Tabla de contenido
análisis de componentes principales
Este artículo presenta una descripción general del análisis de componentes principales y cómo Python implementa el algoritmo. Para obtener artículos sobre los principios matemáticos de los algoritmos de análisis de componentes principales, consulte este artículo:
Explorando los principios matemáticos del
método de análisis de componentes principales
¡Gracias por tu apoyo! ¡Su enlace de tres clics es la mayor motivación para mi creación!
análisis de componentes principales
1. Introducción

El análisis de componentes principales (PCA) es una técnica de extracción de características y reducción de la dimensionalidad de los datos de uso común para convertir datos de alta dimensión en representaciones de baja dimensión mientras se conservan las características principales de los datos.
Proyecta las características originales en un nuevo eje de coordenadas a través de la transformación lineal , de modo que las características proyectadas tengan la mayor variación , a fin de lograr el propósito de reducir la dimensión de los datos .
La idea principal de PCA es encontrar las direcciones principales en los datos, es decir, los componentes principales de los datos, y estos componentes principales son las direcciones en las que los datos varían más. Al retener los componentes principales más importantes, se pueden reducir las dimensiones de los datos, lo que reduce el costo de almacenamiento y computación, al tiempo que reduce el ruido y la información redundante en los datos y mejora la capacidad de generalización del modelo.
Los pasos de trabajo de PCA son los siguientes:
- datos normalizados
- Calcula la matriz de covarianza de los datos.
- Realice la descomposición de valores propios en la matriz de covarianza para obtener valores propios y vectores propios.
- Organice los valores propios en orden descendente y seleccione los vectores propios correspondientes a los primeros valores propios como los componentes principales.
- Proyecte los datos originales sobre los componentes principales seleccionados para obtener los datos reducidos dimensionalmente.
PCA tiene amplias aplicaciones en muchos campos, incluida la visualización de datos, la ingeniería de características, el reconocimiento de patrones, el procesamiento de imágenes, etc. Puede ayudarnos a comprender la estructura interna de los datos, eliminar información redundante y mejorar la eficacia y la eficiencia del modelo.
Es importante tener en cuenta que PCA asume que la distribución de datos es lineal en un espacio de alta dimensión, por lo que es posible que PCA no funcione bien en presencia de relaciones no lineales. En tales casos, se pueden considerar técnicas de reducción de dimensionalidad no lineal como el análisis de componentes principales del kernel (Kernel PCA).
2. Ayuda a entender
Cómo usar la menor cantidad de funciones y conservar los componentes principales originales, como se muestra en la figura:

3. Llamadas a la API
sklearn.descomposición.PCA(n_componentes=Ninguno)
Descomponer los datos en un espacio dimensional más bajo
n_componentes:
Decimal: indica el porcentaje de información que se retiene
entero: a cuántas características reducir
PCA.fit_transform(X) X: datos en formato de matriz numpy [n_samples, n_features]
Valor de retorno: una matriz de las dimensiones especificadas después de la conversión
# -*- coding: utf-8 -*-
# @Author:︶ㄣ释然
# @Time: 2023/8/16 15:42
from sklearn.decomposition import PCA
'''
sklearn.decomposition.PCA(n_components=None)
将数据分解为较低维数空间
n_components:
小数:表示保留百分之多少的信息
整数:减少到多少特征
PCA.fit_transform(X) X:numpy array格式的数据[n_samples,n_features]
返回值:转换后指定维度的array
'''
def pca_demo():
"""
对数据进行PCA降维
"""
data = [[2, 8, 4, 5], [6, 3, 0, 8], [5, 4, 9, 1]]
# 1、实例化PCA, 小数——保留多少信息
transfer = PCA(n_components=0.9)
# 2、调用fit_transform
data1 = transfer.fit_transform(data)
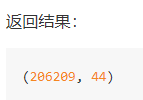
print("保留90%的信息,降维结果为:\n", data1)
# 1、实例化PCA, 整数——指定降维到的维数
transfer2 = PCA(n_components=3)
# 2、调用fit_transform
data2 = transfer2.fit_transform(data)
print("降维到3维的结果:\n", data2)
if __name__ == '__main__':
pca_demo()Resultado de salida:
4. Caso
Caso: Exploración de las preferencias del usuario para la segmentación de categorías de artículos y reducción de dimensionalidad

Los datos son los siguientes:
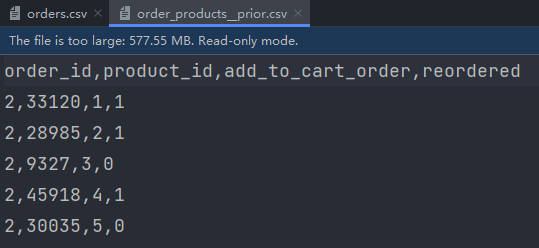
order_products__prior.csv: información de pedido y producto
campo:order_id, product_id, add_to_cart_order, reordered
products.csv: Información del Producto
campo:product_id, product_name, aisle_id, department_id
orders.csv: información del pedido del usuario
campo:order_id,user_id,eval_set,order_number,….
aisles.csv: La categoría de artículo específica a la que pertenece el producto
campo: aisle_id, aisle
paso:
Combinar tablas para que user_id y aisle estén en una tabla
Realizar una transformación de tabulación cruzada
Realizar reducción de dimensionalidad

código:
from sklearn.decomposition import PCA
import pandas as pd
def data_demo():
# 1、获取数据集
# ·商品信息- products.csv:
# Fields:product_id, product_name, aisle_id, department_id
# ·订单与商品信息- order_products__prior.csv:
# Fields:order_id, product_id, add_to_cart_order, reordered
# ·用户的订单信息- orders.csv:
# Fields:order_id, user_id,eval_set, order_number,order_dow, order_hour_of_day, days_since_prior_order
# ·商品所属具体物品类别- aisles.csv:
# Fields:aisle_id, aisle
products = pd.read_csv("data/instacart/products.csv")
order_products = pd.read_csv("data/instacart/order_products__prior.csv")
orders = pd.read_csv("data/instacart/orders.csv")
aisles = pd.read_csv("data/instacart/aisles.csv")
# 2、合并表,将user_id和aisle放在一张表上
# 1)合并orders和order_products on=order_id tab1:order_id, product_id, user_id
tab1 = pd.merge(orders, order_products, on=["order_id", "order_id"])
# 2)合并tab1和products on=product_id tab2:aisle_id
tab2 = pd.merge(tab1, products, on=["product_id", "product_id"])
# 3)合并tab2和aisles on=aisle_id tab3:user_id, aisle
tab3 = pd.merge(tab2, aisles, on=["aisle_id", "aisle_id"])
# 3、交叉表处理,把user_id和aisle进行分组
table = pd.crosstab(tab3["user_id"], tab3["aisle"])
# 4、主成分分析的方法进行降维
# 1)实例化一个转换器类PCA
transfer = PCA(n_components=0.95)
# 2)fit_transform
data = transfer.fit_transform(table)
print(data.shape)
if __name__ == '__main__':
data_demo()resultado: