1. conjunto de datos
1. Objetivo:
saber que el conjunto de datos se divide en conjunto de entrenamiento y conjunto de prueba, y
poder utilizar el conjunto de datos de sklearn.
2. Conjuntos de datos disponibles:
empresas internas, como
las interfaces de datos de Baidu y Weibo, gastan dinero en
conjuntos de datos de propiedad gubernamental.
3. Características del conjunto de datos scikit-learn utilizado en la etapa de aprendizaje
:
(1) Pequeña cantidad de datos
(2) Conveniente para el aprendizaje
Características de UCI:
(1) Contiene 360 conjuntos de datos
(2) Cubre ciencia, vida, economía y otros campos
(3) La cantidad de datos es cientos de miles
Características de Kaggle:
(1) Plataforma de competencia de big data
(2) 800.000 científicos
(3) Datos reales
(4) Gran cantidad de datos
4. Sitio
web Sitio web de Kaggle: https://www.kaggle.com/datasets
Sitio web de UCI: http://archive.ics.uci.edu/ml
Sitio web de scikit-learn: http://scikit-learn.org/stable/ conjuntos de datos
5. Introducción a la herramienta scikit-learn
Aprendizaje automático con Scikit-Learn
(1) Herramienta de aprendizaje automático en lenguaje Python
(2) scikit-learn contiene la implementación de muchos algoritmos de aprendizaje automático conocidos
(3) scikit-learn tiene documentación completa, API rica y fácil de usar
6. Instale scikit-learn
yum install python3 python3-pip
pip3 install -U scikit-learn
pip3 install -U ipython7. Verificar la instalación
$ python3 -m pip show scikit-learn
Name: scikit-learn
Version: 0.24.2
Summary: A set of python modules for machine learning and data mining
Home-page: http://scikit-learn.org
Author: None
Author-email: None
License: new BSD
Location: /usr/local/lib64/python3.6/site-packages
Requires: joblib, scipy, numpy, threadpoolctl
$ python3 -m pip freeze
joblib==1.1.1
numpy==1.19.5
scikit-learn==0.24.2
scipy==1.5.4
threadpoolctl==3.1.0
$ python3 -c "import sklearn; sklearn.show_versions()"
System:
python: 3.6.8 (default, Jun 20 2023, 11:53:23) [GCC 4.8.5 20150623 (Red Hat 4.8.5-44)]
executable: /usr/bin/python3
machine: Linux-3.10.0-1160.92.1.el7.x86_64-x86_64-with-centos-7.9.2009-Core
Python dependencies:
pip: 9.0.3
setuptools: 39.2.0
sklearn: 0.24.2
numpy: 1.19.5
scipy: 1.5.4
Cython: None
pandas: None
matplotlib: None
joblib: 1.1.1
threadpoolctl: 3.1.0
Built with OpenMP: True
8. Contenidos incluidos en scikit-learn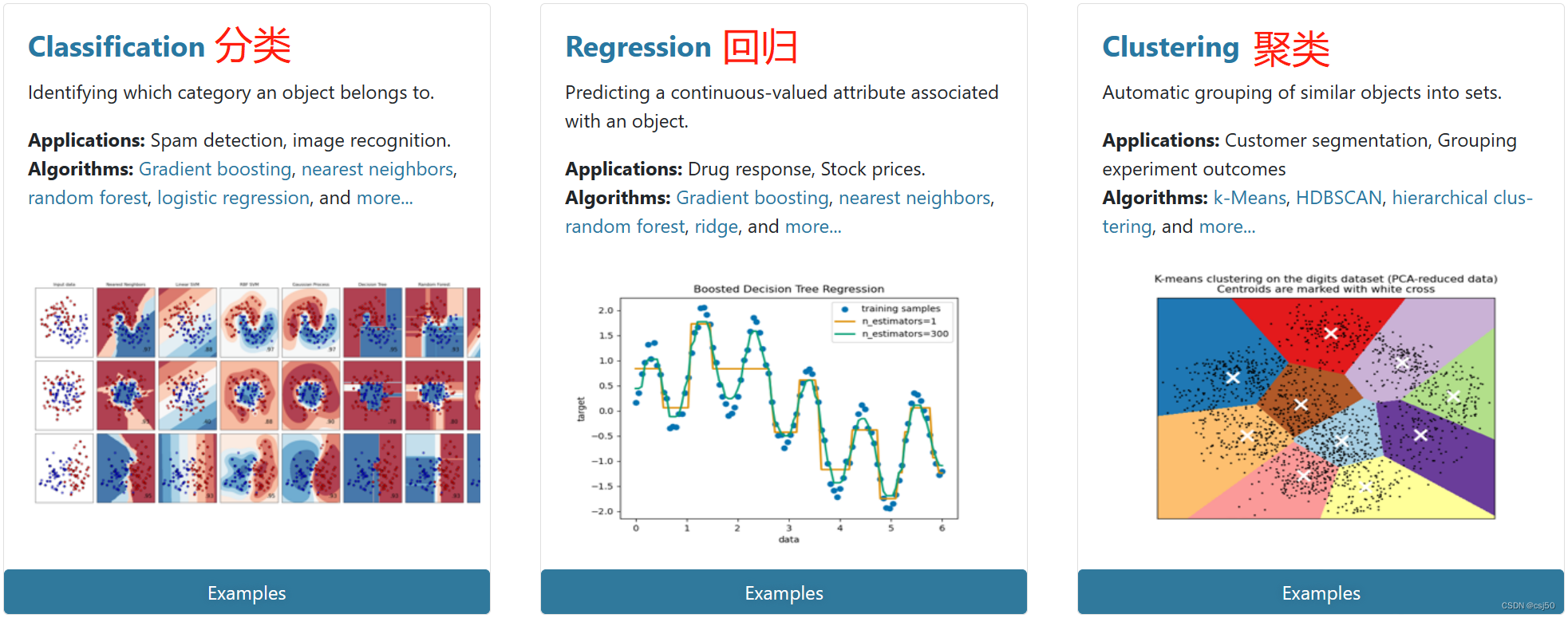
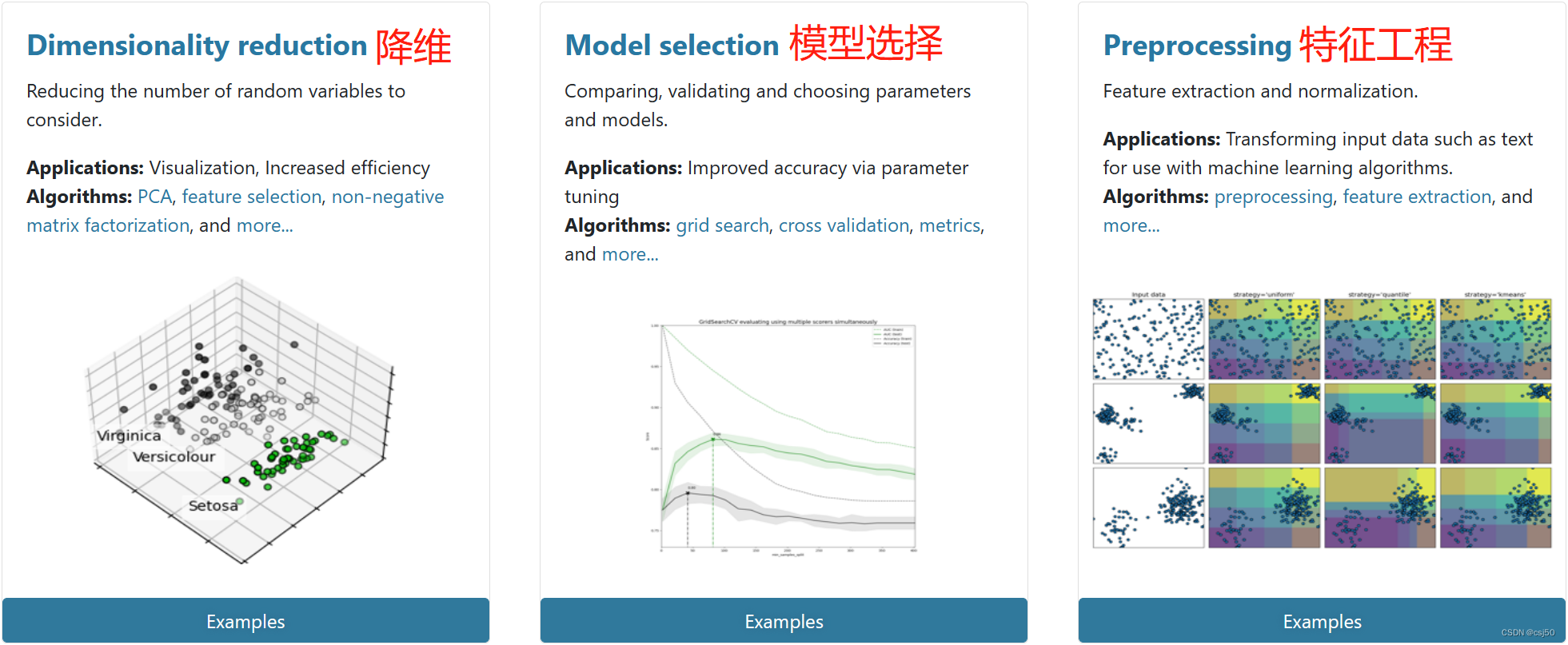
(1) Clasificación, agrupamiento, regresión
(2) Ingeniería de características
(3) Selección y optimización del modelo
2. conjunto de datos sklearn
1. Introducción a la API del conjunto de datos scikit-learn
(1) sklearn.datasets
se carga para obtener conjuntos de datos populares
datasets.load_*()
para obtener conjuntos de datos a pequeña escala, y los datos se incluyen en los conjuntos de datos
datasets.fetch_*(data_home=None)
para obtener datos a gran escala, el conjunto debe descargarse de Internet. El primer parámetro de la función es data_home, que indica el directorio donde se descarga el conjunto de datos. El valor predeterminado es ~/scikit_learn_data/
2. conjunto de datos pequeño de sklearn
(1) sklearn.datasets.load_iris()
carga y devuelve el conjunto de datos del iris
| nombre | cantidad |
| categoría | 3 |
| característica | 4 |
| Número de muestras | 150 |
| Cantidad por categoría | 50 |
(2) sklearn.datasets.load_boston()
carga y devuelve el conjunto de datos de precios de vivienda de Boston
| nombre | cantidad |
| categoría objetivo | 5-50 |
| característica | 13 |
| Número de muestras | 506 |
3. conjunto de datos grande de sklearn
(1) subconjunto sklearn.datasets.fetch_20newsgroups(data_home=None,subset='train') : 'entrenamiento' o 'prueba', 'todos', opcional, seleccione el conjunto de datos
que se va a cargar
"entrenar" para el conjunto de prueba, "prueba" para el conjunto de prueba, "todos" para ambos
4. Uso del conjunto de datos sklearn
(1) Tomando el conjunto de datos del iris como ejemplo
Conjunto de datos de flores de iris
Valores característicos: 4: pétalos, longitud y ancho de los pétalos
Valores objetivo: 3: setosa, vericolor, virginica
(2) Introducción al valor de retorno del conjunto de datos sklearn
Tipos de datos devueltos por carga y recuperación de datos datasets.base.Bunch (formato de diccionario)
: matriz de datos de características, que es una matriz numpy.ndarray bidimensional de [n_samples * n_features]
destino: datos de etiqueta, que es una matriz numpy.ndarray unidimensional de n_samples
DESCR: descripción de datos
nombres_de_características: nombre de certificado especial. Los datos de noticias, los números escritos a mano y los conjuntos de datos de regresión no tienen
target_names: nombres de etiquetas
(3) Cree el archivo day01_machine_learning.py
from sklearn.datasets import load_iris
def datasets_demo():
"""
sklearn数据集使用
"""
#获取数据集
iris = load_iris()
print("鸢尾花数据集:\n", iris)
print("查看数据集描述:\n", iris["DESCR"])
print("查看特征值的名字:\n", iris.feature_names)
print("查看特征值几行几列:\n", iris.data.shape)
return None
if __name__ == "__main__":
# 代码1:sklearn数据集使用
datasets_demo()Ejecutar: python3 day01_machine_learning.py
鸢尾花数据集:
{'data': array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2],
[5.4, 3.9, 1.7, 0.4],
[4.6, 3.4, 1.4, 0.3],
[5. , 3.4, 1.5, 0.2],
[4.4, 2.9, 1.4, 0.2],
[4.9, 3.1, 1.5, 0.1],
[5.4, 3.7, 1.5, 0.2],
[4.8, 3.4, 1.6, 0.2],
[4.8, 3. , 1.4, 0.1],
[4.3, 3. , 1.1, 0.1],
[5.8, 4. , 1.2, 0.2],
[5.7, 4.4, 1.5, 0.4],
[5.4, 3.9, 1.3, 0.4],
[5.1, 3.5, 1.4, 0.3],
[5.7, 3.8, 1.7, 0.3],
[5.1, 3.8, 1.5, 0.3],
[5.4, 3.4, 1.7, 0.2],
[5.1, 3.7, 1.5, 0.4],
[4.6, 3.6, 1. , 0.2],
[5.1, 3.3, 1.7, 0.5],
[4.8, 3.4, 1.9, 0.2],
[5. , 3. , 1.6, 0.2],
[5. , 3.4, 1.6, 0.4],
[5.2, 3.5, 1.5, 0.2],
[5.2, 3.4, 1.4, 0.2],
[4.7, 3.2, 1.6, 0.2],
[4.8, 3.1, 1.6, 0.2],
[5.4, 3.4, 1.5, 0.4],
[5.2, 4.1, 1.5, 0.1],
[5.5, 4.2, 1.4, 0.2],
[4.9, 3.1, 1.5, 0.2],
[5. , 3.2, 1.2, 0.2],
[5.5, 3.5, 1.3, 0.2],
[4.9, 3.6, 1.4, 0.1],
[4.4, 3. , 1.3, 0.2],
[5.1, 3.4, 1.5, 0.2],
[5. , 3.5, 1.3, 0.3],
[4.5, 2.3, 1.3, 0.3],
[4.4, 3.2, 1.3, 0.2],
[5. , 3.5, 1.6, 0.6],
[5.1, 3.8, 1.9, 0.4],
[4.8, 3. , 1.4, 0.3],
[5.1, 3.8, 1.6, 0.2],
[4.6, 3.2, 1.4, 0.2],
[5.3, 3.7, 1.5, 0.2],
[5. , 3.3, 1.4, 0.2],
[7. , 3.2, 4.7, 1.4],
[6.4, 3.2, 4.5, 1.5],
[6.9, 3.1, 4.9, 1.5],
[5.5, 2.3, 4. , 1.3],
[6.5, 2.8, 4.6, 1.5],
[5.7, 2.8, 4.5, 1.3],
[6.3, 3.3, 4.7, 1.6],
[4.9, 2.4, 3.3, 1. ],
[6.6, 2.9, 4.6, 1.3],
[5.2, 2.7, 3.9, 1.4],
[5. , 2. , 3.5, 1. ],
[5.9, 3. , 4.2, 1.5],
[6. , 2.2, 4. , 1. ],
[6.1, 2.9, 4.7, 1.4],
[5.6, 2.9, 3.6, 1.3],
[6.7, 3.1, 4.4, 1.4],
[5.6, 3. , 4.5, 1.5],
[5.8, 2.7, 4.1, 1. ],
[6.2, 2.2, 4.5, 1.5],
[5.6, 2.5, 3.9, 1.1],
[5.9, 3.2, 4.8, 1.8],
[6.1, 2.8, 4. , 1.3],
[6.3, 2.5, 4.9, 1.5],
[6.1, 2.8, 4.7, 1.2],
[6.4, 2.9, 4.3, 1.3],
[6.6, 3. , 4.4, 1.4],
[6.8, 2.8, 4.8, 1.4],
[6.7, 3. , 5. , 1.7],
[6. , 2.9, 4.5, 1.5],
[5.7, 2.6, 3.5, 1. ],
[5.5, 2.4, 3.8, 1.1],
[5.5, 2.4, 3.7, 1. ],
[5.8, 2.7, 3.9, 1.2],
[6. , 2.7, 5.1, 1.6],
[5.4, 3. , 4.5, 1.5],
[6. , 3.4, 4.5, 1.6],
[6.7, 3.1, 4.7, 1.5],
[6.3, 2.3, 4.4, 1.3],
[5.6, 3. , 4.1, 1.3],
[5.5, 2.5, 4. , 1.3],
[5.5, 2.6, 4.4, 1.2],
[6.1, 3. , 4.6, 1.4],
[5.8, 2.6, 4. , 1.2],
[5. , 2.3, 3.3, 1. ],
[5.6, 2.7, 4.2, 1.3],
[5.7, 3. , 4.2, 1.2],
[5.7, 2.9, 4.2, 1.3],
[6.2, 2.9, 4.3, 1.3],
[5.1, 2.5, 3. , 1.1],
[5.7, 2.8, 4.1, 1.3],
[6.3, 3.3, 6. , 2.5],
[5.8, 2.7, 5.1, 1.9],
[7.1, 3. , 5.9, 2.1],
[6.3, 2.9, 5.6, 1.8],
[6.5, 3. , 5.8, 2.2],
[7.6, 3. , 6.6, 2.1],
[4.9, 2.5, 4.5, 1.7],
[7.3, 2.9, 6.3, 1.8],
[6.7, 2.5, 5.8, 1.8],
[7.2, 3.6, 6.1, 2.5],
[6.5, 3.2, 5.1, 2. ],
[6.4, 2.7, 5.3, 1.9],
[6.8, 3. , 5.5, 2.1],
[5.7, 2.5, 5. , 2. ],
[5.8, 2.8, 5.1, 2.4],
[6.4, 3.2, 5.3, 2.3],
[6.5, 3. , 5.5, 1.8],
[7.7, 3.8, 6.7, 2.2],
[7.7, 2.6, 6.9, 2.3],
[6. , 2.2, 5. , 1.5],
[6.9, 3.2, 5.7, 2.3],
[5.6, 2.8, 4.9, 2. ],
[7.7, 2.8, 6.7, 2. ],
[6.3, 2.7, 4.9, 1.8],
[6.7, 3.3, 5.7, 2.1],
[7.2, 3.2, 6. , 1.8],
[6.2, 2.8, 4.8, 1.8],
[6.1, 3. , 4.9, 1.8],
[6.4, 2.8, 5.6, 2.1],
[7.2, 3. , 5.8, 1.6],
[7.4, 2.8, 6.1, 1.9],
[7.9, 3.8, 6.4, 2. ],
[6.4, 2.8, 5.6, 2.2],
[6.3, 2.8, 5.1, 1.5],
[6.1, 2.6, 5.6, 1.4],
[7.7, 3. , 6.1, 2.3],
[6.3, 3.4, 5.6, 2.4],
[6.4, 3.1, 5.5, 1.8],
[6. , 3. , 4.8, 1.8],
[6.9, 3.1, 5.4, 2.1],
[6.7, 3.1, 5.6, 2.4],
[6.9, 3.1, 5.1, 2.3],
[5.8, 2.7, 5.1, 1.9],
[6.8, 3.2, 5.9, 2.3],
[6.7, 3.3, 5.7, 2.5],
[6.7, 3. , 5.2, 2.3],
[6.3, 2.5, 5. , 1.9],
[6.5, 3. , 5.2, 2. ],
[6.2, 3.4, 5.4, 2.3],
[5.9, 3. , 5.1, 1.8]]), 'target': array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]), 'frame': None, 'target_names': array(['setosa', 'versicolor', 'virginica'], dtype='<U10'), 'DESCR': '.. _iris_dataset:\n\nIris plants dataset\n--------------------\n\n**Data Set Characteristics:**\n\n :Number of Instances: 150 (50 in each of three classes)\n :Number of Attributes: 4 numeric, predictive attributes and the class\n :Attribute Information:\n - sepal length in cm\n - sepal width in cm\n - petal length in cm\n - petal width in cm\n - class:\n - Iris-Setosa\n - Iris-Versicolour\n - Iris-Virginica\n \n :Summary Statistics:\n\n ============== ==== ==== ======= ===== ====================\n Min Max Mean SD Class Correlation\n ============== ==== ==== ======= ===== ====================\n sepal length: 4.3 7.9 5.84 0.83 0.7826\n sepal width: 2.0 4.4 3.05 0.43 -0.4194\n petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)\n petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)\n ============== ==== ==== ======= ===== ====================\n\n :Missing Attribute Values: None\n :Class Distribution: 33.3% for each of 3 classes.\n :Creator: R.A. Fisher\n :Donor: Michael Marshall (MARSHALL%[email protected])\n :Date: July, 1988\n\nThe famous Iris database, first used by Sir R.A. Fisher. The dataset is taken\nfrom Fisher\'s paper. Note that it\'s the same as in R, but not as in the UCI\nMachine Learning Repository, which has two wrong data points.\n\nThis is perhaps the best known database to be found in the\npattern recognition literature. Fisher\'s paper is a classic in the field and\nis referenced frequently to this day. (See Duda & Hart, for example.) The\ndata set contains 3 classes of 50 instances each, where each class refers to a\ntype of iris plant. One class is linearly separable from the other 2; the\nlatter are NOT linearly separable from each other.\n\n.. topic:: References\n\n - Fisher, R.A. "The use of multiple measurements in taxonomic problems"\n Annual Eugenics, 7, Part II, 179-188 (1936); also in "Contributions to\n Mathematical Statistics" (John Wiley, NY, 1950).\n - Duda, R.O., & Hart, P.E. (1973) Pattern Classification and Scene Analysis.\n (Q327.D83) John Wiley & Sons. ISBN 0-471-22361-1. See page 218.\n - Dasarathy, B.V. (1980) "Nosing Around the Neighborhood: A New System\n Structure and Classification Rule for Recognition in Partially Exposed\n Environments". IEEE Transactions on Pattern Analysis and Machine\n Intelligence, Vol. PAMI-2, No. 1, 67-71.\n - Gates, G.W. (1972) "The Reduced Nearest Neighbor Rule". IEEE Transactions\n on Information Theory, May 1972, 431-433.\n - See also: 1988 MLC Proceedings, 54-64. Cheeseman et al"s AUTOCLASS II\n conceptual clustering system finds 3 classes in the data.\n - Many, many more ...', 'feature_names': ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'], 'filename': '/usr/local/lib64/python3.6/site-packages/sklearn/datasets/data/iris.csv'}5. Pensamiento: ¿Deberían utilizarse todos los datos obtenidos para entrenar un modelo?
No todo se utiliza para entrenamiento, una pequeña parte se debe reservar para verificar si nuestro modelo es bueno o no, generalmente el 80% es entrenamiento y el 20% es testeo.
3. División de conjuntos de datos
1. El conjunto de datos generales del aprendizaje automático se divide en dos partes
(1) datos de entrenamiento: se utilizan para entrenar y construir modelos
(2) datos de prueba: se utilizan durante las pruebas del modelo para evaluar si el modelo es efectivo.
2. Proporción de división
(1) Conjunto de entrenamiento: 70 %, 80 %, 75 %
(2) Conjunto de prueba: 30 %, 20 %, 25 %
3. API de división de conjuntos de datos
(1) sklearn.model_selection.train_test_split(arrays, *options)
Los siguientes son los parámetros de los arreglos:
x: valor de característica del conjunto de datos
y: valor de etiqueta del conjunto de datos
Los siguientes son los parámetros de las opciones:
test_size: el tamaño del conjunto de prueba, generalmente flotante
random_state: la semilla de número aleatorio utilizada al dividir el conjunto de datos. Diferentes semillas causarán diferentes resultados de muestreo aleatorio. Los mismos resultados de muestreo de semillas son los mismos.
Asigne un valor a random_state donde debe establecerse. Cuando ejecuta este código varias veces, puede obtener exactamente los mismos resultados. Otros también pueden reproducir su proceso ejecutando este código. Si no se establece este parámetro, se seleccionará una semilla aleatoriamente y los resultados de la ejecución serán diferentes en consecuencia.
(2) El orden de retorno de los valores de retorno
: valor de característica del conjunto de entrenamiento, valor de característica del conjunto de prueba, valor objetivo del conjunto de entrenamiento, valor objetivo del conjunto de prueba.
Por lo tanto, el valor de retorno se define como x_train, x_test, y_train, y_test
4. Modificar day01_machine_learning.py
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def datasets_demo():
"""
sklearn数据集使用
"""
#获取数据集
iris = load_iris()
print("鸢尾花数据集:\n", iris)
print("查看数据集描述:\n", iris["DESCR"])
print("查看特征值的名字:\n", iris.feature_names)
print("查看特征值几行几列:\n", iris.data.shape)
#数据集的划分
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
print("训练集的特征值:\n", x_train, x_train.shape)
return None
if __name__ == "__main__":
# 代码1:sklearn数据集使用
datasets_demo()Resultados de ejecución: (Se omite parte del contenido anterior)
训练集的特征值:
[[4.8 3.1 1.6 0.2]
[5.4 3.4 1.5 0.4]
[5.5 2.5 4. 1.3]
[5.5 2.6 4.4 1.2]
[5.7 2.8 4.5 1.3]
[5. 3.4 1.6 0.4]
[5.1 3.4 1.5 0.2]
[4.9 3.6 1.4 0.1]
[6.9 3.1 5.4 2.1]
[6.7 2.5 5.8 1.8]
[7. 3.2 4.7 1.4]
[6.3 3.3 4.7 1.6]
[5.4 3.9 1.3 0.4]
[4.4 3.2 1.3 0.2]
[6.7 3. 5. 1.7]
[5.6 3. 4.1 1.3]
[5.7 2.5 5. 2. ]
[6.5 3. 5.8 2.2]
[5. 3.6 1.4 0.2]
[6.1 2.8 4. 1.3]
[6. 3.4 4.5 1.6]
[6.7 3. 5.2 2.3]
[5.7 4.4 1.5 0.4]
[5.4 3.4 1.7 0.2]
[5. 3.5 1.3 0.3]
[4.8 3. 1.4 0.1]
[5.5 4.2 1.4 0.2]
[4.6 3.6 1. 0.2]
[7.2 3.2 6. 1.8]
[5.1 2.5 3. 1.1]
[6.4 3.2 4.5 1.5]
[7.3 2.9 6.3 1.8]
[4.5 2.3 1.3 0.3]
[5. 3. 1.6 0.2]
[5.7 3.8 1.7 0.3]
[5. 3.3 1.4 0.2]
[6.2 2.2 4.5 1.5]
[5.1 3.5 1.4 0.2]
[6.4 2.9 4.3 1.3]
[4.9 2.4 3.3 1. ]
[6.3 2.5 4.9 1.5]
[6.1 2.8 4.7 1.2]
[5.9 3.2 4.8 1.8]
[5.4 3.9 1.7 0.4]
[6. 2.2 4. 1. ]
[6.4 2.8 5.6 2.1]
[4.8 3.4 1.9 0.2]
[6.4 3.1 5.5 1.8]
[5.9 3. 4.2 1.5]
[6.5 3. 5.5 1.8]
[6. 2.9 4.5 1.5]
[5.5 2.4 3.8 1.1]
[6.2 2.9 4.3 1.3]
[5.2 4.1 1.5 0.1]
[5.2 3.4 1.4 0.2]
[7.7 2.6 6.9 2.3]
[5.7 2.6 3.5 1. ]
[4.6 3.4 1.4 0.3]
[5.8 2.7 4.1 1. ]
[5.8 2.7 3.9 1.2]
[6.2 3.4 5.4 2.3]
[5.9 3. 5.1 1.8]
[4.6 3.1 1.5 0.2]
[5.8 2.8 5.1 2.4]
[5.1 3.5 1.4 0.3]
[6.8 3.2 5.9 2.3]
[4.9 3.1 1.5 0.1]
[5.5 2.3 4. 1.3]
[5.1 3.7 1.5 0.4]
[5.8 2.7 5.1 1.9]
[6.7 3.1 4.4 1.4]
[6.8 3. 5.5 2.1]
[5.2 2.7 3.9 1.4]
[6.7 3.1 5.6 2.4]
[5.3 3.7 1.5 0.2]
[5. 2. 3.5 1. ]
[6.6 2.9 4.6 1.3]
[6. 2.7 5.1 1.6]
[6.3 2.3 4.4 1.3]
[7.7 3. 6.1 2.3]
[4.9 3. 1.4 0.2]
[4.6 3.2 1.4 0.2]
[6.3 2.7 4.9 1.8]
[6.6 3. 4.4 1.4]
[6.9 3.1 4.9 1.5]
[4.3 3. 1.1 0.1]
[5.6 2.7 4.2 1.3]
[4.8 3.4 1.6 0.2]
[7.6 3. 6.6 2.1]
[7.7 2.8 6.7 2. ]
[4.9 2.5 4.5 1.7]
[6.5 3.2 5.1 2. ]
[5.1 3.3 1.7 0.5]
[6.3 2.9 5.6 1.8]
[6.1 2.6 5.6 1.4]
[5. 3.4 1.5 0.2]
[6.1 3. 4.6 1.4]
[5.6 3. 4.5 1.5]
[5.1 3.8 1.5 0.3]
[5.6 2.8 4.9 2. ]
[4.4 3. 1.3 0.2]
[5.5 2.4 3.7 1. ]
[4.7 3.2 1.6 0.2]
[6.7 3.3 5.7 2.5]
[5.2 3.5 1.5 0.2]
[6.4 2.7 5.3 1.9]
[6.3 2.8 5.1 1.5]
[4.4 2.9 1.4 0.2]
[6.1 3. 4.9 1.8]
[4.9 3.1 1.5 0.2]
[5. 2.3 3.3 1. ]
[4.8 3. 1.4 0.3]
[5.8 4. 1.2 0.2]
[6.3 3.4 5.6 2.4]
[5.4 3. 4.5 1.5]
[7.1 3. 5.9 2.1]
[6.3 3.3 6. 2.5]
[5.1 3.8 1.9 0.4]
[6.4 2.8 5.6 2.2]
[7.7 3.8 6.7 2.2]] (120, 4)Debido a que test_size=0.2 significa el 20% del conjunto de prueba, el 80% del conjunto de entrenamiento y un total de 150 muestras, el conjunto de entrenamiento es 150*0.8=120.