Directorio de artículos

1 Prefacio: El azul es la columna de notas de aprendizaje automático del cielo
¡Hola, queridos lectores! Bienvenidos a mi nueva columna: " Blue is the sky machine learning notes ". No podría estar más emocionado de estar aquí para compartir mi amor y exploración del aprendizaje automático con ustedes. Esta columna se convertirá en un rincón cálido para registrar conocimientos de aprendizaje automático e intercambiar ideas, y este artículo es el primer paso de la columna.
1.1 La intención original y el posicionamiento de la columna
Como ávido entusiasta en el campo del aprendizaje automático, siempre he creído que compartir y difundir el conocimiento es la clave para promover el progreso tecnológico. La columna " Blue is the Sky's Machine Learning Notes " será una plataforma actualizada continuamente, donde compartiré mi comprensión del campo del aprendizaje automático, mi experiencia en el proceso de aprendizaje y la experiencia práctica. Espero que a través de esta columna, pueda explorar los misterios del aprendizaje automático con usted, crecer y progresar juntos.
1.2 Contenido principal de este artículo
-
Definición y significado del aprendizaje automático
En el mundo del aprendizaje automático, las computadoras ya no ejecutan pasivamente instrucciones preestablecidas, sino que pueden aprender de manera autónoma y optimizar el rendimiento a través de datos y experiencia. El aprendizaje automático ha penetrado en todos los aspectos de nuestras vidas, desde asistentes inteligentes hasta algoritmos de recomendación, mostrando su poderoso potencial de aplicación. En este artículo, le daré una introducción detallada a la definición de aprendizaje automático y su importancia en la tecnología moderna. -
Terminología básica del aprendizaje automático
Antes de adentrarse en el campo del aprendizaje automático, es muy necesario comprender alguna terminología básica. Este artículo presentará algunos términos de aprendizaje automático de uso común, como aprendizaje supervisado, aprendizaje no supervisado, ingeniería de funciones, etc., para ayudarlo a establecer una comprensión preliminar de estos conceptos y sentar una base sólida para el aprendizaje posterior. -
Explorando la teoría de la NFL
La teoría de la NFL, el teorema de "ningún almuerzo gratis", es un principio importante en el campo del aprendizaje automático. Nos dice que no existe un algoritmo que funcione de manera óptima en todas las situaciones y que diferentes problemas requieren diferentes enfoques. En este artículo, analizaré la connotación de esta teoría y exploraré el significado de su aplicación en problemas prácticos.
2 Definición de aprendizaje automático
En la era actual de explosión de la información, tratamos con todo tipo de datos todos los días. Desde los me gusta en las redes sociales y las recomendaciones en los sitios de compras, hasta los diagnósticos médicos y la conducción inteligente, nuestro mundo está cada vez más influenciado por los datos y la tecnología. Sin embargo, cómo extraer información valiosa de estos datos masivos y tomar decisiones inteligentes es un problema lleno de desafíos. En este contexto, el aprendizaje automático surgió como lo requieren los tiempos, brindando a las computadoras la capacidad de aprender y adaptarse como los humanos.
2.1 La esencia del aprendizaje automático
El aprendizaje automático es la disciplina que permite a las computadoras aprender de la experiencia para mejorar el rendimiento. Su idea central se puede entender con una simple analogía: así como predecimos el clima de mañana en función de la experiencia pasada, o recogemos un buen melón en el mercado, el aprendizaje automático permite que las computadoras obtengan "experiencia" a partir de datos históricos y generen un modelo de algoritmo a partir de datos históricos. aprendiendo estas experiencias, para emitir juicios efectivos ante nuevas situaciones.
Definición formal de Mitchell
Tom Mitchell, en su libro de texto clásico "Aprendizaje automático", da una definición formal de aprendizaje automático, que expresa este concepto de manera más precisa y concreta. Él considera el aprendizaje automático como un proceso de mejora del rendimiento, a través del aprendizaje de datos históricos para mejorar el rendimiento de los programas informáticos en una determinada clase de tareas. En la definición formal, introdujo tres elementos clave:
- P (rendimiento): Indica el rendimiento de un programa informático en una determinada clase de tarea T. Esto podría ser precisión de clasificación, error de regresión, etc., dependiendo de la naturaleza de la tarea.
- T (clase de tarea): se refiere al tipo de problema que el programa de computadora está tratando de resolver. Esto puede ser cualquier cosa, desde el reconocimiento de imágenes hasta el procesamiento del lenguaje natural.
- E (Experiencia): un conjunto de datos que representa la historia, es decir, la experiencia pasada. Estos datos se usarán para entrenar un programa de computadora para que se desempeñe mejor en la tarea T.
De acuerdo con la definición de Mitchell, si un programa de computadora mejora su desempeño P en la tarea T mediante el aprendizaje de la experiencia E, entonces se puede decir que el programa ha aprendido E.
2.2 Clasificación del aprendizaje automático
El aprendizaje automático se puede dividir en varios subcampos, incluidos, entre otros, el aprendizaje supervisado, el aprendizaje no supervisado y el aprendizaje por refuerzo. En el aprendizaje supervisado, una computadora aprende de los datos etiquetados para poder clasificar o retroceder en nuevos datos. En el aprendizaje no supervisado, las computadoras descubren patrones y estructuras a partir de datos no etiquetados para tareas como la agrupación y la reducción de la dimensionalidad. El aprendizaje por refuerzo es dejar que la computadora aprenda la estrategia óptima a través de prueba y error en el proceso de interacción con el entorno.
3 Terminología básica del aprendizaje automático
En el campo del aprendizaje automático, se utilizan muchos términos básicos para describir datos, modelos y procesos de aprendizaje, que nos ayudan a comprender y comunicarnos con mayor precisión. Profundicemos juntos en estos conceptos clave.
La composición básica de los datos
Cuando queremos dejar que la computadora aprenda, primero necesitamos un conjunto de datos como base para el aprendizaje. Tomando como ejemplo los datos de una sandía, cada registro representa la información característica de una sandía:
- Conjunto de datos: la colección de todos los registros se denomina conjunto de datos, que es la fuente de datos para nuestro aprendizaje.
- Instancia/Muestra: cada registro se denomina instancia o muestra, que es un único punto de datos en el conjunto de datos.
- Características/atributos: cada característica individual en un conjunto de datos, como "color" o "golpe", se denomina característica o atributo.
- Vector de características: un registro se puede representar como un vector de características, que es un punto en el eje de coordenadas, donde cada dimensión corresponde a una característica.
Entrenamiento y pruebas
En el aprendizaje automático, necesitamos usar parte de los datos para entrenar el modelo y luego usar otra parte de los datos para probar el rendimiento del modelo:
- Muestras de entrenamiento: las muestras de datos utilizadas para entrenar el modelo se denominan muestras de entrenamiento y estas muestras tienen información etiquetada.
- Conjunto de entrenamiento: la colección de todas las muestras de entrenamiento se denomina conjunto de entrenamiento, que es el conjunto de datos utilizado para entrenar el modelo.
- Muestras de prueba: las muestras de datos utilizadas para probar el rendimiento del modelo se denominan muestras de prueba y, por lo general, estas muestras no tienen información de etiqueta.
- Conjunto de prueba: la colección de todas las muestras de prueba se denomina conjunto de prueba, que es el conjunto de datos utilizado para evaluar el rendimiento del modelo.
Capacidad de generalización y predicción
Un buen modelo de aprendizaje automático debe tener la capacidad de adaptarse a nuevos datos, que es la capacidad de generalización:
- Capacidad de generalización: los resultados de aprendizaje del modelo en el conjunto de entrenamiento se pueden aplicar a datos no vistos, que es la capacidad de generalización del modelo.
Tipos de problemas y tareas de aprendizaje
El aprendizaje automático se puede aplicar a diferentes tipos de problemas, según la naturaleza del valor predicho:
- Clasificación: Cuando los valores pronosticados son valores discretos como melón bueno/melón malo, el problema se llama clasificación. Se puede dividir en clasificación binaria y clasificación múltiple.
- Regresión: cuando el valor pronosticado es un valor continuo, como el tamaño de la población, el problema se denomina regresión.
Aprendizaje supervisado y aprendizaje no supervisado
Según si los datos de entrenamiento tienen información etiquetada, podemos dividir las tareas de aprendizaje automático en dos categorías:
- Aprendizaje supervisado: los datos de entrenamiento se etiquetan, incluidos los problemas de clasificación y regresión.
- Aprendizaje no supervisado: los datos de entrenamiento no tienen información etiquetada, incluidas tareas como reglas de agrupación y asociación.
4 Exploración del teorema "No hay almuerzo gratis" (NFL)
En el campo del aprendizaje automático, existe un teorema ampliamente citado que revela una realidad común en una declaración concisa: no hay almuerzo gratis (No Free Lunch, NFL). La esencia de este teorema no solo tiene profundas aplicaciones en el campo del aprendizaje automático, sino que también se aplica a nuestro camino de desarrollo personal. Lea una publicación de blog anterior: Lecciones de vida en el aprendizaje automático: desarrollo personal del teorema "No hay almuerzo gratis" (NFL)
El teorema NFL (No Free Lunch Theorem) es un teorema fundamental en el campo del aprendizaje automático que proporciona información a través de la derivación matemática. La idea central del teorema es que para todos los problemas y todos los posibles algoritmos de aprendizaje, su desempeño en promedio es el mismo. Esto significa que no existe un único algoritmo que se desempeñe de manera óptima en todos los problemas.
Concretamente, supongamos que tenemos un conjunto de algoritmos de aprendizaje, denotados A = {A1, A2, … , An}, que se aplican a diferentes conjuntos de problemas D = {D1, D2, … , Dm}. Entonces el teorema de la NFL da la siguiente conclusión:
- Para un problema específico Di, cuando un algoritmo Aj funciona bien, debe haber otros problemas Dk, en los que el algoritmo Aj funciona relativamente mal.
- Para el desempeño promedio de cualquier algoritmo, su desempeño en todos los problemas es el mismo, es decir, el desempeño esperado en todos los problemas es igual.
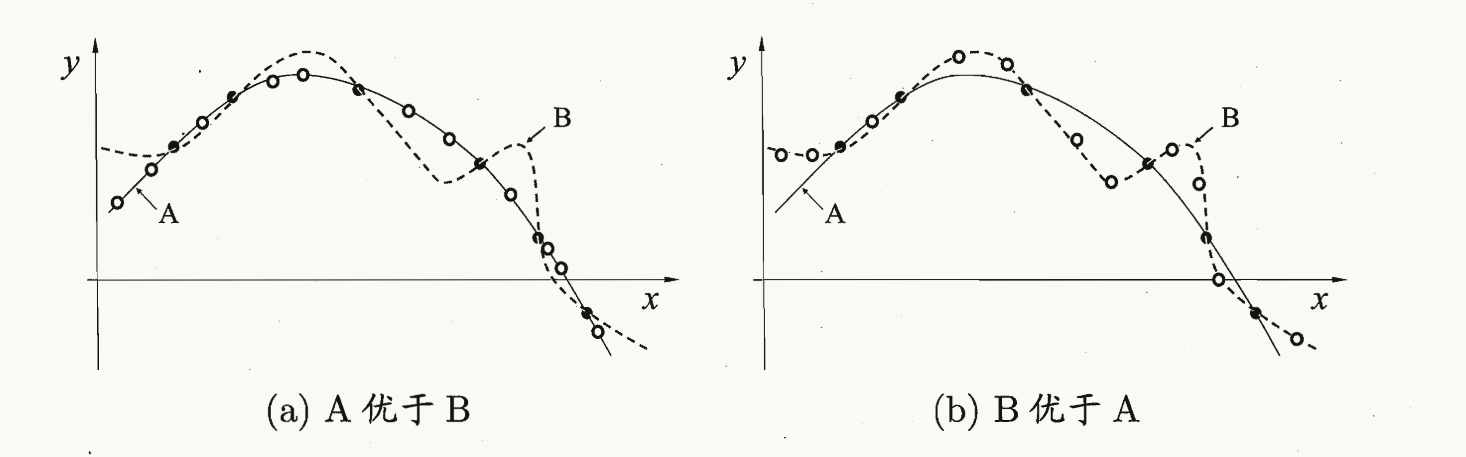
Para comprender mejor el teorema NFL, podemos realizar un análisis específico a través de la derivación de fórmulas.
Supongamos que tenemos dos algoritmos, el Algoritmo a y el Algoritmo B, que se utilizan para la generación de hipótesis y las conjeturas aleatorias, respectivamente. Considere un espacio muestral discreto X y un espacio de hipótesis H. Definimos P(h|X,a) como la probabilidad de que el algoritmo a produzca la hipótesis h basada en los datos de entrenamiento X, y asumimos que deseamos encontrar una verdadera función objetivo f. Entonces, el error del algoritmo a fuera del conjunto de entrenamiento se puede expresar como:

A través de la derivación de fórmulas, podemos ver claramente la base matemática del teorema NFL y comprender su significado. Nos recuerda que ningún algoritmo se adapta a todos los problemas porque existe una conexión inherente entre las características del problema y el algoritmo.
En el desarrollo personal, podemos extender el pensamiento del teorema de la NFL a la elección y desarrollo de carrera. Todos tienen sus propios intereses, habilidades y adaptaciones únicos, y ninguna carrera o campo es adecuado para todos. Necesitamos explorar nuestras fortalezas y encontrar oportunidades y caminos que funcionen para nosotros.
Ya sea en el aprendizaje automático o el desarrollo personal, debemos comprender y aceptar la iluminación del teorema de la NFL y encontrar oportunidades que se adapten a nosotros mediante la exploración de diversos campos. De esta manera, podemos desarrollar todo nuestro potencial y tener éxito en nuestro desarrollo personal. Vayamos más allá de los límites del teorema de la NFL y emprendamos un colorido viaje de desarrollo personal.
5. Conclusión
En Explorando el mundo del aprendizaje automático, profundizamos en la importancia del teorema "No hay almuerzo gratis" (NFL), que no solo aporta un nuevo pensamiento al aprendizaje automático, sino que también señala el camino a seguir para el desarrollo personal. Así como cada algoritmo tiene sus ventajas en diferentes problemas, cada persona también tiene puntos brillantes únicos en el escenario de la vida. En el aprendizaje automático, nos impulsan los datos, nos guían los modelos y buscamos constantemente la optimización y la innovación; en la vida, usamos el trabajo duro como fuerza motriz y los sueños como objetivo para avanzar con firmeza y lograr avances. Ya sea para resolver problemas complejos o darse cuenta del valor personal, la perseverancia y una actitud positiva son las claves del éxito.
En esta publicación de blog, nos sumergimos en la terminología básica del aprendizaje automático y analizamos las implicaciones del teorema "no hay almuerzo gratis" en el aprendizaje automático y el desarrollo personal. Ya sea que esté eligiendo el algoritmo correcto o enfrentando una sensación de brecha en el desarrollo personal, podemos extraer sabiduría de los teoremas de la NFL. Así como cada problema en el aprendizaje automático requiere un algoritmo único, todos tienen su propio camino en la vida. Es la dirección de nuestros esfuerzos comunes para absorber la experiencia del aprendizaje, continuar creciendo y avanzar gradualmente hacia el éxito.
Avancemos valientemente en la exploración del aprendizaje automático; en el viaje de la vida, defendamos la sabiduría del teorema de la NFL, superémonos constantemente y creemos un mañana mejor. Ya sea explorando los límites de la tecnología o realizando sueños personales, debemos creer firmemente que nada es imposible bajo la guía del conocimiento. Enfrentemos juntos los desafíos del futuro, contribuyamos al desarrollo del aprendizaje automático y el progreso de la vida, y escribamos nuestros propios capítulos maravillosos.
