árbol de decisión
¿Qué es un árbol de decisión? El árbol de decisión es un método básico de clasificación y regresión. Para dar un ejemplo fácil de entender, el diagrama de flujo que se muestra a continuación es un árbol de decisión: el rectángulo representa el bloque de decisión y el óvalo representa el bloque de terminación, lo que indica que se ha llegado a una conclusión y que la operación puede finalizar. Las flechas izquierda y derecha que salen del módulo de evaluación se denominan ramas y pueden llegar a otro módulo de evaluación o módulo de terminación. También podemos entender que el modelo de árbol de decisión de clasificación es una estructura de árbol que describe la clasificación de instancias. Un árbol de decisión consta de nodos y aristas dirigidas. Hay dos tipos de nodos: nodos internos y nodos hoja. Los nodos internos representan una característica o atributo y los nodos hoja representan una clase. ¿Estas confundido? ? En el árbol de decisión que se muestra en la siguiente figura, los rectángulos y los óvalos son nodos. Los nodos rectangulares son nodos internos, los nodos elípticos son nodos de hoja y las flechas izquierda y derecha extraídas de los nodos son bordes dirigidos. El nodo superior es el nodo raíz del árbol de decisión. De esta manera, la declaración del nodo corresponde a la declaración del módulo y es fácil de entender.
La mayor parte del texto de este artículo se reproduce de https://cuijiahua.com/blog/2017/11/ml_2_decision_tree_1.html, el código y algunos originales.
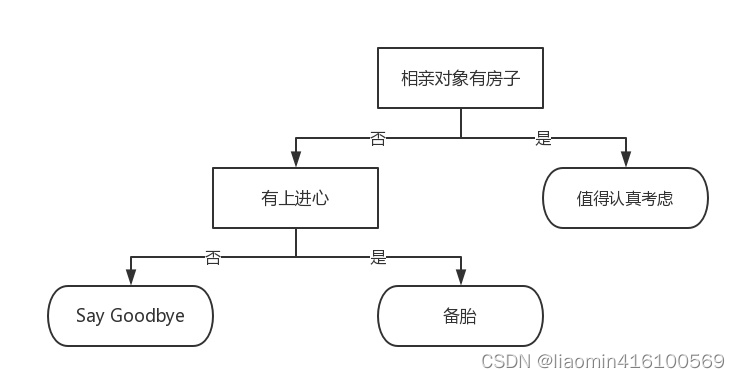
Volvamos a este diagrama de flujo. Sí, lo leíste bien, este es un sistema de clasificación de objetivos de citas imaginario. Primero detecta si el compañero de la cita a ciegas tiene casa. Si tienes una habitación, puedes considerar un mayor contacto con esta cita a ciegas. Si no hay lugar, entonces observe si la cita a ciegas está motivada. Si no, simplemente diga adiós. En este momento, puede decir: "Eres una persona muy agradable, pero no somos adecuados". Si es así, puedes poner la cita a ciegas en la lista de candidatos. , una buena manera de llamarla lista de candidatos, pero para decirlo de manera un tanto imperfecta, es una llanta de refacción.
Pero este es sólo un sistema de clasificación simple para citas a ciegas, solo una clasificación simple. La situación real puede ser mucho más compleja y las consideraciones pueden ser múltiples. ¿Buen carácter? ¿Sabes cocinar? ¿Estás dispuesto a hacer las tareas del hogar? ¿Cuántos hijos hay en la familia? ¿Qué hacen los padres? Dios mío, no quiero decir nada más, da tanto miedo pensar en ello.
Podemos pensar en el árbol de decisión como un conjunto de reglas si-entonces. El proceso de convertir el árbol de decisión en reglas si-entonces es el siguiente: desde el nodo raíz del árbol de decisión hasta el nodo hoja. Cada camino construye una regla. ; las características de los nodos internos en la ruta corresponden a las condiciones de la regla, y la clase del nodo hoja corresponde a la conclusión de la regla. La ruta de un árbol de decisión o su correspondiente conjunto de reglas si-entonces tiene una propiedad importante: mutuamente excluyente y completa. Es decir, cada instancia está cubierta por un camino o regla, y sólo un camino o regla. Lo que se cubre aquí significa que las características de la instancia son consistentes con las características de la ruta o que la instancia satisface las condiciones de la regla.
El uso de árboles de decisión para hacer predicciones requiere el siguiente proceso:
- Recopilar datos: Se puede utilizar cualquier método. Por ejemplo, si queremos construir un sistema de citas a ciegas, podemos obtener datos de casamenteros o entrevistando a citas a ciegas. Según los factores que consideraron y los resultados de la selección final, podemos obtener algunos datos para utilizar.
- Preparar datos: después de recopilar los datos, debemos organizarlos, ordenar toda la información recopilada de acuerdo con ciertas reglas y formatearla para facilitar nuestro procesamiento posterior.
- Analice los datos: se puede utilizar cualquier método. Una vez construido el árbol de decisión, podemos comprobar si el gráfico del árbol de decisión cumple con las expectativas.
Algoritmo de entrenamiento: este proceso consiste en construir un árbol de decisión, también se puede decir que es aprendizaje de árbol de decisión, que consiste en construir una estructura de datos de un árbol de decisión. - Algoritmos de prueba: cálculo de tasas de error utilizando árboles empíricos. Cuando la tasa de error alcanza un rango aceptable, se puede utilizar el árbol de decisión.
Utilice un algoritmo: en este paso se puede utilizar cualquier algoritmo de aprendizaje supervisado y el uso de árboles de decisión puede comprender mejor el significado inherente de los datos.
Preparativos para construir árboles de decisión.
Cada paso del uso de un árbol de decisión para hacer predicciones es importante. Una recopilación de datos inadecuada dará como resultado características insuficientes para que podamos construir un árbol de decisión con una tasa de error baja. Las características de los datos son suficientes, pero si no sabe qué características usar, no podrá construir un modelo de árbol de decisión con un buen efecto de clasificación. Desde una perspectiva algorítmica, la construcción de árboles de decisión es nuestro contenido principal.
¿Cómo construir un árbol de decisión? Generalmente, este proceso se puede resumir en 3 pasos: selección de características, generación de árboles de decisión y poda de árboles de decisión.
Selección de características
La selección de características consiste en seleccionar características que tengan la capacidad de clasificar datos de entrenamiento. Esto puede mejorar la eficiencia del aprendizaje del árbol de decisiones. Si el resultado de la clasificación utilizando una característica no es muy diferente del resultado de la clasificación aleatoria, entonces se dice que esta característica no tiene capacidad de clasificación. Empíricamente, descartar dichas características tiene poco impacto en la precisión del aprendizaje del árbol de decisiones. Por lo general, el estándar para la selección de funciones es la ganancia de información (ganancia de información) o la relación de ganancia de información. Para simplificar, este artículo utiliza la ganancia de información como estándar para la selección de funciones. Entonces, ¿qué es la ganancia de información? Antes de explicar la obtención de información, veamos una serie de ejemplos y una tabla de datos de muestra de una solicitud de préstamo.
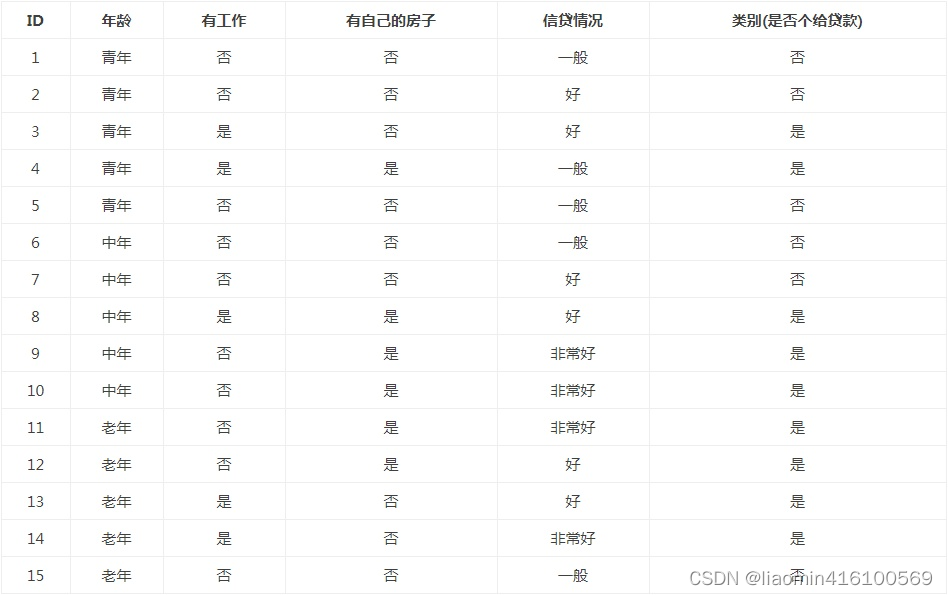
Se espera que a través de los datos de capacitación proporcionados se pueda aprender el árbol de decisiones de una solicitud de préstamo y utilizarlo para clasificar futuras solicitudes de préstamo, es decir, cuando un nuevo cliente solicita un préstamo, el árbol de decisión se utiliza para decidir si se aprueba o no. Solicitud de préstamo en función de las características del solicitante.
La selección de funciones consiste en decidir qué funciones utilizar para dividir el espacio de funciones. Por ejemplo, obtuvimos dos posibles árboles de decisión a través de la tabla de datos anterior, cada uno de los cuales consta de dos nodos raíz con características diferentes.
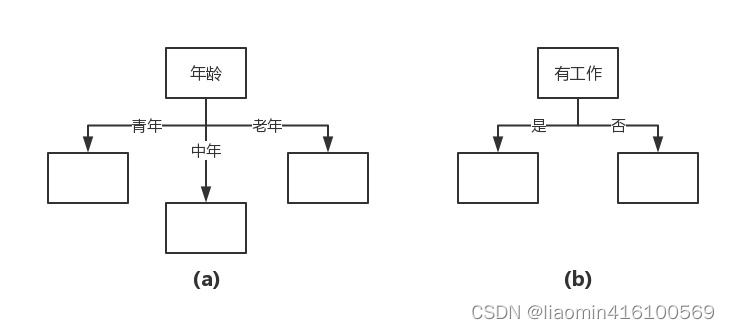
El nodo raíz que se muestra en la Figura (a) se caracteriza por la edad, tiene tres valores y tiene diferentes nodos secundarios correspondientes a diferentes valores. El nodo raíz que se muestra en la Figura (b) se caracteriza por el trabajo, tiene dos valores y tiene diferentes nodos secundarios correspondientes a diferentes valores. Ambos árboles de decisión pueden continuar desde aquí. La pregunta es: ¿qué característica es mejor elegir? Esto requiere determinar criterios para seleccionar características. Intuitivamente, si una característica tiene una mejor capacidad de clasificación, o en otras palabras, el conjunto de datos de entrenamiento se divide en subconjuntos de acuerdo con esta característica, de modo que cada subconjunto tenga la mejor clasificación en las condiciones actuales, entonces se debe seleccionar esta característica. La ganancia de información es una buena representación de este criterio intuitivo.
¿Qué es la ganancia de información? El cambio en la información después de dividir el conjunto de datos se llama ganancia de información. Sabiendo cómo calcular la ganancia de información, podemos calcular la ganancia de información obtenida dividiendo el conjunto de datos para cada valor de característica. Obtener la característica con la mayor ganancia de información es la mejor opción. .
Ganancia de información = incertidumbre de todos los datos - incertidumbre de una determinada característica condición = cuánta certeza mejora esta característica
Entonces, cómo determinar la incertidumbre de los datos conduce al concepto de entropía de Shannon.
Entropía de Shannon
Antes de que podamos evaluar qué partición de datos es la mejor, debemos aprender a calcular la ganancia de información. La medida de la información colectiva se llama entropía de Shannon o simplemente entropía, el nombre proviene de Claude Shannon, el padre de la teoría de la información.
Si no comprende qué son la ganancia de información y la entropía, no se preocupe, porque están destinadas a ser muy confusas para el mundo desde el día en que nacieron. Después de que Claude Shannon escribiera la teoría de la información, John von Neumann sugirió utilizar el término "entropía" porque nadie sabía lo que significaba.
Si desea comprender a fondo el principio de la entropía de la información, consulte el principio gráfico : el método del multiplicador de Lagrange
utilizado en la derivación. Al mismo tiempo, comprenda las características de la función logarítmica:
{kind=link}
{kind=link}
- Si ax =N (a>0, y a≠1), entonces el número x se llama logaritmo de base N con a como base, registrado como La base de N se llama número real.
- Si Y=logaX, significa que la multiplicación de Y a es igual a X
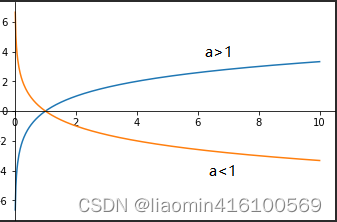
- La base a está entre 0 y 1 y es monótonamente decreciente. Si es mayor que 1, es monótonamente creciente.
- Si a>1 x está entre 0-1 y es un número negativo x=1 y=0 x>1 y es un número positivo
- ln es un operador, lo que significa encontrar el logaritmo natural, es decir, el logaritmo con e como base.
e es una constante, igual a 2.71828183...
lnx puede entenderse como ln (x), es decir, el logaritmo de x con e como base, es decir, cuántas potencias de e son iguales a x.
lnx=loge^x, logeE=Ine=1
La entropía se define como el valor esperado de la información. En teoría de la información y estadística de probabilidad, la entropía es una medida de incertidumbre en una variable aleatoria. Si las cosas a clasificar se pueden dividir en múltiples categorías, la información del símbolo xi se define como:
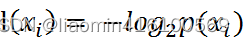
donde p(xi) es la probabilidad de seleccionar esta categoría. Por ejemplo, entre un equipo de 10 personas, los géneros son niños. (3) y niñas (7) dos categorías, el logaritmo en la fórmula anterior se basa en 2, o e puede ser la base (logaritmo natural).
男生熵=-log2 3/10 = 1.7369655941662063
女生熵=-log2 7/10 = 0.5145731728297583
整个团队的熵=男生熵+女生熵 =2.2515387669959646
Tenga en cuenta que log2 p (
A través de la fórmula anterior, podemos obtener todas las categorías de información. Para calcular la entropía, necesitamos calcular el valor esperado de la información (expectativa matemática) contenida en todos los valores posibles de todas las categorías, que se obtiene mediante la siguiente fórmula: Mitad de término
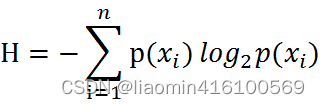
n es el número de categorías. Cuanto mayor es la entropía, mayor es la incertidumbre de la variable aleatoria.
Cuando la probabilidad en entropía se obtiene a partir de la estimación de datos (especialmente la estimación de máxima verosimilitud), la entropía correspondiente se denomina entropía empírica. ¿Qué es la estimación a partir de datos? Por ejemplo, hay 10 datos y hay dos categorías, Categoría A y Categoría B. Entre ellos, 7 datos pertenecen a la categoría A, entonces la probabilidad de la categoría A es siete sobre diez. Entre ellos, 3 datos pertenecen a la categoría B, entonces la probabilidad de la categoría B es tres décimas. La explicación simple es que la probabilidad se calcula en base a los datos. Definimos los datos en la tabla de datos de muestra de la solicitud de préstamo como el conjunto de datos de entrenamiento D, luego la entropía empírica del conjunto de datos de entrenamiento D es H (D), y |D| representa su capacidad de muestra y el número de muestras. Supongamos que K clases Ck, = 1,2,3,…,K,|Ck| es el número de muestras que pertenecen a la clase Ck, por lo que la fórmula de entropía empírica se puede escribir como: Calcular la entropía empírica H( D) de acuerdo con
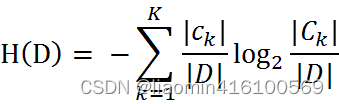
esto Fórmula, analice los datos de la hoja de datos de solicitud de préstamo de muestra. El resultado final de la clasificación son solo dos categorías, a saber, préstamos y no préstamos. Según las estadísticas de datos de la tabla, entre los 15 datos, el resultado de 9 datos es préstamo y el resultado de 6 datos no es préstamo. Por lo tanto, la entropía empírica H(D) del conjunto de datos D es:
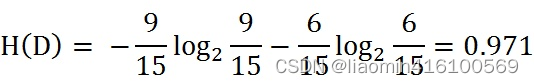
Después del cálculo, se puede ver que el valor de la entropía empírica H(D) del conjunto de datos D es 0,971.
Escribir código para calcular la entropía empírica.
Antes de escribir el código, primero anotamos los atributos del conjunto de datos.
- Edad: 0 representa joven, 1 representa mediana edad, 2 representa viejo;
- Tener trabajo: 0 significa no, 1 significa sí;
- Sea dueño de su propia casa: 0 significa no, 1 significa sí;
- Estado crediticio: 0 significa promedio, 1 significa bueno, 2 significa muy bueno;
- Categoría (si conceder un préstamo): no significa no, sí significa sí.
- Después de determinarlos, podemos crear el conjunto de datos y calcular la entropía empírica. El código se escribe de la siguiente manera:
#%%
#数据集,yes表示放贷,no表示不放贷
'''
具体参考:案例图
特征1表示年龄 0表示青年,1表示中间,2表示老年
特征2表示是否有工作 0表示否,1表示有
特征3表示是否有自己的房子 0表示否 1表示有
特征4是信贷情况 0表示一般 1表示好 2表示非常好。
'''
import numpy as np
dataSet = np.array([[0, 0, 0, 0, 'no'],
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']])
labels = ['不放贷', '放贷']
'''
计算经验熵
D代表传入的数据集
'''
def ShannonEnt(D):
#去除重复元素的结论的分类:[yes,no]
kArray=np.unique(D[:,4].reshape(1,len(D)))
#计算出最终分类的个数
k=len(kArray)
#获取整个样本集的个数
D_count=len(D)
#经验熵
HD=0;
#循环多个分类,计算这个分类的熵,最后求和
for i in range(k):
#获取等于当前分类的数据行
ck=[row for row in D if row[4]==kArray[i]]
HD-=len(ck)/D_count *np.log2(len(ck)/D_count)
return HD;
HD_=ShannonEnt(dataSet)
print("整个数据经验熵:",HD_)
Resultado de salida:
Entropía empírica de datos completos: 0,9709505944546686
Entropía condicional
Sabemos qué es la entropía, pero ¿qué diablos es la entropía condicional? La entropía condicional H (Y | X) representa la incertidumbre de la variable aleatoria Y bajo la condición de variable aleatoria conocida, definida como la expectativa matemática de la entropía
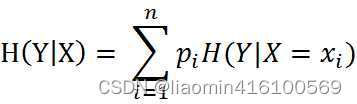
de la distribución de probabilidad condicional de Y bajo las condiciones dadas de D1, D2,···,Dn}, |Di| es el número de muestras de Di. Sea Dik el conjunto de muestras pertenecientes a Ck en el subconjunto Di, es decir, Dik = Di ∩ Ck, y |Dik| es el número de muestras en Dik. Entonces, la fórmula de la entropía condicional empírica puede ser:
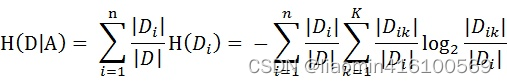
De hecho, es: suma (obtener la probabilidad del mismo conjunto de datos con las características actuales en todos los datos * la entropía de la clasificación final en este conjunto de datos)
'''
计算条件熵
H(D|0) 计算某个特征列的条件熵,当年龄特征的情况下,是否房贷不确定的情况,越大越不确定
'''
def calcConditionShannon(D,index):
#去除重复元素的index列的数组
featureType=np.unique(D[:,index].reshape(1,len(D)))
featureTypeCount=len(featureType)
#获取整个样本集的个数
D_count=len(D)
HDA=0;
for i in range(featureTypeCount):
Di=np.array([row for row in D if row[index]==featureType[i]])
HDA+=len(Di)/D_count*ShannonEnt(Di)
return HDA;
print("年龄特征条件熵",calcConditionShannon(dataSet,0))
Salida: Entropía condicional de característica de edad 0.8879430945988998
ganancia de información
Ganancia de información = incertidumbre de todos los datos - incertidumbre de una determinada condición de característica = cuánta certeza mejora esta característica.
Ganancia de información = entropía empírica - entropía de la condición de característica actual.
La ganancia de información es relativa a la característica. Cuanto mayor sea la ganancia de información, mayor el impacto de las características en el resultado de la clasificación final, debemos elegir la característica que tiene el mayor impacto en el resultado de la clasificación final como nuestra característica de clasificación.
Se aclaran los conceptos de entropía condicional y entropía condicional empírica. A continuación, hablemos de la obtención de información. Como se mencionó anteriormente, la ganancia de información es relativa a las características. Por lo tanto, la ganancia de información g(D,A) de la característica A en el conjunto de datos de entrenamiento D se define como la diferencia entre la entropía empírica H(D) del conjunto D y la entropía condicional empírica H(D|A) de D bajo el Dadas las condiciones de la característica A., es decir:
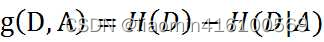
después de hablar de tantas cosas conceptuales, no importa si no lo entiendes, solo da algunos ejemplos, regresa y mira los conceptos, y lo entenderás.
Tome como ejemplo la hoja de datos de muestra de la solicitud de préstamo. Mire los datos en la columna de edad, que es la característica A1. Hay tres categorías: joven, mediana edad y mayor. Solo miramos los datos con la edad de los jóvenes. Hay 5 datos con la edad de los jóvenes. Por lo tanto, la probabilidad de que los datos con la edad de los jóvenes aparezcan en el conjunto de datos de entrenamiento es 5/15, que es un tercio. De la misma manera, la probabilidad de que aparezcan datos de mediana edad y ancianos en el conjunto de datos de entrenamiento es de un tercio. Ahora solo miramos los datos de los jóvenes, la probabilidad de finalmente obtener un préstamo es de dos quintas partes, porque entre los cinco datos, solo dos datos muestran que se obtuvo el préstamo final, de manera similar, los datos de las personas de mediana edad y mayores personas Las probabilidades de conseguir finalmente un préstamo son de tres quintos y cuatro quintos respectivamente. Por lo tanto, el proceso de calcular la ganancia de información de la edad es el siguiente:
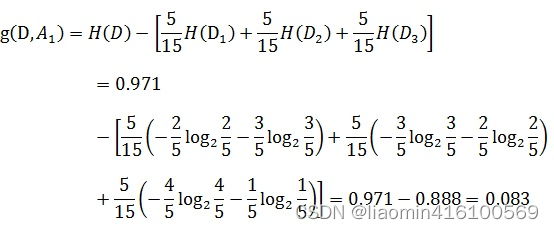
De la misma manera, calcule la ganancia de información de otras características g(D,A2), g(D,A3) y g(D,A4). Ellos son:

Finalmente, compare la ganancia de información de las características. Dado que el valor de ganancia de información de la característica A3 (tener su propia casa) es el mayor, se selecciona A3 como la característica óptima.
Hemos aprendido a calcular la ganancia de información mediante fórmulas, escribamos código para calcular la ganancia de información.
'''
计算某个特征的信息增益
信息增益=整个数据的不确定性-某个特征条件的不确定=这个特征增强了多少确定性
'''
def calaInfoGrain(D,index):
return ShannonEnt(dataSet)-calcConditionShannon(D,index)
print("年龄的信息增益",HD_-calcConditionShannon(dataSet,0))
print("工作的信息增益",calaInfoGrain(dataSet,1))
feature_count=len(dataSet[0])
for i in range(feature_count-1):
print("第"+str(i)+"个特征的信息增益",HD_-calcConditionShannon(dataSet,i))
Salida:
Ganancia de información de la edad 0,08300749985576883
Ganancia de información del trabajo 0,32365019815155627 Ganancia de información
de la característica 0 0,08300749985576883 Ganancia de información de la primera característica 0,32365019815155627
Ganancia
de información de la segunda característica 0,41997309 4021 9749La
ganancia de información de la tercera característica es 0.36298956253708536
Comparando los resultados de nuestros propios cálculos, descubrimos que los resultados eran completamente correctos. El valor del índice de la característica óptima es 2, que es la característica A3 (tiene su propia casa).
Generación de árboles de decisión.
Hemos aprendido los módulos subfuncionales necesarios para construir un algoritmo de árbol de decisión a partir de un conjunto de datos, incluido el cálculo de la entropía empírica y la selección de características óptimas. Su principio de funcionamiento es el siguiente: obtener el conjunto de datos original y luego dividir el conjunto de datos basado en los mejores valores de atributos, dado que puede haber más de dos valores propios, puede haber particiones del conjunto de datos que sean mayores que dos ramas. Después de la primera partición, el conjunto de datos se pasa al siguiente nodo de la rama del árbol. En este nodo, podemos dividir los datos nuevamente. Por tanto, podemos utilizar el principio recursivo para procesar el conjunto de datos.
Existen muchos algoritmos para construir árboles de decisión, como C4.5, ID3 y CART, pero estos algoritmos no siempre consumen funciones cada vez que dividen los datos en grupos cuando se ejecutan. Dado que la cantidad de características no disminuye cada vez que los datos se dividen en grupos, estos algoritmos pueden causar ciertos problemas cuando se usan en la práctica. No necesitamos considerar este problema en este momento, solo necesitamos contar el número de columnas antes de que el algoritmo comience a ejecutarse para ver si usa todos los atributos.
Los algoritmos de generación de árboles de decisión generan árboles de decisión de forma recursiva hasta que ya no pueden continuar. Los árboles generados de esta manera a menudo clasifican los datos de entrenamiento con mucha precisión, pero la clasificación de los datos de prueba desconocidos no es tan precisa, es decir, se produce un sobreajuste. La razón del sobreajuste es que se presta demasiada atención a cómo mejorar la clasificación correcta de los datos de entrenamiento durante el aprendizaje, creando así un árbol de decisiones demasiado complejo. La solución a este problema es considerar la complejidad del árbol de decisión y simplificar el árbol de decisión generado.
Construcción de árboles de decisión
El núcleo del algoritmo ID3 es seleccionar características correspondientes al criterio de ganancia de información en cada nodo del árbol de decisión y construir recursivamente el árbol de decisión. El método específico es: comenzando desde el nodo raíz, calcule la ganancia de información de todas las características posibles para el nodo, seleccione la característica con la mayor ganancia de información como la característica del nodo y establezca subnodos en función de diferentes valores de la característica; luego llame al método anterior de forma recursiva en los nodos secundarios para construir un árbol de decisión; hasta que la ganancia de información de todas las características sea muy pequeña o no se pueda seleccionar ninguna característica. Finalmente se obtiene un árbol de decisión. ID3 equivale a utilizar el método de máxima verosimilitud para seleccionar un modelo probabilístico.
algoritmo ID3
Antes de usar ID3 para construir un árbol de decisión, analicemos los datos.
Datos ordenados por tercera columna
print(dataSet[np.argsort(dataSet[:,2])])
输出:
[['0' '0' '0' '0' 'no']
['0' '0' '0' '1' 'no']
['0' '1' '0' '1' 'yes']
['0' '0' '0' '0' 'no']
['1' '0' '0' '0' 'no']
['1' '0' '0' '1' 'no']
['2' '1' '0' '1' 'yes']
['2' '1' '0' '2' 'yes']
['2' '0' '0' '0' 'no']
['0' '1' '1' '0' 'yes']
['1' '1' '1' '1' 'yes']
['1' '0' '1' '2' 'yes']
['1' '0' '1' '2' 'yes']
['2' '0' '1' '2' 'yes']
['2' '0' '1' '1' 'yes']]
Dado que la característica A3 (tiene su propia casa) tiene el mayor valor de ganancia de información, la característica A3 se selecciona como la característica del nodo raíz. Divide el conjunto de entrenamiento D en dos subconjuntos D1 (el valor de A3 es "sí") y D2 (el valor de A3 es "no"). Dado que D1 solo tiene puntos de muestra de la misma clase, se convierte en un nodo hoja y la marca de clase del nodo es "Sí".
Entre ellos, D1 es
['0' '1' '1' '0' 'yes']
['1' '1' '1' '1' 'yes']
['1' '0' '1' '2' 'yes']
['1' '0' '1' '2' 'yes']
['2' '0' '1' '2' 'yes']
['2' '0' '1' '1' 'yes']]
Dado que solo hay una conclusión de clasificación, sí, cuando D1 = 1, es un nodo hoja. Si no hay bifurcación,
D2 es
['0' '0' '0' '0' 'no']
['0' '0' '0' '1' 'no']
['0' '1' '0' '1' 'yes']
['0' '0' '0' '0' 'no']
['1' '0' '0' '0' 'no']
['1' '0' '0' '1' 'no']
['2' '1' '0' '1' 'yes']
['2' '1' '0' '2' 'yes']
['2' '0' '0' '0' 'no']
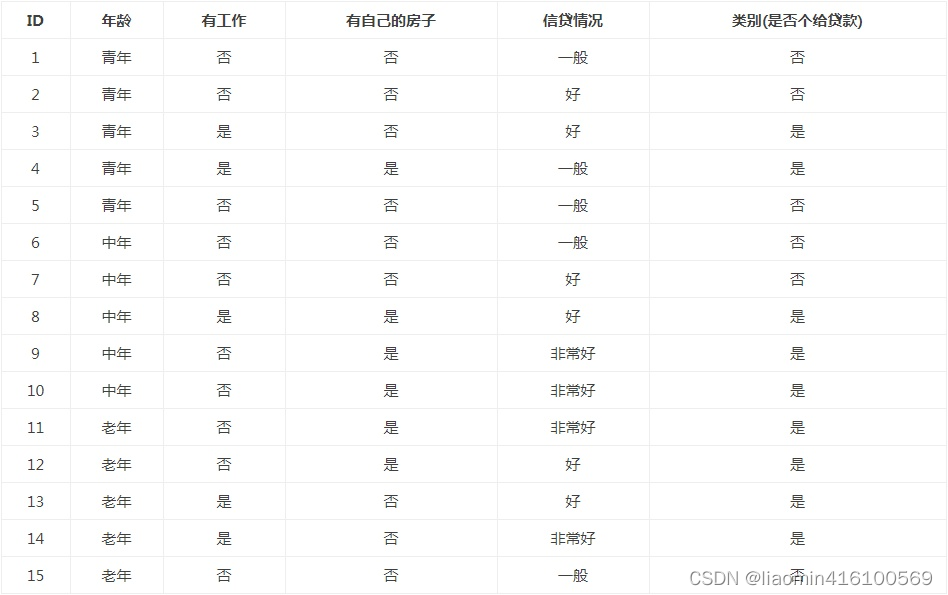
Para D2, se deben seleccionar nuevas características de las características A1 (edad), A2 (empleado) y A4 (situación crediticia), y se calcula la ganancia de información de cada característica: Según el cálculo, la característica A2 (empleado) con el La mayor ganancia de información se selecciona
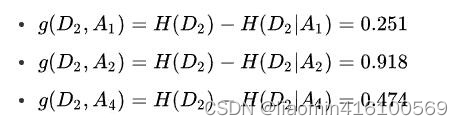
como características del nodo. Dado que A2 tiene dos valores posibles, dos subnodos se derivan de este nodo: un subnodo correspondiente a "Sí" (tiene un trabajo), que contiene 3 muestras, pertenecen a la misma categoría, por lo que este es un punto de nodo hoja , la marca de clase es "Sí"; el otro es un nodo hijo correspondiente a "No" (sin trabajo), que contiene 6 muestras, que también pertenecen a la misma clase, por lo que este también es un nodo hoja, la marca de clase es " No".
Los datos restantes se clasifican según A2.
[['0' '0' '0' '0' 'no']
['0' '0' '0' '1' 'no']
['0' '0' '0' '0' 'no']
['1' '0' '0' '0' 'no']
['1' '0' '0' '1' 'no']
['2' '0' '0' '0' 'no']
['0' '1' '0' '1' 'yes']
['2' '1' '0' '1' 'yes']
['2' '1' '0' '2' 'yes']]
Se encuentra que los resultados de A2 = 0 son todos no, y los resultados de A1 igual a 1 son sí, por lo que no hay otra clasificación, el nodo termina en el punto de trabajo, se puede entender que el nodo hoja es el conclusión
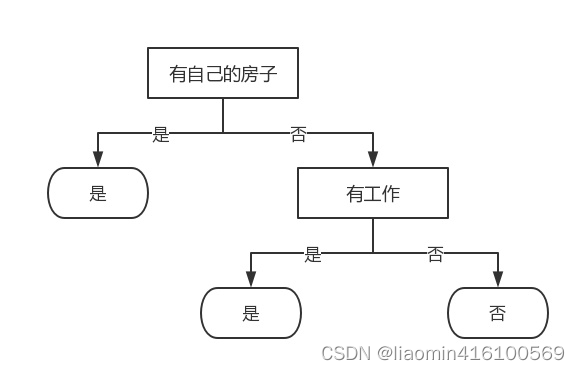
de si se debe prestar o no, y la bifurcación es el valor de la característica.
Escribir código para construir un árbol de decisión.
Usamos un diccionario para almacenar la estructura del árbol de decisión, por ejemplo, el árbol de decisión que analizamos en la sección anterior se puede expresar como:
{'有自己的房子': {0: {'有工作': {0: 'no', 1: 'yes'}}, 1: 'yes'}}
El código se implementa de la siguiente manera.
#%%
'''
将数据按照值指定特征列分组,,比如有房子=1的数据行和无房子=0的数据行
{
0:[[]]
1:[[]]
}
'''
colLabels=["年龄","有工作","有自己的房子","信贷情况"]
def splitData(D,index):
kArray=np.unique(D[:,index].reshape(1,len(D)))
#循环多个分类,计算这个分类的熵,最后求和
returnJSon={};
for i in range(len(kArray)):
#获取等于当前分类的数据行
ck=[row for row in D if row[index]==kArray[i]]
returnJSon[i]=np.array(ck)
return returnJSon;
def createDecisionTree(D):
buildTree=None
#如果传入的D没有数据或者第5列(是否贷款)只有一个分类值,就说明已经是叶子节点了,直接返回结论值
resultUniqueArray=np.unique(D[:,4].reshape(1,len(D)))
print(resultUniqueArray,len(D),len(resultUniqueArray))
if(len(D)==0 or len(resultUniqueArray)==1):
return resultUniqueArray[0]
#获取特征数
feature_count=D.shape[1]
#算出每个特征的信息增益
grain=[calaInfoGrain(D,i)for i in range(feature_count-1)]
#获取信息增益最大的特征值
maxFeatureIndex=np.argmax(grain);
#创建一个json对象,里面有个当前特征名称的对象:比如{'有自己的房子': {}}
buildTree={colLabels[maxFeatureIndex]:{}};
#循环每个独立的特征值
featureGroup=splitData(D,maxFeatureIndex)
for featureValue in featureGroup:
buildTree[colLabels[maxFeatureIndex]][featureValue]=createDecisionTree(featureGroup[featureValue])
return buildTree;
print(createDecisionTree(dataSet))
Visualización del árbol de decisiones
Graphviz es simple y fácil de entender. Aquí usamos Graphviz para la visualización.
Descargue Graphviz y elija agregar el entorno a PATH.
componentes de instalación de Python
pip install graphviz
dibujo de código
from graphviz import Digraph
import uuid
def graphDecisionTree(dot,treeNode,parentName,lineName):
for key in treeNode:
if type(key)==int:
if type(treeNode[key])==str or type(treeNode[key])==np.str_:
#因为会出现两个yes,所以可能不能出现一个分叉而直接指向了,所以名字加上个uuid区分
node_name=str(treeNode[key])+str(uuid.uuid1())
dot.node(name=node_name, label=str(treeNode[key]), color='red',fontname="Microsoft YaHei")
dot.edge(str(parentName),str(node_name), label=str(key), color='red')
else:
graphDecisionTree(dot,treeNode[key],parentName,key)
elif type(treeNode[key])==dict:
graphDecisionTree(dot,treeNode[key],key,None)
if type(key)==str or type(treeNode[key])==str:
dot.node(name=key, label=str(key), color='red',fontname="Microsoft YaHei")
if parentName is not None and lineName is not None:
dot.edge(parentName,key, label=str(lineName), color='red')
dot = Digraph(name="pic", comment="测试", format="png")
graphDecisionTree(dot,decisionTreeJson,None,None)
dot.render(filename='my_pic',
directory='.', # 当前目录
view=True)
Diagrama de flujo de salida
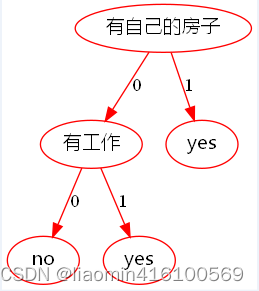
Realizar clasificación utilizando árboles de decisión.
Después de construir el árbol de decisión basado en los datos de entrenamiento, podemos usarlo para clasificar los datos reales. Al realizar la clasificación de datos, se requiere un árbol de decisión junto con los vectores de etiquetas utilizados para construir el árbol. Luego, el programa compara los datos de prueba con los valores en el árbol de decisión y ejecuta recursivamente el proceso hasta ingresar al nodo hoja; finalmente, los datos de prueba se definen como el tipo al que pertenece el nodo hoja. En el código para construir el árbol de decisión, puede ver que hay un parámetro featLabels. ¿Para qué se usa esto? Se utiliza para registrar cada nodo de clasificación. Cuando utilizamos el árbol de decisión para hacer predicciones, podemos ingresar los valores de los atributos de los nodos de clasificación requeridos en orden. Por ejemplo, si uso el árbol de decisión entrenado anteriormente para la clasificación, entonces solo necesito proporcionar dos datos: si la persona tiene una casa y si tiene un trabajo, sin proporcionar información redundante.
El código para la clasificación mediante árboles de decisión es muy simple, el código está escrito de la siguiente manera:
#%%
'''
在决策树中判断传入的特征是否贷款
'''
def classfiy(decisionTreeJson,featureLabel,vecTest,index):
if type(decisionTreeJson)==str or type(decisionTreeJson)==np.str_:
return decisionTreeJson
elif type(decisionTreeJson[featureLabel[index]])==dict :
return classfiy(decisionTreeJson[featureLabel[index]][vecTest[index]],featureLabel,vecTest,index+1)
else :
return decisionTreeJson
print("是" if classfiy(decisionTreeJson,featureLabel,[1,0],0)=='yes' else "否")
Almacenamiento del árbol de decisiones
Solo usa la serialización
import pickle
#写入
with open(filename, 'wb') as fw:
pickle.dump(inputTree, fw)
#读取
fr = open(filename, 'rb')
json=pickle.load(fr)
Sklearn utiliza árboles de decisión para predecir tipos de ojos de contacto
Antecedentes prácticos
Vayamos al grano de este artículo: ¿Cómo determinan los oftalmólogos el tipo de lentes de contacto que debe usar un paciente? Una vez que comprendamos cómo funcionan los árboles de decisión, podremos incluso ayudar a las personas a determinar el tipo de lentes que deben usar.
El conjunto de datos de lentes de contacto es un conjunto de datos muy famoso que contiene muchas condiciones de observación que cambian el estado de los ojos y el tipo de lentes de contacto recomendados por los médicos. Los tipos de lentes de contacto incluyen lentes duros, blandos y sin lentes. Fuente de datos y base de datos UCI, dirección de descarga del conjunto de datos: https://github.com/lzeqian/machinelearntry/blob/master/sklearn_decisiontree/lenses.txt
Hay 24 conjuntos de datos en total. Las etiquetas de los datos son edad, prescripción, astigmático, tasa de desgarro y clase. Es decir, la primera columna es la edad, la segunda columna son los síntomas y la tercera columna es si el astigmatismo es presente, la cuarta columna es el número de lágrimas, y la cuarta columna es el número de lágrimas. Las cinco columnas son las etiquetas de clasificación final. Los datos se muestran en la siguiente figura:
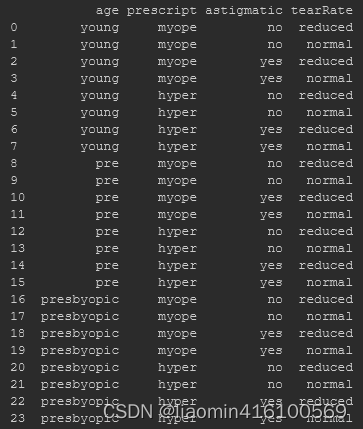
Puede utilizar un programa Python ya escrito para crear un árbol de decisiones, pero para continuar aprendiendo, este artículo utiliza Sklearn.
Construya un árbol de decisiones usando Sklearn
Dirección oficial del documento en inglés: http://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
El módulo sklearn.tree proporciona modelos de árboles de decisión para resolver problemas de clasificación y regresión. El método se muestra en la siguiente figura:
Este contenido práctico utiliza DecisionTreeClassifier y export_graphviz, el primero se usa para la construcción del árbol de decisión y el segundo para la visualización del árbol de decisión.
DecisionTreeClassifier construye un árbol de decisión:
Primero echemos un vistazo a la función DecisionTreeClassifier, que tiene un total de 12 parámetros:

La descripción del parámetro es la siguiente:
- criterio: criterio de selección de características, parámetro opcional, el valor predeterminado es gini y se puede configurar en entropía. Gini es la impureza de Gini, que es la tasa de error esperada al aplicar aleatoriamente un determinado resultado de un conjunto a un determinado elemento de datos. Es una idea basada en estadísticas. La entropía es la entropía de Shannon, que es la que comentamos en el artículo anterior, es una idea basada en la teoría de la información. Sklearn establece gini como parámetro predeterminado. Debería haberse considerado en consecuencia. ¿Quizás la precisión sea mayor? El algoritmo ID3 usa entropía y el algoritmo CART usa gini.
- divisor: estándar de selección de puntos de división de características, parámetro opcional, el valor predeterminado es el mejor y se puede configurar como aleatorio. Estrategia de selección para cada nodo. El mejor parámetro selecciona las mejores características de segmentación según el algoritmo, como gini y entropía. Random encuentra aleatoriamente el punto de división óptimo local entre algunos puntos de división. El "mejor" predeterminado es adecuado cuando el tamaño de la muestra es pequeño, y si el tamaño de los datos de la muestra es muy grande, se recomienda "aleatorio" para la construcción del árbol de decisión.
-max_features: el número máximo de características consideradas al dividir, parámetro opcional, el valor predeterminado es Ninguno. El número máximo de características consideradas al buscar la mejor segmentación (n_features es el número total de características), existen las siguientes 6 situaciones:
- Si max_features es un número entero, se consideran las características de max_features;
- Si max_features es un número de punto flotante, considere las características int(max_features * n_features);
- Si max_features está configurado en automático, entonces max_features = sqrt(n_features);
- Si max_features está configurado en sqrt, entonces max_featrues = sqrt(n_features), lo mismo que auto;
- Si max_features está configurado en log2, entonces max_features = log2(n_features);
- Si max_features se establece en Ninguno, entonces max_features = n_features, es decir, se utilizan todas las funciones.
- En términos generales, si el número de características de muestra no es mucho, como menos de 50, podemos usar el valor predeterminado "Ninguno". Si el número de características es muy grande, podemos usar de manera flexible otros valores que acabamos de describir para controlar el característica más grande considerada al dividir el número para controlar el tiempo de generación del árbol de decisión.
- max_ Depth: la profundidad máxima del árbol de decisión, parámetro opcional, el valor predeterminado es Ninguno. Este parámetro es el número de niveles del árbol. El concepto de niveles es que, por ejemplo, en el ejemplo del préstamo, el número de niveles del árbol de decisión es 2 niveles. Si este parámetro se establece en Ninguno, el árbol de decisión no limitará la profundidad del subárbol al construir el subárbol. En términos generales, puede ignorar este valor cuando hay pocos datos o pocas funciones. O hasta que haya menos de min_smaples_split muestras si se establece el parámetro min_samples_slipt. Si el modelo tiene un tamaño de muestra grande y muchas características, se recomienda limitar la profundidad máxima, cuyo valor específico depende de la distribución de los datos. Los valores utilizados habitualmente pueden oscilar entre 10 y 100.
- min_samples_split: el número mínimo de muestras necesarias para la redivisión del nodo interno, parámetro opcional, el valor predeterminado es 2. Este valor limita las condiciones bajo las cuales el subárbol puede continuar dividiéndose. Si min_samples_split es un número entero, entonces min_samples_split se utiliza como el número mínimo de muestras al dividir nodos internos, es decir, si las muestras son menores que min_samples_split, deje de dividir. Si min_samples_split es un número de coma flotante, entonces min_samples_split es un porcentaje, ceil(min_samples_split * n_samples), y el número se redondea hacia arriba. Si el tamaño de la muestra no es grande, no hay necesidad de preocuparse por este valor. Si el tamaño de la muestra es de magnitud muy grande, se recomienda aumentar este valor.
- min_samples_leaf: número mínimo de muestras para nodos hoja, parámetro opcional, el valor predeterminado es 1. Este valor limita el número mínimo de muestras para los nodos de hoja. Si el número de un nodo de hoja es menor que el número de muestras, se podará junto con sus nodos hermanos. El nodo hoja requiere el número mínimo de muestras, es decir, cuántas muestras se necesitan para llegar finalmente al nodo hoja y contar como nodo hoja. Si se establece en 1, se construirá un árbol de decisión incluso si solo hay 1 muestra en esta categoría. Si min_samples_leaf es un número entero, entonces min_samples_leaf se utiliza como el número mínimo de muestras. Si es un número de coma flotante, entonces min_samples_leaf es un porcentaje. Igual que arriba, celi(min_samples_leaf * n_samples), el número se redondea hacia arriba. Si el tamaño de la muestra no es grande, no hay necesidad de preocuparse por este valor. Si el tamaño de la muestra es de magnitud muy grande, se recomienda aumentar este valor.
- min_weight_fraction_leaf: la suma mínima del peso de muestra de los nodos de hoja, parámetro opcional, el valor predeterminado es 0. Este valor limita el valor mínimo de la suma de pesos de todas las muestras de un nodo hoja. Si es menor que este valor, se podará junto con sus nodos hermanos. En términos generales, si tenemos muchas muestras con valores faltantes, o la desviación de la categoría de distribución de las muestras del árbol de clasificación es grande, se introducirán pesos de muestra y debemos prestar atención a este valor.
- max_leaf_nodes: número máximo de nodos hoja, parámetro opcional, el valor predeterminado es Ninguno. Al limitar el número máximo de nodos de hojas, se puede evitar el sobreajuste. Si se agregan restricciones, el algoritmo construirá un árbol de decisión óptimo dentro del número máximo de nodos hoja. Si no hay muchas características, no es necesario considerar este valor, pero si hay muchas características, se puede restringir y el valor específico se puede obtener mediante validación cruzada.
- class_weight: peso de categoría, parámetro opcional, el valor predeterminado es Ninguno, también puede ser diccionario, lista de diccionarios o equilibrado. Especificar el peso de cada categoría de muestras es principalmente para evitar que el conjunto de entrenamiento tenga demasiadas muestras de ciertas categorías, lo que hace que el árbol de decisión entrenado esté demasiado sesgado hacia estas categorías. El peso de la categoría se puede dar en el formato {class_label:peso}. Aquí puede especificar el peso de cada muestra usted mismo o utilizar equilibrado. Si utiliza equilibrado, el algoritmo calculará el peso por sí solo. El peso de la muestra correspondiente a la categoría con un tamaño de muestra pequeño será alto. Por supuesto, si la distribución de categorías de su muestra no tiene un sesgo obvio, puede ignorar este parámetro y seleccionar el valor predeterminado Ninguno.
- random_state: parámetro opcional, el valor predeterminado es Ninguno. Semilla de número aleatorio. Si es un certificado, random_state se utilizará como semilla de números aleatorios para el generador de números aleatorios. Semilla de número aleatorio: Si no se establece ningún número aleatorio, el número aleatorio está relacionado con la hora actual del sistema y es diferente en cada momento. Si se establece una semilla de número aleatorio, el mismo número aleatorio generado en diferentes momentos será el mismo con la misma semilla de número aleatorio. Si es una instancia de RandomState, entonces random_state es el generador de números aleatorios. Si no hay ninguno, el generador de números aleatorios utiliza np.random.
- min_impurity_split: impureza mínima de la división del nodo, parámetro opcional, el valor predeterminado es 1e-7. Este es un umbral que limita el crecimiento del árbol de decisión. Si la impureza (coeficiente de Gini, ganancia de información, error cuadrático medio, diferencia absoluta) de un nodo es menor que este umbral, el nodo ya no generará nodos secundarios. Ese es el nodo hoja.
preordenar: si los datos están preordenados, parámetro opcional, el valor predeterminado es Falso, este valor es un valor booleano, el valor predeterminado es Falso para no ordenar. En términos generales, si el tamaño de la muestra es pequeño o el árbol de decisión con una profundidad pequeña es limitado, establecerlo en verdadero puede hacer que la selección de los puntos de división sea más rápida y el árbol de decisión se construya más rápido. Si el tamaño de la muestra es demasiado grande, no habrá ningún beneficio. El problema es que cuando el tamaño de la muestra es pequeño, mi velocidad no es lenta. Por lo tanto, este valor generalmente se ignora.
Además de prestar atención a estos parámetros, otros puntos a los que se debe prestar atención al ajustar los parámetros incluyen:
- Cuando el número de muestras es pequeño pero las características de la muestra son muy grandes, es fácil sobreajustar el árbol de decisión. En términos generales, es más fácil construir un modelo robusto cuando el número de muestras es mayor que el número de características.
- Si el número de muestras es pequeño pero las características de la muestra son muy grandes, antes de ajustar el modelo de árbol de decisión, se recomienda realizar una reducción dimensional, como el análisis de componentes principales (PCA), la selección de características (Losso) o el análisis de componentes independientes (ICA). ). La dimensionalidad de dichas características se reducirá considerablemente. Entonces será mejor ajustarse al modelo de árbol de decisión.
- Se recomienda utilizar la visualización de árboles de decisión y, al mismo tiempo, limitar primero la profundidad del árbol de decisión, de modo que primero pueda observar el ajuste preliminar de los datos en el árbol de decisión generado y luego decidir si aumentar la profundidad. profundidad.
- Al entrenar el modelo, preste atención al estado de categoría de las muestras (principalmente refiriéndose al árbol de clasificación). Si la distribución de categorías es muy desigual, considere usar class_weight para limitar que el modelo esté demasiado sesgado hacia categorías con muchas muestras.
- La matriz del árbol de decisión utiliza el tipo float32 de numpy. Si los datos de entrenamiento no están en este formato, el algoritmo los copiará primero y luego los ejecutará.
- Si la matriz de muestra de entrada es escasa, se recomienda llamar a csc_matrix sparse antes del ajuste y a csr_matrix sparse antes de la predicción.
sklearn.tree.DecisionTreeClassifier() proporciona algunos métodos que podemos usar, como se muestra en la siguiente figura:
Sabiendo esto, podemos escribir código.
Nota: Debido a que la función fit() no puede recibir datos de tipo cadena, puede ver en la información impresa que todos los datos son de tipo cadena. Antes de usar la función fit(), necesitamos codificar el conjunto de datos. Aquí se pueden usar dos métodos:
- LabelEncoder: convierte una cadena en un valor incremental
- OneHotEncoder: convierte una cadena a un número entero usando el algoritmo One-of-K
Para serializar datos de tipo cadena, primero debemos generar datos de pandas, lo que facilitará nuestro trabajo de serialización. El método que utilizo aquí es datos originales->diccionario->datos de pandas, y el código es el siguiente:
#%%
import numpy as np
import pandas as pd
fr = open('lenses.txt')
lenses = np.array([inst.strip().split('\t') for inst in fr.readlines()])
print(lenses)
#四个特征一列是:年龄,第二列是症状,第三列是是否散光,第四列是眼泪数量
#,第五列是最终的分类标签,隐形眼镜类型包括硬材质(hard)、软材质(soft)以及不适合佩戴隐形眼镜(no lenses)
lensesLabels = ['age', 'prescript', 'astigmatic', 'tearRate']
#最终分类在最后一列
lenses_target = [each[-1] for each in lenses]
print(lenses_target)
#%%
#组装成带有表头的数据格式
lensesDataFrame=np.concatenate((np.array([lensesLabels]),lenses[:,0:4]))
'''
注意dataframe的用法
df['a']#取a列
df[['a','b']]#取a、b列
默认的表头是0,1,2这样的序号,如果需要自定义表头需要定义json
{
"age":[young,pre],
"prescript":["myope","myope"]
}
'''
jsonData= {l:lenses[:,i]for i,l in enumerate(lensesLabels)}
lenses_pd = pd.DataFrame(jsonData) #生成pandas.DataFrame
print(lenses_pd)
#%%
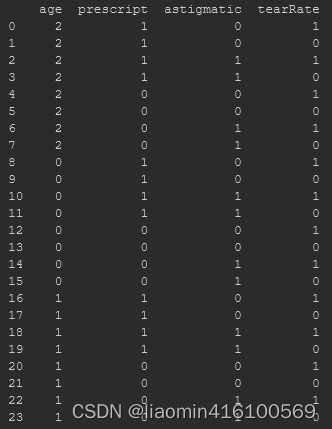
from sklearn.preprocessing import LabelEncoder
# 将所有的label 比如young转换成0,pre转为成1这样的数字编码
le = LabelEncoder()
#传入一个一维的数字,在这个数组里,相同的字符串转换为相同的数字
for i in lenses_pd.columns:
lenses_pd[i]=le.fit_transform(lenses_pd[i])
print(lenses_pd)
Visualizando árboles de decisión usando Graphviz
Graphviz se ha instalado antes, instale una biblioteca pydotplus
pip3 install pydotplus
escribir codigo
#使用sklearn决策树
from sklearn import tree
import pydotplus
from io import StringIO
clf = tree.DecisionTreeClassifier(max_depth = 4) #创建DecisionTreeClassifier()类
clf = clf.fit(lenses_pd.values.tolist(), lenses_target) #使用数据,构建决策树
dot_data = StringIO()
tree.export_graphviz(clf, out_file = dot_data, #绘制决策树
feature_names = lenses_pd.keys(),
class_names = clf.classes_,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("tree.pdf")
Ejecute el código y se generará un archivo PDF llamado árbol en el mismo directorio donde se guarda el archivo python, abra el archivo y podremos ver la visualización del árbol de decisión.
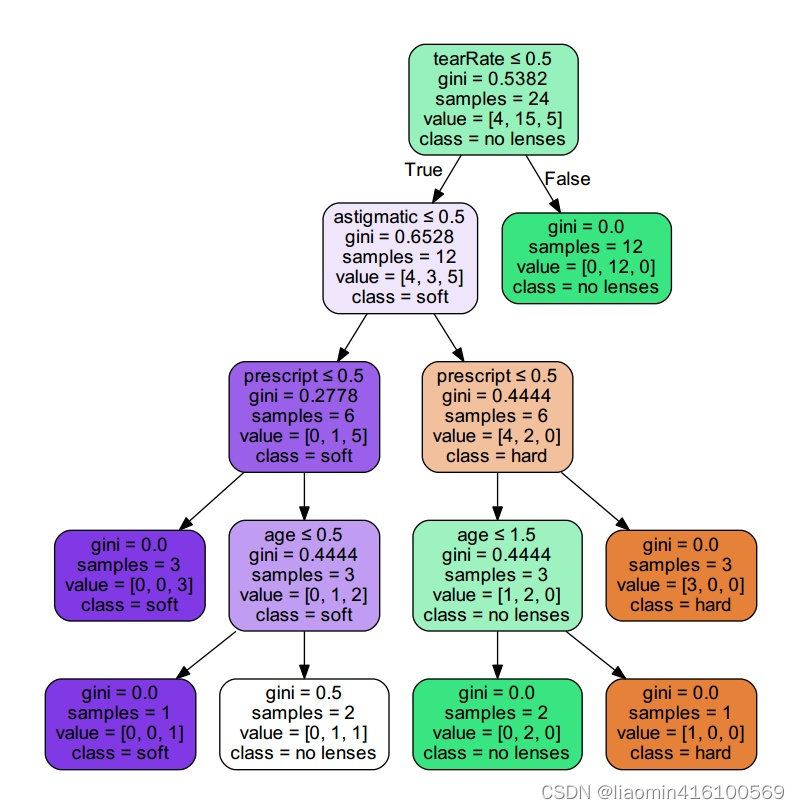
Después de determinar el árbol de decisión, podemos hacer predicciones. Puedes echar un vistazo a qué tipo de material de lentes de contacto es adecuado para ti en función de tu condición ocular, edad y otras características. Utilice el siguiente código para ver los resultados de la predicción:
print(clf.predict([[1,1,1,0]]))
Resumir
Algunas ventajas de los árboles de decisión:
- Fácil de entender y explicar. Se pueden visualizar árboles de decisión.
- Se requiere poco preprocesamiento de datos. Otros métodos suelen requerir la estandarización de los datos, la creación de variables ficticias y la eliminación de valores faltantes. Los árboles de decisión aún no admiten valores faltantes.
- El costo de usar un árbol (por ejemplo, predecir datos) es el logaritmo del número de puntos de datos de entrenamiento.
- Puede manejar variables numéricas y categóricas. La mayoría de los demás métodos son adecuados para analizar un conjunto de variables.
- Puede manejar problemas de variables de salida de múltiples valores.
- Utilice un modelo de caja blanca. Esta regla se expresa fácilmente mediante juicios lógicos si se observa una situación. Por el contrario, en el caso de un modelo de caja negra (como una red neuronal artificial), los resultados serán muy difíciles de interpretar.
- Incluso para modelos reales, se puede aplicar bien incluso cuando los supuestos no son válidos.
Algunas desventajas de los árboles de decisión:
- El aprendizaje del árbol de decisiones puede crear un árbol que sea demasiado complejo y no prediga bien los datos. Eso es sobreajuste. El mecanismo de poda (no compatible ahora), que establece la cantidad mínima de muestras requeridas para un nodo de hoja, o la profundidad máxima del número, puede evitar el sobreajuste.
- Los árboles de decisión pueden ser inestables porque incluso mutaciones muy pequeñas pueden producir un árbol completamente diferente. Este problema se soluciona mediante árboles de decisión con un conjunto.
- Los conceptos son difíciles de aprender porque los árboles de decisión no los explican bien, por ejemplo, problemas XOR, paridad o multiplexor.
- Si ciertas clasificaciones dominan, el árbol de decisión creará un árbol sesgado. Por lo tanto, se recomienda tomar muestras para equilibrar las muestras antes del entrenamiento.
otro: