(D) Árbol de decisiones Árbol de decisiones
concepto básico
árbol de decisión (árbol de decisión) se basa en una probabilidad conocida de ocurrencia de las diversas situaciones de huelga un valor actual neto del valor esperado es mayor que la probabilidad mediante la construcción de un árbol de decisión es igual a cero, la evaluación de riesgos del proyecto, el método de análisis de decisión para determinar su viabilidad, es método gráfico para uso intuitivo de análisis probabilístico. Debido a esta decisión ramas pintadas gráficos como las ramas de un árbol, los llamados árboles de decisión.
aprendizaje automático, árbol de decisión es un modelo predictivo, sino que representa una relación de correspondencia entre el objeto y el valor del atributo del objeto. Cada nodo del árbol representa un objeto, y un valor de atributo para cada ruta posible representa bifurcado, y cada nodo hoja correspondiente al objeto desde el nodo raíz a la hoja nodo el camino indicado experimentado por el valor.
Una sola salida de árbol de decisión, Ruoyu tiene salidas complejas, puede crear un árbol de decisión independiente para controlar la salida diferente. Decisión La minería de datos del árbol es una técnica usada a menudo, se puede utilizar para analizar los datos, también se puede utilizar para hacer predicciones. En resumen, el árbol de decisión (árbol de decisión) es un métodos de clasificación y regresión básicos.
En la clasificación, basado en la característica de la instancia de proceso representa clasificación. Se puede considerar como un conjunto de reglas si-entonces pueden ser considerados como una probabilidad condicional definido en el espacio de características con la distribución de espacio. El modelo principal es un poco legible velocidad de clasificación, rápido. Aprendizaje, utilizando los datos de entrenamiento, con base en función de la pérdida de minimizar construir una decisión principios modelo de árbol. Cuando la predicción de nuevos datos, la decisión de clasificar el uso del modelo de libro.
Los datos generados a partir de la técnica de aprendizaje automático árbol de decisiones de aprendizaje llamado árbol de decisión. Decisión de aprendizaje árbol típicamente comprende tres etapas: selección de características , árbol de decisión de generación y de poda .
Decisión algoritmo de clasificación de árboles
| Árbol de decisiones Algoritmo | Descripción del algoritmo |
| algoritmo ID3 | El núcleo se encuentra en los niveles de los nodos del árbol de decisión, el método que utiliza la propiedad ganancia de información como criterio de selección, se determina que ayuda a generar las propiedades adecuadas para ser utilizado en cada nodo |
| C4.5 | C4.5 algoritmo de árbol de decisión es un algoritmo de clasificación algoritmo de aprendizaje automático árbol de decisión, el algoritmo básico es el algoritmo ID3. C4.5 algoritmo hereda las ventajas de ID3 y el algoritmo ID3 para mejorar en las siguientes áreas: (1) con una relación de ganancia de información para seleccionar Propiedades, seleccione el valor para superar el sesgo de los muchos atributos con ganancia de información de atributos cuando la selección es insuficiente; (2) la poda el proceso de construcción del árbol; (3) para completar el procesamiento de los atributos continuos discretos; (4) se pueden procesar los datos es incompleta. C4.5 algoritmo tiene las siguientes ventajas: clasificación generar reglas más fácil de entender, de alta tasa de precisión. La desventaja es que: durante la construcción del árbol, es necesario ajustar los datos de la exploración y clasificación de una pluralidad de veces, lo que resulta en el algoritmo ineficiente secuencialmente. |
| algoritmo CART | CART (clasificación y regresión árbol) Que algoritmo de árbol de clasificación y regresión, que es una implementación del árbol de decisión. Carro binario algoritmo recursivo es una técnica de segmentación, la muestra actual se divide en dos sub-muestras, de tal manera que cada nodo no hoja tiene dos ramas generados, por lo algoritmo de árbol de decisión Carro genera una estructura de árbol binario es simple. Como el algoritmo CART se compone de un árbol binario, que a cada paso de la toma de decisiones sólo puede ser "sí" o "no", una característica incluso si hay varios valores, los datos se divide en dos partes. En el algoritmo de la compra está dividido en dos pasos: (1) Árbol de decisiones: Una muestra de la contribución proceso de partición recursiva, árbol de decisión generó lo más grande posible; (2) del árbol de decisiones poda: la poda con los datos de verificación, como una función del tiempo con una mínima pérdida de los criterios de poda. |
Las ventajas y desventajas del árbol de decisión
Ventajas: complejidad computacional no es alto, la salida es fácil de entender, la supresión de los valores intermedios son datos insensibles procesamiento de características irrelevantes.
Contras: pueden causar problema del exceso de juego.
Aplicable Tipo de datos: numérico y el tipo nominal
Cuando se construye un árbol de decisiones, la primera pregunta que tenemos que abordar es el conjunto de datos actual que cuenta con desempeñar un papel decisivo en la división de clasificación de datos. Para encontrar la característica decisiva, labrado los mejores resultados, hay que evaluar cada función. Después de completar la prueba, el conjunto de datos original se dividió en varios subconjuntos de datos. Estos datos subconjuntos distribuidos en el primer punto de decisión en todas las ramas. Si los datos en una rama del mismo tipo, no más lejos división del conjunto de datos. Si los datos dentro del subconjunto de datos no pertenece al mismo tipo, entonces la necesidad de repetir los datos del proceso dividido en subconjuntos. Partición de los mismos subconjuntos de datos procedimiento, y dividir el conjunto de datos original hasta que todos los datos están en el mismo tipo de datos dentro de un subconjunto.
El siguiente es un árbol de decisión basado en los datos de ganancia generados establecidos sandía 2.0. Cita de "aprendizaje automático" (Zhou Zhihua, Tsinghua University Press, P78)

Clasificación modelo de árbol es una descripción de la instancia de árbol de clasificación. Árbol de decisión formada por la unión (nodo) a un lado y con una composición (borde dirigido). Hay dos tipos de nodos: nodo interno (nodo interno) y el nodo hoja (nodo hoja) nodo representa las características internas o propiedades de un nodo hoja representa una clase.
, A partir de la clasificación árbol de decisión raíz de un ejemplo característico de un ensayo de acuerdo con resultados de pruebas, será asignado a sus instancias nodo hijo; en este caso, corresponde cada nodo hijo a un valor de la función. Así recursivamente por ejemplo, para prueba y distribución, hasta alcanzar un nodo hoja. La última instancia de la clase asignada al nodo hoja.
reglas del árbol y si-entonces
árbol de decisión puede ser pensado como un conjunto de reglas si-entonces. Un árbol de decisión construido regla desde el nodo raíz a un nodo hoja; en el que el nodo interno condición de una regla correspondiente, y la clase correspondiente al nodo de hoja de las conclusiones de la regla.
camino de árbol de decisión o un conjunto correspondiente de reglas si-entonces tienen una importante propiedad: exclusiva y completa. Es decir, no es una ruta de ejemplo uno o están cubiertos por una regla, y la preparación de un camino cubierto por una norma o.
estructura de árbol de decisión
predicciones realizar a través de un árbol de decisión requiere el siguiente procedimiento:
La recogida de datos: Se puede utilizar cualquier método. Por ejemplo, quieren construir un sistema de citas, podemos obtener datos de celestina allí, o visitando cita a ciegas. De acuerdo con factor en su consideración y resultado de la selección final, podemos conseguir un poco para nuestro uso de los datos.
Preparación de los datos: la recopilación de datos haya terminado, tenemos que resolver, esta información recopilada toda ordenadas de acuerdo a ciertas reglas y el diseño, para facilitar nuestro tratamiento de seguimiento.
Análisis de los datos: Se puede utilizar cualquier método, una vez finalizada la construcción del árbol de decisión, que puede comprobar si una línea gráfica de árbol de decisión con las expectativas.
El entrenamiento de algoritmo: Este proceso es la construcción de un árbol de decisión, lo mismo puede también ser dicho árbol de decisiones de aprendizaje, que es la construcción de una estructura de datos de árbol de decisión.
algoritmo de prueba: experiencia con tasa de error de cálculo árbol. Cuando la tasa de error del rango aceptable, el árbol de decisión puede ser objeto de un uso.
Uso algoritmo: Este procedimiento se puede utilizar para cualquier algoritmo de aprendizaje supervisado, un árbol de decisión se puede utilizar para comprender mejor el significado interno de los datos.
Decisión algoritmo de aprendizaje es un árbol recursivo, generalmente se selecciona características óptimas, y los datos de entrenamiento se divide de acuerdo con esta función, de tal manera que cada proceso tiene un conjunto de sub-datos de la mejor clasificación. Este proceso corresponde a la división del espacio de características, pero también corresponde a una construcción de árbol de decisión.
1) Start: Construcción del nodo raíz, el nodo raíz en todos los datos de entrenamiento, para seleccionar una función óptima, de acuerdo con las características de la formación conjunto de datos se divide en subconjuntos, de manera que cada subconjunto tiene una preferencia bajo las condiciones actuales clasificación.
2) Si un subconjunto de éstos han sido capaces de sustancialmente clasificados correctamente, a continuación, construir un nodo hoja, y los subconjuntos asignados al nodo hoja correspondiente a.
3) Si existe un subconjunto no puede ser clasificado correctamente, éstas subconjunto de selección de las mejores nuevas características, continuarán siendo dividido, construir el nodo correspondiente, si de forma recursiva hasta que todo subconjunto de datos de entrenamiento es esencial clasificación correcta, o hasta que no hay características adecuadas.
4) Cada subconjunto se asigna a los nodos de hoja que tienen una clase definida, generando así un árbol de decisión.
En general, un árbol de decisión que comprende un nodo raíz, una pluralidad de nodos internos y una pluralidad de nodos de hoja; hoja de nodo corresponde a un volumen de atributos de libros; cada nodo hoja del conjunto de muestra incluido en los resultados de ensayos de propiedades son se divide en sub-nodo; el nodo raíz contiene el corpus muestra, el camino desde la raíz a cada nodo de la hoja de la bebida tenía una determinación de la secuencia de prueba. El objetivo de aprendizaje árbol de decisión es producir un fuerte árbol de generalización, que es el proceso básico es simple y sólo tiene que seguir el "divide y vencerás" estrategia (divide y vencerás), como se muestra a continuación:

Obviamente, el árbol de decisiones es un proceso recursivo. En el algoritmo básico de árbol de decisión, hay tres situaciones pueden conducir a un retorno recursiva:
- El nodo de la muestra actual contiene el pleno consentimiento de perteneciente a la categoría, hay división;
- El conjunto actual de atributos está vacía, todas las muestras o los valores de la misma en todas las propiedades no se pueden dividir;
- conjunto de muestras incluidas en el nodo actual está vacía, no se puede dividir.
En el segundo caso, se calificó el nodo actual es un nodo hoja, y su categoría configurar para los nodos de tipo de muestra contenía; en el tercer escenario, la misma marca el nodo actual es una hoja nodo, que fijará su nodo de las categorías contenidas en la muestra hasta su categoría principal. Tenga en cuenta que en ambos casos una diferencia de fondo: en el caso de usar dos distribución posterior del nodo actual, y el caso de las tres muestras es el nodo padre distribución a priori como la distribución del nodo actual.
Árbol de decisiones y la distribución de probabilidad condicional
Condicional árbol de distribución de probabilidad definida en una partición del espacio de características. El espacio de características se divide en mutuamente excluyentes región célula o área de la celda, y se define en cada celda una distribución de probabilidad de clase constituye una distribución de probabilidad condicional.
Un árbol de decisión del trayecto corresponde a una unidad de la división. distribución de probabilidad condicional del árbol de decisión representado en la clase de probabilidad condicional a las unidades respectivas en virtud de componentes de distribución de condiciones predeterminadas.
X es una variable aleatoria asume características, X es una variable aleatoria que representa la clase, entonces la distribución de probabilidad condicional P (Y | X) .X tomado de la unión al conjunto de división, pero, Y valores dados en la clase . La probabilidad condicional en cada nodo hoja es generalmente a una cierta probabilidad de la clase más grande.
aprendizaje de árbol de decisión
aprendizaje de árbol de decisión es un conjunto de datos de entrenamiento para estimar el modelo de probabilidad condicional . modelo de probabilidad condicional basada en el espacio de características en clases es un número infinito. modelo de probabilidad condicional debemos elegir no sólo los datos de entrenamiento tienen un buen ajuste, sino también para tener un buen predictor de datos desconocidos .
árbol de decisiones de aprendizaje función de pérdida expresó este objetivo. Decisión de aprendizaje árbol de la pérdida de la función suele ser la regularización de la función de máxima verosimilitud . estrategia de aprendizaje árbol de decisión es la pérdida de función de la función objetivo se minimiza .
Cuando la función de pérdida OK, estudiando el problema se convierte en la elección del árbol de decisión óptima en el sentido de pérdida de problemas de la función . Debido a seleccionar los mejores árboles de decisión posible a partir del árbol de decisión es NP (no es un polinomio) problema completo , por lo que, en realidad, los algoritmos de aprendizaje de árboles de decisión típicamente emplean la heurística método (heurístico) , aproximado para resolver el problema de optimización. Tal árbol de decisión resultante es generalmente sub-óptima (sub-óptimo) de.
Decisión algoritmo de aprendizaje es un árbol recursivo, generalmente se selecciona características óptimas, y los datos de entrenamiento se divide de acuerdo con esta función, de tal manera que cada proceso tiene un conjunto de sub-datos de la mejor clasificación. Este proceso corresponde a la división del espacio de características, pero también corresponde a una construcción de árbol de decisión.
algoritmo de selección de características incluye un árbol de decisiones de aprendizaje, genera la poda de árbol de decisión del árbol. Desde el árbol de decisión representa una distribución de probabilidad condicional, diferentes matices del modelo de probabilidad correspondiente a este árbol de diversa complejidad. libro decisión generó correspondiente al modelo de selección parcial , poda de árbol de decisión correspondiente modelo de selección mundial .
los objetivos de aprendizaje de árbol de decisión: el determinado conjunto de datos de entrenamiento para construir un modelo de árbol de decisión, por lo que es posible instancias correctamente clasificar.
La naturaleza del árbol de decisiones de aprendizaje: del conjunto de entrenamiento resumió un conjunto de reglas de clasificación, o por el conjunto de datos de entrenamiento para estimar el modelo de probabilidad condicional.
Decisión función de la pérdida de aprendizaje árbol: regularización de la función de máxima verosimilitud
Decisión Prueba de Aprendizaje del árbol: para minimizar la función de pérdida
Selección de características
Si se utiliza una función de resultados de la clasificación con surtido aleatorio de demérito afirmado que esta característica no es muy diferente capacidad de clasificación no. El tiro Esta característica tiene poco efecto sobre la precisión de libro de toma de decisiones en la experiencia de aprendizaje. Por lo general, característica criterio de selección es información de ganancia o la relación de ganancia de información.
La selección de características se decide utilizar esta característica para dividir el espacio de características. Información de ganancia (ganancia de información) puede ser una buena representación de los criterios visuales.
entropía
La entropía es una medida de la pureza de la muestra, la relación Jiading D-ésima k clase de muestra conjunto de muestras de corriente representa el pk (k = 1,2, ..., | y |), la entropía se define como D :
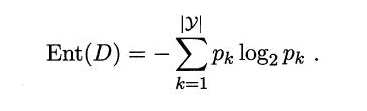
Valor (D) de la Ent más pequeño, mayor es la pureza de D.
ganancia de información

En general, cuanto mayor es la información de ganancia, quiere decir que el uso de una propiedad que se obtiene dividiendo el mayor "actualización pureza." ¿Qué es seleccionar el atributo división de ganancia de información ID3 como criterio.
Desventaja de ganancia de información
Los datos más grandes y más sobre la ganancia de información de atributos de clase, como en la ganancia de información de clave principal es muy grande, pero es evidente que dará lugar a un ajuste por exceso, por lo que hay un poco de ganancia de información defecto
tasa de ganancia
De hecho, el criterio de ganancia de información puede tener una preferencia por los grandes valores del número de atributos, tales preferencias pueden reducir los efectos adversos. C4.5 algoritmo de árbol de decisión no utiliza directamente la ganancia de información, pero el uso de la "tasa de ganancia" para seleccionar la división óptima de la propiedad, la ganancia se define como:

El más probable que un número de valores de atributos (es decir, la V más grande), el valor de IV (a) es por lo general más grande. Cabe señalar que los criterios de relación de ganancia puede ser menor número de preferencia atributo de valor, y por lo tanto no es directamente C4.5 para seleccionar la ganancia de la división más grande de la propiedad del candidato, pero el uso de una heurística: comienzan con los candidatos divididos propiedad encontrar la ganancia de información sobre el promedio propiedades, y luego elegir la tasa de ganancia más alta.
índice de Gini (GINI)
índice GINI:
1, una medida de la disparidad;
2, que normalmente se utiliza para medir la desigualdad de ingresos se puede utilizar para medir cualquier distribución no uniforme;
3, es un número entre 0 y 1, 0 exactamente iguales, 1- completamente iguales;
4, dentro de la categoría general incluye el más desordenado, GINI mayor índice (con el concepto de entropía es muy similar).
Carro árbol de decisión para seleccionar la propiedad división. conjunto de datos Pureza D se puede utilizar para medir el índice de Gini
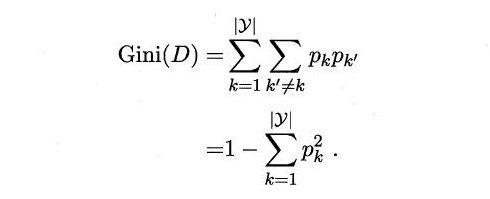
Por lo tanto, Gini más pequeño (D), mayor será la pureza del conjunto de datos D

proceso de poda
árbol de decisión es propenso a exceso de montaje, que se debe de adaptar muy bien para entrenar al conjunto de datos, pero no funciona bien en el conjunto de datos de prueba. Esta vez, ya sea de control condición de terminación de ramas de los árboles evitar demasiados pequeños por el umbral, o que haya sido formadas por el árbol de decisiones de la poda para evitar un exceso de ajuste . Otro medio para superar la exceso de montaje se basa en la idea de establecer Bootstrap Bosque aleatoria (Random Forest) .
Árbol de decisiones poda es el principal medio de tratar con "más ajustada". En el aprendizaje de árbol de decisión, con el fin de clasificar la muestra lo más correcta posible, el proceso de nodo de partición se repite, a veces resultando en rama de un árbol excesiva, entonces a veces poner sus propias características como la naturaleza general de todos los datos ha dado lugar a un exceso de ajuste, por lo tanto, , puede reducir el riesgo de exceso de montaje por activamente eliminar algunas ramas
Las estrategias básicas antes de la poda y poda, poda se refiere al proceso de árbol de decisión para cada nodo que se calcula antes de la división, si el árbol de nodos de división actual no puede traer las mejoras de rendimiento de la generalización, señal de paro de la división del nodo actual es un nodo hoja; la poda es completa iniciar el conjunto de entrenamiento para generar un árbol de decisión, y luego desde la parte inferior hacia arriba para inspeccionar los nodos que no son hojas, si el nodo correspondiente a un nodo hoja sustitución de palabras árbol de decisión puede traer generalización de rendimiento, vuelva a colocar el nodo hoja sub-árbol.
En pocas palabras:
Primera poda - durante la construcción, cuando un nodo poda condiciones se cumplen, la construcción parada inmediata de esta rama.
Después de la poda - para completar la estructura completa del árbol de decisión, a continuación, recorrer el árbol mediante la poda ciertas condiciones.
De hecho, la poda criterio es la forma de determinar el tamaño del árbol de decisiones, la poda puede referirse a las ideas son los siguientes:
(1) conjunto (conjunto de entrenamiento) utilizando un conjunto de entrenamiento y una validación (conjunto de validación), para evaluar la eficacia del método de poda nodos de poda;
(2) usando todo el conjunto de entrenamiento para el entrenamiento, pero el uso de una prueba estadística para estimar si el guarnecido un nodo particular mejorará la evaluación de los datos de rendimiento fuera del conjunto de entrenamiento, como el uso de chi-cuadrado (Quinlan, 1986) de prueba para ampliar aún más el nodo si puede mejorar el rendimiento de los datos de clasificación enteras, o simplemente mejorar el rendimiento del conjunto de datos de entrenamiento actual;
(3) el uso de criterios claros para medir la complejidad de los ejemplos de entrenamiento y el árbol de decisión, cuando el código de longitud mínima, el crecimiento del árbol parada, tales como MDL (mínimo Descripción Longitud) criterio.
Análisis de impacto
Primera poda hace que una gran cantidad de ramas no se expande, lo que no sólo reduce el riesgo de exceso de montaje, sino que también reduce significativamente el costo del tiempo de formación árbol de decisión y el tiempo de prueba. Sin embargo, aunque algunas ramas Actualmente no mejora la generalización. Y puede incluso conducir a una generalización reducción temporal, pero la posterior división en su base no podría conducir a un aumento significativo, por lo que esta naturaleza codiciosa a la poda, el árbol representa un riesgo para los menos aptos.
árbol comparativo después de la poda y pre-poda generada, puede ser visto por lo general después de la poda de ciruela más ramas de la pre-reserva, que underfitting poco riesgo, por lo que la poda de generalización a menudo debido a pre poda de árboles. Pero el proceso de poda está cortado desde la parte inferior hacia arriba, por lo que el tiempo de entrenamiento antes de podar sobrecarga que más grande.
Referencia Bowen: https://www.jianshu.com/p/61a93017bb02?from=singlemessage
Frontera de decisión de árboles de clasificación
Además, la decisión de clasificación árbol límite se ha formado una serie de características distintivas: ejes paralelos, es decir, tiene un límite libre y una pluralidad de ejes de coordenadas paralelo compuestas de segmentos.

herramienta graphviz
Graphviz es de código abierto de software de visualización gráfica . Es una visualización gráfica de la información de configuración se representa como una visión abstracta y la red de la figura método. Se tiene importantes aplicaciones en la creación de redes, la bioinformática, la ingeniería de software, bases de datos y diseño de páginas web, aprendizaje automático, y las interfaces visuales en otros campos técnicos.
Graphviz: Descargar herramientas de visualización:
https://graphviz.gitlab.io/_pages/Download/Download_windows.html
instrucción de conversión entró en la línea de comandos:
-o des.pdf -Tpdf src.dot DOT
src.dot .dot archivo se representa con el camino de
des.pdf archivo .pdf representado se genera, y preferiblemente también con un camino
Por ejemplo:
-Tpdf punto G: \ aprendizaje automático \ tree.dot -o G: \ aprendizaje automático \ tree.pdf - dot éxito archivos en formato pdf
-Tpng punto G: \ aprendizaje automático \ tree.dot -o G: \ aprendizaje automático \ tree.png - dot correctamente los archivos en un archivo PNG.
