructors表示构造方法,Declared表示所有权限,s表示多个
常用成员方法
| 方法名 | 说明 |
|---|---|
getModifiers |
获取修饰符。返回表示该成员或构造函数的Java语言修饰符的整数。可以使用 Modifier 类来解码这个整数中包含的修饰符。 |
getParameters |
获取此方法的形式参数。返回一个包含 Parameter 对象的数组,每个 Parameter 对象描述一个参数。如果该方法没有参数,则返回长度为 0 的数组。 |
setAccessible |
将此对象的可访问标志设置为指示的布尔值。值为 true 表示反射对象在使用时应该取消 Java 语言访问检查。 |
27.3.2基本用例-获取构造方法
//1.获得整体(class字节码文件对象)
Class clazz = Class.forName("com.itheima.reflectdemo.Student");
//2.获取构造方法对象
//2.1获取所有构造方法(public)
Constructor[] constructors1 = clazz.getConstructors();
System.out.println("=======================");
//2.2获取所有构造(带私有的)
Constructor[] constructors2 = clazz.getDeclaredConstructors();
System.out.println("=======================");
//2.3获取指定的空参构造
Constructor con1 = clazz.getConstructor();
Constructor con2 = clazz.getConstructor(String.class,int.class);
System.out.println("=======================");
//2.4获取指定的构造(所有构造都可以获取到,包括public包括private)
Constructor con3 = clazz.getDeclaredConstructor();
//3.获取构造方法的权限修饰符
int modifiers = con3.getModifiers();
//4.获取构造方法的参数信息
Parameter[] parameters = con4.getParameters();
//5.暴力反射
con4.setAccessible(true);
Student stu = (Student) con4.newInstance("张三", 23);
说明:
当通过字节码文件,获取到Java中的构造方法后,可以更深入的获取构造方法的详细信息
27.4获取成员变量
27.4.1概述
| 方法名 | 说明 |
|---|---|
| Field[] getFields() | 返回所有成员变量对象的数组(只能拿public的) |
| Field[] getDeclaredFields() | 返回所有成员变量对象的数组,存在就能拿到 |
| Field getField(String name) | 返回单个成员变量对象(只能拿public的) |
| Field getDeclaredField(String name) | 返回单个成员变量对象,存在就能拿到 |
说明:
获取成员变量解析,get获取,Constructors表示构造方法,Declared表示所有权限,s表示多个
| 方法名称 | 说明 |
|---|---|
| getModifiers | 返回该方法的修饰符,如public、static、final等 |
| getName | 返回该方法的名称 |
| getType | 返回该方法参数类型的Class对象的数组 |
| setAccessible | 设置是否允许访问该方法,若设置为true,则可访问private修饰符的方法。 |
27.4.2基本用例-获取成员变量
//1.获取class字节码文件的对象
Class clazz = Class.forName("com.itheima.myreflect3.Student");
//2.获取成员变量
//2.1获取所有的成员变量
Field[] fields = clazz.getDeclaredFields();
//2.2获取单个的成员变量
Field name = clazz.getDeclaredField("name");
System.out.println(name);
//2.3获取权限修饰符
int modifiers = name.getModifiers();
System.out.println(modifiers);
//2.4获取成员变量的名字
String n = name.getName();
System.out.println(n);
//2.5获取成员变量的数据类型
Class<?> type = name.getType();
System.out.println(type);
//3.获取成员变量记录的值
Student s = new Student("zhangsan",23,"男");
name.setAccessible(true);
String value = (String) name.get(s);
System.out.println(value);
//4.修改对象里面记录的值
name.set(s,"lisi");
System.out.println(s);
说明:
可对获取到的成员变量进行更细一步的操作,例如获取变量修饰符、变量名、数据类型、变量值,修改变量值等
27.5获取成员方法
27.5.1概述
| 方法名 | 说明 |
|---|---|
| Method[] getMethods() | 返回所有成员方法对象的数组(只能拿public的) |
| Method[] getDeclaredMethods() | 返回所有成员方法对象的数组,存在就能拿到 |
| Method getMethod(String name, Class<?>… parameterTypes) | 返回单个成员方法对象(只能拿public的) |
| Method getDeclaredMethod(String name, Class<?>… parameterTypes) | 返回单个成员方法对象,存在就能拿到 |
说明:
获取成员方法解析,get获取,Constructors表示构造方法,Declared表示所有权限,s表示多个
| 方法名 | 说明 |
|---|---|
| getModifiers | 返回当前方法的修饰符的整数表示,修饰符包括public、private、protected、static、final等等 |
| getName | 返回当前方法的名称 |
| getParameters | 返回当前方法的参数列表,以Parameter数组形式返回 |
| getExceptionTypes | 返回当前方法抛出的异常类型数组 |
| invoke | 通过反射调用当前方法 |
27.5.2基本用例-获取成员方法
//1. 获取class字节码文件对象
Class clazz = Class.forName("com.itheima.myreflect4.Student");
//2.获取方法对象
//2.1获取里面所有的方法对象(包含父类中所有的公共方法)
Method[] methods = clazz.getMethods();
//2.2获取里面所有的方法对象(不能获取父类的,但是可以获取本类中私有的方法)
Method[] methods = clazz.getDeclaredMethods();
//2.3获取指定的单一方法
Method m = clazz.getDeclaredMethod("eat", String.class);
System.out.println(m);
//3.获取方法的修饰符
int modifiers = m.getModifiers();
System.out.println(modifiers);
//4.获取方法的名字
String name = m.getName();
System.out.println(name);
//5.获取方法的形参
Parameter[] parameters = m.getParameters();
//6.获取方法的抛出的异常
Class[] exceptionTypes = m.getExceptionTypes();
//7.方法运行
/*Method类中用于创建对象的方法
Object invoke(Object obj, Object... args):运行方法
参数一:用obj对象调用该方法
参数二:调用方法的传递的参数(如果没有就不写)
返回值:方法的返回值(如果没有就不写)*/
Student s = new Student();
m.setAccessible(true);
//参数一s:表示方法的调用者
//参数二"汉堡包":表示在调用方法的时候传递的实际参数
String result = (String) m.invoke(s, "汉堡包");
System.out.println(result);
28.动态代理
笔记小结:
- 概述:动态代理是一种机制,它允许在运行时创建一个代理对象,代理对象能够拦截并处理被代理对象的方法调用。跟IP的代理不一样,动态代理是用于增强被代理对象的功能
- 作用:代理可以无侵入式的给对象增强其他的功能
- 基本用例:使用
Proxy类提供的newProxyInstance方法,进行动态的代理
28.1概述
28.1.1定义
在 Java 中,动态代理是一种机制,它允许在运行时创建一个代理对象,代理对象能够拦截并处理被代理对象的方法调用
28.1.2作用
代理可以无侵入式的给对象增强其他的功能

补充:
通过接口保证,后面的对象和代理需要实现同一个接口,接口中就是被代理的所有方法
28.2基本用例
步骤一:创建接口
说明:
我们可以把所有想要被代理的方法定义在接口当中
public interface Star {
//唱歌
public abstract String sing(String name);
//跳舞
public abstract void dance();
}
说明:
此接口,需要各个被代理对象与代理,共同实现。目的是让代理能够调用被代理对象内的方法
步骤二:创建被代理对象
- 创建实体类
public class BigStar implements Star {
private String name;
public BigStar() {
}
public BigStar(String name) {
this.name = name;
}
//唱歌
@Override
public String sing(String name){
System.out.println(this.name + "正在唱" + name);
return "谢谢";
}
//跳舞
@Override
public void dance(){
System.out.println(this.name + "正在跳舞");
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
public String toString() {
return "BigStar{name = " + name + "}";
}
}
步骤三:创建代理
说明:
给一个明星的对象,创建一个代理
/*
* 类的作用:
* 创建一个代理
* */
public class ProxyUtil {
/*
* 方法的作用:
* 给一个明星的对象,创建一个代理
* 形参:
* 被代理的明星对象
* 返回值:
* 给明星创建的代理
* 需求:
* 外面的人想要大明星唱一首歌
* 1. 获取代理的对象
* 代理对象 = ProxyUtil.createProxy(大明星的对象);
* 2. 再调用代理的唱歌方法
* 代理对象.唱歌的方法("只因你太美");
* */
public static Star createProxy(BigStar bigStar){
/* java.lang.reflect.Proxy类:提供了为对象产生代理对象的方法:
public static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h)
参数一:用于指定用哪个类加载器,去加载生成的代理类
参数二:指定接口,这些接口用于指定生成的代理长什么,也就是有哪些方法
参数三:用来指定生成的代理对象要干什么事情*/
Star star = (Star) Proxy.newProxyInstance(
ProxyUtil.class.getClassLoader(),//参数一:用于指定用哪个类加载器,去加载生成的代理类
new Class[]{
Star.class},//参数二:指定接口,这些接口用于指定生成的代理长什么,也就是有哪些方法
//参数三:用来指定生成的代理对象要干什么事情
new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
/*
* 参数一:代理的对象
* 参数二:要运行的方法 sing
* 参数三:调用sing方法时,传递的实参
* */
if("sing".equals(method.getName())){
System.out.println("准备话筒,收钱");
}else if("dance".equals(method.getName())){
System.out.println("准备场地,收钱");
}
//去找大明星开始唱歌或者跳舞
//代码的表现形式:调用大明星里面唱歌或者跳舞的方法
return method.invoke(bigStar,args);
}
}
);
return star;
}
}
说明:
- 此代理对象,需要用到Proxy类中的newProxyInstance方法
public static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h)
步骤四:演示
public class Test {
public static void main(String[] args) {
/*
需求:
外面的人想要大明星唱一首歌
1. 获取代理的对象
代理对象 = ProxyUtil.createProxy(大明星的对象);
2. 再调用代理的唱歌方法
代理对象.唱歌的方法("只因你太美");
*/
//1. 获取代理的对象
BigStar bigStar = new BigStar("鸡哥");
Star proxy = ProxyUtil.createProxy(bigStar);
//2. 调用唱歌的方法
String result = proxy.sing("只因你太美");
System.out.println(result);
}
}
29.日志
笔记小结:
- 概述:日志技术,可以便于记录重要的信息,将这些详细信息保存到文件和数据库中
- 日志级别:TRACE < DEBUG < INFO < WARN < ERROR
- 补充:@Sf4j注解也可以输出到本地,详细请参考springboot项目使用slf4j控制台输出日志+输出日志文件到本地_org.slf4j.loggerfactory 日志路径_余额一个亿的博客-CSDN博客
29.1概述
29.1.1定义
在Java中,日志在合适的时候加入,用于记录重要的信息。便于运维进行管理
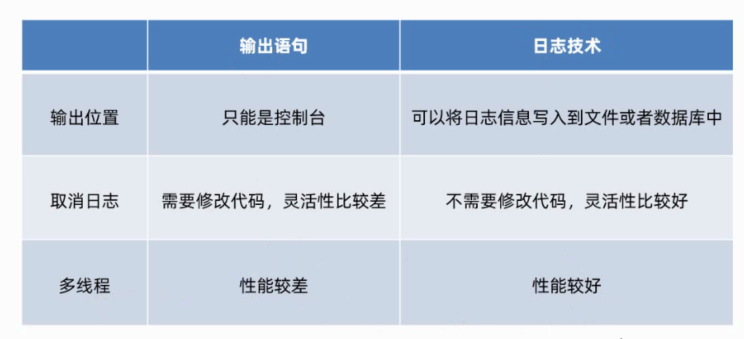
29.1.2作用
- 跟输出语句一样,可以把程序在运行过程中的详细信息都打印在控制台上
- 利用log日志还可以把这些详细信息保存到文件和数据库中
29.1.3日志级别
TRACE, DEBUG, INFO, WARN, ERROR
日志级别从小到大的关系:
TRACE < DEBUG < INFO < WARN < ERROR
29.1.4体系结构
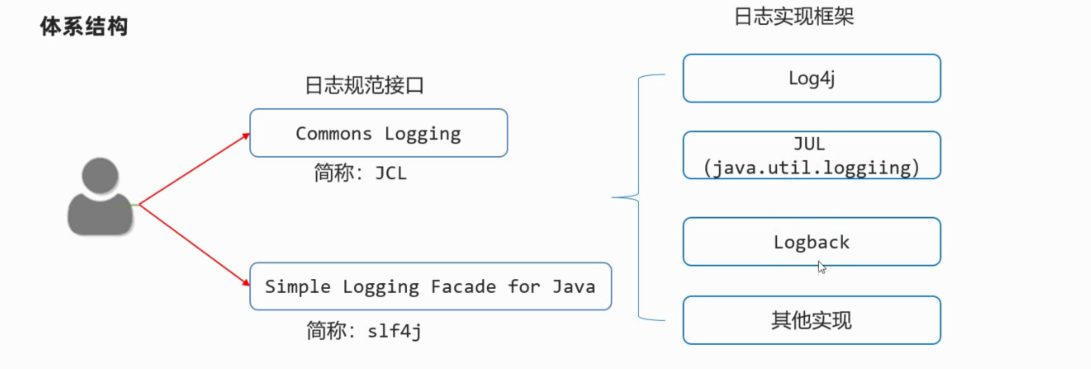
- 日志规范:一些接口,提供给日志的实现框架设计的标准
- 日志框架:牛人或者第三方公司已经做好的日志记录实现代码,后来者直接可以拿去使用
29.2Logback日志框架
29.2.1概述
Logback是基于slf4j的日志规范实现的框架,性能比之前使用的log4j要好
说明:
官方网站:https://logback.qos.ch/index.html
29.2.2模块
Logback主要分为三个技术模块:
- logback-core:该模块为其他两个模块提供基础代码,必须有。
- logback-classic:完整实现了slf4j API的模块。
- logback-access模块与Tomcat和Jetty 等Servlet容器集成,以提供HTTP 访问日志功能
29.3Logback基本用例
步骤一:导入jar包,并添加依赖库

步骤二:将Logback的核心配置文件logback.xml直接拷贝到src目录下(必须是src下)
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!--
CONSOLE :表示当前的日志信息是可以输出到控制台的。
-->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<!--输出流对象 默认 System.out 改为 System.err-->
<target>System.out</target>
<encoder>
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度
%msg:日志消息,%n是换行符-->
<pattern>%d{
yyyy-MM-dd HH:mm:ss.SSS} [%-5level] %c [%thread] : %msg%n</pattern>
</encoder>
</appender>
<!-- File是输出的方向通向文件的 -->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<encoder>
<pattern>%d{
yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{
36} - %msg%n</pattern>
<charset>utf-8</charset>
</encoder>
<!--日志输出路径-->
<file>C:/code/itheima-data.log</file>
<!--指定日志文件拆分和压缩规则-->
<rollingPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!--通过指定压缩文件名称,来确定分割文件方式-->
<fileNamePattern>C:/code/itheima-data2-%d{
yyyy-MMdd}.log%i.gz</fileNamePattern>
<!--文件拆分大小-->
<maxFileSize>1MB</maxFileSize>
</rollingPolicy>
</appender>
<!--
level:用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL 和 OFF
, 默认debug
<root>可以包含零个或多个<appender-ref>元素,标识这个输出位置将会被本日志级别控制。
-->
<root level="info">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="FILE" />
</root>
</configuration>
步骤三:在代码中获取日志的对象
public static final Logger LOGGER= LoggerFactory.getLdgger("类对象");
步骤四:使用日志对象的方法记录系统的日志信息
29.4Logback配置文件
Logback日志输出位置、格式设置:
- 通过logback.xml中的标签可以设置输出位置和日志信息的详细格式。
- 通常可以设置2个日志输定位置:一个是控制台、一个是系统文件中
输出到控制台的配置标志:
<appender name="CONSOLE" class="ch.qos.logback.core.consoleAppender">
输出到系统文件的配置标志:
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"">
30.注解
笔记小结:
概述:在Java中,注解(Annotation)是一种元数据机制,它允许在源代码、编译时以及运行时为程序元素(类、方法、字段等)添加信息、标记和说明
常用注解:@Override:表示方法的重写、@Deprecated:表示修饰的方法已过时、@SuppressWarnings(“all”):压制警告
自定义注解:
说明:自己编写注解,通常来说与反射一并使用。
// 定义格式 public @interface 注解名称{ public 属性类型 属性名() default 默认值; }元注解:
- @Retention:用来标识注解的生命周期(有效范围)
- @Target:用来标识注解使用的位置
30.1概述
30.1.1定义
在Java中,注解(Annotation)是一种元数据机制,它允许在源代码、编译时以及运行时为程序元素(类、方法、字段等)添加信息、标记和说明。注解可以帮助开发人员在代码中添加关键信息,以便在后续的编译、构建、部署和运行过程中使用
@RestController
@RequestMapping("order")
public @interface MyAnnotation {
String value();
int priority() default 0;
}
说明:
以
@开头的代码行即为注解
30.1.2作用
Java的注解通过**@符号**来表示,紧接着是注解的名称。注解可以附加到类、方法、字段、参数等程序元素上,以提供额外的元数据。注解的元数据信息可以被编译器、工具和运行时框架使用,用于自动生成代码、配置应用程序行为,以及实现一些特定的功能
30.1.3注释和注解的区别
-
共同点:都可以对程序进行解释说明
-
不同点:注释,是给程序员看的。只在Java中有效。在class文件中不存在注释的
说明:
- 当编译之后,会进行注释擦除
- 注解,是给虚拟机看的。当虚拟机看到注解之后,就知道要做什么事情了
30.2基本用例
说明:
注解的一般使用
步骤一:认识注解
@Override
说明:
明白这个注解的作用。在以前看过注解@Override,当子类重写父类方法的时候,在重写的方法上面写@Override。当虚拟机看到@Override的时候,就知道下面的方法是重写的父类的。检查语法,如果语法正确编译正常,如果语法错误,就会报错。
步骤二:添加注解
@Override
public PageResult search(GlobalSearchDTO requestParams) {
……
}
说明:
注解通常添加在类中的方法上
补充:
也有添加在
@interface注解之上的,这个叫源注解
30.3常用注解
JVM提供的注解:
-
@Override:表示方法的重写
-
@Deprecated:表示修饰的方法已过时
-
@SuppressWarnings(“all”):压制警告
第三方框架注解
- Junit:
- @Test 表示运行测试方法
- @Before 表示在Test之前运行,进行数据的初始化
- @After 表示在Test之后运行,进行数据的还原
30.4自定义注解
30.4.1概述
自定义注解就是自己做一个注解来使用。自定义注解单独存在是没有什么意义的,一般会跟反射结合起来使用,会用发射去解析注解。
注意:
JVM不会对自定义的注解添加任何逻辑,怎样处理完全由Java代码决定。也就是说光定义了注解是不足以使用的,需要通过反射等手法来实现实现注解的逻辑
30.4.2基本用例
说明:
- 定义注解格式
public @interface 注解名称{ public 属性类型 属性名() default 默认值; }
- 属性类型可以为:基本数据类型、String、Class、注解等
- 使用注解格式
@注解名称(属性名1 = 值1,属性名2 = 值2)
- 使用自定义注解时要保证注解每个属性都有值。注解可以使用默认值
步骤一:定义注解
public @interface Annotation {
public abstract String value();
}
步骤二:使用注解
@Annotation(value = "")
private int myField;
说明:
- value属性,如果只有一个value属性的情况下,使用value属性的时候可以省略value名称不写
- 但是加里右多个属性日多个属性沿右默认值,那么value名称是不能省略的
步骤三:获取注解
public class MyClass implements MyInterface {
@Annotation("My Class")
private int myField;
@Override
public void myMethod() {
}
public static void main(String[] args) throws NoSuchFieldException, NoSuchMethodException {
// 1.获取成员变量
Field field = MyClass.class.getDeclaredField("myField");
// 2.获取成员变量上的注解
Annotation annotation = field.getAnnotation(Annotation.class);
// 3.获取该成员变量注解上的值
System.out.println(annotation.value());
}
}
补充:获取方法上的注解
Method method = MyClass.class.getMethod("myMethod"); MyAnnotation annotation = method.getAnnotation(MyAnnotation.class); System.out.println(annotation.value());
30.5元注解
30.5.1概述
在Java中,元注解(Meta-annotation)是用于注解其他注解的注解,也就是说,元注解用于对其他注解进行注解。元注解为开发者提供了定义和控制注解行为的能力,可以影响注解在代码中的使用和解释方式
简单的说,就是写在注解上的注解
30.5.2分类
- @Retention:用于指定注解的保留策略,即注解在什么级别保存(源代码、类文件、运行时)。
- @Target:用于指定注解可以应用的目标元素类型,如类、方法、字段等。
- @Documented:用于指定注解是否包含在Java文档中。
- @Inherited:用于指定注解是否被子类继承。
30.5.3@Target
用来标识注解使用的位置,如果没有使用该注解标识,则自定义的注解可以使用在任意位置。
可使用的值定义在ElementType枚举类中,常用值如下
- TYPE,类,接口
- FIELD, 成员变量
- METHOD, 成员方法
- PARAMETER, 方法参数
- CONSTRUCTOR, 构造方法
- LOCAL_VARIABLE, 局部变量
30.5.4@Retention
用来标识注解的生命周期(有效范围)
可使用的值定义在RetentionPolicy枚举类中,常用值如下
- SOURCE:注解只作用在源码阶段,生成的字节码文件中不存在
- CLASS:注解作用在源码阶段,字节码文件阶段,运行阶段不存在,默认值
- RUNTIME:注解作用在源码阶段,字节码文件阶段,运行阶段
30.算法(目前了解,日后补充)
数据结构是数据存储的方式,算法是数据计算的方式。所以在开发中,算法和数据结构息息相关。今天的讲义中会涉及部分数据结构的专业名词,如果各位铁粉有疑惑,可以先看一下哥们后面录制的数据结构,再回头看算法。
30.1查找算法
30.1.1. 基本查找
也叫做顺序查找
说明:顺序查找适合于存储结构为数组或者链表。
基本思想:顺序查找也称为线形查找,属于无序查找算法。从数据结构线的一端开始,顺序扫描,依次将遍历到的结点与要查找的值相比较,若相等则表示查找成功;若遍历结束仍没有找到相同的,表示查找失败。
示例代码:
public class A01_BasicSearchDemo1 {
public static void main(String[] args) {
//基本查找/顺序查找
//核心:
//从0索引开始挨个往后查找
//需求:定义一个方法利用基本查找,查询某个元素是否存在
//数据如下:{131, 127, 147, 81, 103, 23, 7, 79}
int[] arr = {
131, 127, 147, 81, 103, 23, 7, 79};
int number = 82;
System.out.println(basicSearch(arr, number));
}
//参数:
//一:数组
//二:要查找的元素
//返回值:
//元素是否存在
public static boolean basicSearch(int[] arr, int number){
//利用基本查找来查找number在数组中是否存在
for (int i = 0; i < arr.length; i++) {
if(arr[i] == number){
return true;
}
}
return false;
}
}
30.1.2. 二分查找
也叫做折半查找
说明:元素必须是有序的,从小到大,或者从大到小都是可以的。
如果是无序的,也可以先进行排序。但是排序之后,会改变原有数据的顺序,查找出来元素位置跟原来的元素可能是不一样的,所以排序之后再查找只能判断当前数据是否在容器当中,返回的索引无实际的意义。
基本思想:也称为是折半查找,属于有序查找算法。用给定值先与中间结点比较。比较完之后有三种情况:
-
相等
说明找到了
-
要查找的数据比中间节点小
说明要查找的数字在中间节点左边
-
要查找的数据比中间节点大
说明要查找的数字在中间节点右边
代码示例:
package com.itheima.search;
public class A02_BinarySearchDemo1 {
public static void main(String[] args) {
//二分查找/折半查找
//核心:
//每次排除一半的查找范围
//需求:定义一个方法利用二分查找,查询某个元素在数组中的索引
//数据如下:{7, 23, 79, 81, 103, 127, 131, 147}
int[] arr = {
7, 23, 79, 81, 103, 127, 131, 147};
System.out.println(binarySearch(arr, 150));
}
public static int binarySearch(int[] arr, int number){
//1.定义两个变量记录要查找的范围
int min = 0;
int max = arr.length - 1;
//2.利用循环不断的去找要查找的数据
while(true){
if(min > max){
return -1;
}
//3.找到min和max的中间位置
int mid = (min + max) / 2;
//4.拿着mid指向的元素跟要查找的元素进行比较
if(arr[mid] > number){
//4.1 number在mid的左边
//min不变,max = mid - 1;
max = mid - 1;
}else if(arr[mid] < number){
//4.2 number在mid的右边
//max不变,min = mid + 1;
min = mid + 1;
}else{
//4.3 number跟mid指向的元素一样
//找到了
return mid;
}
}
}
}
30.1.3. 插值查找
在介绍插值查找之前,先考虑一个问题:
为什么二分查找算法一定要是折半,而不是折四分之一或者折更多呢?
其实就是因为方便,简单,但是如果我能在二分查找的基础上,让中间的mid点,尽可能靠近想要查找的元素,那不就能提高查找的效率了吗?
二分查找中查找点计算如下:
mid=(low+high)/2, 即mid=low+1/2*(high-low);
我们可以将查找的点改进为如下:
mid=low+(key-a[low])/(a[high]-a[low])*(high-low),
这样,让mid值的变化更靠近关键字key,这样也就间接地减少了比较次数。
基本思想:基于二分查找算法,将查找点的选择改进为自适应选择,可以提高查找效率。当然,差值查找也属于有序查找。
**细节:**对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好的多。反之,数组中如果分布非常不均匀,那么插值查找未必是很合适的选择。
代码跟二分查找类似,只要修改一下mid的计算方式即可。
30.1.4. 斐波那契查找
在介绍斐波那契查找算法之前,我们先介绍一下很它紧密相连并且大家都熟知的一个概念——黄金分割。
黄金比例又称黄金分割,是指事物各部分间一定的数学比例关系,即将整体一分为二,较大部分与较小部分之比等于整体与较大部分之比,其比值约为1:0.619或1.619:1。
0.619被公认为最具有审美意义的比例数字,这个数值的作用不仅仅体现在诸如绘画、雕塑、音乐、建筑等艺术领域,而且在管理、工程设计等方面也有着不可忽视的作用。因此被称为黄金分割。
在数学中有一个非常有名的数学规律:斐波那契数列:1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89…….
(从第三个数开始,后边每一个数都是前两个数的和)。
然后我们会发现,随着斐波那契数列的递增,前后两个数的比值会越来越接近0.619,利用这个特性,我们就可以将黄金比例运用到查找技术中。

基本思想:也是二分查找的一种提升算法,通过运用黄金比例的概念在数列中选择查找点进行查找,提高查找效率。同样地,斐波那契查找也属于一种有序查找算法。
斐波那契查找也是在二分查找的基础上进行了优化,优化中间点mid的计算方式即可
代码示例:
public class FeiBoSearchDemo {
public static int maxSize = 20;
public static void main(String[] args) {
int[] arr = {
1, 8, 10, 89, 1000, 1234};
System.out.println(search(arr, 1234));
}
public static int[] getFeiBo() {
int[] arr = new int[maxSize];
arr[0] = 1;
arr[1] = 1;
for (int i = 2; i < maxSize; i++) {
arr[i] = arr[i - 1] + arr[i - 2];
}
return arr;
}
public static int search(int[] arr, int key) {
int low = 0;
int high = arr.length - 1;
//表示斐波那契数分割数的下标值
int index = 0;
int mid = 0;
//调用斐波那契数列
int[] f = getFeiBo();
//获取斐波那契分割数值的下标
while (high > (f[index] - 1)) {
index++;
}
//因为f[k]值可能大于a的长度,因此需要使用Arrays工具类,构造一个新法数组,并指向temp[],不足的部分会使用0补齐
int[] temp = Arrays.copyOf(arr, f[index]);
//实际需要使用arr数组的最后一个数来填充不足的部分
for (int i = high + 1; i < temp.length; i++) {
temp[i] = arr[high];
}
//使用while循环处理,找到key值
while (low <= high) {
mid = low + f[index - 1] - 1;
if (key < temp[mid]) {
//向数组的前面部分进行查找
high = mid - 1;
/*
对k--进行理解
1.全部元素=前面的元素+后面的元素
2.f[k]=k[k-1]+f[k-2]
因为前面有k-1个元素没所以可以继续分为f[k-1]=f[k-2]+f[k-3]
即在f[k-1]的前面继续查找k--
即下次循环,mid=f[k-1-1]-1
*/
index--;
} else if (key > temp[mid]) {
//向数组的后面的部分进行查找
low = mid + 1;
index -= 2;
} else {
//找到了
//需要确定返回的是哪个下标
if (mid <= high) {
return mid;
} else {
return high;
}
}
}
return -1;
}
}
30.1.5. 分块查找
当数据表中的数据元素很多时,可以采用分块查找。
汲取了顺序查找和折半查找各自的优点,既有动态结构,又适于快速查找
分块查找适用于数据较多,但是数据不会发生变化的情况,如果需要一边添加一边查找,建议使用哈希查找
分块查找的过程:
- 需要把数据分成N多小块,块与块之间不能有数据重复的交集。
- 给每一块创建对象单独存储到数组当中
- 查找数据的时候,先在数组查,当前数据属于哪一块
- 再到这一块中顺序查找
代码示例:
package com.itheima.search;
public class A03_BlockSearchDemo {
public static void main(String[] args) {
/*
分块查找
核心思想:
块内无序,块间有序
实现步骤:
1.创建数组blockArr存放每一个块对象的信息
2.先查找blockArr确定要查找的数据属于哪一块
3.再单独遍历这一块数据即可
*/
int[] arr = {
16, 5, 9, 12,21, 19,
32, 23, 37, 26, 45, 34,
50, 48, 61, 52, 73, 66};
//创建三个块的对象
Block b1 = new Block(21,0,5);
Block b2 = new Block(45,6,11);
Block b3 = new Block(73,12,19);
//定义数组用来管理三个块的对象(索引表)
Block[] blockArr = {
b1,b2,b3};
//定义一个变量用来记录要查找的元素
int number = 37;
//调用方法,传递索引表,数组,要查找的元素
int index = getIndex(blockArr,arr,number);
//打印一下
System.out.println(index);
}
//利用分块查找的原理,查询number的索引
private static int getIndex(Block[] blockArr, int[] arr, int number) {
//1.确定number是在那一块当中
int indexBlock = findIndexBlock(blockArr, number);
if(indexBlock == -1){
//表示number不在数组当中
return -1;
}
//2.获取这一块的起始索引和结束索引 --- 30
// Block b1 = new Block(21,0,5); ---- 0
// Block b2 = new Block(45,6,11); ---- 1
// Block b3 = new Block(73,12,19); ---- 2
int startIndex = blockArr[indexBlock].getStartIndex();
int endIndex = blockArr[indexBlock].getEndIndex();
//3.遍历
for (int i = startIndex; i <= endIndex; i++) {
if(arr[i] == number){
return i;
}
}
return -1;
}
//定义一个方法,用来确定number在哪一块当中
public static int findIndexBlock(Block[] blockArr,int number){
//100
//从0索引开始遍历blockArr,如果number小于max,那么就表示number是在这一块当中的
for (int i = 0; i < blockArr.length; i++) {
if(number <= blockArr[i].getMax()){
return i;
}
}
return -1;
}
}
class Block{
private int max;//最大值
private int startIndex;//起始索引
private int endIndex;//结束索引
public Block() {
}
public Block(int max, int startIndex, int endIndex) {
this.max = max;
this.startIndex = startIndex;
this.endIndex = endIndex;
}
/**
* 获取
* @return max
*/
public int getMax() {
return max;
}
/**
* 设置
* @param max
*/
public void setMax(int max) {
this.max = max;
}
/**
* 获取
* @return startIndex
*/
public int getStartIndex() {
return startIndex;
}
/**
* 设置
* @param startIndex
*/
public void setStartIndex(int startIndex) {
this.startIndex = startIndex;
}
/**
* 获取
* @return endIndex
*/
public int getEndIndex() {
return endIndex;
}
/**
* 设置
* @param endIndex
*/
public void setEndIndex(int endIndex) {
this.endIndex = endIndex;
}
public String toString() {
return "Block{max = " + max + ", startIndex = " + startIndex + ", endIndex = " + endIndex + "}";
}
}
30.1.6. 哈希查找
哈希查找是分块查找的进阶版,适用于数据一边添加一边查找的情况。
一般是数组 + 链表的结合体或者是数组+链表 + 红黑树的结合体
在课程中,为了让大家方便理解,所以规定:
- 数组的0索引处存储1~100
- 数组的1索引处存储101~200
- 数组的2索引处存储201~300
- 以此类推
但是实际上,我们一般不会采取这种方式,因为这种方式容易导致一块区域添加的元素过多,导致效率偏低。
更多的是先计算出当前数据的哈希值,用哈希值跟数组的长度进行计算,计算出应存入的位置,再挂在数组的后面形成链表,如果挂的元素太多而且数组长度过长,我们也会把链表转化为红黑树,进一步提高效率。
具体的过程,大家可以参见B站阿玮讲解课程:从入门到起飞。在集合章节详细讲解了哈希表的数据结构。全程采取动画形式讲解,让大家一目了然。
在此不多做阐述。
30.1.7. 树表查找
本知识点涉及到数据结构:树。
建议先看一下后面阿玮讲解的数据结构,再回头理解。
基本思想:二叉查找树是先对待查找的数据进行生成树,确保树的左分支的值小于右分支的值,然后在就行和每个节点的父节点比较大小,查找最适合的范围。 这个算法的查找效率很高,但是如果使用这种查找方法要首先创建树。
二叉查找树(BinarySearch Tree,也叫二叉搜索树,或称二叉排序树Binary Sort Tree),具有下列性质的二叉树:
1)若任意节点左子树上所有的数据,均小于本身;
2)若任意节点右子树上所有的数据,均大于本身;
二叉查找树性质:对二叉查找树进行中序遍历,即可得到有序的数列。
基于二叉查找树进行优化,进而可以得到其他的树表查找算法,如平衡树、红黑树等高效算法。
具体细节大家可以参见B站阿玮讲解课程:从入门到起飞。在集合章节详细讲解了树数据结构。全程采取动画形式讲解,让大家一目了然。
在此不多做阐述。
不管是二叉查找树,还是平衡二叉树,还是红黑树,查找的性能都比较高
30.2排序算法
30.2.1. 冒泡排序
冒泡排序(Bubble Sort)也是一种简单直观的排序算法。
它重复的遍历过要排序的数列,一次比较相邻的两个元素,如果他们的顺序错误就把他们交换过来。
这个算法的名字由来是因为越大的元素会经由交换慢慢"浮"到最后面。
当然,大家可以按照从大到小的方式进行排列。
30.2.1.1 算法步骤
- 相邻的元素两两比较,大的放右边,小的放左边
- 第一轮比较完毕之后,最大值就已经确定,第二轮可以少循环一次,后面以此类推
- 如果数组中有n个数据,总共我们只要执行n-1轮的代码就可以
30.2.1.2 动图演示

30.2.1.3 代码示例
public class A01_BubbleDemo {
public static void main(String[] args) {
/*
冒泡排序:
核心思想:
1,相邻的元素两两比较,大的放右边,小的放左边。
2,第一轮比较完毕之后,最大值就已经确定,第二轮可以少循环一次,后面以此类推。
3,如果数组中有n个数据,总共我们只要执行n-1轮的代码就可以。
*/
//1.定义数组
int[] arr = {
2, 4, 5, 3, 1};
//2.利用冒泡排序将数组中的数据变成 1 2 3 4 5
//外循环:表示我要执行多少轮。 如果有n个数据,那么执行n - 1 轮
for (int i = 0; i < arr.length - 1; i++) {
//内循环:每一轮中我如何比较数据并找到当前的最大值
//-1:为了防止索引越界
//-i:提高效率,每一轮执行的次数应该比上一轮少一次。
for (int j = 0; j < arr.length - 1 - i; j++) {
//i 依次表示数组中的每一个索引:0 1 2 3 4
if(arr[j] > arr[j + 1]){
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
printArr(arr);
}
private static void printArr(int[] arr) {
//3.遍历数组
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}
System.out.println();
}
}
30.2.2. 选择排序
30.2.2.1 算法步骤
- 从0索引开始,跟后面的元素一一比较
- 小的放前面,大的放后面
- 第一次循环结束后,最小的数据已经确定
- 第二次循环从1索引开始以此类推
- 第三轮循环从2索引开始以此类推
- 第四轮循环从3索引开始以此类推。
30.2.2.2 动图演示

public class A02_SelectionDemo {
public static void main(String[] args) {
/*
选择排序:
1,从0索引开始,跟后面的元素一一比较。
2,小的放前面,大的放后面。
3,第一次循环结束后,最小的数据已经确定。
4,第二次循环从1索引开始以此类推。
*/
//1.定义数组
int[] arr = {
2, 4, 5, 3, 1};
//2.利用选择排序让数组变成 1 2 3 4 5
/* //第一轮:
//从0索引开始,跟后面的元素一一比较。
for (int i = 0 + 1; i < arr.length; i++) {
//拿着0索引跟后面的数据进行比较
if(arr[0] > arr[i]){
int temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
}
}*/
//最终代码:
//外循环:几轮
//i:表示这一轮中,我拿着哪个索引上的数据跟后面的数据进行比较并交换
for (int i = 0; i < arr.length -1; i++) {
//内循环:每一轮我要干什么事情?
//拿着i跟i后面的数据进行比较交换
for (int j = i + 1; j < arr.length; j++) {
if(arr[i] > arr[j]){
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
}
printArr(arr);
}
private static void printArr(int[] arr) {
//3.遍历数组
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}
System.out.println();
}
}
30.2.3. 插入排序
插入排序的代码实现虽然没有冒泡排序和选择排序那么简单粗暴,但它的原理应该是最容易理解的了,因为只要打过扑克牌的人都应该能够秒懂。插入排序是一种最简单直观的排序算法,它的工作原理是通过创建有序序列和无序序列,然后再遍历无序序列得到里面每一个数字,把每一个数字插入到有序序列中正确的位置。
插入排序在插入的时候,有优化算法,在遍历有序序列找正确位置时,可以采取二分查找
30.2.3.1 算法步骤
将0索引的元素到N索引的元素看做是有序的,把N+1索引的元素到最后一个当成是无序的。
遍历无序的数据,将遍历到的元素插入有序序列中适当的位置,如遇到相同数据,插在后面。
N的范围:0~最大索引
30.2.3.2 动图演示

package com.itheima.mysort;
public class A03_InsertDemo {
public static void main(String[] args) {
/*
插入排序:
将0索引的元素到N索引的元素看做是有序的,把N+1索引的元素到最后一个当成是无序的。
遍历无序的数据,将遍历到的元素插入有序序列中适当的位置,如遇到相同数据,插在后面。
N的范围:0~最大索引
*/
int[] arr = {
3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48};
//1.找到无序的哪一组数组是从哪个索引开始的。 2
int startIndex = -1;
for (int i = 0; i < arr.length; i++) {
if(arr[i] > arr[i + 1]){
startIndex = i + 1;
break;
}
}
//2.遍历从startIndex开始到最后一个元素,依次得到无序的哪一组数据中的每一个元素
for (int i = startIndex; i < arr.length; i++) {
//问题:如何把遍历到的数据,插入到前面有序的这一组当中
//记录当前要插入数据的索引
int j = i;
while(j > 0 && arr[j] < arr[j - 1]){
//交换位置
int temp = arr[j];
arr[j] = arr[j - 1];
arr[j - 1] = temp;
j--;
}
}
printArr(arr);
}
private static void printArr(int[] arr) {
//3.遍历数组
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}
System.out.println();
}
}
30.2.4. 快速排序
快速排序是由东尼·霍尔所发展的一种排序算法。
快速排序又是一种分而治之思想在排序算法上的典型应用。
快速排序的名字起的是简单粗暴,因为一听到这个名字你就知道它存在的意义,就是快,而且效率高!
它是处理大数据最快的排序算法之一了。
30.2.4.1 算法步骤
- 从数列中挑出一个元素,一般都是左边第一个数字,称为 “基准数”;
- 创建两个指针,一个从前往后走,一个从后往前走。
- 先执行后面的指针,找出第一个比基准数小的数字
- 再执行前面的指针,找出第一个比基准数大的数字
- 交换两个指针指向的数字
- 直到两个指针相遇
- 将基准数跟指针指向位置的数字交换位置,称之为:基准数归位。
- 第一轮结束之后,基准数左边的数字都是比基准数小的,基准数右边的数字都是比基准数大的。
- 把基准数左边看做一个序列,把基准数右边看做一个序列,按照刚刚的规则递归排序
30.2.4.2 动图演示

package com.itheima.mysort;
import java.util.Arrays;
public class A05_QuickSortDemo {
public static void main(String[] args) {
System.out.println(Integer.MAX_VALUE);
System.out.println(Integer.MIN_VALUE);
/*
快速排序:
第一轮:以0索引的数字为基准数,确定基准数在数组中正确的位置。
比基准数小的全部在左边,比基准数大的全部在右边。
后面以此类推。
*/
int[] arr = {
1,1, 6, 2, 7, 9, 3, 4, 5, 1,10, 8};
//int[] arr = new int[1000000];
/* Random r = new Random();
for (int i = 0; i < arr.length; i++) {
arr[i] = r.nextInt();
}*/
long start = System.currentTimeMillis();
quickSort(arr, 0, arr.length - 1);
long end = System.currentTimeMillis();
System.out.println(end - start);//149
System.out.println(Arrays.toString(arr));
//课堂练习:
//我们可以利用相同的办法去测试一下,选择排序,冒泡排序以及插入排序运行的效率
//得到一个结论:快速排序真的非常快。
/* for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}*/
}
/*
* 参数一:我们要排序的数组
* 参数二:要排序数组的起始索引
* 参数三:要排序数组的结束索引
* */
public static void quickSort(int[] arr, int i, int j) {
//定义两个变量记录要查找的范围
int start = i;
int end = j;
if(start > end){
//递归的出口
return;
}
//记录基准数
int baseNumber = arr[i];
//利用循环找到要交换的数字
while(start != end){
//利用end,从后往前开始找,找比基准数小的数字
//int[] arr = {1, 6, 2, 7, 9, 3, 4, 5, 10, 8};
while(true){
if(end <= start || arr[end] < baseNumber){
break;
}
end--;
}
System.out.println(end);
//利用start,从前往后找,找比基准数大的数字
while(true){
if(end <= start || arr[start] > baseNumber){
break;
}
start++;
}
//把end和start指向的元素进行交换
int temp = arr[start];
arr[start] = arr[end];
arr[end] = temp;
}
//当start和end指向了同一个元素的时候,那么上面的循环就会结束
//表示已经找到了基准数在数组中应存入的位置
//基准数归位
//就是拿着这个范围中的第一个数字,跟start指向的元素进行交换
int temp = arr[i];
arr[i] = arr[start];
arr[start] = temp;
//确定6左边的范围,重复刚刚所做的事情
quickSort(arr,i,start - 1);
//确定6右边的范围,重复刚刚所做的事情
quickSort(arr,start + 1,j);
}
}
30.补充(目前了解,日后补充)
30.1类加载器
30.1.1概述
类加载器∶负责将.class文件(存储的物理文件)加载在到内存中
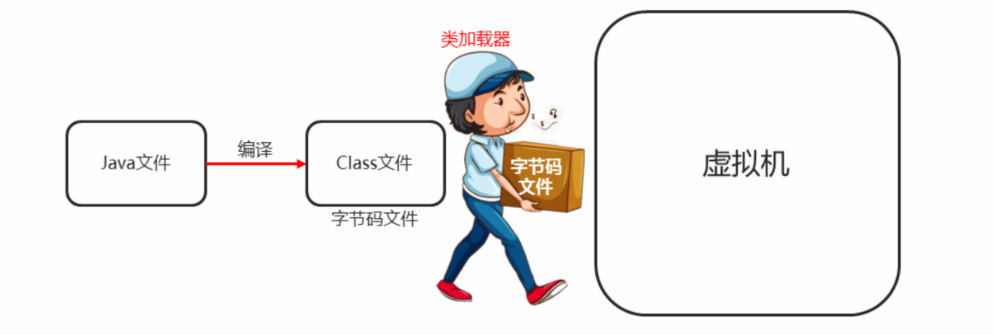
30.1.2类加载的时机
- 创建类的实例(对象)
- 调用类的类方法
- 访问类或者接口的类变量,或者为该类变量赋值
- 使用反射方式来强制创建某个类或接口对应的java.lang.Class对象
- 初始化某个类的子类
- 直接使用java.exe命令来运行某个主类
总结:用到就加载,不用就不加载
30.1.3类加载的过程
-
加载
- 通过包名 + 类名,获取这个类,准备用流进行传输
- 在这个类加载到内存中
- 加载完毕创建一个class对象
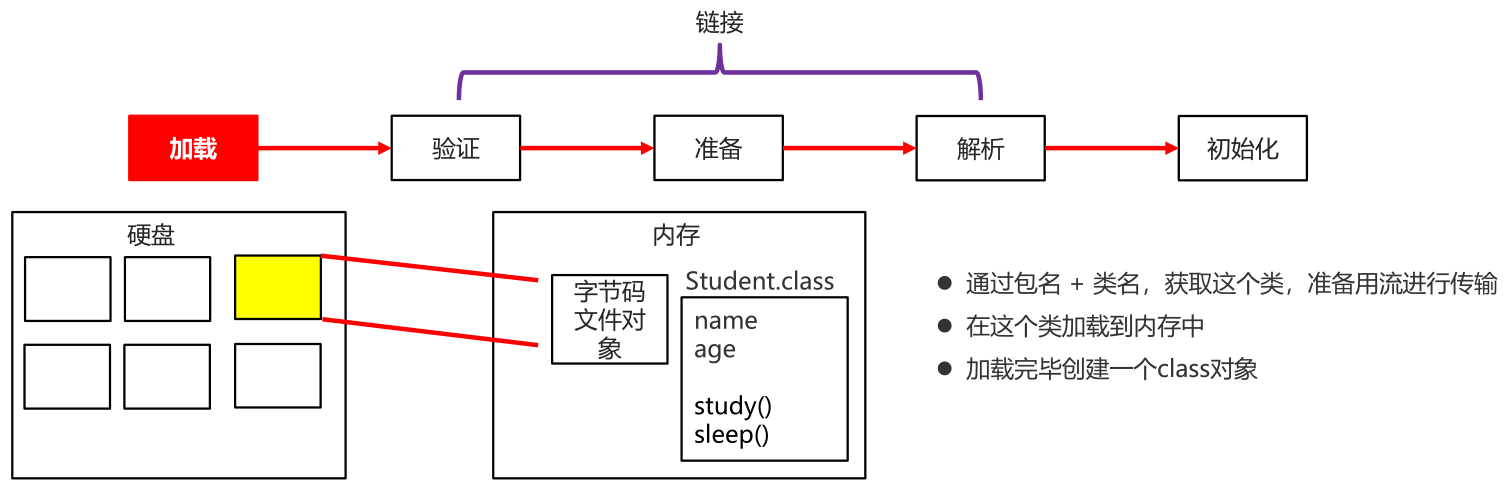
-
链接
- 验证:确保Class文件字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身安全(文件中的信息是否符合虚拟机规范有没有安全隐患)
- 准备:负责为类的类变量(被static修饰的变量)分配内存,并设置默认初始化值(初始化静态变量)
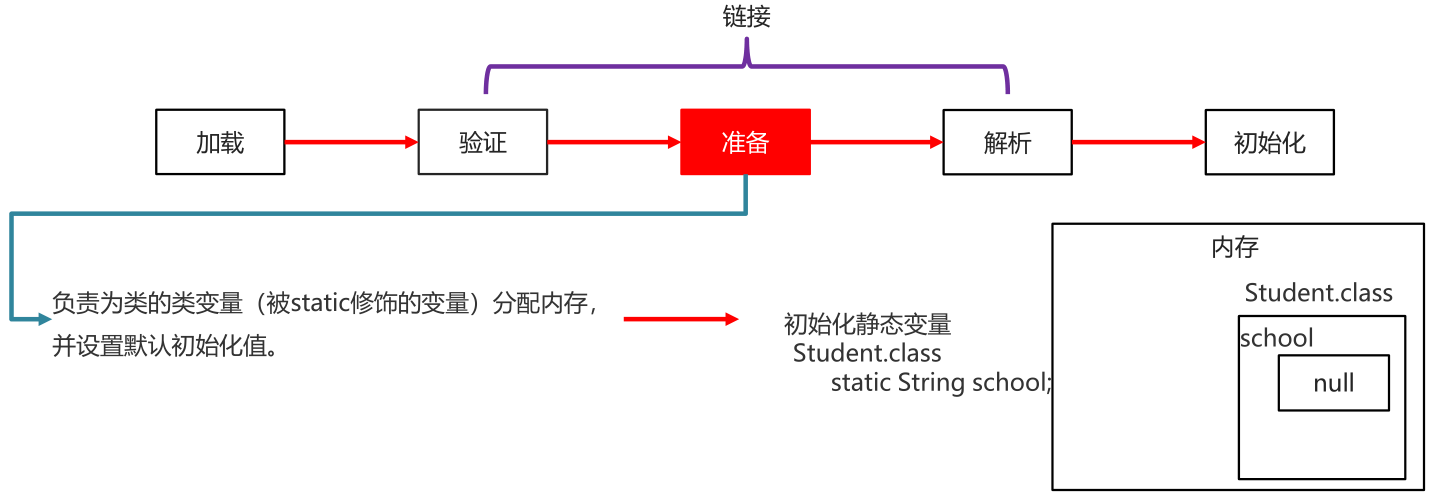
- 解析:将类的二进制数据流中的符号引用替换为直接引用(本类中如果用到了其他类,此时就需要找到对应的类)
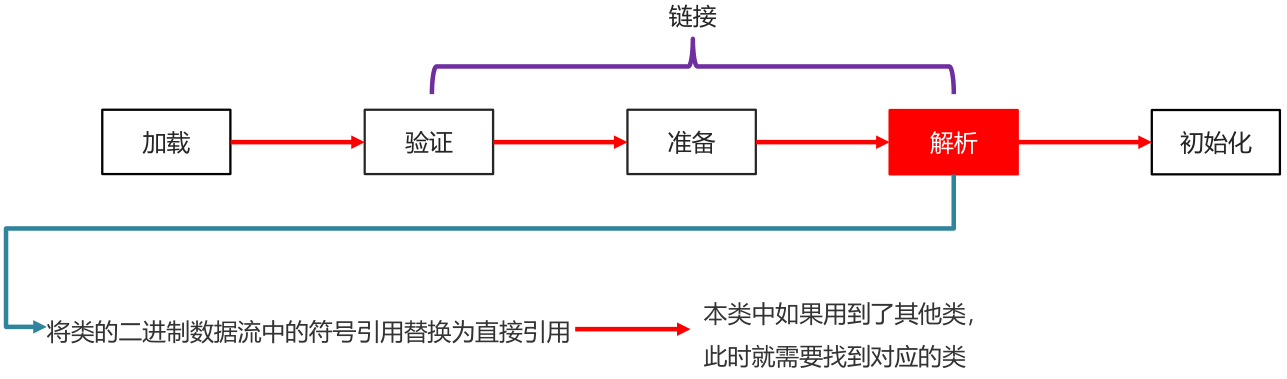
-
初始化:根据程序员通过程序制定的主观计划去初始化类变量和其他资源(静态变量赋值以及初始化其他资源)
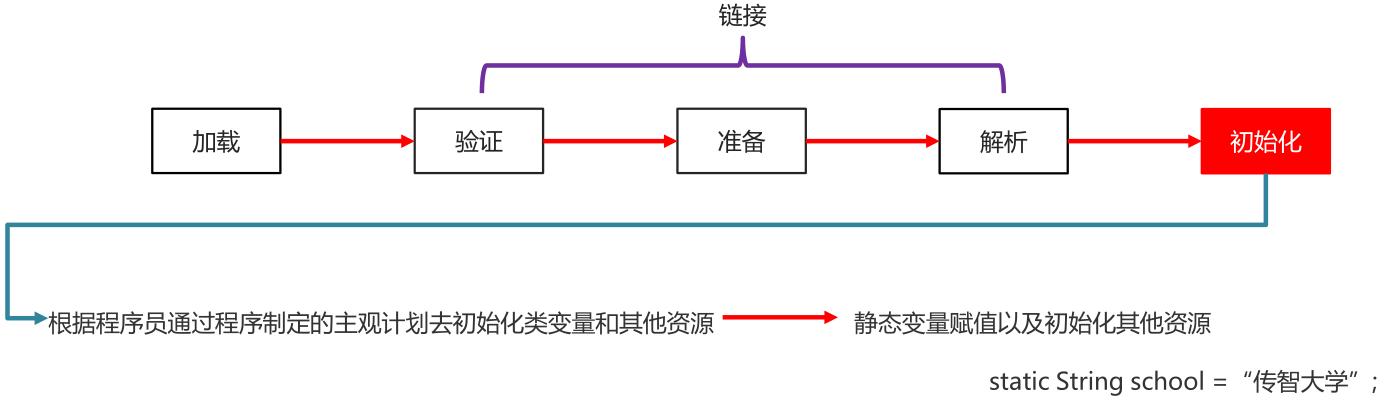
小结:
- 当一个类被使用的时候,才会加载到内存
- 类加载的过程: 加载、验证、准备、解析、初始化
30.1.4类加载的分类
分类
- Bootstrap class loader:虚拟机的内置类加载器,通常表示为null ,并且没有父null
- Platform class loader:平台类加载器,负责加载JDK中一些特殊的模块
- System class loader:系统类加载器,负责加载用户类路径上所指定的类库
30.1.5双亲委派模型
如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行,如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器,如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式
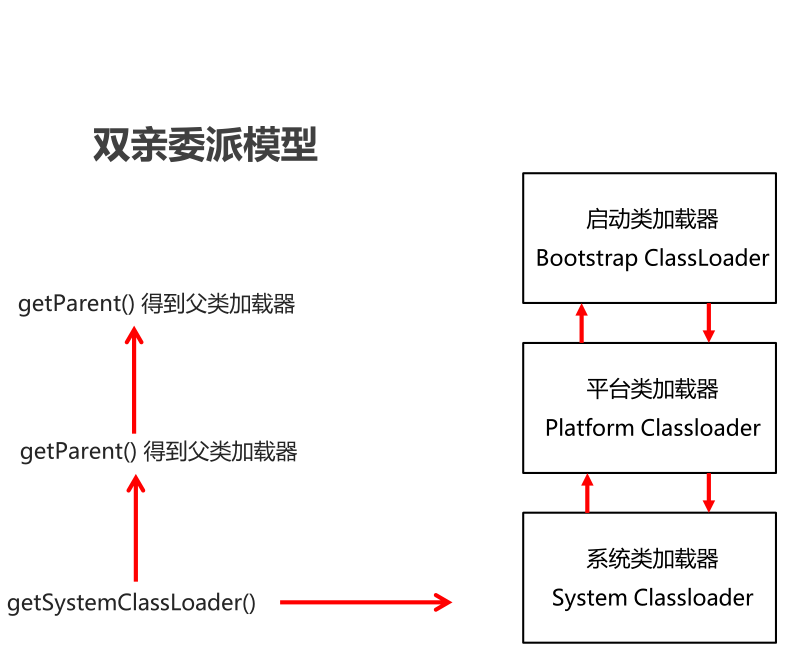
30.1.6类加载器常用方法
| 方法名 | 说明 |
|---|---|
| public static ClassLoader getSystemClassLoader() | 获取系统类加载器 |
| public InputStream getResourceAsStream(String name) | 加载某一个资源文件 |
示例:
public class ClassLoaderDemo2 {
public static void main(String[] args) throws IOException {
//static ClassLoader getSystemClassLoader() 获取系统类加载器
//InputStream getResourceAsStream(String name) 加载某一个资源文件
//获取系统类加载器
ClassLoader systemClassLoader = ClassLoader.getSystemClassLoader();
//利用加载器去加载一个指定的文件
//参数:文件的路径(放在src的根目录下,默认去那里加载)
//返回值:字节流。
InputStream is = systemClassLoader.getResourceAsStream("prop.properties");
Properties prop = new Properties();
prop.load(is);
System.out.println(prop);
is.close();
}
}
注意:
prop.properties文件,需要放在src下,才能被读取并加载
30.2XML
30.2.1三种配置文件的优缺点

30.2.2概述
- XML的全称为(EXtensible Markup Language),是一种可扩展的标记语言
- 标记语言: 通过标签来描述数据的一门语言(标签有时我们也将其称之为元素)
- 可扩展:标签的名字是可以自定义的,XML文件是由很多标签组成的,而标签名是可以自定义的
例如:
-
作用
- 用于进行存储数据和传输数据
- 作为软件的配置文件
-
作为配置文件的优势
- 可读性好
- 可维护性高
30.2.3使用
XML的创建
- 就是创建一个XML类型的文件,要求文件的后缀必须使用xml,如hello_world.xml
XML的基本语法
-
Una etiqueta consta de un par de corchetes angulares seguidos de un identificador legal.
<student> -
Las etiquetas deben aparecer en pares.
<student> </student> 前边的是开始标签,后边的是结束标签 -
Las etiquetas especiales se pueden desemparejar, pero deben tener una etiqueta de cierre
<address/> -
Los atributos se pueden definir en etiquetas. Los atributos y los nombres de las etiquetas están separados por espacios. Los valores de los atributos deben estar entre comillas.
<student id="1"> </student> -
Las etiquetas deben anidarse correctamente
这是正确的: <student id="1"> <name>张三</name> </student> 这是错误的: <student id="1"><name>张三</student></name>
30.2.4 Restricciones del documento
30.2.4.1 Descripción general
30.2.4.2 Clasificación
30.3 Pruebas unitarias
30.3.1 Descripción general
30.3.2 Inicio rápido